
-
https://github.com/kubernetes/community/pull/1054
-
https://github.com/kubernetes/community/pull/1140
-
https://github.com/kubernetes/community/pull/1105
-
Kubernetes 1.9和1.10部分程式碼

-
更好的利用本地高效能介質(SSD,Flash)提升資料庫服務能力 QPS/TPS(其實這個結論未必成立,後面會有贅述)
-
更閉環的運維成本,現在越來越多的資料庫支援基於Replicated的技術實現資料多副本和資料一致性(比如MySQL Group Replication / MariaDB Galera Cluster / Percona XtraDB Cluster的),DBA可以處理所有問題,而不在依賴儲存工程師或者SA的支援。
apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: mysql-5.7
spec:
replicas: 1
template:
metadata:
name: mysql-5.7
spec:
containers:
name: mysql
resources:
limits:
cpu: 5300m
memory: 5Gi
volumeMounts:
- mountPath: /var/lib/mysql
name: data
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
func (spc *realStatefulPodControl) CreateStatefulPod(set *apps.StatefulSet, pod *v1.Pod) error {
// Create the Pod's PVCs prior to creating the Pod
if err := spc.createPersistentVolumeClaims(set, pod); err != nil {
spc.recordPodEvent("create", set, pod, err)
return err
}
// If we created the PVCs attempt to create the Pod
_, err := spc.client.CoreV1().Pods(set.Namespace).Create(pod)
// sink already exists errors
if apierrors.IsAlreadyExists(err) {
return err
}
spc.recordPodEvent("create", set, pod, err)
return err
}

-
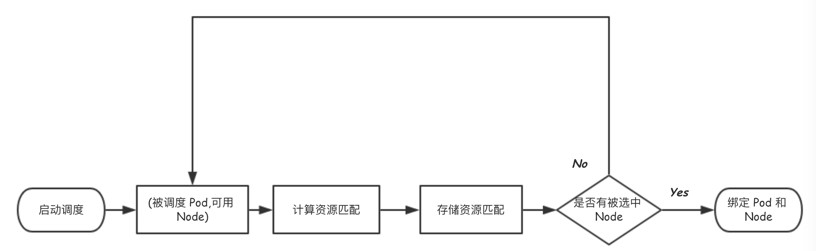
PVC系結在Pod排程之前,PersistentVolume Controller不會等待Scheduler排程結果,在Statefulset中PVC先於Pod建立,所以PVC/PV系結可能完成在Pod排程之前。
-
Scheduler不感知捲的“位置”,僅考慮儲存容量、訪問許可權、儲存型別、還有第三方CloudProvider上的限制(譬如在AWS、GCE、Aure上使用Disk數量的限制)
-
嘗試讓兩個老闆溝通
-
站隊,挑一個老闆,只聽其中一個的指揮
-
辭職
-
如何標記Topology-Aware Volume
-
如何讓PersistentVolume Controller不再參與,同時不影響原有流程
"volume.alpha.kubernetes.io/node-affinity": '{
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{ "matchExpressions": [
{ "key": "kubernetes.io/hostname",
"operator": "In",
"values": ["Node1"]
}
]}
]}
}'
-
建立StorageClass “X”(無需Provisioner),並設定StorageClass.VolumeBindingMode = VolumeBindingWaitForFirstConsumer
-
PVC.StorageClass設定為X
return *class.VolumeBindingMode == storage.VolumeBindingWaitForFirstConsumer
if claim.Spec.VolumeName == "" {
// User did not care which PV they get.
delayBinding, err := ctrl.shouldDelayBinding(claim)
….
switch {
case delayBinding:
do nothing-
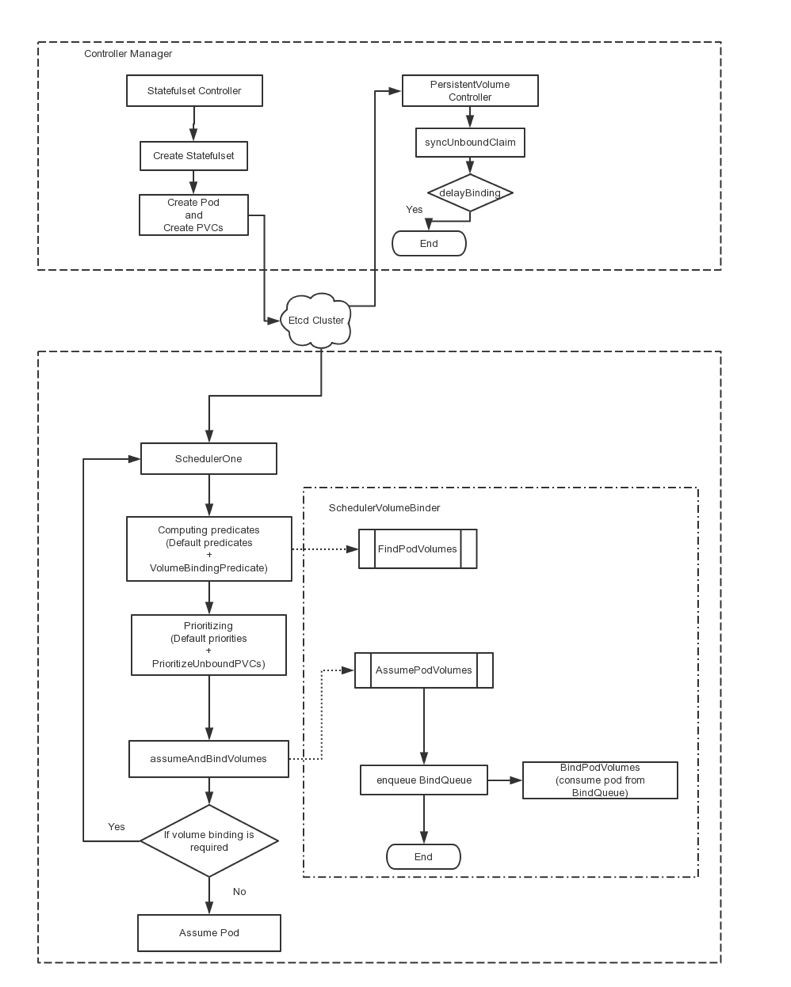
執行原有Predicates函式
-
執行新增Predicate函式CheckVolumeBinding校驗候選Node是否滿足PV物理拓撲(主要邏輯由FindPodVolumes提供):
已係結PVC:對應PV.NodeAffinity需匹配候選Node,否則該節點需要pass
未系結PVC:該PVC是否需要延時系結,如需要,遍歷未系結PV,其NodeAffinity是否匹配候選Node,如滿足,記錄PVC和PV的對映關係到快取bindingInfo中,留待節點最終選出來之後進行最終的系結。
以上都不滿足時 : PVC.StorageClass是否可以動態建立 Topology-Aware Volume(又叫 Topology-aware dynamic provisioning)
-
執行原有Priorities函式
-
執行新增Priority函式PrioritizeVolumes。Volume容量匹配越高越好,避免本地儲存資源浪費。
-
Scheduler選出Node
-
由Scheduler進行API update,完成最終的PVC/PV系結(非同步操作,時間具有不確定性,可能失敗)
-
從快取bindingInfo中獲取候選Node上PVC和PV的系結關係,並透過API完成實際的系結
-
如果需要StorageClass動態建立,被選出Node將被賦值給StorageClass.topologyKey,作為StorageClass建立Volume的拓撲約束,該功能的實現還在討論中。
-
系結被排程Pod和Node

