商湯科技是一家計算機視覺領域的AI創業公司,公司內會有一些業務需要雲端API支援,一些客戶也會透過公網呼叫這些所謂SaaS服務。總體來講,雲API的架構比較簡單,另外由於公司成立不久,歷史包袱要輕許多,很多業務在設計之初就有類似微服務的架構,比較適合通過容器化來適配其部署較繁複的問題。
公司各個業務線相對獨立,在組織上,體現在人員,績效及彙報關係的差異;在技術上體現在程式語言,框架及技術架構的獨自演進,而服務的部署上線和後續維護的工作,則劃歸於運維部門。這種獨立性、差異性所加大的運維複雜度需要得到收斂。
我們遇到的問題不是新問題,業界也是有不少應對的工具和方法論,但在早期,我們對運維工具的複雜性增長還是保持了一定的剋制:SSH + Bash Scripts扛過了早期的一段時光,Ansible也得到過數月的應用,但現實所迫,我們最終還是投向了Docker的懷抱。
Docker是革命性的,乾凈利落的UX俘獲了技術人員的芳心,我們當時所處的時期,容器編排的大戰則正處於Docker Swarm mode釋出的階段,而我們需要尋找那種工具,要既能應對日益增長的運維複雜度,也能把運維工程師從單調、重覆、壓力大的釋出中解放出來。
Rancher是我們在HackerNews上的評論上看到的,其簡單易用性讓我們看到了生產環境部署容器化應用的曙光,但是要真正能放心地在生產環境使用容器,不“翻車”,還是有不少工作要做。由於篇幅的原因,事無巨細的描述是不現實的。我接下來首先介紹我們當時的需求分析和技術選型,再談談幾個重要的組成部分如容器映象、監控報警和可靠性保障。

暫時拋開容器/容器編排/微服務這些時髦的詞在一邊,對於我們當時的情況,這套新的運維工具需要三個特性才能算成功:開發友好、操作可控及易運維。
能把應用打包的工作推給開發來做,來消滅自己打包/編譯如Java/Ruby/Python程式碼的工作,但又要保證開發打出的包在生產環境至少要能執行,所以怎麼能讓開發人員方便正確地打出釋出包,後者又能自動流轉到生產環境是關鍵。長話短說,我們採取的是Docker + Harbor的方式,由開發人員構建容器映象,透過LDAP認證推送到公司內部基於Harbor的容器映象站,再透過Harbor的Replication機制,自動將內部映象同步到生產環境的映象站,具體實現可參考接下來的容器映象一節。
能讓開發人員參與到服務釋出的工作中來,由於業務線迥異的業務場景/技術棧/架構,使得只靠運維人員來解決釋出時出現的程式碼相關問題是勉為其難的,所以需要能夠讓開發人員在受控的情境下,參與到服務日常的釋出工作中來,而這就需要像其提供一些受限可審計且易用的介面,WebUI+Webhook就是比較靈活的方案。這方面,Rancher提供的功能符合需求。
運維複雜度實話說是我們關註的核心,畢竟容器化是運維部門為適應複雜度與日俱增而發起的,屁股決定腦袋。考慮到本身容器的黑盒性和穩定性欠佳的問題,再加上真正把容器技術搞明白的人寥寥無幾,能平穩落地的容器化運維在我們這裡體現為三個需求:多租戶支援,穩定且出了事能知道,故障切換成本低。多租戶是支援多個並行業務線的必要項;容器出問題的情況太多,線上環境以作業系統映象的方式限定每臺機器Docker和核心版本;由於傳統監控報警工具在容器化環境捉襟見肘,需要一整套新的監控報警解決方案;沒人有把握能現場除錯所有容器問題(如跨主機容器網路不通/掛載點洩漏/dockerd卡死/基礎元件容器起不來),需要藍綠部署的出故障後能立刻切換,維護可靠與可控感對於一個新系統至關重要。
