前言
HBase 是一個基於 Hadoop 面向列的非關係型分散式資料庫(NoSQL), 設計概念來源於谷歌的 BigTable 模型,面向實時讀寫、隨機訪問大規模資料集的場景,是一個高可靠性、高效能、高伸縮的分散式儲存系統,在大資料相關領域應用廣泛. HBase 系統支援對所儲存的資料進行透明切分,從而使得系統的儲存以及計算具有良好的水平擴充套件性.
知乎從 2017 年起開始逐漸採用 HBase 系統儲存各類線上業務資料,併在 HBase 服務之上構建各類應用模型以及資料計算任務;伴隨著知乎這兩年的發展,知乎核心架構團隊基於開源容器排程平臺 Kubernetes 打造了一整套 HBase 服務平臺管理系統,經過近兩年的研發迭代,目前已經形成了一套較為完整的 HBase 自動化運維服務體系,能夠完成 HBase 叢集的快捷部署,平滑擴縮容,HBase 元件細粒度監控,故障跟蹤等功能.
背景
知乎對 HBase 的使用經驗不算太長,在 2017 年初的時候,HBase 服務主要用於離線演演算法,推薦,反作弊,還有基礎資料倉庫資料的儲存計算,透過 MapReduce 和 Spark 來進行訪問. 而在當時知乎的線上儲存主要採用 MySQL 和 Redis 系統,其中:
- MySQL: 支援大部分的業務資料儲存,當資料規模增大後有一些需要進行擴容的表,分表會帶來一定的複雜性,有些業務希望能遮蔽這個事情,還有一些是因為歷史原因在表設計的時候用 rmsdb 的形式存了一些本該由列儲存的資料,希望做一下遷移. 此外 MySQL 基於 SSD,雖然效能很好,花銷也比較大;
- Redis: 可以提供大規模的快取,也可以提供一定的儲存支援. Redis 效能極好,主要的侷限是做資料 Resharding 較為繁瑣 ,其次是記憶體成本較高;
針對以上兩種線上儲存所存在的一些問題,我們希望建立一套線上儲存 NoSQL 服務,對以上兩種儲存作為一個補充;選型期間我們也考慮過 Cassandra, 早期一些業務曾嘗試使用 Cassandra 作為儲存,隔壁團隊在運維了一段時間的 Cassandra 系統之後,遇到不少的問題,Cassandra 系統可操作性沒有達到預期,目前除了 Tracing 相關的系統,其他業務已經放棄使用 Cassandra.
我們從已有的離線儲存系統出發,在衡量了穩定性,效能,程式碼成熟度,上下游系統承接,業界使用場景以及社群活躍度等方面之後,選擇了 HBase,作為知乎線上儲存的支撐元件之一.
HBase On Kubernetes
初期知乎只有一套進行離線計算的叢集,所有業務都跑在一個叢集上,並且 HBase 叢集和其他離線計算 yarn 以及 Impala 混合部署,HBase 的日常離線計算和資料讀寫都嚴重受到其他系統影響;並且 HBase 的監控都只停留在主機層面的監控,出現執行問題時,進行排查很困難,系統恢復服務時間較長,這種狀態下,我們需要重新構建一套適用於線上服務的系統.
在這樣的場景下,我們對線上 HBase 服務的需求是明確的:
隔離性:
- 從業務方的視角來說,希望相關的服務做到環境隔離,許可權收歸業務,避免誤操作和業務相互影響;
- 對於響應時間,服務的可用性,都可以根據業務的需要指定 SLA;
- 對於資源的分配和 blockcache 等引數的配置也能夠更加有適應性,提供業務級別的監控和報警,快速定位和響應問題;
資源利用率:從運維的角度,資源的分配要合理,盡可能的提升主機 cpu,記憶體包括磁碟的有效利用率;
成本控制: 團隊用最小的成本去得到最大的運維收益,所以需要提供便捷的呼叫介面,能夠靈活的進行 HBase 叢集的申請,擴容,管理,監控. 同時成本包括機器資源,還有工程師. 當時我們線上的這套系統是由一位工程師獨立去進行維護.
