作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
在深度學習等端到端方案已經逐步席捲 NLP 的今天,你是否還願意去思考自然語言背後的基本原理?我們常說“文字挖掘”,你真的感受到了“挖掘”的味道了嗎?
無意中的邂逅
前段時間看了一篇關於無監督句法分析的文章 [1],繼而從它的參考文獻中發現了論文 Redundancy Reduction as a Strategy for Unsupervised Learning,這篇論文介紹了如何從去掉空格的英文文章中將英文單詞複原。對應到中文,這不就是詞庫構建嗎?於是饒有興緻地細讀了一番,發現論文思路清晰、理論完整、結果漂亮,讓人賞心悅目。
儘管現在看來,這篇論文的價值不是很大,甚至其結果可能已經被很多人學習過了,但是要註意:這是一篇 1993 年的論文。在 PC 機還沒有流行的年代,就做出瞭如此前瞻性的研究。
雖然如今深度學習流行,NLP 任務越做越複雜,這確實是一大進步,但是我們對 NLP 原理的真正瞭解,還不一定超過幾十年前的前輩們多少。
這篇論文是透過“去冗餘”(Redundancy Reduction)來實現無監督地構建詞庫的,從資訊理論的角度來看,“去冗餘”就是資訊熵的最小化。無監督句法分析那篇文章也指出“資訊熵最小化是無監督的 NLP 的唯一可行的方案”。
我進而學習了一些相關資料,並且結合自己的理解思考了一番,發現這個評論確實是耐人尋味。我覺得,不僅僅是 NLP,資訊熵最小化很可能是所有無監督學習的根本。
何為最小熵原理?
讀者或許已經聽說過最大熵原理和最大熵模型,現在這個最小熵原理又是什麼?它跟最大熵不矛盾嗎?
我們知道,熵是不確定性的度量,最大熵原理的意思就是說我們在對結果進行推測時,要承認我們的無知,所以要最大化不確定性,以得到最客觀的結果。而對於最小熵原理,我們有兩個理解角度:
1. 直觀的理解:文明的演化過程總是一個探索和發現的過程,經過我們的努力,越多越多的東西從不確定變成了確定,熵逐漸地趨於最小化。因此,要從一堆原始資料中發現隱含的規律(把文明重演出來),就要在這個規律是否有助於降低總體的資訊熵,因為這代表了文明演化的方向,這就是“最小熵原理”。
2. 稍嚴謹的理解:“知識”有一個固有資訊熵,代表它的本質資訊量。但在我們徹底理解它之前,總會有未知的因素,這使得我們在表達它的時候帶有冗餘,所以按照我們當前的理解去估算資訊熵,得到的事實上是固有資訊熵的上界,而資訊熵最小化意味著我們要想辦法降低這個上界,也就意味著減少了未知,逼近固有資訊熵。
於是,我沿著“最小熵原理”這條路,重新整理了前人的工作,並做了一些新的拓展,最終就有了這些文字。讀者將會慢慢看到,最小熵原理能用一種極具解釋性和啟發性的方法來匯出豐富的結果來。
語言的資訊
讓我們從考究語言的資訊熵開始,慢慢進入這個最小熵原理的世界。
資訊熵=學習成本
從“熵”不起:從熵、最大熵原理到最大熵模型(一)[2] 我們可以知道,一個物件的資訊熵是正比於它的機率的負對數的,也就是:

如果認為中文的基本單位是字,那麼中文就是字的組合,pc 就意味著對應字的機率,而 −logpc 就是該字的資訊量。我們可以透過大量的語料估算每個漢字的平均資訊:

如果 log 是以 2 為底的話,那麼根據網上流傳的資料,這個值約是 9.65 位元(我自己統計了一些文章,得到的數值約為 9.5,兩者相當)。類似地,英文中每個字母的平均資訊約是 4.03 位元。
這個數字意味著什麼呢?一般可以認為,我們接收或記憶資訊的速度是固定的,那麼這個資訊量的大小事實上也就相當於我們接收這個資訊所需要的時間(或者所花費的精力,等等),從而也可以說這個數字意味著我們學習這個東西的難度(記憶負荷)。比如,假設我們每秒只能接收 1 位元的資訊,那麼按字來記憶一篇 800 字文章,就需要 9.65×800 秒的時間。
中英文孰優孰劣?
既然中文單字資訊熵是 9.65,而英文字母資訊熵才 4.03,這是不是意味著英文是一種更高效的表達呢?
顯然不能這麼武斷,難道背英語作文一定比背誦漢語作文要容易麼?
比如 800 字的中文作文翻譯成英文的話,也許就有 500 詞了,平均每個英文 4 個字母,那麼資訊量就是 4.03×500×4≈9.65×800,可見它們是相當的。換句話說,比較不同文字單元的資訊量是沒有意義的,有意義的是資訊總量,也就是說描述同樣的意思時誰更簡練。
當兩句話的意思一樣時,這個“意思”的固有資訊量是不變的,但用不同語言表達時,就不可避免引入“冗餘”,所以不同語言表達起來的資訊量不一樣,這個資訊量其實就相當於記憶負荷,越累贅的語言資訊量越大,記憶負荷越大。
就好比教同樣的課程,有的老師教得清晰明瞭,學生輕鬆地懂了,有的老師教得哆裡哆嗦,學生也學得很痛苦。同樣是一節課程,本質上它們的知識量是一樣的,而教得差的老師,表明授課過程中帶來了過多的無關資訊量,這就是“冗餘”,所以我們要想辦法“去冗餘”。
上述中英文的估計結果相當,表明中英文都經過長期的最佳化,雙方都大致達到了一個比較最佳化的狀態,並沒有誰明顯優於誰的說法。
套路之路
註意,上面的估算中,我們強調了“按字來記憶”,也許我們太熟悉中文了,沒意識到這意味著什麼,事實上這代表了一種很機械的記憶方式,而我們事實上不是這樣做的。
念經也有學問
回顧我們小時候背誦古詩、文言文的情景,剛開始我們是完全不理解、囫圇吞棗地背誦,也就是每個字都認識、串起來就不知道什麼含義的那種,這就是所謂的“按字來閱讀”了。很顯然,這樣的記憶難度是很大的。
後來,我們也慢慢去揣摩古文的成文規律了,逐漸能理解一些古詩或文言文的含義了,背誦難度就會降下來。到了高中,我們還會學習到文言文中“賓語前置”、“定語後置”之類的語法規律,這對我們記憶和理解文言文都是很有幫助的。
重點來了!
從古文的例子我們就能夠感受到,像念經一樣逐字背誦是很困難的,組詞理解後就容易些,如果能找到一些語法規律,就更加容易記憶和理解了。但是我們接收(記憶)資訊的速度還是固定的,這也就意味著分詞、語法這些步驟,降低了語言的資訊量,從而降低了我們的學習成本。
