
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @duinodo。本文是 ETH Zurich 發表於 CVPR 2018 的工作,論文提出了兩個網路策略,用於處理語意分割任務中使用合成資料訓練的域適配問題。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:杜敏,華中科技大學碩士生,研究方向為樣式識別與智慧系統。
■ 論文 | ROAD: Reality Oriented Adaptation for Semantic Segmentation of Urban Scenes
■ 連結 | https://www.paperweekly.site/papers/1828
■ 作者 | Yuhua Chen / Wen Li / Luc Van Gool
問題背景
本文研究的是無人駕駛場景中的語意分割問題。語意分割的樣本標記成本很高,使用合成資料能幫助解決樣本不足問題。但是合成的資料和真實的資料之間存在差異,這種差異會極大影響使用合成資料訓練的模型在真實資料上的表現。
本文研究難點在於如何處理合成資料和真實資料之間的差異,該問題存在兩方面原因:
-
用合成資料訓練的模型,很容易對合成資料過擬合,對合成資料可以提取很好的特徵,而對真實資料就提取不到特徵了;
-
合成資料和真實資料的分佈存在明顯的差異,而模型對合成資料存在偏好。
其實以上兩點說的是一點,只不過從兩個角度說,這兩點分別對應本文設計的兩個子模型。
解決思路
本文的主要貢獻在於提出了兩個網路策略,用於處理語意分割任務中使用合成資料訓練的域適配問題。
為了避免模型對合成資料的過擬合,本文使用 Target Guided Distillation Module,讓模型模模擬實圖片的訓練的特徵。
為瞭解決資料分佈不一的問題,使用 Spatial-aware Adaption Module,充分考慮兩種資料在空間分佈上的差異,使得模型在兩種資料上能夠得到相似的特徵。
論文模型
1. Target Guided Distillation

用 ImageNet 訓練好的特徵提取網路(圖中灰色部分)作為 target,讓分割模型提取的特徵盡可能的像 target 提取的特徵,distillation loss 採用尤拉距離計算方法。訓練的時候,當輸入是真實圖片,計算 distillation loss;當輸入是合成圖片,輸出分割的損失。
2. Spatial-Aware Adaption

使用 max-min loss(對抗訓練)的方式完成適配(domain distribution adaption)任務。適配任務的目的是,讓特徵提取網路,對不同分佈域的資料,提取到類似的特徵,而不影響後續的任務處理。
該問題的關鍵在於“類似的特徵”如何表達。來自不同分佈域的資料,內容存在差異,肯定無法直接用 mseloss 這種形式的損失來處理,所以,使用判別器損失,是比較合適的。
圖中綠色框中的 domain classifier 就是這個判別器。紅框同時也是上上圖中分割網路所使用的摺積特徵提取網路,而中間的藍色框,表示的是標題中的“Spatial-Aware”,也就是把對用整張圖的特徵,分成 3×3 個區域,分別對每個區域計算判別損失。
3. 整個模型
整個網路連起來,如下圖所示。測試的時候,只使用用圖中黃色框的部分。

實驗
真實資料集 Cityscapes [1],合成資料集 GTAV [2],分割網路使用 PSPnet 和 Deeplab。其中,Cityscapes 僅使用圖片,未使用標簽(本文要處理的是盡可能不使用人工標記的樣本)。
訓練時,一個 batch 中有 10 張圖片,5 張來自 Cityscapes,5 張來自 GTAV。使用真實圖片進行測試,計算 mIOU,實驗結果如下。
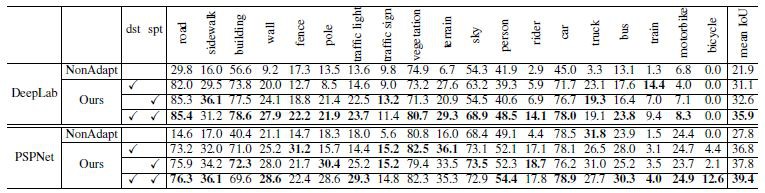
適配能提升 14 個百分點,但是相比於使用人工標記的訓練結果 [3],還是要差很多很多。
本文提出的適配方法,相比於其他適配方法,效果也是最好的。

評價
本文研究的問題(使用合成資料減少對人工標註資料的依賴)很有實際意義,但是目前的效果還是差一些,似乎只能充當 boosting,離標的還有一段距離。很多視覺任務,都可以嘗試這種方法,以減少對實際標註樣本量的需求。
另外,是否可以研究,在使用合成資料的情況下,檢測結果(在真實資料下測試的指標)隨真實標記樣本量的變化情況,定性地瞭解,到底合成資料能在多大程度上,減少手工標註量。比如,可能畫出如下曲線:

如果能做到這個地步,那在實際應用中,使用合成資料進行訓練這種方法,可能會廣泛使用,畢竟目前還僅僅停留在學術論文的地步。
相關連結
[1] Cityscapes資料集
https://www.cityscapes-dataset.com/
[2] GTAV資料集
https://download.visinf.tu-darmstadt.de/data/from_games/
[3] 使用人工標記的訓練結果
https://www.cityscapes-dataset.com/benchmarks/#pixel-level-results
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:

▲ 戳我檢視招聘詳情
 #崗 位 推 薦#
#崗 位 推 薦#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文