綜合以上需求,參考我們團隊之前對基礎設施平臺化的經驗,最終的標的是把 HBase 服務做成基礎元件服務平臺向提供給上游業務,這個也是知乎技術平臺部門工作思路之一,盡可能的把所有的元件對業務都黑盒化,介面化,服務化. 同時在使用和監控的粒度上盡可能的準確,細緻,全面. 我們構建線上 HBase 管理運維繫統的一個初衷.
Why Kubernetes?
前文說到我們希望將整個 HBase 系統平臺服務化,那就涉及到如何管理和運維 HBase 系統,知乎在微服務和容器方面的工作積累和經驗是相當豐富的,在當時我們所有的線上業務都已經完成了容器化的遷移工作,超萬級別的業務容器平穩執行在基於 mesos 的容器管理平臺 Bay 上(參見[1]);與此同時,團隊也在積極的做著 Infrastructure 容器化的嘗試,已經成功將基礎訊息佇列元件 Kafka 容器化執行於 Kubernetes 系統之上 (參見[2]),因此我們決定也將 HBase 透過 Kubernetes 來進行資源的管理排程.
Kubernetes[3] 是谷歌開源的容器叢集管理系統,是 Google 多年大規模容器管理技術 Borg 的開源版本. Kubernetes 提供各種維度元件的資源管理和排程方案,隔離容器的資源使用,各個元件的 HA 工作,同時還有較為完善的網路方案. Kubernetes 被設計作為構建元件和工具的生態系統平臺,可以輕鬆地部署、擴充套件和管理應用程式. 有著 Kubernetes 大法的加持,我們很快有了最初的落地版本([4]).
初代
最初的落地版本架構見下圖,平臺在共享的物理叢集上透過 Kubernetes(以下簡稱 K8S) API 建立了多套邏輯上隔離的 HBase 叢集,每套叢集由一組 Master 和若干個 Regionserver (以下簡稱 RS) 構成, 叢集共享一套 HDFS 儲存叢集,各自依賴的 Zookeeper 叢集獨立;叢集透過一套管理系統 Kubas 服務來進行管理([4]).

第一代架構
模組定義
在 K8S 中如何去構建 HBase 叢集,首先需要用 K8S 本身的基礎元件去描述 HBase 的構成;K8S 的資源元件有以下幾種:
- Node: 定義主機節點,可以是物理機,也可以是虛擬機器;
- Pod: 一組緊密關聯的容器集合,是 K8S 排程的基本單位;
- ReplicationController: 一組 pod 的控制器,透過其能夠確保 pod 的執行數量和健康,並能夠彈性伸縮;
結合之前 Kafka on K8S 的經驗,出於高可用和擴充套件性的考慮,我們沒有採用一個 Pod 裡帶多個容器的部署方式,統一用一個 ReplicationController 定義一類 HBase 元件,就是上圖中的 Master,Regionserver 還有按需建立的 Thriftserver;透過以上概念,我們在 K8S 上就可以這樣定義一套最小 HBase 叢集:
2 * Master ReplicationController;
3 * Regionserver ReplicationController;
2 * Thriftserver ReplicationController (可選);
高可用以及故障恢復
作為面向線上業務服務的系統,高可用和故障轉移是必需在設計就要考慮的事情,在整體設計中,我們分別考慮元件級別,叢集級別和資料儲存級別的可用性和故障恢復問題.
元件級別
HBase 本身已經考慮了很多故障切換和恢復的方案:
- Zookeeper 叢集:自身設計保證了可用性;
- Master: 透過多個master註冊在 Zookeeper 叢集上來進行主節點的 HA 和更新;
- RegionServer: 本身就是無狀態的,節點失效下線以後會把上面的 region 自動遷走,對服務可用性不會有太大影響;
- Thriftserver: 當時業務大多數是 Python 和 Golang,透過用 Thrift 對 HBase 的進行,Thriftserver 本身是單點的,這裡我們透過 HAProxy 來代理一組 Thriftserver 服務;
- HDFS:本身又由 Namenode 和 DataNode 節點組成,Namenode 我們開啟 HA 功能, 保證了 HDFS 的叢集可用性;
叢集級別
- Pod 容器失效: Pod 是透過 ReplicationController 維護的, K8S 的 ControllerManager 會在它 的儲存 etcd 去監聽元件的失效情況,如果副本少於預設值會自動新的 Pod 容器來進行服務;
- Kubernetes 叢集崩潰: 該場景曾經在生產環境中出現過,針對這種情況,我們對 SLA 要求較高的業務採用了少量物理機搭配容器的方式進行混合部署,極端場景出現時,可以保證重要業務收到的影響可控;
資料級別
所有在 K8S 上構建的 HBase 叢集都共享了一套 HDFS 叢集,資料的可用性由 HDFS 叢集的多副本來提供.