再細想一下,其實不單單是語言,我們學習任何東西都是這樣的,如果只有少數的內容要學習,那麼我們強行記住就行了,但學習的東西比較多時,我們就試圖找出其中的“套路”,比如中國象棋中就分開局、中局、殘局,每種局面都有很多“定式”,用來降低初學者的學習難度,而且也是在複雜局面中應變的基礎;再好比我們有《孫子兵法》、《三十六計》,這些都是“套路大全”。透過挖掘“套路”來減輕逐一記憶的負擔,“套路”的出現就是一個減少資訊量的過程。
說到底,念經念多了,也能發現經文的套路了。
以不變應萬變
一言以蔽之,我們接收資訊的速度是固定的,所以加快我們的學習進度的唯一方法就是降低學習標的的冗餘資訊量,所謂“去蕪存菁”,這就是 NLP 中的最小熵原理了,也就是一開始所提到的“去冗餘”,我們可以理解為是“省去沒必要的學習成本”。
事實上,一個高效的學習過程必定能體現出這個思想,同樣地,教師也是根據這個思想來設計他們的教學計劃的。在教學的時候,教師更傾向於講授那些“通解通法”(哪怕步驟多一點),也不會選擇每一題都講一種獨特的、巧妙的解法;在準備高考時,我們會努力摸索各種出題套路、解題套路。這些都是透過挖掘“套路”來降低資訊熵、從而降低學習成本的過程,“套路”就是“去冗餘”的方法。
“套路”即“定式”,有了足夠多的套路,我們才能以不變應萬變。所謂“萬變不離其宗”,這個“宗”,也就是套路了吧。當“套路”過多時,我們又會進一步尋找“套套路”——即套路的套路,來減輕我們記憶套路的負擔,這是一個層層遞進的過程。看來,將個體現象上升為套路,正是人類的智慧的體現呢。
好了,空話不宜多說,接下來我們就正式走上修煉套路的旅途。
這部分,我們介紹“套路寶典”第一式——“當機立斷”:
1. 匯出平均字資訊熵的概念,然後基於最小熵原理推匯出互資訊公式;
2. 並且完成詞庫的無監督構建、給出一元分詞模型的資訊熵詮釋,從而展示有關生成套路、識別套路的基本方法和技巧。這既是最小熵原理的第一個使用案例,也是整個“套路寶典”的總綱。
由字到詞
從上文可以看到,假設我們根本不懂中文,那麼我們一開始會將中文看成是一系列“字”隨機組合的字串,但是慢慢地我們會發現背景關係是有聯絡的,它並不是“字”的隨機組合,它應該是“套路”的隨機組合。於是為了減輕我們的記憶成本,我們會去挖掘一些語言的“套路”。第一個“套路”,是相鄰的字之間的組合定式,這些組合定式,也就是我們理解的“詞”。
平均字資訊熵
假如有一批語料,我們將它分好詞,以詞作為中文的單位,那麼每個詞的資訊量是 −logpw,因此我們就可以計算記憶這批語料所要花費的時間為:

這裡 w∈語料是對語料逐詞求和,不用去重。如果不分詞,按照字來理解,那麼需要的時間為:

根據前一節的理解,分詞其實就是為了減輕記憶負擔,那麼理論上應該有:

當然,很多詞語是重覆出現的,因此我們可以把相同項合併:
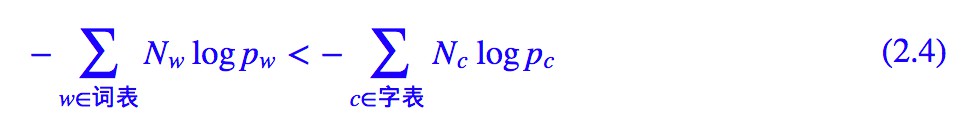
其中 Nw,Nc 分別是在語料中統計得到詞和字的頻數。對式 (2.4) 兩邊除以語料的總字數,那麼右端就是:

其中 Nc/總字數=pc 即為字 c 的頻率,所以上式就是每個字的平均資訊,而 (2.4) 左端可以變形為:
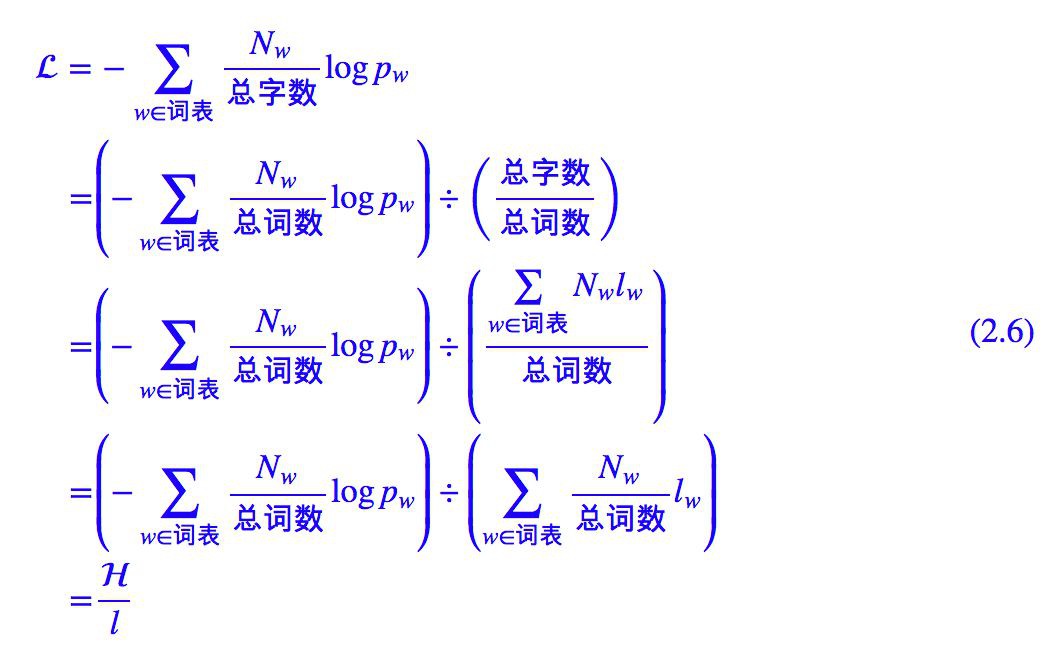
其中 Nw/總詞數=pw 是詞 w 的頻率,lw 是詞 w 的字數,所以 H 是平均每個詞的資訊量,l 是每個詞的平均字數:

因此 L 實際上是按詞來記憶時平均每個字的資訊量,是我們要比較和最佳化的終極標的。我們將總的資訊量轉化為平均到每個字的資訊量,是為了得到一個統一的度量標準。
豐富你的詞彙量
是不是真如期望一樣,分詞有助於降低了學習難度?我簡單統計了一下,對微信公眾號的文章做一個基本的分詞後,H≈10.8 位元,每個詞平均是 1.5 個字,也就是 l≈1.5,那麼 L=7.2 位元,這明顯小於逐字記憶的 9.65 位元。這就說明瞭在中文裡邊,按詞來記憶確實比按字來記憶要輕鬆。
“分詞”這個操作,降低了中文的學習難度,這也是“分詞”通常都作為中文 NLP 的第一步的原因。
簡單來想,對語言進行分詞之後,我們需要記憶的詞表變大了,但是每個句子的長度變短了,整體來說學習難度是降低了。所以這也就不難理解為什麼要學好英語,就得去背單詞,因為豐富我們的詞彙量能降低學習語言的難度。
提煉套路
反過來,我們也可以由 L 的最小化,來指導我們無監督地把詞庫構建出來。這就是“套路是如何煉成的”這門課的重點內容了。
套路之行,始於區域性
首先我們將平均字資訊熵 L 區域性化。所謂區域性化,是指考察怎樣的兩個基本元素合併成一個新的元素後,會導致 L 降低,這樣我們就可以逐步合併以完成熵最小化的標的。這裡用“基本元素”來描述,是為了將問題一般化,因為字可以合併為詞,詞可以合併為片語,等等,這個過程是迭代的,迭代過程中“基本元素”是變化的。
“區域性化”是接下來大部分內容的基礎,其推導過程雖然冗長,但都是比較簡單的運算,稍加思考即可弄懂。
假設目前 i 的頻數為 Ni,總頻數為 N,那麼可以估算 Pi=Ni/N,假設 i 的字數為 li,那麼就可以算出當前的:

如果將兩個相鄰的 a,b 合併成一項呢?假設 (a,b) 的頻數為 Nab,那麼在合併前可以估計 Pab=Nab/N。如果將它們合併為一個“詞”來看待,那麼總頻數實際上是下降了,變為 Ñ =N−Nab,而 Ña=Na−Nab,Ñb=Nb−Nab,其他頻數不變,因此我們就可以重新估計各個頻率:

於是:

其中:

而:

因此:

我們的目的是讓![]() 變小,所以很明顯,一個好的“套路”應該要使得 Fab≫0。
變小,所以很明顯,一個好的“套路”應該要使得 Fab≫0。
簡明優美的近似
Fab 的運算式過於複雜,以至於難以發現出規律來,我們可以做一些近似。Pab≤Pa,Pb 總是成立的,而很多時候甚至可以認為 Pab≪Pa,Pb,這樣一來在使用自然對數時就有:

因為這個近似的條件是要使用自然對數(ln(1+x)≈x),所以我們將下麵的 log 全部改為自然對數 ln。代入 Fab 的運算式並去掉 Pab 的二次以上的項,得到:

這個指標就比較簡明漂亮了,其中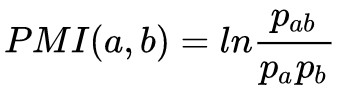 我們稱之為點互資訊。
我們稱之為點互資訊。

上面討論的是兩個元素的合併,如果是 k 個基本元素 a=(a1,…,ak) 的合併,那麼同樣可以推得:

其近似公式為:

推導盡,詞庫現
現在我們可以看到,要使得標的讓![]() 變小,就應該要有 Fab≫0,而 Fab 的一個下界近似是 F∗ab,所以我們可以用 F∗ab≫0 來進行確定哪些元素是需要合併,而對應於詞庫構建的過程,F∗ab≫0 實際上告訴我們哪些字是需要合併成詞的。
變小,就應該要有 Fab≫0,而 Fab 的一個下界近似是 F∗ab,所以我們可以用 F∗ab≫0 來進行確定哪些元素是需要合併,而對應於詞庫構建的過程,F∗ab≫0 實際上告訴我們哪些字是需要合併成詞的。
根據 F∗ab 的特點不難看出,F∗ab≫0 的一個必要的條件是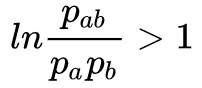 ,也就是說互資訊至少要大於1,這個必要條件下,互資訊越大越好,a,b 的共現頻率也越大越好,這就告訴我們要從共現頻率和互資訊兩個角度來判斷是否要把元素合併。
,也就是說互資訊至少要大於1,這個必要條件下,互資訊越大越好,a,b 的共現頻率也越大越好,這就告訴我們要從共現頻率和互資訊兩個角度來判斷是否要把元素合併。
在詞庫構建這個事情上,還有一個巧妙的招數,那就是對 F∗ab 的“逆運用”:式 F∗ab 告訴我們滿足 F∗ab≫0 時,兩個元素就應該合併。那麼反過來,F∗ab 小於某個 θ 時,是不是就應該切分呢?(逆向思維,從確定哪些要“合併”變為確定哪些要“切分”,所謂“當機立斷”)。
這樣的話我們只需要用兩個元素合併的公式來指導我們對語料進行一個粗糙的切分,然後對切分結果進行統計篩選,就可以得到很多詞了。
這樣,我們就得到一種簡單有效的構建詞庫的演演算法:

以前三步得到的詞典還是有冗餘的,這體現為:直接用這個詞典構建一個一元分詞模型,那麼詞典中的有些詞永遠都不會被分出來,因為那些詞可以用它們的子詞表示出來,並且子詞的機率乘積還大於它本身的機率。
比如在實驗中,因為“的、主”以及“主、要”的互資訊都大於 1,所以詞庫中出現了“的主要”這個“詞”,但統計發現 p (的主要)< p (的) p (主要),那麼這個詞在一元模型分詞的時候是不會分出來的,這個“詞”放在詞庫中只會浪費記憶體,所以要去掉“的主要”這個詞,並且把“的主要”的頻數加到“的”和“主要”這兩個詞上面。
因此,根據這個原則,我們可以過濾掉一部分的候選詞:

“去冗”這一步的作用還是很明顯的,可以去掉 30% 甚至 50% 以上的“不及格”的候選詞,以下就是篩選出來的一部分(100 個):

