有位學弟想讓我說說編譯和連結的簡單過程,我覺得幾句話簡單說的話也沒什麼意思,索性寫篇博文稍微詳細的解釋一下吧。其實詳細的流程在經典的《Linkers and Loaders》和《深入理解計算機系統》中均有描述,也有國產的諸如《程式員的自我修養——連結、裝載與庫》等大牛著作。不過,我想大家恐怕很難有足夠的時間去研讀這些厚如詞典的書籍。正巧我大致翻閱過其中的部分章節,乾脆也融入這篇文章作為補充吧。
我的環境:Fedora 16 i686 kernel-3.6.11-4 gcc 4.6.3
其實MSVC的編譯器在編譯過程中的流程是差不多的,只是具體呼叫的程式和使用的引數不同罷了。不過為了描述的流暢性,我在行文中不會涉及MSVC的具體操作,使用Windows的同學可以自行搜尋相關指令和引數。但是作為Linuxer,我還是歡迎大家使用Linux系統。如果大家確實需要,我會擠時間在附言中給出MSVC中相對應的試驗方法。
閑話不多說了,我們進入正題。在正式開始我們的描述前,我們先來引出幾個問題:
C語言程式碼為什麼要編譯後才能執行?整個過程中編譯器都做了什麼?
C程式碼中經常會包含頭檔案,那頭檔案是什麼?C語言庫又是什麼?
有人說main函式是C語言程式的入口,是這樣嗎?難道就不能把其它函式當入口?
不同的作業系統上編譯好的程式可以直接複製過去執行嗎?
如果上面的問題你都能回答的話,那麼後文就不用再看下去了。因為本文是純粹的面向新手,所以註定了不會寫的多麼詳細和深刻。如果你不知道或者不是很清楚,那麼我們就一起繼續研究吧。
我們就以最經典的HelloWorld程式為例開始吧。我們先使用vim等文字編輯器寫好程式碼,接著在終端執行命令 gcc HelloWorld.c -o HelloWorld 輸出了可執行檔案HelloWorld,最後我們在終端執行 ./HelloWorld,順利地顯示了輸出結果。

可是,簡單的命令背後經過了什麼樣的處理過程呢?gcc真的就“直接”生成了最後的可執行檔案了嗎?當然不是,我們在gcc編譯命令列加上引數 –verbose要求gcc輸出完整的處理過程(命令列加上 -v 也行),我們看到了一段較長的過程輸出。

輸出結果我們就不完整截圖了,大家有興趣可以自己試驗然後試著分析整個流程。
一圖勝千言,我們先上一張圖吧。這是gcc編譯過程的分解圖,我在網上找不到滿意的,就自己畫了一張簡單的,大家將就著看吧。

從圖中我們大致可以看出gcc處理HelloWorld.c的大致過程:
預處理(Prepressing)—>編譯(Compilation)—>彙編(Assembly)—>連結(Linking)
括號中我註明瞭各個過程中實際執行任務的程式名稱:前處理器cpp、編譯器cc1、彙編器as以及最後的聯結器ld。
我們一步一步來看,首先是預處理,我們看看預處理階段對程式碼進行了哪些處理。
我們在終端輸入指令 gcc -E HelloWorld.c -o HelloWorld.i,然後我們開啟輸出檔案。
首先是大段大段的變數和函式的宣告,汗..我們的程式碼哪裡去了?我們在vim的普通樣式中按下shift+g(大寫G)來到最後,終於在幾千行以後看到了我們可憐兮兮的幾行程式碼。

前面幾千行是什麼呢?其實它就是 /usr/include/stdio.h 檔案的所有內容,前處理器把所有的#include替換為實際檔案的內容了。這個過程是遞迴進行的,所以stdio.h裡面的#include也被實際內容所替換了。