實現細節
資源分配
初期物理節點統一採用 2*12 核心的 cpu,128G 記憶體和 4T 的磁碟,其中磁碟用於搭建服務的 HDFS,CPU 和記憶體則在 K8S 環境中用於建立 HBase 相關服務的節點.
Master 元件的功能主要是管理 HBase 叢集,Thriftserver 元件主要承擔代理的角色,所以這兩個元件資源都按照固定額度分配.
在對 Regionserver 元件進行資源分配設計的時候,考慮兩種方式去定義資源:

資源分配方式
按照業務需求分配:
- 根據業務方對自身服務的描述,對相關的 QPS 以及 SLA 進行評估,為業務專門配置引數,包含 blockcache, region 大小以及數量等;
- 優點是針對業務最佳化,能夠充分的利用資源,降低業務的資源佔用成本;
- 管理成本增加,需要對每一個業務進行評估,對平臺維護人員非常不友好,同時需要業務同學本身對 HBase 有理解;
統一規格的資源分配:
- CPU 以及 MEM 都按照預先設定好的配額來分配, 提供多檔的配置,將 CPU 和 MEM 的配置套餐化;
- 方便之處在於業務擴容時直接增加 Regionserver 的個數,配置穩定,運維成本較低,遇到問題時排障方便;
- 針對某些有特有訪問方式的業務有侷限性,如 CPU 計算型,大 KV 儲存,或者有 MOB 需求的業務,需要特殊的定製;
介於當時考慮接入的線上業務並不多,所以採用了按業務定製的方式去配置 Regionserver, 正式環境同一業務採用統一配置的一組Regionserver,不存在混合配置的 Regionserver 組.
引數配置
基礎映象基於 cdh5.5.0-hbase1.0.0 構建
# Example for hbase dockerfile
# install cdh5.5.0-hbase1.0.0
ADD hdfs-site.xml /usr/lib/hbase/conf/
ADD core-site.xml /usr/lib/hbase/conf/
ADD env-init.py /usr/lib/hbase/bin/
ENV JAVA_HOME /usr/lib/jvm/java-8-oracle
ENV HBASE_HOME /usr/lib/hbase
ENV HADOOP_PREFIX /usr/lib/hadoop
ADD env-init.py /usr/lib/hbase/bin/
ADD hadoop_xml_conf.sh /usr/lib/hbase/bin/
- 固定的環境變數,如 JDK_HOME, HBASE_HOME, 都透過 ENV 註入到容器映象中;
- 與 HDFS 相關的環境變數,如 hdfs-site.xml 和 core-site.xml 預先加入 Docker 映象中,構建的過程中就放入了 HBase 的相關目錄中,用以確保 HBase 服務能夠透過對應配置訪問到 HDFS;
- 與 HBase 相關的配置資訊, 如元件啟動依賴的 Zookeeper 叢集地址,HDFS 資料目錄路徑, 堆記憶體以及GC 引數等,這些配置都需要根據傳入 Kubas Service 的資訊進行對應變數的修改, 一個典型的傳入引數示例:
REQUEST_DATA = {
“name”: ‘test-cluster’,
“rootdir”: “hdfs://namenode01:8020/tmp/hbase/test-cluster”,
“zkparent”: “/test-cluster”,
“zkhost”: “zookeeper01,zookeeper02,zookeeper03”,
“zkport”: 2181,
“regionserver_num”: ‘3’,
“codecs”: “snappy”,
“client_type”: “java”,
“cpu”: ‘1’,
“memory”: ’30’,
“status”: “running”,
}
透過上面的引數 Kubas Service 啟動 Docker 時,在啟動命令中利用 hadoop_xml_conf.sh 和 env-init.py 修改 hbase-site.xml 和 hbase-env.sh 檔案來完成最後的配置註入,如下所示:
source /usr/lib/hbase/bin/hadoop_xml_conf.sh
&& put_config –file /etc/hbase/conf/hbase-site.xml –property hbase.regionserver.codecs –value snappy
&& put_config –file /etc/hbase/conf/hbase-site.xml –property zookeeper.znode.parent –value /test-cluster
&& put_config –file /etc/hbase/conf/hbase-site.xml –property hbase.rootdir –value hdfs://namenode01:8020/tmp/hbase/test-cluster
&& put_config –file /etc/hbase/conf/hbase-site.xml –property hbase.zookeeper.quorum –value zookeeper01,zookeeper02,zookeeper03
&& put_config –file /etc/hbase/conf/hbase-site.xml –property hbase.zookeeper.property.clientPort –value 2181
&& service hbase-regionserver start && tail -f /var/log/hbase/hbase-hbase-regionserver.log
網路通訊
網路方面,採用了 Kubernetes 上原生的網路樣式,每一個 Pod 都有自己的 IP 地址,容器之間可以直接通訊,同時在 Kubernetes 叢集中添加了 DNS 自動註冊和反註冊功能, 以 Pod 的標識名字作為域名,在 Pod 建立和重啟和銷毀時將相關資訊同步全域性 DNS.
在這個地方我們遇到過問題,當時我們的 DNS 解析不能在 Docker 網路環境中透過 IP 反解出對應的容器域名,這就使得 Regionserver 在啟動之後向 Master 註冊和向 Zookeeper 叢集註冊的服務名字不一致,導致 Master 中對同一個 Regionserver 登記兩次,造成 Master 與 Regionserver 無法正常通訊,整個叢集無法正常提供服務.
經過我們對原始碼的研究和實驗之後,我們在容器啟動 Regionserver 服務之前修改 /etc/hosts 檔案,將 Kubernetes 對註入的 hostname 資訊遮蔽;這樣的修改讓容器啟動的 HBase 叢集能夠順利啟動並初始化成功,但是也給運維提升了複雜度,因為現在 HBase 提供的 Master 頁現在看到的 Regionserver 都是 IP 形式的記錄,給監控和故障處理帶來了諸多不便.
存在問題
初代架構順利落地,在成功接入了近十個叢集業務之後,這套架構面臨了以下幾個問題:
管理操作業務 HBase 叢集較為繁瑣:
- 需要手動提前確定 HDFS 叢集的儲存,以及申請獨立 Zookeeper 叢集,早期為了省事直接多套 HBase 共享了一套 Zookeeper 叢集,這和我們設計的初衷不符合;
- 容器識別符號和 HBase Master 裡註冊的 regionserver 地址不一致,影響故障定位;
- 單 Regionserver 執行在一個單獨的 ReplicationController (以下簡稱 RC ), 但是擴容縮容為充分利用 RC 的特性,粗暴的採用增加或減少 RC 的方式進行擴容縮容;
HBase 配置:
- 最初的設計缺乏靈活性,與 HBase 服務配置有關的 hbase-site.xml 以及 hbase-env.sh固化在 Docker Image 裡,這種情況下, 如果需要更新大量配置,則需要重新 build 映象;