可以發現,除了“中國人”這個外,其他確實都是我們認識中的“不及格”的詞語。
PS:“去冗”這一步需要一些人工規則來對長詞進行降權,因為有限的語料對長詞的統計是很不充分的,因此長詞的機率估計會偏高。而既然是“人工規則”,那就讓讀者自由發揮了,這裡不明確給出。
難道就這麼簡單?
當然,哪怕是經過上述 4 步,這個演演算法看起來還是過於簡單,以至於會讓人懷疑它的效果。有讀者應該會想到,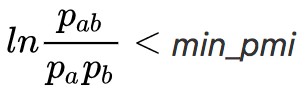 不意味著
不意味著 呀,也就是相鄰兩個字的互資訊很小,但三個字的互資訊可能就大了,只根據兩字的互資訊來切分是不是過於武斷了?
呀,也就是相鄰兩個字的互資訊很小,但三個字的互資訊可能就大了,只根據兩字的互資訊來切分是不是過於武斷了?
確實有這樣的例子,比如在某些語料中,“共和國”中的“和”、“國”,“林心如”中的“心”、“如”,兩個字的互資訊是比較小的,但三字的互資訊就很大了。
然而事實上,落實到中文詞庫構建這個應用上,這種情況並不多,因為中文跟英文不同,英文基本單位是字母,也就是隻有 26 個,它們兩兩組合才 676 個,甚至三三組合也才一萬多個,而漢字本身就有數千個,而理論上漢字對(即 2-gram)就有數百萬個了,所以只需要統計 2-gram 就能得到相對充分地反映漢字的組合特徵。所以如果出現了這種錯例,很大可能是因為這些詞不是我們輸入語料的顯著詞,說白了,錯了就錯了唄。
因此我們基本上不必要討論三個或三個以上元素合併的公式,用上述的鄰字的判別演演算法即可,在很多情景下它都可以滿足我們的需求了。如果要對它進行改進的話,都無法避免引入三階或更高階的語言模型,並且還可能需要引入動態規劃演演算法,這會大大降低演演算法效率。也就是說,改進的思路是有的,但改進的代價會有點大。
識別套路
現在我們可以找出一些自然語言的“套路”——也就是詞語了。接下來的問題是,給我們一句話,如何識別出這句話中的套路呢?而對於“詞”這個套路,說白了,就是有了詞庫和詞頻後如何分詞呢?
一元分詞新詮釋
有了前述討論,其實就很簡單了,自始至終,我們找套路就是為了減輕記憶負擔,降低語料總的資訊量,而我們有:
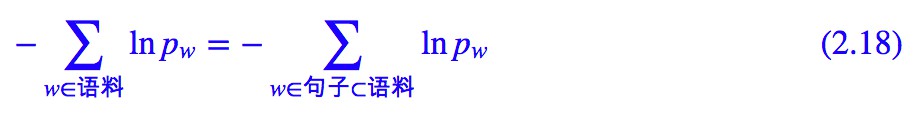
也就是最小化總的資訊量等價最小化每個句子的資訊量。所以對於一個給定的句子,它的最好的分詞方案——假設為 w1,w2,…,wn —— 那麼應該使得該句子的總資訊量:
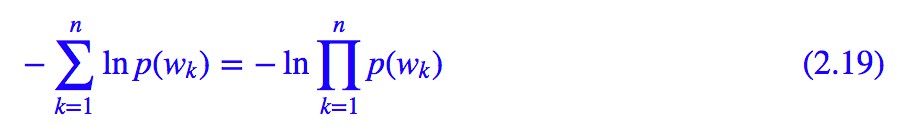
最小,這其實就是一元分詞模型——使得每個詞的機率乘積最大,但這裡我們透過最小熵原理賦予了它新的詮釋。
核心的動態規劃
一元分詞模型可以透過動態規劃來求解。動態規劃是 NLP 中的核心演演算法之一,它是求滿足馬爾可夫假設的圖模型的最優路徑的方法。
一般的最優路徑是一個複雜度很高的問題,然而由於馬爾可夫假設的存在,使得這裡存在一個高效的演演算法,效率為 ?(n),這個演演算法稱之為動態規劃,也稱為 viterbi 演演算法,是由安德魯·維特比(Andrew Viterbi)於 1967 年提出。動態規劃的其根本思想是:一條最優路徑如果拆分為兩部分,那麼每一部分都是一條(區域性)最優路徑。