而且我在HelloWorld.c裡面的所有註釋被前處理器全部刪除了。就連printf陳述句前的Tab縮排也被替換為一個空格了,顯得程式碼都不美觀了。
時間關係,我們就不一一試驗處理的內容了,我直接給出前處理器處理的大致範圍吧。
展開所有的宏定義並刪除 #define
處理所有的條件編譯指令,例如 #if #else #endif #ifndef …
把所有的 #include 替換為頭檔案實際內容,遞迴進行
把所有的註釋 // 和 / / 替換為空格
新增行號和檔案名標識以供編譯器使用
保留所有的 #pragma 指令,因為編譯器要使用
……
基本上就是這些了。在這裡我順便插播一個小技巧,在程式碼中有時候宏定義比較複雜的時候我們很難判斷其處理後的結構是否正確。這個時候我們呢就可以使用gcc的-E引數輸出處理結果來判斷了。
前文中我們提到了頭檔案中放置的是變數定義和函式宣告等等內容。這些到底是什麼東西呢?其實在比較早的時候呼叫函式並不需要宣告,後來因為“筆誤”之類的錯誤實在太多,造成了連結期間的錯誤過多,所有編譯器開始要求對所有使用的變數或者函式給出宣告,以支援編譯器進行引數檢查和型別匹配。頭檔案包含的基本上就是這些東西和一些預先的宏定義來方便程式員程式設計。其實對於我們的HelloWorld.c程式來說不需要這個龐大的頭檔案,只需要在main函式前宣告printf函式,不需要#include
宣告如下:
|
|
這個大家就自行測試吧。另外再補充一點,gcc其實並不要求函式一定要在被呼叫之前定義或者宣告(MSVC不允許),因為gcc在處理到某個未知型別的函式時,會為其建立一個隱式宣告,並假設該函式傳回值型別為int。但gcc此時無法檢查傳遞給該函式的引數型別和個數是否正確,不利於編譯器為我們排除錯誤(而且如果該函式的傳回值不是int的話也會出錯)。所以還是建議大家在函式呼叫前,先對其定義或宣告。
預處理部分說完了,我們接著看編譯和彙編。那麼什麼是編譯?一句話描述:編譯就是把預處理之後的檔案進行一系列詞法分析、語法分析、語意分析以及最佳化後生成的相應彙編程式碼檔案。這一部分我們不能展開說了,一來我沒有系統學習過編譯原理的內容不敢信口開河,二來這部分要是展開去說需要很厚很厚的一本書了,細節大家就自己學習《編譯原理》吧,相關的資料自然就是經典的龍書、虎書和鯨書了。
gcc怎麼檢視編譯後的彙編程式碼呢?命令是 gcc -S HelloWorld.c -o HelloWorld.s,這樣輸出了彙編程式碼檔案HelloWorld.s,其實輸出的檔案名可以隨意,我是習慣使然。順便說一句,這裡生成的彙編是AT&T;風格的彙編程式碼,如果大家更熟悉Intel風格,可以在命令列加上引數 -masm=intel ,這樣gcc就會生成Intel風格的彙編程式碼了(如圖,這個好多人不知道哦)。不過gcc的行內彙編只支援AT&T;風格,大家還是找找資料學學AT&T;風格吧。

再下來是彙編步驟,我們繼續用一句話來描述:彙編就是將編譯後的彙編程式碼翻譯為機器碼,幾乎每一條彙編指令對應一句機器碼。
這裡其實也沒有什麼好說的了,命令列 gcc -c HelloWorld.c 可以讓編譯器只進行到生成標的檔案這一步,這樣我們就能在目錄下看到HelloWorld.o檔案了。
