,有趣實用的分散式架構頻道。
本期是 SOFAChannel 第三期,SOFARPC 效能最佳化(下),進一步分享 SOFARPC 在效能上做的一些最佳化。
本期你將收穫:
如何控制序列化和反序列化的時機;
如何透過執行緒池隔離,避免部分介面對整體效能的影響;
如何進行客戶端權重調節,最佳化啟動期和故障時的效能;
服務端 Server Fail Fast 支援,減少無效操作;
在 Netty 記憶體操作中,如何最佳化記憶體使用。
歡迎加入直播互動釘釘群:23127468,不錯過每場直播。

大家好,今天是 SOFAChannel 第三期,歡迎大家觀看。
我是來自螞蟻金服中介軟體的雷志遠,花名碧遠,目前負責 SOFARPC 框架的相關工作。在上一期直播中,給大家介紹了 SOFARPC 效能最佳化方面的關於自定義協議、Netty 引數最佳化、動態代理等的最佳化。
往期的直播回顧,可以在文末獲取。
本期互動中獎名單:
@司馬懿 @鄧從寶 @霧淵,請回覆公眾號進行禮品領取
今天我們會從序列化控制、記憶體操作最佳化、執行緒池隔離等方面來介紹剩餘的部分。
序列化最佳化
上次介紹了序列化方式的選擇,這次主要介紹序列化和反序列化的時機、處理的位置以及這樣的好處,如避免佔用 IO 執行緒,影響 IO 效能等。
上一節,我們介紹的 BOLT 協議的設計,回顧一下:

可以看到有這三個地方不是透過原生型別直接寫的:ClassName,Header,Content 。其餘的,例如 RequestId 是直接寫的,或者說跟具體請求物件無關的。所以在選擇序列化和反序列化時機的時候,我們根據自己的需求,也精確的控制了協議以上三個部分的時機。
對於序列化
serializeClazz 是最簡單的:
byte[] clz = this.requestClass.getBytes(Configs.DEFAULT_CHARSET);直接將字串轉換成 Byte 陣列即可,跟具體的任何序列化方式,比如跟採用 Hessian 還是 Pb 都是無關的。
serializeHeader 則是序列化 HeaderMap。這時候因為有了前面的 requestClass,就可以根據這個名字拿到SOFARPC 層或者使用者自己註冊的序列化器。然後進行序列化 Header,這個對應 SOFARPC 框架中的 SofaRpcSerialization 類。在這個類裡,我們可以自由使用本次傳輸的物件,將一些必要資訊提取到Header 中,併進行對應的編碼。這裡也不跟具體的序列化方式有關,是一個簡單 Map 的序列化,寫 key、寫 value、寫分隔符。有興趣的同學可以直接看原始碼。
原始碼連結:
https://github.com/alipay/sofa-bolt/blob/531d1c0d872553d92fc55775565b3f7be8661afa/src/main/java/com/alipay/remoting/rpc/protocol/RpcRequestCommand.java#L66
serializeContent 序列化業務物件的資訊,這裡 RPC 框架會根據本次使用者配置的資訊決定如何操作序列化物件,是呼叫 Hessian 還是呼叫 Pb 來序列化。
至此,完成了序列化過程。可以看到,這些操作實際上都是在業務發起的執行緒裡面的,在請求傳送階段,也就是在呼叫 Netty 的寫介面之前,跟 IO 執行緒池還沒什麼關係,所以都會在業務執行緒裡先做好序列化。
對於反序列化
介紹完序列化,反序列化的時機就有一些差異,需要重點考慮。在服務端的請求接收階段,我們有 IO 執行緒、業務執行緒兩種執行緒池。為了最大程度的配合業務特性、保證整體吞吐,SOFABolt 設計了精細的開關來控制反序列化時機。
具體選擇邏輯如下:

使用者請求處理器圖
體現在程式碼的這個類中。
