
導讀:圍棋人機大戰、人臉識別、自動駕駛、智慧控制、語言和影象理解……這些年,人工智慧的威力,我們已經見識過太多。“人工智慧”甚至入選“2017年度中國媒體十大流行語”。
如今,深度學習結合大資料,讓人工智慧學習“知識”成為可能。人工智慧正在試圖擁有一個人類的大腦。那麼,在人工智慧橫行的時代,人類的工作甚至生存的空間又在哪裡?
以下觀點和案例會告訴你,人類在未來在4個工作領域仍然不可替代,這4項工作也將成為業內的“鐵飯碗”。希望本文能夠為你的職業規劃及發展方向提供幫助。

將從大資料中提取“知識”的工作交給人工智慧,但這絕不意味著人類將變得無關緊要。人類需要承擔“選擇合適方法”等新的任務。讓我們來看看人類應發揮的4點作用。
01 進行深層神經網路的內部設計,為人工智慧選擇合適的機器學習方法
深層學習(Deep Learning)也有缺點,絕不是萬能的方法。而且在很多情況下我們使用傳統的方法會更加見效。東京大學的原田達也教授作為影象識別技術的研究人員指出:“其中的一個難題就是,關於如何進行深層神經網路的內部設計,目前還沒有人能夠提出一個明確的設計指南。”
所以人類應該發揮的第一個作用,就是選擇合適的機器學習方法。
除了深層學習之外,機器學習的方法還有很多。對很多企業來說,與其一下子就嘗試難以駕馭的深層學習,不如引入現有的機器學習方法更具實際意義。
在方法的選擇上,我們可以參考橫濱國立大學濱上知樹教授的做法。橫濱市從2008年起開始構建“119緊急電話對緊急程度/病情嚴重程度的識別(call triage)”預測模型系統,而濱上教授正是負責該專案機器學習的研究人員。
橫濱市的call triage指的是從通話內容中預測撥打119電話的患者病情的嚴重程度,根據具體癥狀來調整急救人員的種類和規模。因為現在急救人員的人手增加存在困難,如何有效安排就顯得非常重要。
這時候最重要的一點就是“不能把重症的患者判斷為輕症”(濱上教授)。哪怕允許“把輕症的患者判斷為重症”,也絕不允許系統把重症患者判斷為輕症。也正因為如此,系統最初的預測精準度還不到30%。

▲橫濱市“call triage支援系統”
濱上教授為了提高準確度,始終在更新機器學習的方法。從最初的“logistic回歸”分析到“貝葉斯網路”“支援向量機(SVM)”,再到現在的“隨機森林”,隨著每一次方法的改進,系統的預測精準度都有所提升,現在已經在80%以上。
有意思的一點是,比起在構建預測模型時參考了醫生意見的貝葉斯網路,沒有參考醫生意見的SVM及隨機森林的預測精確度反而更高。濱上教授指出:“電腦竟然能比醫生更準確地判斷患者病情的嚴重程度,這對一般人來說可能在感情上很難接受。消除這種誤解,也是人工智慧研究人員的重要任務之一。”
02 找出機器學習和深層學習的適用領域
找出機器學習和深層學習的適用領域,這是人類的第二個作用。透過在各個領域不斷嘗試機器學習並評估其成效,尋找可以應用的新領域,這種態度是非常重要的。
製藥公司過去依靠的是實驗和建模方式,而現在它們開始利用機器學習進行新藥研發。
2014年,日本的非營利組織(NPO)“併列生物資訊處理Initiative”舉辦了“用電腦創造製藥原料”大賽。在這場大賽中,引進了機器學習的風險企業“資訊數理生物”公司拔得了頭籌。比賽的主題是從220萬種化合物中尋找出擁有某種療效的、可用於製藥的化合物。
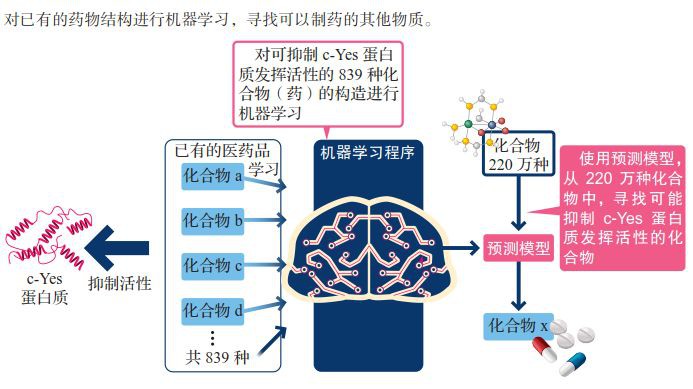
▲“資訊數理生物”公司研發的“虛擬篩選”系統
在這裡需要找出損傷蛋白質活性的化合物,這是造成疾病的原因。目前共有兩種方法可以找出這種化合物:①進行真實的實驗。②透過電腦建模的方式再現蛋白質和化合物的構造,並據此進行模擬實驗。
但是,化合物共有220萬種,如果對每一種都進行實驗或建模,從成本到時間上都很難做到。該公司根據“結構相似的化合物,其作用也相似”這一生物規則為線索,讓電腦“針對現有醫葯品的結構進行機器學習,尋找結構相似的化合物”(望月正弘)。實踐證明,利用這種方法確實找到了有望作為藥品發揮作用的化合物。
在素材和材料領域也能看到同樣的探索。在“資訊材料學”方面,現在正透過機器學習尋找可用於製造超導體及太陽能電池材料、鋰離子電池材料的化合物。
03 驗證機器提出的假設,思考這些樣式和規律產生的原因
人工智慧可以從大量資料中找到樣式和規律,而思考這些樣式和規律產生的原因,從中發現新知識,則是隻有人類才能完成的工作。這也是人類的第三個作用。
日本大型綜合建設公司大林組計劃從2014年11月開始啟用系統,採用NEC的“異種混合學習”機器學習技術,根據樓宇裡安裝的4500個感測器提供的資料,對24小時或1個月後樓宇的能源消耗量進行預測。
樓宇的能源消耗樣式根據平日、週末和時間段等不同而有所不同。對於具體在什麼時間點樣式會發生改變這一點,一直以來都是靠人工根據專業知識分出幾種不同的情況,再製作出合適的模型進行判斷的。