Linux下的可執行檔案以及標的檔案的格式叫作ELF(Executable Linkable Format)。其實Windows下的PE(Portable Executable)也好,ELF也罷,都是COFF(Common file format)格式的一種變種,甚至Windows下的標的檔案就是以COFF格式去儲存的。不同的作業系統之間的可執行檔案的格式通常是不一樣的,所以造成了編譯好的HelloWorld沒有辦法直接複製執行,而需要在相關平臺上重新編譯。當然了,不能執行的原因自然不是這一點點,不同的作業系統介面(windows API和Linux的System Call)以及相關的類庫不同也是原因之一。
由於本文的讀者定位,我們不能詳細展開說了,有相關需求的同學可以去看《Windows PE權威指南》和《程式員的自我修養》去詳細瞭解。
我們接下來看最後的連結過程。這一步是將彙編產生的標的檔案和所使用的庫函式的標的檔案連結生成一個可執行檔案的過程。我想在這裡稍微的擴充套件一下篇幅,稍微詳細的說一說連結,一來這裡造成的錯誤通常難以理解和處理,二來使用第三方庫在開發中越來越常見了,想著大家可能更需要稍微瞭解一些細節了。
我們先介紹gnu binutils工具包,這是一整套的二進位制分析處理工具包。詳細介紹請大家參考喂雞百科:http://zh.wikipedia.org/wiki/GNU_Binutils
我的fedora已經自帶了這套工具包,如果你的發行版沒有,請自行搜尋安裝方法。
這套工具包含了足夠多的工具,我們甚至可以用來研究ELF檔案的格式等內容。不過本文只是拋磚引玉,更多的使用方法和技巧還是需要大家自己去學習和研究。
由於時間關係,上篇到此就告一段落了,我們的問題2和3還沒有給出完整的答案,而且連結還沒有詳細去解釋和說明。這些內容我們將在下篇中解決,當然,大家也可以先行研究,到時候我們相互學習補充。
上回書我們說到了連結以前,今天我們來研究最後的連結問題。
連結這個話題延伸之後完全可以跑到九霄雲外去,為了避免本文牽扯到過多的話題導致言之泛泛,我們先設定本文涉及的範圍。我們今天討論只連結進行的大致步驟及其規則、靜態連結庫與動態連結庫的建立和使用這兩大塊的問題。至於可執行檔案的載入、可執行檔案的執行時儲存器映像之類的內容我們暫時不討論。
首先,什麼是連結?我們取用CSAPP的定義:連結(linking)是將各種程式碼和資料部分收集起來並組合成為一個單一檔案的過程,這個檔案可被載入(或被複製)到儲存器並執行。
需要強調的是,連結可以執行於編譯時(compile time),也就是在原始碼被翻譯成機器程式碼時;也可以執行於載入時,也就是在程式被載入器(loader)載入到儲存器並執行時;甚至執行於執行時(run time),由應用程式來執行。
說了這麼多,瞭解連結有什麼用呢?生命這麼短暫,我們幹嘛要去學習一些根本用不到的東西。當然有用了,繼續取用CSAPP的說法,如下:
理解聯結器將幫助你構造大型程式。
理解聯結器將幫助你避免一些危險的程式設計錯誤。
理解連結將幫助你理解語言的作用域是如何實現的。
理解連結將幫助你理解其他重要的系統概念。
理解連結將使你能夠利用共享庫。
……
言歸正傳,我們開始吧。為了避免我們的描述過於枯燥,我們還是以C語言為例吧。想必大家透過我們在上篇中的描述,已經知道C程式碼編譯後的標的檔案了吧。標的檔案最終要和標準庫進行連結生成最後的可執行檔案。那麼,標準庫和我們生成的標的檔案是什麼關係呢?
