(點選上方公眾號,可快速關註)
英文:Felipe Hoffa,翻譯:Linux中國/Xingyu.Wang
linux.cn/article-9037-1-rel.html
在這篇分析報告中,我們將使用 2017 年度截止至當前時間(2017 年 10 月)為止,GitHub 上所有公開的推送事件的資料。對於每個 GitHub 使用者,我們將盡可能地猜測其所屬的公司。此外,我們僅檢視那些今年得到了至少 20 個星標的倉庫。
以下是我的報告結果,你也可以在我的互動式 Data Studio 報告上進一步加工。
頂級雲服務商的比較
2017 年它們在 GitHub 上的表現:
-
微軟看起來約有 1300 名員工積極地推送程式碼到 GitHub 上的 825 個頂級倉庫。
-
谷歌顯示出約有 900 名員工在 GitHub 上活躍,他們推送程式碼到大約 1100 個頂級倉庫。
-
亞馬遜似乎只有 134 名員工活躍在 GitHub 上,他們推送程式碼到僅僅 158 個頂級專案上。
-
不是所有的專案都一樣:在超過 25% 的倉庫上谷歌員工要比微軟員工貢獻的多,而那些倉庫得到了更多的星標(53 萬對比 26 萬)。亞馬遜的倉庫 2017 年合計才得到了 2.7 萬個星標。

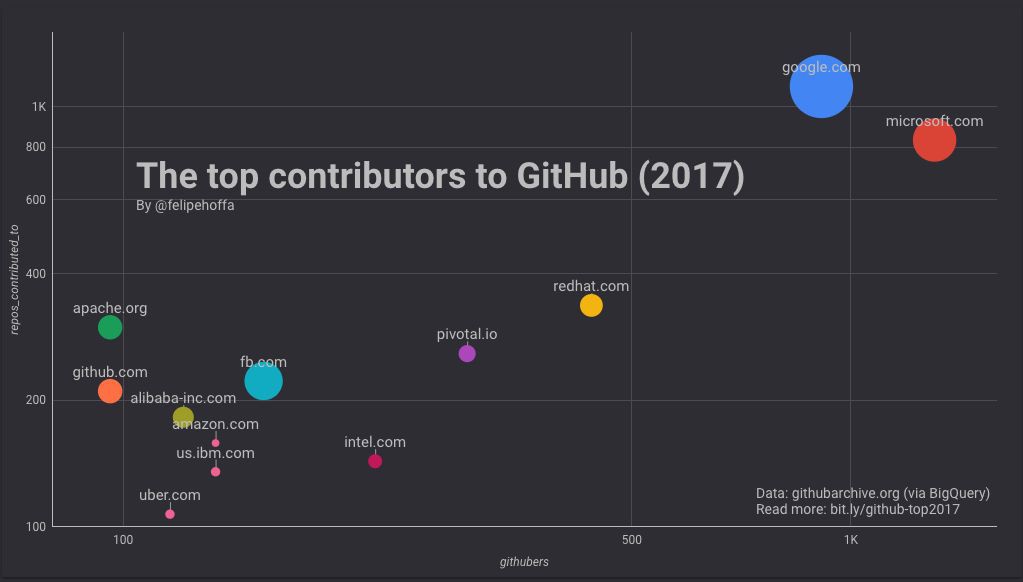
紅帽、IBM、Pivotal、英特爾和 Facebook
如果說亞馬遜看起來被微軟和谷歌遠遠拋在了身後,那麼這之間還有哪些公司呢?根據這個排名來看,紅帽、Pivotal 和英特爾在 GitHub 上做出了巨大貢獻:
註意,下表中合併了所有的 IBM 地區域名(各個地區會展示在其後的表格中)。