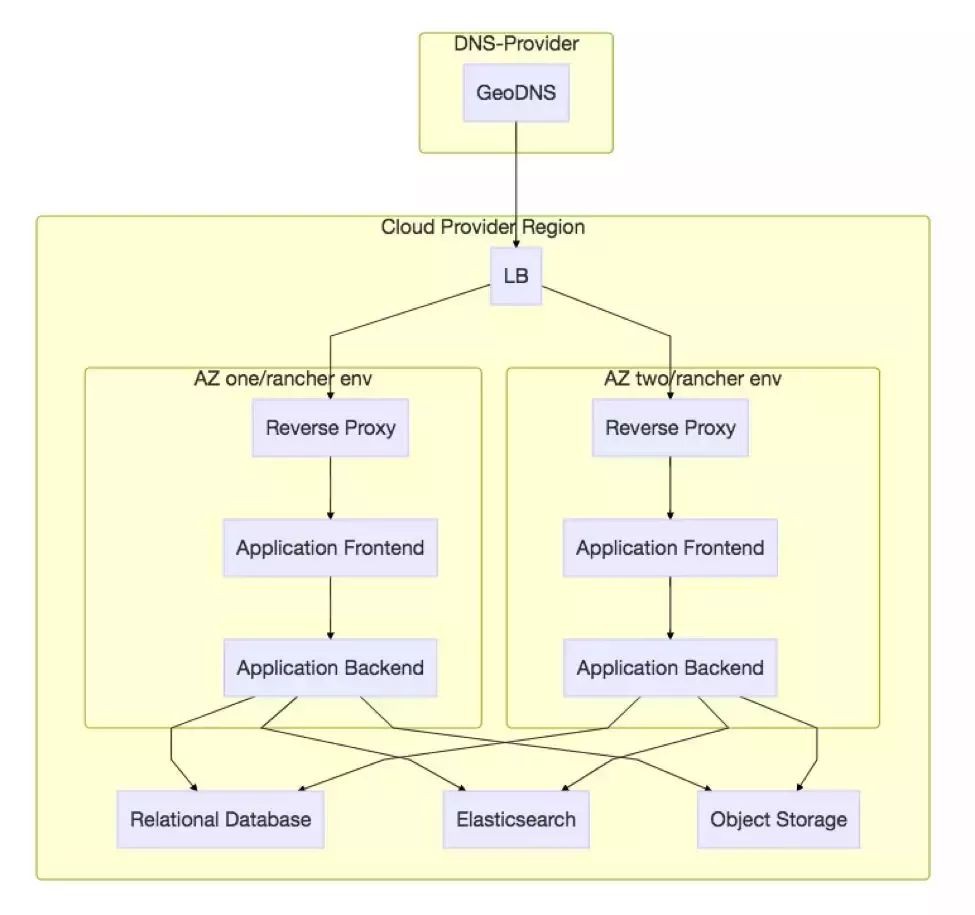
總結一下,Rancher、Harbor、Prometheus/Alertmanager為主的開源系統組合可以基本滿足容器管理的大部分需求,總體架構如下圖:
容器映象服務是公司級別的IT基礎設施,在各個辦公區互聯頻寬有限的物理限制下,需要給分散在多個地理位置的使用者以一致、方便、快速的使用體驗。我們主要使用了VMware開源的Harbor工具來搭建容器映象服務,雖然Harbor解決瞭如認證、同步等問題,但Harbor不是這個問題的銀色子彈,還是需要做一些工作來使映象服務有比較好的使用者體驗。這種體驗我們以Google Container Registry為例來展現。
作為Google的開放容器映象服務,全球各地的使用者都會以同一個域名gcr.io推拉映象docker push gcr.io/my_repo/my_image:my_tag,但其實使用者推拉映象的請求,由於來源地理位置不同,可能會被GeoDNS分發在不同的Google資料中心上,這些資料中心之間有高速網路連線,各種應用包括GCR會透過網路同步資料。這樣的方法既給使用者一致的使用體驗,即所有人都是透過gcr.io的域名推拉映象,又因為每個人都是同自己地理位置近的資料中心互動而不會太“卡”,並且由於Google Container Registry底層儲存的跨資料中心在不斷高速同步映象(得益於Google優異的IT基礎設施),異國他鄉的別人也能感覺很快地拉取我們推送的映象(映象“推”和“拉”的非同步性是前提條件)。
花篇幅介紹Google Container Registry的目的是,使用者體驗對使用者接受度至關重要,而後者往往是一個新服務存活的關鍵,即在公司內部提供類似GCR一般的體驗,是我們容器映象服務為了成功落地而想接近的產品觀感。為了達到這種觀感,需要介紹兩個核心的功能,開發/生產映象自動同步,映象跨辦公區同步。另外,雖然有點超出映象服務本身,但由於特殊的國情和使用關聯性,國外映象(DockerHub、GCR、Quay)拉取慢也是影響容器映象服務使用體驗的關鍵一環,映象加速服務也是需要的。
由於開發環境(公司私網),生產環境(公網)的安全性和使用場景的差異,我們部署了兩套映象服務,內網的為了方便開發人員使用是基於LDAP認證,而公網的則做了多種安全措施來限制訪問。但這帶來的問題是如何方便地向生產環境傳遞映象,即開發人員在內網打出的映象需要能自動地同步到生產環境。
我們利用了Harbor的replication功能,只對生產環境需要的專案才手動啟用了replication,透過這種方式只需初次上線時候的配置,後續開發的映象推送就會有內網Harbor自動同步到公網的Harbor上,不需要人工操作。
由於公司在多地有辦公區,同一個team的成員也會有地理位置的分佈。為了使他們能方便地協作開發,映象需要跨地同步,這我們就依靠了公司已有的Swift儲存,這一塊兒沒有太多可說的,頻寬越大,同步的速度就越快。值得一提的是,由於Harbor的UI需要從MySQL提取資料,所以如果需要各地看到一樣的介面,是需要同步Harbor MySQL資料的。
很多開源映象都託管在DockerHub、Google Container Registry和Quay上,由於受制於GFW及公司網路頻寬,直接pull這些映象,速度如龜爬,極大影響工作心情和效率。