其實,任何一個程式,它的背後都有一套龐大的程式碼在支撐著它,以使得該程式能夠正常執行。這套程式碼至少包括入口函式、以及其所依賴的函式構成的函式集合。當然,它還包含了各種標準庫函式的實現。
這個“支撐模組”就叫做執行時庫(Runtime Library)。而C語言的執行庫,即被稱為C執行時庫(CRT)。
CRT大致包括:啟動與退出相關的程式碼(包括入口函式及入口函式所依賴的其他函式)、標準庫函式(ANSI C標準規定的函式實現)、I/O相關、堆的封裝實現、語言特殊功能的實現以及除錯相關。其中標準庫函式的實現佔據了主要地位。標準庫函式大家想必很熟悉了,而我們平時常用的printf,scanf函式就是標準庫函式的成員。C語言標準庫在不同的平臺上實現了不同的版本,我們只要依賴其介面定義,就能保證程式在不同平臺上的一致行為。C語言標準庫有24個,囊括標準輸入輸出、檔案操作、字串操作、數學函式以及日期等等內容。大家有興趣的可以自行搜尋。
既然C語言提供了標準庫函式供我們使用,那麼以什麼形式提供呢?原始碼嗎?當然不是了。下麵我們引入靜態連結庫的概念。我們幾乎每一次寫程式都難免去使用庫函式,那麼每一次去編譯豈不是太麻煩了。幹嘛不把標準庫函式提前編譯好,需要的時候直接連結呢?我很負責任的說,我們就是這麼做的。
那麼,標準庫以什麼形式存在呢?一個標的檔案?我們知道,連結的最小單位就是一個個標的檔案,如果我們只用到一個printf函式,就需要和整個庫連結的話豈不是太浪費資源了麼?但是,如果把庫函式分別定義在彼此獨立的程式碼檔案裡,這樣編譯出來的可是一大堆標的檔案,有點混亂吧?所以,編輯器系統提供了一種機制,將所有的編譯出來的標的檔案打包成一個單獨的檔案,叫做靜態庫(static library)。當聯結器和靜態庫連結的時候,聯結器會從這個打包的檔案中“解壓縮”出需要的部分標的檔案進行連結。這樣就解決了資源浪費的問題。
Linux/Unix系統下ANSI C的庫名叫做libc.a,另外數學函式單獨在libm.a庫裡。靜態庫採用一種稱為存檔(archive)的特殊檔案格式來儲存。其實就是一個標的檔案的集合,檔案頭描述了每個成員標的檔案的位置和大小。
光說不練是假把式,我們自己做個靜態庫試試。為了簡單起見我們就做一個只有兩個函式的私有庫吧。
我們在swap.c裡定義一個swap函式,在add.c裡定義了一個add函式。最後還有含有它們宣告的calc.h頭檔案。
|
|
|
|
|
|
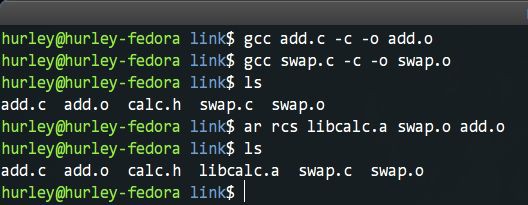
我們分別編譯它們得到了swap.o和add.o這兩個標的檔案,最後使用ar命令將其打包為一個靜態庫。
現在我們怎麼使用這個靜態庫呢?我們寫一個test.c使用這個庫中的swap函式吧。程式碼如下:
|
|
下來是編譯執行,命令列執行gcc test.c ./libcalc.a -o test編譯,執行。如圖,我們輸出了預期的結果。

可能你會問,我們使用C語言標準庫的時候,編譯並不需要加什麼庫名啊。是的,我們不需要。因為標準庫已經是標準了,所以會被預設連結。不過因為數學函式庫libm.a沒有預設連結,所以我們使用了數學函式的程式碼在編譯時需要在命令列指定 -lm 連結(-l是制定連結庫,m是去掉lib之後的庫名),不過現在好多gcc都預設連結libm.c庫了,比如我機子上的gcc 4.6.3會預設連結的。
正如我們所看到的,靜態連結庫解決了一些問題,但是它同時帶來了另一些問題。比如說每一個使用了相同的C標準函式的程式都需要和相關標的檔案進行連結,浪費磁碟空間;當一個程式有多個副本執行時,相同的庫程式碼部分被載入記憶體,浪費記憶體;當庫程式碼更新之後,使用這些庫的函式必須全部重新編譯……
有更好的辦法嗎?當然有。我們接下來引入動態連結庫/共享庫(shared library)。
動態連結庫/共享庫是一個標的模組,在執行時可以載入到任意的儲存器地址,並和一個正在執行的程式連結起來。這個過程就是動態連結(dynamic linking),是由一個叫做動態聯結器(dynamic linker)的程式完成的。
Unix/Linux中共享庫的字尾名通常是.so(微軟那個估計大家很熟悉,就是DLL檔案)。怎麼建立一個動態連結庫呢?