apiVersion: v1
kind: PersistentVolume
metadata:
name: local-pv
annotations:
"volume.alpha.kubernetes.io/node-affinity": '{
"requiredDuringSchedulingIgnoredDuringExecution": {
"nodeSelectorTerms": [
{ "matchExpressions": [
{ "key": "kubernetes.io/hostname",
"operator": "In",
"values": ["k8s-node1-product"]
}
]}
]}
}'
spec:
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Delete
storageClassName: local-storage
local:
path: /mnt/disks/ssd1
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer
apiVersion: apps/v1beta1
kind: StatefulSet
metadata:
name: mysql-5.7
spec:
replicas: 1
template:
metadata:
name: mysql-5.7
spec:
containers:
name: mysql
resources:
limits:
cpu: 5300m
memory: 5Gi
volumeMounts:
- mountPath: /var/lib/mysql
name: data
volumeClaimTemplates:
- metadata:
annotations:
volume.beta.kubernetes.io/storage-class: local-storage
name: data
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
-
資源利用率降低。一旦本地儲存使用完,即使CPU、Memory剩餘再多,該節點也無法提供服務;
-
需要做好本地儲存規劃,譬如每個節點Volume的數量、容量等,就像原來使用儲存時需要把LUN規劃好一樣,在一個大規模執行的環境,存在落地難度。
-
Node不可用後,等待閾值超時,以確定Node無法恢復
-
如確認Node不可恢復,刪除PVC,透過解除PVC和PV系結的方式,解除Pod和Node的系結
-
Scheduler將Pod排程到其他可用Node,PVC重新系結到可用Node的PV。
-
Operator查詢MySQL最新備份,複製到新的PV
-
MySQL叢集透過增量同步方式恢復實體資料
-
增量同步變為實時同步,MySQL叢集恢復