com.alipay.remoting.rpc.protocol.RpcRequestProcessor#process
從上圖可以看到 反序列化 大致分成以下三種情況,各個適用於不同的場景。
| IO 執行緒池動作 | 業務執行緒池 | 使用場景 |
|
反序列化 ClassName |
反序列化 Header 和 Content 處理業務 |
一般 RPC 預設場景。IO 執行緒池識別出來當前是哪個類,呼叫使用者註冊的對應處理器 |
|
反序列化 ClassName 和 Header |
僅反序列化 Content 和業務處理 |
希望根據 Header 中的資訊,選擇執行緒池,而不是直接註冊的執行緒池 |
|
一次性反序列化 ClassName、Header 和 Content,並直接處理 |
沒有邏輯 |
IO 密集型的業務 |
執行緒池隔離
經過前面的介紹,可以瞭解到,由於業務邏輯通常情況下在 SOFARPC 設定的一個預設執行緒池裡面處理,這個執行緒池是公用的。也就是說, 對於一個應用,當他作為服務端時,所有的呼叫請求都會在這個執行緒池中處理。
舉個例子:如果應用 A 對外提供兩個介面,S1 和 S2,由於 S2 介面的效能不足,可能是下游系統的拖累,會導致這個預設執行緒池一直被佔用,無法空閑出來被其他請求使用。這會導致 S1 的處理能力受到影響,對外報錯,執行緒池已滿,導致整個業務鏈路不穩定,有時候 S1 的重要性可能比 S2 更高。
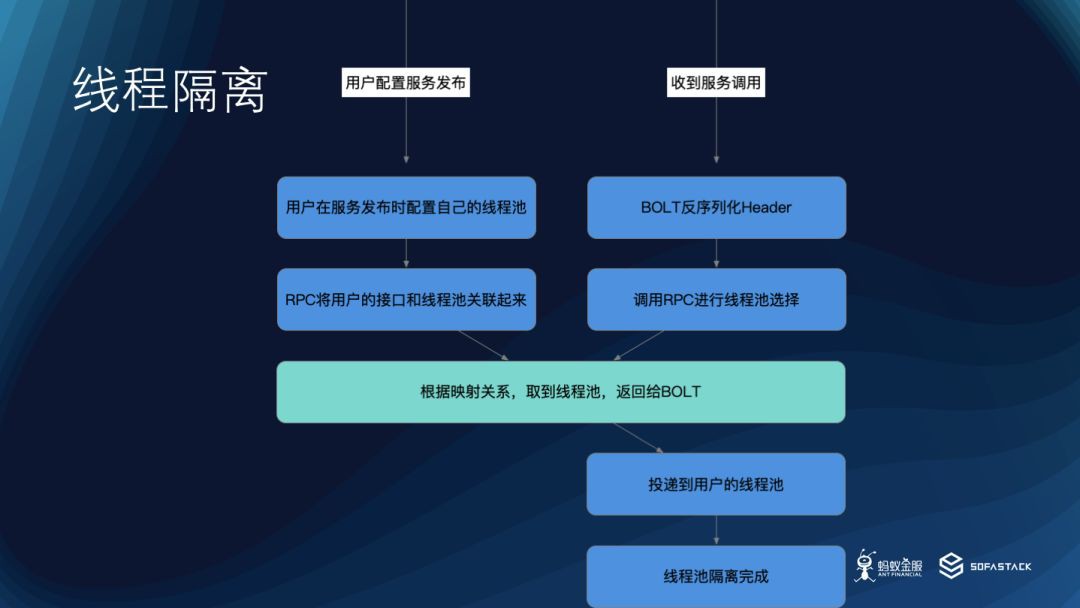
執行緒池隔離圖
因此,基於上面的設計,SOFARPC 框架允許在序列化的時候,根據使用者對當前介面的執行緒池配置將介面和服務資訊放到 Header 中,反序列化的時候,根據這個 Header 資訊選擇到使用者自定義的執行緒池。這樣,使用者可以針對不同的服務介面配置不同的業務執行緒池,可以避免部分介面對整個效能的影響。在系統介面較多的時候,可以有效的提高整體的效能。
記憶體操作最佳化
介紹完執行緒池隔離之後,我們介紹一下 Netty 記憶體操作的一些註意事項。在 Netty 記憶體操作中,如何儘量少的使用記憶體和避免垃圾回收,來最佳化效能。先來看一些基礎概念。
記憶體基礎
在 JVM 中 記憶體可分為兩大塊,一個是堆記憶體,一個是直接記憶體。
堆記憶體是 JVM 所管理的記憶體。所有的物件實體都要在堆上分配,垃圾收集器可以在堆上回收垃圾,有不同的執行條件和回收區域。
JVM 使用 Native 函式在堆外分配記憶體。為什麼要在堆外分配記憶體?主要因為在堆上的話, IO 操作會涉及到頻繁的記憶體分配和銷毀,這會導致 GC 頻繁,對效能會有比較大的影響。
註意:直接分配本身也並不見得效能有多好,所以還要有池的概念,減少頻繁的分配。
因此 JVM 中的直接記憶體,存在堆記憶體中的其實就是 DirectByteBuffer 類,它本身其實很小,真的記憶體是在堆外,透過 JVM 堆中的 DirectByteBuffer 物件作為這塊記憶體的取用進行操作。直接記憶體不會受到 Java 堆的限制,只受本機記憶體影響。當然可以設定最大大小。也並不是 Direct 就完全跟 Heap 沒什麼關係了,因為堆中的這個物件持有了堆外的地址,只有這個物件被回收了,直接記憶體才能釋放。
其中 DirectByteBuffer 經過幾次 young gc 之後,會進入老年代。當老年代滿了之後,會觸發 Full GC。
因為本身很小,很難佔滿老年代,因此基本不會觸發 Full GC,帶來的後果是大量堆外記憶體一直佔著不放,無法進行記憶體回收。所以這裡要註意 -XX:+DisableExplicitGC 不要關閉。
Pool 還是 UnPool