一種可行方案是將這些映象透過代理下載下來,docker tag後上傳到公司映象站,再更改相應manifest yaml,但這種方案的使用者體驗就是像最終幻想裡的踩雷式遇敵,普通使用者不知道為什麼應用起不了,即使知道了是因為映象拉取慢,映象有時能拉有時又不能拉,他的機器能拉,我的機器不能拉,得搞明白哪裡去配預設映象地址,而且還得想辦法把映象從國外拉回來,上傳到公司,整個過程繁瑣耗時低智,把時間浪費在這種事情上,實在是浪費生命。
我們採取的方案是,用mirror.example.com的域名來mirror DockerHub,同時公司nameserver劫持Quay,GCR,這樣使用者只需要配置一次docker daemon就可以無痛拉取所有常用映象,也不用擔心是否哪裡需要override拉取映象的位置,而且每個辦公區都做類似的部署,這樣使用者都是在辦公區本地拉取映象,速度快並且節約寶貴的辦公區間頻寬。
值得一提的是,由於對gcr.io等域名在辦公區內網做了劫持,但我們手裡肯定沒有這些域名的key,所以必須用http來拉取映象,於是需要配置docker daemon的–insecure-registry這個項。
配置docker daemon(以Ubuntu 16.04為例)
sudo -s
cat << EOF > /etc/docker/daemon.json
{
"insecure-registries": ["quay.io", "gcr.io","k8s.gcr.io],
"registry-mirrors": ["https:
}
EOF
systemctl restart docker.service
拉取dockerhub映象
docker pull ubuntu:xenial
拉取google映象
docker pull gcr.io/google_containers/kube-apiserver:v1.10.0
拉取quay映象
docker pull quay.io/coreos/etcd:v3.2
minikube
minikube start
由於Zabbix等傳統監控報警工具容器化環境中捉襟見肘,我們需要重新建立一套監控報警系統,幸虧Prometheus/Alertmanager使用還算比較方便,並且已有的Zabbix由於使用不善,導致已有監控系統的使用者體驗很差(誤報/漏報/報警風暴/命名不規範/操作複雜等等),不然在有限的時間和人員條件下,只是為了kick start而什麼都得另起爐灶,還是很麻煩的。
其實分散式系統的監控報警系統,不論在是否用容器,都需要解決這些問題:能感知機器/容器(行程)/應用/三個層面的指標,分散在各個機器的日誌要能儘快收集起來供查詢檢索及報警低信噪比、不誤報不漏報、能“望文生義”等。
而這些問題就像之前提到的,Prometheus/Alertmanager已經解決得比較好了:透過exporter pattern,外掛化的解決靈活適配不同監控標的(node-exporter、cAdvisor、mysql-exporter、elasticsearch-exporter等等);利用Prometheus和Rancher DNS服務配合,可以動態發現新加入的exporter/agent;Alertmanager則是一款很優秀的報警工具,能實現alerts的路由/聚合/正則匹配,配合已有的郵件和我們自己新增的微信(現已官方支援)/電話(整合阿裡雲語音服務),每天報警數量和頻次達到了oncall人員能接受的狀態。