▲大林組公司的樓宇能源消耗預測系統
NEC的異種混合學習則是透過機器學習的方法觀察到樣式的轉換,再根據不同的樣式生成模型。傳統的預測模型的失誤率超過10%,預計匯入異種混合學習之後,失誤率會降到5%以下。
大林組公司環境解決方案部小野島一部長說:“今後我們要做的工作就是,瞭解異種混合學習在什麼節點對樣式進行切換,找到其背後的原因。”比如異種混合學習分析出以某戶外溫度值為節點,預測模型會發生切換。“我們要弄明白在超過這個溫度時樓宇中的哪些內容會發生改變。透過理清這些因果關係,可能會發現新的節能方法。”
04 收集資料,制定資料收集機制以供人工智慧進行學習
只要有資料,人工智慧就可以學習,但是如果沒有資料,那就什麼也做不了。如何制定資料收集機制以供人工智慧進行學習,是人類的重要任務,也是人類的第四個作用。
日本SoftBank Mobile公司目前正在推進由SoftBank Robotics研發的人形機器人“Pepper”的推廣活動。其目的之一,就是透過Pepper“收集店裡接待客人時的相關資料”(SoftBank Robotics PMO室林要主任)。

▲Softbank公司的待客機器人“Pepper”
一直以來,都是由店員在店裡承擔接待客人的工作。“店員和客人進行溝通以後,顧客有哪些反應”這一類資料完全沒有記錄下來。
Pepper可以識別顧客聲音,理解話語內容,透過對話向客人提供服務。它甚至還可以根據顧客的語音語調判斷客人的情緒。透過Pepper的行為,可以收集到有關顧客反應的相關資料。
“要想讓‘服務型機器人’在服務行業大顯身手,最重要的一點就是收集資料。如果可以大量收集到能夠確保一定質量的資料,就可以孕育出新的認知。”林要主任說。
資料收集工作中最難的一點,就在於收集反映人類判斷結果的“訓練資料”。如果訓練資料的收集實在困難,也可以採用“無監督學習”方式。
例如,風險企業Informetis僅僅根據家庭或辦公室裡一個電流感測器的資料,就透過無監督學習的方式開發了可以分別識別多臺機器用電量的“機器分離技術”。該技術的特點在於無須為每一臺機器配備電流感測器。
“冰箱、電視、電腦等機器的種類繁多,我們認為很難收集用於識別各類機器的訓練資料,也就是反映各機器耗電傾向的資料,所以採用了無監督學習方式。”該公司社長只野太郎介紹說。
哪些資料需要收集,哪些資料能夠收集,對這些問題進行判斷,正是隻有我們人類才能完成的工作。
關於作者:日經計算機,一本寫給管理者與領導者的IT綜合資訊雜誌,以連結IT策劃、研發、應用為己任。旨在傳播“推進商業的IT”資訊,讓讀者能輕鬆理解策劃、研發與應用的綜合資訊。

本文摘編自《物聯網商業時代》
點選“閱讀原文”瞭解及購買本書
轉載請聯絡:baiyu@hzbook.com
點選文末右下角“寫留言”發表你的觀點
推薦語:有網友評論該書為“未來生活的提前預演”。這是一部全面展示物聯網前沿的產業分析手冊,物聯網並不是時髦的概念,它在悄悄從產業鏈的上游改變我們的世界。
推薦閱讀
日本老爺爺堅持17年用Excel作畫,我可能用了假的Excel···
看完此文再不懂區塊鏈算我輸:手把手教你用Python從零開始建立區塊鏈
Q: 你找到你的專屬“鐵飯碗”了嗎?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩文章,請在公眾號後臺點選“歷史文章”檢視