Netty 從 4.1.x 開始,非 Android 平臺預設使用池化(PooledByteBufAllocator)實現,能最大程度的減少記憶體碎片。另外一種方式是非池化(UnpooledByteBufAllocator),每次傳回一個新實體。可以檢視 io.netty.buffer.ByteBufUtil 這個工具類即可。
在 4.1.x 之前,由於 Netty 無法確認 Pool 是否存在記憶體洩漏,所以並沒有開啟。目前,SOFARPC 的 SOFABolt 中目前對於 Pool 和 Upool 是透過引數決定的,預設還是 Unpool。使用 Pool 會有更好的效能資料。在 SOFABolt 1.5.0 中進行了開啟,如果新開發 RPC 框架,可以進行預設開啟。SOFARPC 在下個版本會進行開啟。
可能大家對這個的感受不是很直觀,因此我們提供了一個測試 Demo。
註意:
-
如果 DirectMemory 設定過小,是不會啟用 Pooled 的。
-
另外需要註意 PooledByteBufAllocator 的 MaxDirectMemorySize 設定。本機驗證的話,大概需要 96M 以上,在 Demo中有說明。
-
Demo地址:
https://github.com/leizhiyuan/rpcchannel
DEFAULT_NUM_DIRECT_ARENA = Math.max(0,SystemPropertyUtil.getInt("io.netty.allocator.numDirectArenas",(int) Math.min(defaultMinNumArena,PlatformDependent.maxDirectMemory() / defaultChunkSize / 2 / 3)));
Direct 還是 Heap
目前 Netty 在 write 的時候預設是 Direct ,而在 read 到位元組流的時候會進行選擇,可以檢視如下程式碼,
io.netty.channel.nio.AbstractNioByteChannel.NioByteUnsafe#read框架所採取的策略是:如果所執行的平臺提供了 Unsafe 相關的操作,則呼叫 Unsafe 在 Direct 區域進行記憶體分配,否則在 Heap 上進行分配。
有興趣的同學可以透過 Demo 3 中的示例來 debug,斷點打在如下的位置,就可以看到 Netty 選擇的過程。
io.netty.buffer.AbstractByteBufAllocator#ioBuffer(int)正常 RPC 的開發中,基本上都會在 Direct 區域進行記憶體分配,在 Heap 中進行記憶體分配本身也不符合 RPC 的效能要求。因為 GC 有比較大的效能影響,而 GC 在執行中,業務的程式碼影響比較大,可控性不強。
其他註意事項
一般來說,我們不會主動去分配 ByteBuf ,只要去操作讀寫 ByteBuf。所以:
-
使用 Bytebuf.forEachByte() ,傳入 Processor 來代替迴圈 ByteBuf.readByte() 的遍歷操作,需要避免rangeCheck() 。因為每次 readByte() 都不是讀一個位元組這麼簡單,首先要判斷 refCnt() 是否大於0,然後再做範圍檢查防止越界。getByte(i=int) 又有一些檢查函式,JVM 沒有內連的時候,效能就有一定的損耗。
-
使用 CompositeByteBuf 來避免不必要的記憶體複製。在操作一些協議包資料拼接時會比較有用,比如在 Service Mesh 的場景,如果我們需要改變 Header 中的 RequestId,然後和原始的 Body 資料拼接時這個操作就會非常有用。
-
如果要讀1個 int , 用 Bytebuf.readInt() , 不要使用 Bytebuf.readBytes(buf, 0, 4) 。這樣就能避免一次記憶體複製,其他 long 等同理,畢竟還要轉換回來,效能也更好。在 Demo 4 中有體現。