- 由於最初設計是共享一套 HDFS 叢集作為多 HBase 叢集的儲存,所以與 HDFS 有關的 hdfs-site.xml 和 core-site.xml 配置檔案也被直接配置進了映象. 如果需要在 Kubas service 中上線依賴其他 HDFS 叢集的 HBase,也需要重新構建映象;
HDFS 隔離:
- 隨著接入 HBase 叢集的增多,不同的 HBase 叢集業務對 HDFS 的 IO 消耗有不同的要求,因此有了分離 HBase 依賴的 HDFS 叢集的需求;
- 主要問題源自 Docker 映象對相關配置檔案的固化,與 HDFS 有關的 hdfs-site.xml 和 core-site.xml 配置檔案與相關 Docker 映象對應,而不同 Docker 映象的版本完全由研發人員自己管理,最初版本的實現並未考慮到這些問題;
監控運維:
- 指標資料不充分,堆內堆外記憶體變化,region 以及 table 的訪問資訊都未有提取或聚合
- region 熱點定位較慢,無法在短時間內定位到熱點 region;
- 新增或者下線元件只能透過掃 kubas service 的資料庫來發現相關變更,元件的異常如 regionserver 掉線或重啟,master 切換等不能及時反饋;
重構
為了進一步解決初版架構存在的問題,最佳化 HBase 的管控流程,我們重新審視了已有的架構,並結合 Kubernetes 的新特性,對原有的架構進行升級改造,重新用 Golang 重寫了整個 Kubas 管理系統的服務 (初版使用了 Python 進行開發) ,併在 Kubas 管理系統的基礎上,開發了多個用於監控和運維的基礎微服務,提高了在 Kubernetes 上進行 HBase 叢集部署的靈活性,架構如下圖所示:
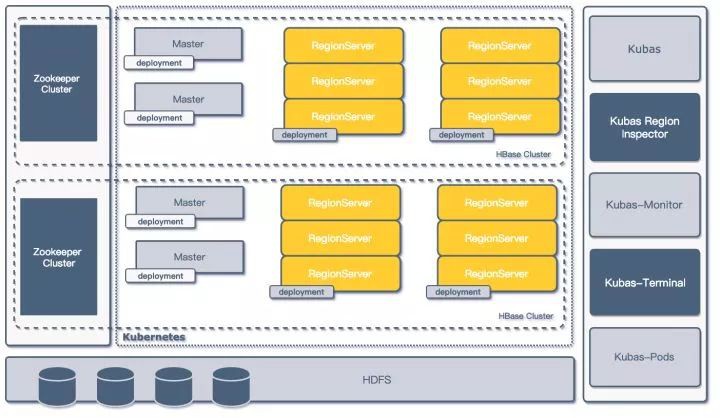
二代架構圖
Deployment & Config Map
Deployment
- Deployment (部署) 是 Kubernetes 中的一個概念,是 Pod 或者 ReplicaSet 的一組更新物件描述,用於取代之前的 ReplicationController. Deployment 繼承了 ReplicationController 的所有功能,並擁有更多的管理新特性;
- 在新的 Kubas 管理系統中,新設計用 Deployment 代替 ReplicationController 做 Pod 的管理,使用一個 Deployment 部署一組 Regionservers 的方式來代替單Regionserver 對應一個 ReplicationController 的設計,提升叢集部署擴縮容管理的靈活性;
- 每一組 Deployment 都會註入各類資訊維度的標簽,如相關叢集的資訊就,服務型別,所屬應用等;

Deployment 部署
ConfigMap
- ConfigMap 是 Kubernetes 用來儲存配置檔案的資源物件,透過 ConfigMap 可以將外部配置在啟動容器之前掛載到容器中的指定位置,並以此為容器中執行的程式提供配置資訊;
- 重構之後管理系統中,所有 HBase 的元件配置都存放至 ConfigMap 之中,系統管理人員會根據需-要預先生成若干 HBase 的配置模板存放到 K8S 系統的 ConfigMap 中;
- 在業務方提供出 HBase 服務申請時,管理人員透過業務資源的需求結合配置模板,為申請的 HBase 叢集元件渲染具體的 hbase-site.xml 以及 hbase-env.sh 等 HBase 配置相關的檔案再存放到 ConfigMap 中;
- 最後在容器啟動時,k8s 會根據 deployment 將 ConfigMap 中的配置檔案 Mount 到配置中指定的路徑中;
- 和 Deployment 的操作類似,每一份 ConfigMap 也都會標記上標簽,將相關的 ConfigMap 和對應的叢集和應用關聯上;
 ConfigMap 存檔
ConfigMap 存檔
元件引數配置
在引入了 ConfigMap 功能之後,之前建立叢集的請求資訊也隨之改變.