至於日誌收集,我們還是遵從了社群的推薦,使用了Elasticsearch + Fluentd + Kibana的組合,Fluentd作為Rancher的Global Serivce(對應於Kubernetes的daemon set),收集每臺機器的系統日誌,dockerd日誌,透過docker_metadata這個外掛來收集容器標準輸出(log_driver: json_file)的日誌,Rancher基礎服務日誌,既本地檔案系統壓縮存檔也及時地發往相應的Elasticsearch服務(並未用容器方式啟動),透過Kibana視覺化供產品售後使用。基於的日誌報警使用的是Yelp開源的Elastalert工具。
為每個環境手動建立監控報警stack還是蠻繁瑣的,於是我們也自定義了一個Rancher Catalog來方便部署。
監控報警系統涉及的方面太多,而至於什麼是一個“好”的監控報警系統,不是我在這裡能闡述的話題,Google的Site Reliability Engineering的這本書有我認為比較好的詮釋,但一個拋磚引玉的觀點可以分享,即把監控報警系統也當成一個嚴肅的產品來設計和改進,需要有一個人(最好是核心oncall人員)承擔產品經理般的角色,來從人性地角度來衡量這個產品是否真的好用,是否有觀感上的問題,特別是要避免破窗效應,這樣對於建立oncall人員對監控報警系統的信賴和認可至關重要。
分散式系統在提升了併發效能的同時,也增大了區域性故障的機率。健壯的程式設計和部署方案能夠提高系統的容錯性,提高系統的可用性。可靠性保障是運維部門發起的一系列目的在於保障業務穩定/可靠/魯棒的措施和方法,具體包括:
-
生產就緒性檢查
-
備份管理體系
-
故障分析與總結
-
Chaos Monkey
主要談談Chaos Monkey,總體思路就是流水不腐,戶樞不蠹。透過模擬各種可能存在的故障,發現系統存在的可用性問題,提醒開發/運維人員進行各種層面的改進。
-
service升級
-
業務容器隨機銷毀
-
主機遣散
-
網路抖動模擬
-
Rancher基礎服務升級
-
主機級別網路故障
-
單主機機器宕機
-
若干個主機機器宕機
-
可用區宕機
-
體量較小公司也可以搭建相對可用的容器平臺。
-
公司發展早期投入一些精力在基礎設施的建設上,從長遠來看還是有價值的,這種價值體現在很早就可以積累一批有能力有經驗有幹勁兒的團隊,來不斷對抗規模擴大後的複雜性猛增的問題。一個“讓人直觀感覺”,“看起來”混亂的基礎技術架構,會很大程度上影響開發人員編碼效率。甚至可以根據破窗原理揣測,開發人員可能會覺得將會執行在“臟”,“亂”,”差”平臺的專案沒必要把質量看得太重。對於一個大的組織來講,秩序是一種可貴的資產,是有無法估量的價值的。
-
映象拉取慢問題也可以比較優雅地緩解。
-
國內訪問國外網路資源總體來講還是不方便的,即使沒有GFW,頻寬也是很大的問題。而我們的解決方案也很樸素,就是快取加本地訪問,這樣用比較優雅高效地方法解決一個“蒼蠅”問題,改善了很多人的工作體驗,作為工程人員,心裡是很滿足的。
-
容器化也可以看作是一種對傳統運維體系的重構。
-
容器化本質上是當容器成為技術架構的所謂building blocks之後,對已有開發運維解決方案重新審視,設計與重構。微服務、雲原生催生了容器技術產生,而後者,特別是Docker工具本身美妙的UX,極大地鼓舞了技術人員與企業奔向運維“應許之地”的熱情。雖然大家都心知肚明銀色子彈並不存在,但Kubernetes ecosystem越來越看起來前途不可限量,給人以無限希望。而販賣希望本身被歷史不斷證明,倒真是穩賺不虧的商業樣式。
A:是的,這也是社群推薦的實踐,同一個映象流轉開發/測試/預釋出/生產環境,可以預先提供一些安全/小型的base image給開發人員,做好配置檔案與程式碼的隔離就好。