Facebook 和 IBM(美)在 GitHub 上的活躍使用者數同亞馬遜差不多,但是它們所貢獻的專案得到了更多的星標(特別是 Facebook):
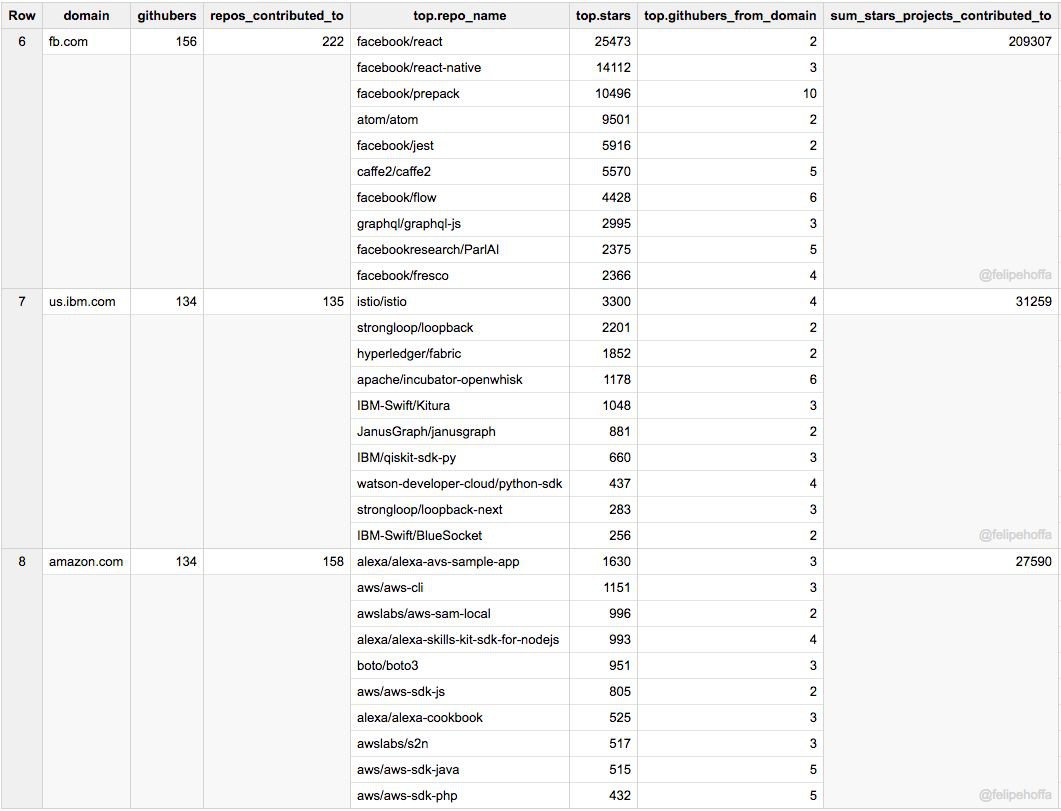
接下來是阿裡巴巴、Uber 和 Wix:

以及 GitHub 自己、Apache 和騰訊:

百度、蘋果和 Mozilla:
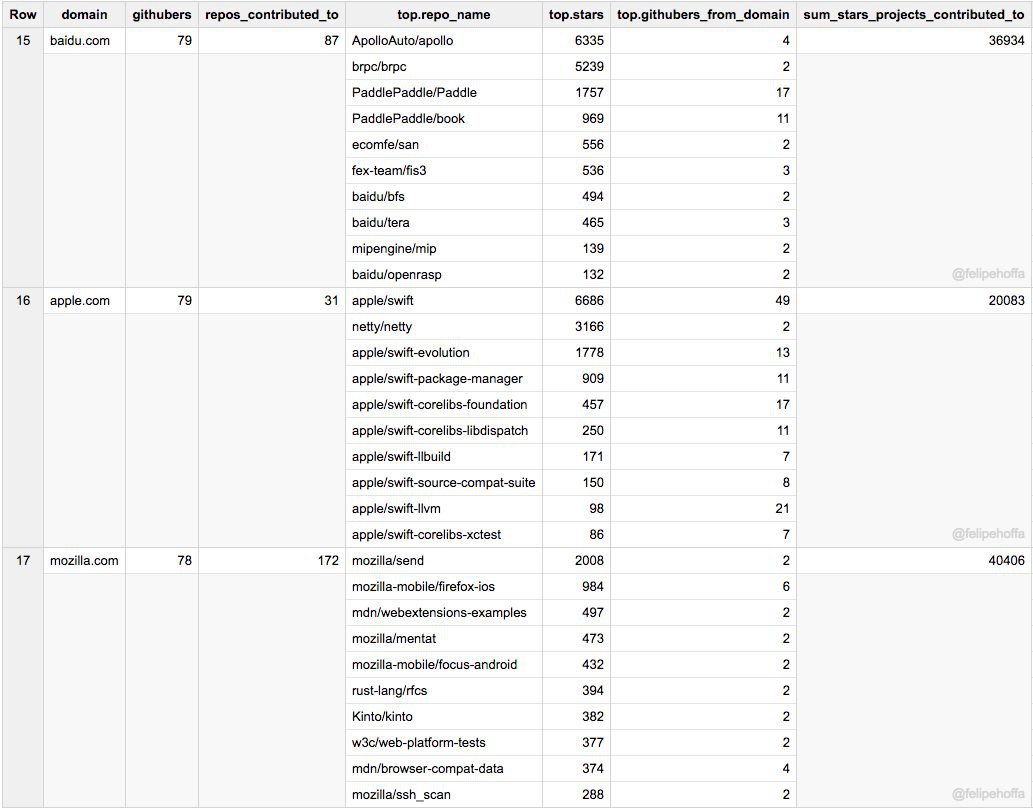
(LCTT 譯註:很高興看到國內的頂級網際網路公司阿裡巴巴、騰訊和百度在這裡排名前列!)
甲骨文、斯坦福大學、麻省理工、Shopify、MongoDb、伯克利大學、VmWare、Netflix、Salesforce 和 Gsa.gov:

LinkedIn、Broad Institute、Palantir、雅虎、MapBox、Unity3d、Automattic(WordPress 的開發商)、Sandia、Travis-ci 和 Spotify:

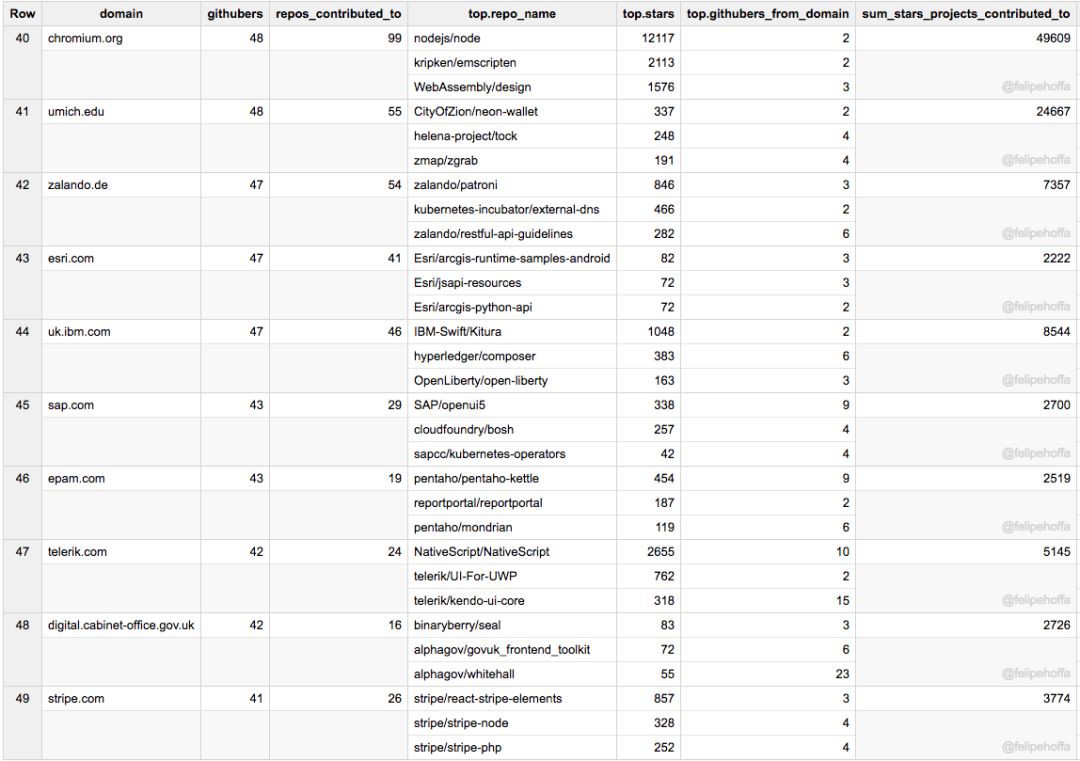
Chromium、UMich、Zalando、Esri、IBM (英)、SAP、EPAM、Telerik、UK Cabinet Office 和 Stripe:
Cern、Odoo、Kitware、Suse、Yandex、IBM (加)、Adobe、AirBnB、Chef 和 The Guardian:

Arm、Macports、Docker、Nuxeo、NVidia、Yelp、Elastic、NYU、WSO2、Mesosphere 和 Inria:

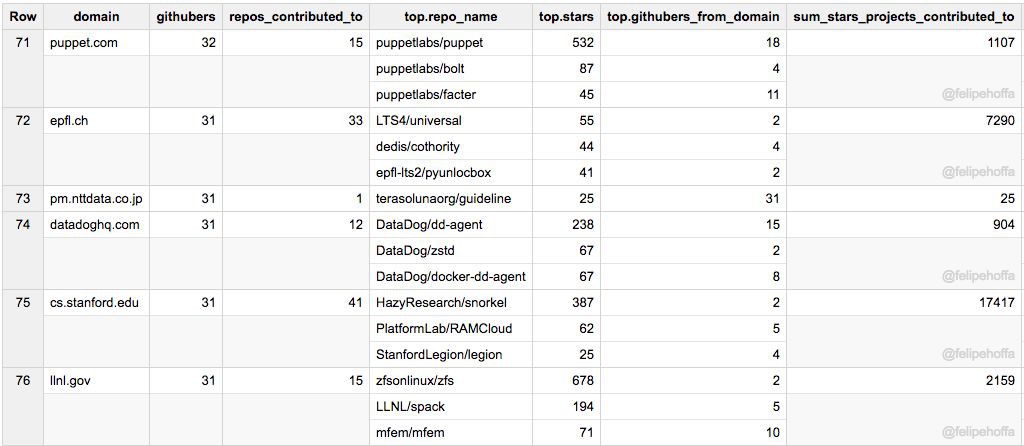
Puppet、斯坦福(電腦科學)、DatadogHQ、Epfl、NTT Data 和 Lawrence Livermore Lab:
我的分析方法
我是怎樣將 GitHub 使用者關聯到其公司的
在 GitHub 上判定每個使用者所屬的公司並不容易,但是我們可以使用其推送事件的提交訊息中展示的郵件地址域名來判斷。
-
同樣的郵件地址可以出現在幾個使用者身上,所以我僅考慮那些對此期間獲得了超過 20 個星標的專案進行推送的使用者。
-
我僅統計了在此期間推送超過 3 次的 GitHub 使用者。
-
使用者推送程式碼到 GitHub 上可以在其推送中顯示許多不同的郵件地址,這部分是由 GIt 工作機制決定的。為了判定每個使用者的組織,我會查詢那些在推送中出現更頻繁的郵件地址。
-
不是每個使用者都在 GitHub 上使用其組織的郵件。有許多人使用 gmail.com、users.noreply.github.com 和其它郵件託管商的郵件地址。有時候這是為了保持匿名和保護其公司郵箱,但是如果我不能定位其公司域名,這些使用者我就不會統計。抱歉。
-
有時候員工會更換所任職的公司。我會將他們分配給其推送最多的公司。
我的查詢陳述句
#standardSQL
WITH
period AS (
SELECT *
FROM `githubarchive.month.2017*` a
),
repo_stars AS (
SELECT repo.id, COUNT(DISTINCT actor.login) stars, APPROX_TOP_COUNT(repo.name, 1)[OFFSET(0)].value repo_name
FROM period
WHERE type=‘WatchEvent’
GROUP BY 1
HAVING stars>20
),
pushers_guess_emails_and_top_projects AS (
SELECT *
# , REGEXP_EXTRACT(email, r’@(.*)’) domain
, REGEXP_REPLACE(REGEXP_EXTRACT(email, r‘@(.*)’), r‘.*.ibm.com’, ‘ibm.com’) domain
FROM (
SELECT actor.id
, APPROX_TOP_COUNT(actor.login,1)[OFFSET(0)].value login
, APPROX_TOP_COUNT(JSON_EXTRACT_SCALAR(payload, ‘$.commits[0].author.email’),1)[OFFSET(0)].value email
, COUNT(*) c
, ARRAY_AGG(DISTINCT TO_JSON_STRING(STRUCT(b.repo_name,stars))) repos
FROM period a
JOIN repo_stars b
ON a.repo.id=b.id
WHERE type=‘PushEvent’
GROUP BY 1
HAVING c>3
)
)
SELECT * FROM (
SELECT domain
, githubers
, (SELECT COUNT(DISTINCT repo) FROM UNNEST(repos) repo) repos_contributed_to
, ARRAY(
SELECT AS STRUCT JSON_EXTRACT_SCALAR(repo, ‘$.repo_name’) repo_name