我們還是以上面的程式碼為例,我們先刪除之前的靜態庫和標的檔案。首先是建立動態連結庫,我們執行gcc swap.c add.c -shared -o libcalc.so 就可以了,就這麼簡單(微軟那個有所區別,我們在這裡只為說明概念,有興趣的同學請自行搜尋)。
順便說一下,最好在gcc命令列加上一句-fPIC讓其生成與位置無關的程式碼(PIC),具體原因超出本文範圍,故不予討論。

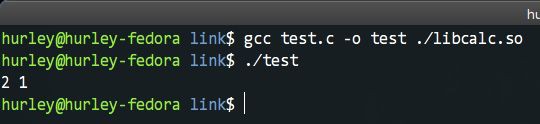
如何使用呢?我們繼續編譯測試程式碼,執行gcc test.c -o test ./libcalc.so即可。執行後我們仍舊得到了預期的結果。
這看起來也沒啥不一樣的啊。其實不然,我們用ldd命令(ldd是我們在上篇中推薦的GNU binutils工具包的組成之一)檢查test檔案的依賴。
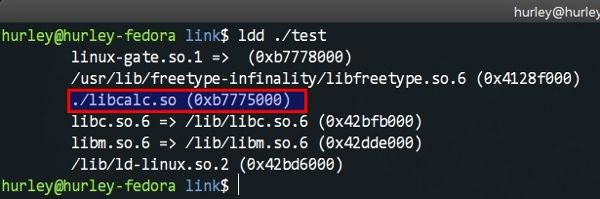
我們看到這個檔案能順利執行需要依賴libcalc.so這個動態庫,我們還能看到C語言的標準庫預設也是動態連結的(在gcc編譯的命令列加上 -static 可以要求靜態連結)。
好處在哪?第一,庫更新之後,只需要替換掉動態庫檔案即可,無需編譯所有依賴庫的可執行檔案。第二,程式有多個副本執行時,記憶體中只需要一份庫程式碼,節省空間。
大家想想,C語言標準庫好多程式都在用,但記憶體只有一份程式碼,這樣節省的空間很可觀吧,而且假如庫程式碼發現bug,只需要更新libc.so即可,所有程式即可使用新的程式碼,豈不是很Cool。
好了,關於庫我們就說到這裡了,再說下去就沒法子結束了。
我們來看看連結過程中具體做的事情。連結的步驟大致包括了地址和空間分配(Address and Storage Allocation)、符號決議(Symbol Resolution)和重定位(Relocation)等主要步驟。
首先是地址和空間分配,我們之前提到的標的檔案其實全稱叫做可重定位標的檔案(這隻是一種翻譯,叫法很多…)。標的檔案的格式已經無限度接近可執行檔案了,Unix/Linux下的標的檔案的格式叫做ELF(Executable and Linkable Format,可執行連線格式)。詳細的討論可執行檔案的格式超出了本文範圍,我們只需要知道可執行檔案中程式碼,資料,符號等內容分別儲存在不同的段中就可以了,這也和保護樣式下的記憶體分段是有一定關係的,但是這個又會扯遠就不詳談了……
地址和空間分配以及重定位我們簡單敘述一下就好,但是符號決議這裡我想稍微展開描述一下。
什麼是符號(symbol)?簡單說我們在程式碼中定義的函式和變數可以統稱為符號。符號名(symbol name)就是函式名和變數名了。
標的檔案的拼合其實也就是對標的檔案之間相互的符號取用的一個修正。我們知道一個C語言程式碼檔案只要所有的符號被宣告過就可以透過編譯了,可是對某符號的取用怎麼知道位置呢?比如我們呼叫了printf函式,編譯時留下了要填入的函式地址,那麼printf函式的實際地址在那呢?這個空位什麼時候修正呢?當然是連結的時候,重定位那一步就是做這個的。但是在修改地址之前需要做符號決議,那什麼是符號決議呢?正如前文所說,編譯期間留下了很多需要重新定位的符號,所以標的檔案中會有一塊區域專門儲存符號表。那聯結器如何知道具體位置呢?其實聯結器不知道,所以聯結器會搜尋全部的待連結的標的檔案,尋找這個符號的位置,然後修正每一個符號的地址。