A:為了保證同一個映象流轉開發/測試/預釋出/生產環境,所以需要首先把配置與程式碼分離,配置可以透過環境變數,side-kick container或者rancher-secret的方式傳入程式碼所在映象。
Q:資料庫你們也放Docker裡麼?現在我看到有些人也把MySQL放Docker裡,這種方案你們研究過麼?可行性如何?
A:有狀態的應用跑在容器裡本身就是一個複雜的問題,Kubernetes也是引入了Operator pattern才在幾個有狀態的應用(etcd/Prometheus)上有比較好的效果,Operator的程式碼量也是相對龐大的,Rancher/Cattle作為輕量級的解決方案,還是適合Web型別的應用跑在容器裡。
Q:Prometheus和Altermanger有沒有相關檔案?
A:Prometheus/Alertmanager說實話,是poorly documented,Alertmanager我們是程式碼好好看過的,Prometheus的查詢陳述句也是不太好寫,這一點沒啥好辦法,多看多嘗試吧。
A:介面監控我們做的比較粗糙,用的blackbox-exporter,需要手動新增,目前監控報警系統我們在深度定製中,標的是做成向OpsGenie這樣的體驗;網路抖動是用https://github.com/alexei-led/pumba 這個工具做的。
Q:你們的服務可用性達到了一個什麼樣的級別呢?有沒有出現過什麼比較大的事故?
A:目前各個服務上線都不久,談可用性就比較虛了;比較大的事故的話,我們曾經遇到Rancher 的一個bug(https://github.com/rancher/rancher/issues/9118),還有應用沒有好好配健康檢查,服務行程PID不為1,大量503這樣的,我們每次大的事故都會做Postmortem,早期還不少的,主要是經驗和測試不夠的問題。
A:我們是利用Rancher的Environments做多租戶的,每個環境一個租戶(其實為了可靈活切換/基礎元件升級,每個租戶會有兩個幾乎一樣的環境)。
Q:普羅米修斯裡面的NodeExporter和cAdvicor都是Overlay網路的地址吧。如何和宿主機對應上呢?每次找起來挺費勁的。
A:這個是好問題,這兩個直接用host network,然後勾選cattle的Enable Rancher DNS service discovery這個選項,來讓Rancher DNS服務應用到不使用Managed Network的服務就好。
Q:EFK的日誌資料用的什麼儲存?貴司維護Rancher的團隊有多少人?
A:Fluentd會在本地檔案系統壓一份,再往Elasticsearch打一份(配置檔案裡用copy這個Directive),我司維護Rancher的團隊為4人,但這個團隊不僅僅維護Rancher,還有不少內部系統開發類、研發類的工作。
本次培訓內容包括:Docker基礎、容器技術、Docker映象、資料共享與持久化、Docker三駕馬車、Docker實踐、Kubernetes基礎、Pod基礎與進階、常用物件操作、服務發現、Helm、Kubernetes核心元件原理分析、Kubernetes服務質量保證、排程詳解與應用場景、網路、基於Kubernetes的CI/CD、基於Kubernetes的配置管理等,點選瞭解具體培訓內容。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。