-
RecyclableArrayList ,在出現頻繁 new ArrayList 的場景可考慮使用 。例如:SOFABolt 在批次解包時使用了 RecyclableArrayList ,可以讓 Netty 來回收。上期分享中有介紹到這個功能,詳情可見文末上期回顧連結。
-
避免複製,為了失敗時重試,假設要保留內容稍後使用。不想 Netty 在傳送完畢後把 buffer 就直接釋放了,可以用 copy() 複製一個新的 ByteBuf。但是下麵這樣更高效, BytebufnewBuf=oldBuf.duplicate().retain() ;只是複製出獨立的讀寫索引, 底下的 ByteBuffer 是共享的,同時將 ByteBuffer 的計數器+1,這樣可以避免釋放,而不是透過複製來阻止釋放。
- 最後出現問題,使用 PooledBytebuf 時要善於利用 -Dio.netty.leakDetection.level 引數,可以定位記憶體洩漏出現的資訊。
客戶端權重調節
下麵,我們說一下權重。在路由階段的權重調節,我們通常能夠拿到很多可以呼叫的服務端。這時候通常情況下,最好的負載均衡演演算法應該是隨機演演算法。當然如果一些特殊的需求,比如希望同樣的引數落到固定的機器組,一致性Hash 也是可以選擇的。
不過,在系統規模到達很高的情況下,需要對啟動期間和單機故障發生期間的呼叫有一定的調整。
啟動期權重調節
如果應用剛剛啟動完成,此時 JIT 的最佳化以及其他相關元件還未充分預熱完成。此時,如果立刻收到正常的流量呼叫可能會導致當前機器處理非常緩慢,甚至直接當機無法正常啟動。這時需要的操作是:先關閉流量,然後重啟,之後開放流量。
為此,SOFARPC 允許使用者在釋出服務時,設定當前服務在啟動後的一段時間內接受的權重數值,預設是100。

權重負載均衡圖
如上圖所示,假設使用者設定了某個服務 A 的啟動預熱時間為 60s,期間權重是10,則 SOFARPC 在呼叫的時候會進行如圖所示的權重調節。
這裡我們假設有三個服務端,兩個過了啟動期間,另一個還在啟動期間。在負載均衡的時候,三個伺服器會根據各自的權重佔總權重的比例來進行負載均衡。這樣,在啟動期間的服務方就會收到比較少的呼叫,防止打垮服務端。當過了啟動期間之後,會使用預設的 100 權重進行負載均衡。這個在 Demo 5 中有示例。
執行時單機故障權重調節
除了啟動期間保護服務端之外,還有個情況,是服務端在執行期間假死,或者其他故障。現象會是:服務發現中心認為機器存活,所以還是會給客戶端推送這個地址,但是呼叫一直超時,或者一直有其他非業務異常。這種情況下,如果還是呼叫,一方面會影響鏈路的效能,因為執行緒佔用等;另一方面會有持續的報錯。因此,這種情況下還需要透過單機故障剔除的功能,對異常機器的權重進行調整,最終可以在負載均衡的時候生效。
對於單機故障剔除,本次我們不做為重點講解,有興趣的同學可以點選連結檢視相關文章介紹。
Server Fail Fast 支援
服務端根據客戶端的超時時間來決定是否丟棄已經超時的結果,並且不傳回,以減少網路資料以及減少不必要的處理,帶來效能提升。

這裡面分兩種。
第一種是 SOFABolt 在網路層的 Server Fail Fast
對於 SOFABolt 層面, SOFABolt 會在 Decode 完位元組流之後,記錄一個開始時間,然後在準備分發給 RPC 的業務執行緒池之前,會比較一下當前時間,是否已經超過了使用者的超時時間。如果超過了,直接丟棄,不分發給RPC,也不會給客戶端響應。
第二種是 SOFARPC 在業務層的 Server Fail Fast