RequestData
{
“name”: “performance-test-rmwl”,
“namespace”: “online”,
“app”: “kubas”,
“config_template”: “online-example-base.v1”,
“status”: “Ready”,
“properties”: {
“hbase.regionserver.codecs”: “snappy”,
“hbase.rootdir”: “hdfs://zhihu-example-online:8020/user/online-tsn/performance-test-rmwl”,
“hbase.zookeeper.property.clientPort”: “2181”,
“hbase.zookeeper.quorum”: “zookeeper01,zookeeper02,zookeeper03”,
“zookeeper.znode.parent”: “/performance-test-rmwl”
},
“client_type”: “java”,
“cluster_uid”: “k8s-example-hbase—performance-test-rmwl—example”
}
其中 config_template 指定了該叢集使用的配置資訊模板,之後所有和該 HBase 叢集有關的元件配置都由該配置模板渲染出具體配置.
config_template 中還預先約定了 HBase 元件的基礎執行配置資訊,如元件型別,使用的啟動命令,採用的映象檔案,初始的副本數等.
servers:
{
“master”: {
“servertype”: “master”,
“command”: “service hbase-master start && tail -f /var/log/hbase/hbase-hbase-master.log”,
“replicas”: 1,
“image”: “dockerimage.zhihu.example/apps/example-master:v1.1”,
“requests”: {
“cpu”: “500m”,
“memory”: “5Gi”
},
“limits”: {
“cpu”: “4000m”
}
},
}
Docker 映象檔案配合 ConfigMap 功能,在預先約定的路徑方式存放配置檔案資訊,同時在真正的 HBase 配置路徑中加入軟鏈檔案.
RUN mkdir -p /data/hbase/hbase-site
RUN mv /etc/hbase/conf/hbase-site.xml /data/hbase/hbase-site/hbase-site.xml
RUN ln -s /data/hbase/hbase-site/hbase-site.xml /etc/hbase/conf/hbase-site.xml
RUN mkdir -p /data/hbase/hbase-env
RUN mv /etc/hbase/conf/hbase-env.sh /data/hbase/hbase-env/hbase-env.sh
RUN ln -s /data/hbase/hbase-env/hbase-env.sh /etc/hbase/conf/hbase-env.sh
構建流程
結合之前對 Deployment 以及 ConfigMap 的引入,以及對 Dockerfile 的修改,整個 HBase 構建流程也有了改進:

HBase on Kubernetes 構建流程
- 編製相關的 Dockerfile 並構建基礎的 HBase 元件映象;
- 為將要建立的 HBase 構建基礎屬性配置模板,訂製基礎資源,這部分可以透過 Kubas API 在 Kubernetes 叢集中建立 ConfigMap;
- 具體建立部署叢集時,透過呼叫 Kubas API, 結合之前構建的 ConfigMap 模板,渲染出 HBase 叢集中各類元件的詳細 ConfigMap, 然後在 Kubernetes 叢集中構建 Deployment;
- 最終透過之前構建好的映象載入元件 ConfigMap 中的配置,完成在 Kubernetes Node 中執行的一個 HBase 元件容器;
透過結合 K8S 的 ConfigMap 功能的配置模板,以及 Kubas API 呼叫,我們就可以在短時間部署出一套可用的 HBase 最小叢集 (2Master + 3RegionServer + 2Thriftserver), 在所有宿主機 Host 都已經快取 Docker 映象檔案的場景下,部署並啟動一整套 HBase 叢集的時間不超過 15 秒.
同時在缺少專屬前端控制檯的情況下,可以完全依託 Kubernetes dashboard 完成 HBase 叢集元件的擴容縮容,以及元件配置的查詢修改更新以及重新部署.
資源控制
在完成重構之後,HBase 服務面向知乎內部業務進行開放,短期內知乎 HBase 叢集上升超過30+ 叢集,伴隨著 HBase 叢集數量的增多,有兩個問題逐漸顯現:
- 運維成本增高: 需要運維的叢集逐漸增高;
- 資源浪費:這是因為很多業務的業務量並不高,但是為了保證 HBase 的高可用,我們至少需要提供 2 個 Master + 3 個 Region Server,而往往 Master 的負載都非常低,這就造成了資源浪費.