, CAST(JSON_EXTRACT_SCALAR(repo, ‘$.stars’) AS INT64) stars
, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo
GROUP BY 1, 2
HAVING githubers_from_domain>1
ORDER BY stars DESC LIMIT 3
) top
, (SELECT SUM(CAST(JSON_EXTRACT_SCALAR(repo, ‘$.stars’) AS INT64)) FROM (SELECT DISTINCT repo FROM UNNEST(repos) repo)) sum_stars_projects_contributed_to
FROM (
SELECT domain, COUNT(*) githubers, ARRAY_CONCAT_AGG(ARRAY(SELECT * FROM UNNEST(repos) repo)) repos
FROM pushers_guess_emails_and_top_projects
#WHERE domain IN UNNEST(SPLIT(‘google.com|microsoft.com|amazon.com’, ‘|’))
WHERE domain NOT IN UNNEST(SPLIT(‘gmail.com|users.noreply.github.com|qq.com|hotmail.com|163.com|me.com|googlemail.com|outlook.com|yahoo.com|web.de|iki.fi|foxmail.com|yandex.ru’, ‘|’)) # email hosters
GROUP BY 1
HAVING githubers > 30
)
WHERE (SELECT MAX(githubers_from_domain) FROM (SELECT repo, COUNT(*) githubers_from_domain FROM UNNEST(repos) repo GROUP BY repo))>4 # second filter email hosters
)
ORDER BY githubers DESC
FAQ
有的公司有 1500 個倉庫,為什麼只統計了 200 個?有的倉庫有 7000 個星標,為什麼只顯示 1500 個?
我進行了過濾。我只統計了 2017 年的星標。舉個例子說,Apache 在 GitHub 上有超過 1500 個倉庫,但是今年只有 205 個專案得到了超過 20 個星標。


這表明瞭開源的發展形勢麼?
註意,這個對 GitHub 的分析沒有包括像 Android、Chromium、GNU、Mozilla 等頂級社群,也沒有包括 Apache 基金會或 Eclipse 基金會,還有一些其它專案選擇在 GitHub 之外開展起活動。
這對於我的組織不公平
我只能統計我所看到的資料。歡迎對我的統計的前提提出意見,以及對我的統計方法給出改進方法。如果有能用的查詢陳述句就更好了。
舉個例子,要看看當我合併了 IBM 的各個地區域名到其頂級域時排名發生了什麼變化,可以用一條 SQL 陳述句解決:
SELECT *, REGEXP_REPLACE(REGEXP_EXTRACT(email, r‘@(.*)’), r‘.*.ibm.com’, ‘ibm.com’) domain

當合併了其地區域名後, IBM 的相對位置明顯上升了。
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能