如果 SOFABolt 分發給 SOFARPC 的時候,還沒有超時,但是 SOFARPC 走完了服務端業務邏輯之後,發現已經超時了。這時候,可以不傳回業務結果,直接構造異常超時結果,資料更少,但結果是一樣的。
註意:這裡會有個副作用,雖然服務端處理其實是完成了,但是日誌裡可能會列印一個錯誤碼,需要根據實際情況開啟。
之後我們會開放引數允許,使用者設定。
使用者可調節引數
對使用者的配置,大家都可以透過 com.alipay.sofa.rpc.boot.config.SofaBootRpcProperties 這個類來檢視。
使用方式和標準的 SpringBoot 工程是一致,開箱即可。
如果是特別特殊的需求,或者並不使用 Spring 作為開發框架,我們也允許使用者透過定製 rpc-config.json 檔案來進行調整,包括動態代理生成方式、預設的 tracer、超時時間的控制、時機序列化黑名單是否開啟等等。這些引數在有特殊需求的情況下可以最佳化效能。
執行緒池調節
以業務執行緒數為例,目前預設執行緒池,20核心執行緒數,200最大執行緒數,0佇列。可以透過以下配置項來調整:
com.alipay.sofa.rpc.bolt.thread.pool.core.size # bolt 核心執行緒數com.alipay.sofa.rpc.bolt.thread.pool.max.size # bolt 最大執行緒數com.alipay.sofa.rpc.bolt.thread.pool.queue.size # bolt 執行緒池佇列
這裡執行緒池的設定上,主要關註佇列大小這個設定項。如果佇列數比較大,會導致如果上游系統處理能力不足的時候,請求積壓在佇列中,等真正處理的時候已經過了比較長的時間,而且如果請求量非常大,會導致之後的請求都至少等待整個佇列前面的資料。
所以如果業務是一個延遲敏感的系統, 建議不要設定佇列大小;如果業務可以接受一定程度的執行緒池等待,可以設定。這樣,可以避過短暫的流量高峰。
總結
SOFARPC 和 SOFABolt 在效能最佳化上做了一些工作,包括一些比較實際的業務需求產生的效能最佳化方式。兩篇文章不足以介紹更多的程式碼實現細節和方式。錯過上期直播的可以點選文末連結進行回顧。
相信大家在 RPC 或者其他中介軟體的開發中,也有自己獨到的效能最佳化方式,如果大家對 RPC 的效能和需求有自己的想法,歡迎大家在釘釘群(搜尋群號即可加入:23127468)或者 Github 上與我們討論交流。
到此,我們 SOFAChannel 的 SOFARPC 系列主題關於效能最佳化相關的兩期分享就介紹完了,感謝大家。
關於 SOFAChannel 有想要交流的話題可以在文末留言或者在公眾號留言告知我們。
本期影片回顧
https://tech.antfin.com/activities/245
往期直播精彩回顧
-
SOFAChannel#2 SOFARPC 效能最佳化實踐(上):
https://tech.antfin.com/activities/244
-
https://tech.antfin.com/activities/148
相關參考連結
-
Demo 連結:
https://github.com/leizhiyuan/rpcchannel
-
bolt enable Pooled:
https://github.com/alipay/sofa-bolt/issues/78
-
Netty pooled release note:
https://netty.io/wiki/new-and-noteworthy-in-4.1.html#pooledbytebufallocator-as-the-default-allocator
講師觀點


長按關註,不錯過每一場技術直播
歡迎大家共同打造 SOFAStack https://github.com/alipay