為瞭解決如上的兩個問題,同時又不能打破資源隔離的需求,我們將 HBase RSGroup 功能加入到了HBase 平臺的管理系統中.
最佳化後的架構如下:

RSGroup 的使用
由於平臺方對業務 HBase 叢集的管理本身就具有隔離性,所以在進行更進一步資源管理的時候,平臺方採用的是降級的方式來管理 HBase 叢集,透過監聽每個單獨叢集的指標,如果業務叢集的負載在上線一段時間後低於閾值,平臺方就會配合業務方,將該 HBase 叢集遷移到一套 Mixed HBase 叢集上.
同時如果在 Mixed HBase 叢集中執行的某個 HBase 業務負載增加,並持續一段時間超過閾值後,平臺方就會考慮將相關業務提升至單獨的叢集.
多 IDC 最佳化
隨著知乎業務的發展和擴大,知乎的基礎架構逐漸升級至多機房架構,知乎 HBase 平臺管理方式也在這個過程中進行了進一步升級,開始構建多機房管理的管理方式;基本架構如下圖所示:

多 IDC 訪問方式
- 業務 HBase 叢集分別在多個 IDC 上執行,由業務確定 IDC 機房的主從方式,業務的從 IDC 叢集資料透過平臺方的資料同步元件進行資料同步;
- 各 IDC 的 Kubas 服務主要負責對本地 Kubernetes 叢集的具體操作,包括 HBase 叢集的建立刪除管理,regionserver 的擴容等 HBase 元件的管理操作,Kubas 服務部署與機房相關,僅對接部署所在機房的 K8S 叢集;
- 各 IDC 的 Kubas 服務向叢集發現服務上報本機房叢集資訊,同時更新相關叢集主從相關資訊;
- 業務方透過平臺方封裝的 Client SDK 對多機房的 HBase 叢集進行訪問,客戶端透過叢集發現服務可以確定 HBase 叢集的主從關係,從而將相關的讀寫操作分離,寫入修改訪問可以透過客戶端指向主 IDC 的叢集;
- 跨機房間的資料同步採用了自研的 HBase Replication WALTransfer 來提供增量資料的同步;
資料同步
在各類業務場景中,都存在跨 HBase 叢集的資料同步的需求,比如資料在離線 HBase 叢集和線上叢集同步,多 IDC 叢集資料同步等;對於 HBase 的資料同步來說,分為全量複製和增量複製兩種方式;

HBase 資料同步
在知乎 HBase 平臺中,我們採用兩種方式進行 HBase 叢集間的資料同步
HBase Snapshot:
全量資料複製我們採用了 HBase Snapshot 的方式進行;主要應用在離線資料同步線上資料的場景;
WALTransfer:
主要用於 HBase 叢集之間的的增量資料同步;增量複製我們沒有採用 HBase Replication,相關同步方式我們透過自研的 WALTransfer 元件來對 HBase 資料進行增量同步;
WALTransfer 透過讀取源資料 HBase 叢集提供 WAL 檔案串列,於 HDFS 叢集中定位對應的 WAL 檔案,將 HBase 的增量資料按序寫入到目的叢集,相關的細節我們會在以後的文章中詳細解析
監控
從之前重構後的架構圖上我們可以看到,在 Kubas 服務中我們添加了很多模組,這些模組基本屬於 HBase 平臺的監控管理模組.
Kubas-Monitor 元件
基本的監控模組,採用輪詢的方式發現新增 HBase 叢集,透過訂閱 Zookeeper 叢集發現 HBase 叢集 Master 以及 Regionserver 組.
採集 Regionserver Metric 中的資料,主要採集資料包括:
- region 的資訊,上線 region 數量,store 的數量、storefile 的大小、storefileindex 的大小,讀取時 memstore 命中的次數和缺失次數;
- blockcache 的資訊,例如 blockcache 中使用多少、空閑多少、累計的缺失率、命中率等.