具體來講,在最短路徑分詞中,動態規劃就是說:從左往右掃描句子,掃描到當前字時,只保留直到當前字的最優分詞結果,以及經過當前字的所有“準最優序列”(防止過早地誤切)。
比如,對於句子“中外科學名著”,首先掃描“中”,它就是唯一的分詞結果,這個結果被儲存下來,經過“中”字的詞還有“中外”,因此也要儲存下來,也就是說,當掃描到第一個字時,臨時變數存的是“中”、“中外”兩個候選結果。
第二步,掃描“外”字,這時我們知道“中外”可以有“中 / 外”分成兩字,或者直接就“中外”成一個詞兩種選擇,當然,後者機率更大,因此“中 / 外”的結果不保留,只保留“中外”,但是,經過“外”的詞還有“外科”,那麼應當保留“中 / 外科”的可能性,也就是說,掃描到第二字時,所存的就是“中外”、“中 / 外科”兩個候選結果。
接下來到“科”字,由於“中外 / 科”的機率沒有“中 / 外科”機率那麼大,因此到這一步最優的分詞方案是“中 / 外科”,但是經過“科”字的詞語還有“科學”,因此此時還有保留“中外 / 科學”的可能性,所以掃描到第三字是,所存的就是“中 / 外科”和“中外 / 科學”。
依此類推,直到最後一字,就可以成功分出“中外 / 科學 / 名著”。整個過程的原則就是:保留至當前字最優的方案,以及不放過經過當前字的所有詞(避免過早誤切)。
在此,筆者覺得,動態規劃在 NLP 中的作用是怎麼強調都不為過的,不管你面對的是傳統機器學習還是深度學習,都必須掌握動態規劃演演算法,不僅要懂得用,還要懂得自己完整寫出來(結合 Trie 樹或者 AC 自動機)。
原理再思
儘管我們只是初步完成了無監督構建詞庫這件事情,但含義遠不止於此。
讀者不妨頭腦風暴一下,我們前面做的是一件非常神奇的事情:我們並不是人為總結一些機械的規則來構建詞庫,我們是找到了平均字資訊熵這個標的,然後試圖最小化它,然後就把詞庫構建出來了。這似乎有點“重演文明”的味道?
做過實驗的讀者可能又會反駁:你這出來的東西,很多都不是我們認識的“詞”呀?
筆者認為,只要讓模型具有了演化的能力和方向,那麼它究竟演化出什麼樣子的結果來其實是不重要的。就好比分詞,我們並不是為了分詞而分詞,我們分詞是為了後面的任務做準備的,既然如此,何必關心分出來的詞準不準的?前面都已經說了,分詞的目的是為了降低任務難度罷了。我們真正要關心的,是對最後的任務的處理能力。
聽起來有點耍無賴,但事實上這才是真正有人工智慧的味道——假如一群真正具有智慧的機器人慢慢地從零開始發展文明,憑什麼他發展出來的結果要跟我們的一樣呢?
當然,分詞只是第一步,事實上出現誤差的本質原因是因為我們只關心了分詞,而沒有做更複雜的語言結構和語意分析。我們後面還會試圖做更多的工作,推導更多的“套路”,讀者將會慢慢發現,我們最後得到的結果確實是跟語言學現象吻合的。
參考文獻
[1]. 無監督句法分析
http://www.52nlp.cn/一種基於生語料的無監督的語法規則學習方法
[2]. “熵”不起:從熵、最大熵原理到最大熵模型(一)
https://kexue.fm/archives/3534

點選以下標題檢視作者其他文章:

▲ 戳我檢視招聘詳情
 #崗 位 推 薦#
#崗 位 推 薦#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 進入作者部落格