這時候我們可以隆重介紹一個幾乎所有人在編譯程式的時候會遇見的問題——符號查詢問題。這個通常有兩種錯誤形式,即找不到某符號或者符號重定義。
首先是找不到符號,比如,當我們宣告了一個swap函式卻沒有定義它的時候,我們呼叫這個函式的程式碼可以透過編譯,但是在連結期間卻會遇到錯誤。形如“test.c:(.text+0x29): undefined reference to ‘swap’”這樣,特別的,MSVC編譯器報錯是找不到符號_swap。咦?那個下劃線哪裡來的?這得從C語言剛誕生說起。當C語言剛面世的時候,已經存在不少用組合語言寫好的庫了,因為聯結器的符號唯一規則,假如該庫中存在main函式,我們就不能在C程式碼中出現main函式了,因為會遭遇符號重定義錯誤,倘若放棄這些庫又是一大損失。所以當時的編譯器會對程式碼中的符號進行修飾(name decoration),C語言的程式碼會在符號前加下劃線,fortran語言在符號前後都加下劃線,這樣各個標的檔案就不會同名了,就解決了符號衝突的問題。隨著時間的流逝,作業系統和編譯器都被重寫了好多遍了,當前的這個問題已經可以無視了。所以新版的gcc一般不會再加下劃線做符號修飾了(也可以在編譯的命令列加上-fleading-underscore/-fno-fleading-underscore開開啟/關閉這個是否加下劃線)。而MSVC依舊保留了這個傳統,所以我們可以看到_swap這樣的修飾。
順便說一下,符號衝突是很常見的事情,特別是在大型專案的開發中,所以我們需要一個約定良好的命名規則。C++也引入了名稱空間來幫助我們解決這些問題,因為C++中存在函式多載這些東西,所以C++的符號修飾更加複雜難懂(Linux下有c++filt命令幫助我們翻譯一個被C++編譯器修飾過的符號)。
說了這麼多,該到了我們變成中需要註意的一個大問題了。即存在同名符號時聯結器如何處理。不是剛剛說了會報告重名錯誤嗎?怎麼又要研究這個?很可惜,不僅僅這麼簡單。在編譯時,編譯器會向彙編器輸出每個全域性符號,分為強(strong)符號和弱符號(weak),彙編器把這個資訊隱含的編碼在可重定位標的檔案的符號表裡。其中函式和已初始化過的全域性變數是強符號,未初始化的全域性變數是弱符號。根據強弱符號的定義,GNU聯結器採用的規則如下:
不允許多個強符號
如果有一個強符號和一個或多個弱符號,則選擇強符號
如果有多個弱符號,則隨機選擇一個
好了,就三條,第一條會報符號重名錯誤的,而後兩條預設情況下甚至連警告都不會有。關鍵就在這裡,預設甚至連警告都沒有。
我們來個實驗具體說一下:
|
|
|
|
這兩個檔案編譯執行會輸出什麼呢?聰明的你想必已經知道了吧?沒錯,就是5。

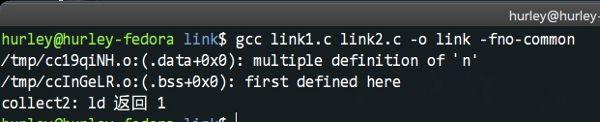
初始化過的n是強符號,被優先選擇了。但是,在很複雜的專案程式碼,這樣的錯誤很難發現,特別是多執行緒的……不過當我們懷疑程式碼中的bug可能是因為此原因引起的時候,我們可以在gcc命令列加上-fno-common這個引數,這樣聯結器在遇到多重定義的符號時,都會給出一條警告資訊,而無關強弱符號。如圖所示:
好了,到這裡我們的下篇到此也該結束了,不過關於編譯連結其實遠比這深奧複雜的多,我權當拋磚引玉,各位看官自可深入研究。