- 讀寫請求的統計資訊,例如最大最小讀寫響應時間,讀寫的表分佈、讀寫資料量、讀寫失敗次數等;
- compact 與 split 的操作資訊,例如佇列的長度、操作次數和時間等;
- handler 的資訊,例如佇列長度、處於活躍 handler 的數量以及活躍的 reader 數量;
其他維度的指標如容器 CPU 以及 Mem 佔用來自 Kubernetes 平臺監控,磁碟 IO,磁碟佔用等來自主機監控
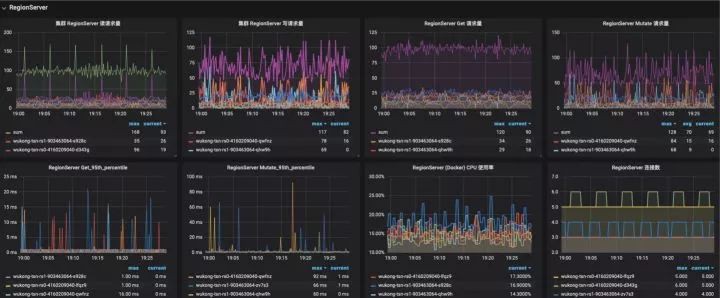
HBase 部分監控
Kubas-Region-Inspector 元件
- 採集 HBase 表 Region 資訊,透過 HBase API 介面,獲取每個 HBase Region 的資料統計資訊,並將 Region 資料聚合成資料表資訊;
- 透過呼叫開源元件形成 HBase 叢集 Region 分佈的圖表,對 Region 熱點進行定位;
 HBase Region 分佈監控
HBase Region 分佈監控
透過以上模組採集的監控資訊,基本可以描述在 Kubernetes 上執行的 HBase 叢集的狀態資訊,並能夠輔助運維管理人員對故障進行定位排除.
Future Work
隨著公司業務的快速發展,知乎的 HBase 平臺業務同時也在不斷的迭代最佳化,短期內我們會從以下幾個方向進一步提升知乎 HBase 平臺的管理服務能力:
- 提升叢集安全穩定性. 加入 HBase 許可權支援,進一步提升多租戶訪問下的安全隔離性;
- 使用者叢集構建定製化. 透過提供使用者資料管理系統,向業務使用者開放 HBase 構建介面,這樣業務使用者可以自行構建 HBase 叢集,新增 Phoniex 等外掛的支援;
- 運維檢測自動化. 自動對叢集擴容,自動熱點檢測以及轉移等;
寫在最後
HBase 在知乎的推廣應用從 2017 年開始,平臺架構經過了若干個版本的迭代最終穩定,在這裡感謝 @bzy 在前期的鋪墊,感謝 @高勛 為資源隔離化和資源利用率最佳化所做的工作. 特別感謝 @王政英 在使用 HBase 服務期間給我們提供的建議和 downtime.
知乎核心架構團隊負責解決知乎業務複雜度和併發規模提升給核心資源排程以及資料儲存架構帶來的問題以及挑戰,隨著知乎使用者和業務規模的快速增長,以及基礎架構複雜度的持續提升,團隊面臨的技術挑戰也越來越多,目前正在持續實施多機房異地多活的架構改造和資源的最佳化,努力保障和提升知乎核心架構的質量和穩定性,歡迎對技術感興趣、渴望技術挑戰的小夥伴與 neuron@zhihu.com /baiyuqing@zhihu.com 聯絡.
Reference
[1] 知乎基於 Kubernetes 的 Kafka 平臺的設計和實現
https://zhuanlan.zhihu.com/p/36366473
[2] 知乎容器平臺演進及與大資料融合實踐
https://mp.weixin.qq.com/s/lt3kr4iFi8hk44hT6HzPag
[3] Kubernetes
http://kubernetes.io/
[4] Building online hbase cluster of zhihu based on kubernetes
http://www.slideshare.net/HBaseCon/hbaseconasia2017-building-online-hbase-cluster-of-zhihu-based-on-kubernetes
相關閱讀:
技術原創及架構實踐文章,歡迎透過公眾號選單「聯絡我們」進行投稿。轉載請註明來自高可用架構「ArchNotes」微信公眾號及包含以下二維碼。
高可用架構
改變網際網路的構建方式

長按二維碼 關註「高可用架構」公眾號

