
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @Cratial。深度學習領域一直存在一個比較嚴重的問題——“災難性遺忘”,即一旦使用新的資料集去訓練已有的模型,該模型將會失去對原資料集識別的能力。
為解決這一問題,本文提出了樹摺積神經網路,透過先將物體分為幾個大類,然後再將各個大類依次進行劃分、識別,就像樹一樣不斷地開枝散葉,最終葉節點得到的類別就是我們所要識別的類。
如果你對本文工作感興趣,點選底部的閱讀原文即可檢視原論文。
關於作者:吳仕超,東北大學碩士生,研究方向為腦機介面、駕駛疲勞檢測和機器學習。
■ 論文 | Tree-CNN: A Deep Convolutional Neural Network for Lifelong Learning
■ 連結 | https://www.paperweekly.site/papers/1839
■ 作者 | Deboleena Roy / Priyadarshini Panda / Kaushik Roy
網路結構及學習策略
網路結構
Tree-CNN 模型借鑒了層分類器,樹摺積神經網路由節點構成,和資料結構中的樹一樣,每個節點都有自己的 ID、父親(Parent)及孩子(Children),網(Net,處理影象的摺積神經網路),LT(”Labels Transform”,就是每個節點所對應的標簽,對於根節點和枝節點來說,可以是對最終分類類別的一種劃分,對於葉節點來說,就是最終的分類類別),其中最頂部為樹的根節點。
本文提出的網路結構如下圖所示。對於一張影象,首先會將其送到根節點網路去分類得到“super-classes”,然後根據所識別到的“super-classes”,將影象送入對應的節點做進一步分類,得到一個更“具體”的類別,依次進行遞推,直到分類出我們想要的類。
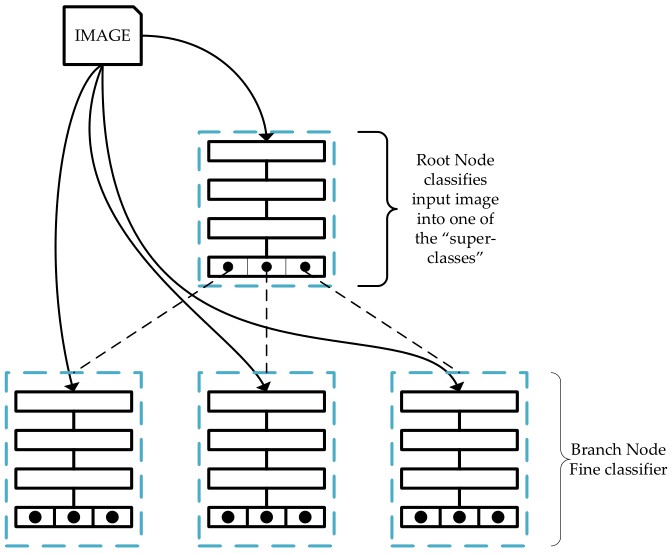
▲ 圖1
其實這就和人的識別過程相似,例如有下麵一堆物品:數學書、語文書、物理書、橡皮、鉛筆。如果要識別物理書,我們可能要經歷這樣的過程,先在這一堆中找到書,然後可能還要在書裡面找到理科類的書,然後再從理科類的書中找到物理書,同樣我們要找鉛筆的話,我們可能需要先找到文具類的物品,然後再從中找到鉛筆。
學習策略
在識別方面,Tree-CNN 的思想很簡單。如圖 1 所示,主要就是從根節點出發,輸出得到一個影象屬於各個大類的機率,根據最大機率所對應的位置將識別過程轉移到下一節點,這樣最終我們能夠到達葉節點,葉節點對應得到的就是我們要識別的結果。整個過程如圖 2 所示。

▲ 圖2
如果僅按照上面的思路去做識別,其實並沒有太大的意義,不僅使識別變得很麻煩,而且在下麵的實驗中也證明瞭採用該方法所得到的識別率並不會有所提高。而這篇論文最主要的目的就是要解決我們在前面提到的“災難性遺忘問題”,即文中所說的達到“lifelong”的效果。
對於新給的類別,我們將這些類的影象輸入到根節點網路中,根節點的輸出為 OK×M×I,其中 K、M、I 分別為根節點的孩子數、新類別數、每類的影象數。
然後利用式(1)來求得每類影象的輸出平均值 Oavg,再使用 softmax 來計算機率情況。以機率分佈表示該類與根節點下麵子類的相似程度。對於第 m 類,我們按照其機率分佈進行排列,得到公式(3)。


根據根節點得到的機率分佈,文中分別對下麵三種情況進行了討論:
-
當輸出機率中最大機率大於設定的閾值,則說明該類別和該位置對應的子節點有很大的關係,因此將該類別加到該子節點上;
-
若輸出機率中有多個機率值大於設定的閾值,就聯合多個子節點來共同組成新的子節點;
-
如果所有的輸出機率值都小於閾值,那麼就為新類別增加新的子節點,這個節點是一個葉節點。
同樣,我們將會對別的支節點繼續上面的操作。透過上面的這些操作,實現對新類別的學習,文中稱這種學習方式為 incremental/lifelong learning。
實驗方法與結果分析
在這部分,作者分別針對 CIFAR-10 及 CIFAT-100 資料集上進行了測試。
實驗方法
1. CIFAR-10
在 CIFAR-10 的實驗中,作者選取 6 類影象作為初始訓練集,又將 6 類中的為汽車、卡車設定為交通工具類,將貓、狗、馬設為動物類,因此構建出的初始樹的結構如圖 3(a)所示。
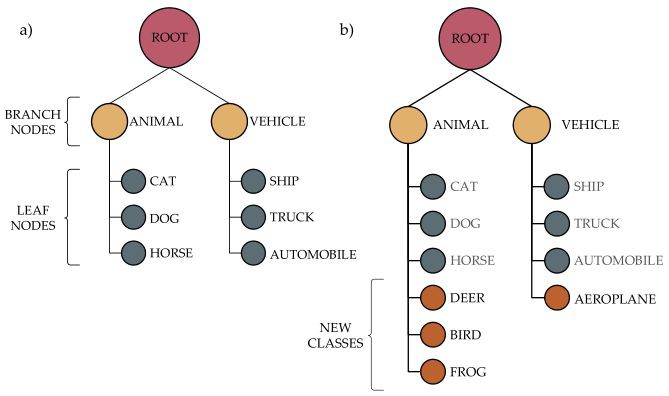
▲ 圖3
具體網路結構如圖 4 所示,根節點網路是包含兩層摺積、兩層池化的摺積神經網路,支節點是包含 3 層摺積的摺積神經網路。

▲ 圖4
當新的類別出現時(文中將 CIFAR-10 另外 4 個類別作為新類別),按照文中的學習策略,我們先利用根節點的網路對四種類別的圖片進行分類,得到的輸出情況如圖 5 所示,從圖中可以看出,在根節點的識別中 Frog、Deer、Bird 被分類為動物的機率很高,Airplane 被分類為交通工具的機率較高。
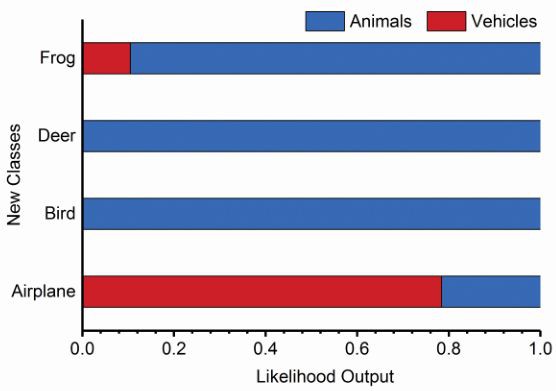
▲ 圖5
根據文中的策略,Frog、Deer、Bird 將會被加入到動物類節點,同樣 Airplane 將會被加入到交通工具類節點。經過 incremental/lifelong learning 後的 Tree-CNN 的結構如圖 3(b)所示。 具體訓練過程如圖 6 所示。

▲ 圖6
為了對比 Tree-CNN 的效果,作者又搭建了一個包含 4 層摺積的神經網路,並分別透過調節全連線層、全連線 +conv1、全連線 +conv1+conv2、全連線 +conv1+conv2+conv3、全連線 +conv1+conv2+conv3+conv4 的引數來進行微調。
2. CIFAR-100
對於 CIFAR-100 資料集,作者將 100 類資料分為 10 組,每組包含 10 類樣本。在網路方面,作者將根節點網路的摺積層改為 3,並改變了全連線層的輸出數目。
實驗結果分析
在這部分,作者透過設定兩個引數來衡量 Tree-CNN 的效能。

其中,Training Effort 表示 incremental learning 網路的更改程度,即可以衡量“災難性遺忘”的程度,引數改變的程度越高,遺忘度越強。
圖 7 比較了在 CIFAR-10 上微調網路和 Tree-CNN 的識別效果對比,可以看出相對於微調策略,Tree-CNN 的 Training Effort 僅比微調全連線層高,而準確率卻能超出微調全連線層 +conv1。

▲ 圖7
這一現象在 CIFAR-100 中表現更加明顯。


▲ 圖8
從圖 7、圖 8 中可以看出 Tree-CNN 的準確率已經和微調整個網路相差無幾,但是在 Training Effort 上卻遠小於微調整個網路。
從圖 9 所示分類結果中可以看出,在各個枝節點中,具有相同的特性的類被分配在相同的枝節點中。這一情況在 CIFAR-100 所得到的 Tree-CNN 最終的結構中更能體現出來。

除了一些葉節點外,在語意上具有相同特徵的物體會被分類到同一支節點下,如圖 10 所示。

▲ 圖10
總結與分析
本文雖然在一定程度上減少了神經網路“災難性遺忘”問題,但是從整篇文章來看,本文並沒能使網路的識別準確率得到提升,反而,相對於微調整個網路來說,準確率還有所降低。
此外,本文搭建的網路實在太多,雖然各個子網路的網路結構比較簡單,但是調節網路會很費時。
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:

▲ 戳我檢視招聘詳情
 #崗 位 推 薦#
#崗 位 推 薦#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文