
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @marcw。為瞭解決標的輸出的不規範性問題以及提供可解釋的語意聚合過程,本文提出了一個神經語意解析器(neural semantic parser)。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:王克欣,中科院自動化研究所碩士生,研究方向為自然語言處理。
■ 論文 | Learning Structured Natural Language Representations for Semantic Parsing
■ 連結 | https://www.paperweekly.site/papers/963
■ 原始碼 | https://github.com/cheng6076/scanner
任務介紹
本文介紹的任務,語意解析(Sematic Parsing),是將自然語言的句子轉換為機器可解析的語意表達。具體而言,在這篇文章中,研究的問題為:
給定一個知識庫(knowledge base)K,以及標註有對應的匹配知識庫的語意表達(grounded meaning representation)G 或者問題答案(denotation)y的自然語言句子(問題)x,要學習得到一個語意解析器,使之可以完成經由一個中間未匹配知識庫的語意表達 U,來將 x 對映到對應的 G 的功能。
相關工作
大多數現有工作將語意解析的處理方法分成兩類,第一類是透過一個任務相關的文法將自然語言句子直接解析(parse)、匹配知識圖譜(grounded to a knowledge base)轉為語意表達。第二類方法是首先使用句法分析器將自然語言句子解析為任務無關的中間表達(intermediate representation),然後再將中間表達轉換為匹配知識圖譜的最終表達。
第一類方法
根據前人工作來看,目前使用編碼器-解碼器(encoder-decoder)模型處理語意解析的方法依然應當歸為第一類方法。這種方法減少了領域相關假設、文法學習以及大量的特徵工程工作的需要。
但是這種模型無法去解釋語意聚合(meaning composition)是如何進行的,這也是該類模型極大靈活性的代價。而語意聚合的可解釋性在處理邊界(modeling limitation)問題上有著很大的作用。
另外,由於缺乏任務相關的先驗知識的引入,學習任務關於可能推倒(derivation)的考慮上以及標的輸出的不規範性(ill-formed,如解析結果少了或多了若干括號)問題上不能得到很好的限制。
第二類方法
第二類方法的一個優勢在於產生了可重覆利用的中間表達,這種中間表達由於其任務無關性可以一定程度上處理未出現的詞(unseen words)以及不同領域的知識遷移(knowledge transfer)。
文章動機與主要貢獻
為瞭解決標的輸出的不規範性問題以及提供可解釋的語意聚合過程,這篇文章提出了一個神經語意解析器(neural semantic parser)。
與其他方法相比,該模型沒有使用外部的解析器(如 dependency parser)以及手工設計的 CCG 文法,而是採用了基於狀態轉移(transition-based)的方法生成謂詞-引數(predicate-argument)形式的中間表達,由此避免了生成不規範形式的語意表達。
另外與目前語意解析問題中大多數採用的 CKY 類似的自底向上(bottom-up)解析策略相比,本文提出的方法不需要對自然語言的句子結構的進行人為的特徵分解(decomposition),可以利用大量的非區域性特徵。
基於假設匹配知識圖譜後的語意表達與未匹配的語意表達同構(isomorphic)的假設,本文提出的狀態轉移模型的輸出最終可以匹配到某一個知識圖譜。
模型細節與程式碼
整個網路是在標註了對應的邏輯形式或者問題答案的自然語言句子集上進行端到端訓練的。這篇文章附上的開原始碼只給出了適用於標註邏輯形式的資料集的版本,下麵將結合具體訓練樣本的訓練過程以及程式碼來進行這部分的介紹。
適用標註邏輯形式的資料集的版本
這裡的邏輯形式為 Funql,一個訓練樣本及其標註為:
how many states have a city called rochester
answer(count(state(loc(city(cityid(rochester,_)))))) (*)
下麵結合對該樣本的訓練更新過程進行闡述。
訓練過程
輸入:
訓練樣本集:這裡是用的語料庫為 GEOQUERY,包含 880 個關於美國地理資訊的問題和對應的邏輯查詢陳述句);
通用謂詞表:這些謂詞與領域無關,例如 (∗) 中的 answer,count,state,loc,city,cityid,_ 等,詳細的關於通用謂詞表見附錄-通用謂詞)。
輸出:訓練好的語意分析器,能夠將自然語言問題對映到相應的邏輯表達(Funql)。
過程:
1. 將問題的單詞加入單詞詞典(這裡和下文提到的詞典都是為了之後神經網路的 softmax 輸出對應輸出字串而建立的);
word_vocab.feed_all(sen)
2. 對邏輯表達進行解析得到語法樹,可以從語法樹中獲得其中包含的非終結符和終結符以及能夠更直接指導狀態轉移系統訓練的標註資訊 U(ungrouned meaning representation)。
其中 U=(a,u):
-
a 為狀態轉移系統的動作(action)序列,包括 NT,TER 和 ACT(對應原文的 RED),分別代表在棧中加入一個非終結符、在棧中加入一個終結符以及規約;
-
u 為項(包括終結符和非終結符)序列,為 NT,TER 動作的引數。
在對邏輯表達解析以及構造語法樹時, 首先將邏輯表達轉換為另一種方便處理形式:

對應這裡:

互動呼叫:
def parse_list(tokens) #對運算式深入分解(進到括號內),直到不能分解(沒有括號)
與:
def parse_operands(tokens) #每個括號後緊跟的為運運算元,也即動作,對這些動作進行記錄
最後得到了語法樹的巢狀 list 表示,這裡為:
'list'
>: [‘answer’, [‘count’, [‘state’, [‘loc’, [‘city’,
[‘cityid’, ‘rochester,’, ‘_’]]]]]]
這兩個函式的完整程式碼見附錄-程式碼-parse_list 和附錄-程式碼-parse_operands。
得到所有的終結符和非終結符,加入對應的詞典:
nt_vocab.feed_all(nt)
ter_vocab.feed_all(ter)
最後參照語法樹的巢狀 list 表示,構建語法樹。
def construct_from_list(self, content) #遞迴深度優先的自底向上構建樹,將巢狀
list表示裡的list對應子樹根節點;list中從第二個元素開始算起,若為字串則將其對應為
葉結點。
完整程式碼見附錄-程式碼-construct_from_list,這裡得到的語法樹為:

再根據語法樹得到 U。這部分可以自定向下(top-down)採用先序(pre-order)遍歷(本文介紹的),也可以採用自底向上(bottom_up)遍歷。
def top_down(self, identifier, general_predicates) #對語法樹進行先序遍歷,
遍歷到葉節點時在項序列u裡加入對應字串,在動作序列a裡加入'NT';遍歷遇到子樹根節點時
在項序列u裡加入對應字串content,如果該字串為通用謂詞則在動作序列a裡加入'NT(content)',
否則加入'NT';遍歷完一個子樹進行回溯時在動作序列a裡加入'ACT'。
這裡得到:
-
動作序列a
'list'
>: [‘NT(answer)’, ‘NT(count)’, ‘NT’, ‘NT’, ‘NT’,
‘NT(cityid)’, ‘TER’, ‘TER’, ‘ACT’, ‘ACT’, ‘ACT’, ‘ACT’, ‘ACT’,
‘ACT’]
-
項序列u
'list'
>: [‘rochester,’, ‘_’, ‘cityid’, ‘city’, ‘loc’,
‘state’, ‘count’, ‘answer’]
註:這裡的_或是可能出現的 all 也為通用謂詞,但在狀態轉移系統裡對應的動作都為 TER。完整程式碼見附錄-程式碼-top_down。
3. 上一步得到的訓練用的資訊為:
word_tokens[fname].append(sen) #自然語言問題句子對應的單詞串列
tree_tokens[fname].append(tree_token) #上一步得到的u
tran_actions[fname].append(action) #上一步得到的a
對應的:
word_tokens, tree_tokens, tran_actions #鍵為{'train','valid','test'}值為
訓練用資訊的dict
從這三個 dict 中按照序號各拿出一個同序號位置的元素即構成了一個訓練用實體 (sen,u,a)。
4. 下麵介紹計算圖(computing graph)的構建以及狀態轉移系統的轉移過程。
這裡訓練的網路結構為:

對每個訓練實體,首先將 sen 中的單詞序列編碼對映到一個雙向 LSTM 的輸出的隱層向量序列 buffer。
tok_embeddings =
[self.word_input_layer(self.word_lookup[self.word_vocab[word]]) for
word in words]
#get buffer representation with blstm
forward_sequence, backward_sequence =
self.blstm.predict(tok_embeddings)
buffer = [dy.concatenate([x, y]) for x, y in
zip(forward_sequence,reversed(backward_sequence))]
#輸出為兩個方向相反的LSTM的輸出的拼接(concatenate)
接下來自頂向下的生成語意解析樹。
生的方式為根據狀態轉移系統的 buffer,stack 以及 action 資訊來預測下一個動作,並和標註的動作比較得到相應的對數機率加入到 loss 裡。
然後根據 stack 的狀態得到可行動作(valid action,來限制狀態轉移系統的動作),並根據當前標註動作分情況(NT,NT_general,TER,ACT)進行子操作,在每個子操作中根據 buffer 資訊來預測動作的引數,並和標註的動作的引數來比較得到相應的對數機率加入到 loss 裡。
下麵分幾部分闡述計算圖構建以及狀態轉移過程:
-
根據狀態轉移系統的 buffer,stack 以及 action 資訊來預測下一個動作
使用 stack 的當前隱層輸出 stack_embedding 以及 buffer 隱層向量序列作為輸入根據註意力機制來計算的權重,將 buffer 賦權累加(這裡有不同的賦權累加方式)得到 buffer 的嵌入表示 buffer_embedding。
再在 stack 中從後往前找到最後入棧的非終結符(對應子樹根節點),記錄其對應的詞向量經線性層(linear layer)輸出的嵌入表示 parent_embedding(還未經過隱層單元處理,下文稱其為原始表達(raw representation))。
最後將三個嵌入表示拼接得到解析器狀態的嵌入表示 parserstate:

再將 parser_state 依次經由一層隱層的前饋神經網路、dropout 處理、線性層處理、softmax 處理得到可行動作的對數機率,並和標註的當前動作對比,將對數機率加入到 loss 中。
stack_embedding = stack[-1][0].output() # stack[-1] means the last one in the list 'stack'.
action_summary = action_top.output()
word_weights = self.attention(stack_embedding, buffer) # Get the attention weight list of the encoding words.
buffer_embedding, _ = attention_output(buffer, word_weights, 'soft_average')
# Get the attention-weighted word embedding vectors (a vector).
for i in range(len(stack)):
if stack[len(stack)-1-i][1] == 'p':
parent_embedding = stack[len(stack)-1-i][2]
# parent_embedding is just the embeding vector computed from
# the word vector into a linear layer Wx+b.
# Just the word vector without processing
# into the hidden state.
break
parser_state = dy.concatenate([buffer_embedding, stack_embedding, parent_embedding, action_summary])
h = self.mlp_layer(parser_state)
if options.dropout > 0:
h = dy.dropout(h, options.dropout)
if len(valid_actions) > 0:
log_probs = dy.log_softmax(self.act_proj_layer(h), valid_actions)
assert action in valid_actions, "action not in scope"
losses.append(-dy.pick(log_probs, action))
# Append the corresponding log probability of the action
# annotated by the training examples.
-
根據 buffer 資訊來預測動作的引數
對於動作 NT,TER,根據上一步預測動作中得到的註意力機制權重,對 buffer 進行加權累加,得到輸出的特徵,再經由線性層以及 softmax 處理得到對數機率,與相應標註的非終結符或終結符對比,將得到的對數機率加入 loss 中。
對於狀態轉移處理,將標註的非終結符或終結符對應的詞向量經由線性層得到嵌入表示 nt_embedding(ter_embedding),作為 LSTM 的下一個隱層單元的輸入,輸入進去得到當前棧的狀態 stack_state,將三元組(對於動作 NT):

或(對於動作 TER):

入棧,其中 ‘p’ 和 ‘c’ 分別對應父節點和子節點。
對於動作 NT_general, 因為可以由 action 的內容得到具體的領域無關謂詞的字串,不作引數預測處理。
# If the aciton is NT, then caculate the log probability of
# the corresponding annotated term choices.
#generate non-terminal
nt = self.nt_vocab[oracle_tokens.pop(0)]
#no need to predict the ROOT (assumed ROOT is fixed)
if word_weights is not None:
train_selection = self.train_selection if np.random.randint(10)
> 5 else "soft_average"
output_feature, output_logprob = attention_output(buffer,
word_weights, train_selection)
log_probs_nt =
dy.log_softmax(self.nt_proj_layer(output_feature))
losses.append(-dy.pick(log_probs_nt, nt))
# Append the corresponding log probability of the NT
# annotated by the training examples.
if train_selection == "hard_sample":
baseline_feature, _ = attention_output(buffer,
word_weights, "soft_average")
log_probs_baseline =
dy.log_softmax(self.nt_proj_layer(baseline_feature))
r = dy.nobackprop(dy.pick(log_probs_nt, nt) -
dy.pick(log_probs_baseline, nt))
losses.append(-output_logprob * dy.rectify(r))
stack_state, label, _ = stack[-1] if stack else (stack_top, 'ROOT',
stack_top)
nt_embedding = self.nt_input_layer(self.nt_lookup[nt])
stack_state = stack_state.add_input(nt_embedding)
stack.append((stack_state, 'p', nt_embedding)) # 'p' for parent.
-
規約過程
規約時,先彈棧至剛將語意解析樹的父節點對應的三元組彈出,記錄每個三元組中的原始表達(也即詞向量經一層線性層處理得到的向量)。
將彈出的得到的葉節點對應的原始表達求平均,再和父節點的原始表達拼接得到組合表達 composed_rep,再將組合表達作為 stack 的 LSTM 的下一個輸入,構造新的隱層單元 stack_state,最後將以下三元組入棧。

#subtree completion
found_p = 0
path_input = []
#keep popping until the parent is found
while found_p != 1:
top = stack.pop()
top_raw_rep, top_label, top_rep = top[2], top[1], top[0]
# Raw representation, label('c' or 'p') and representation
respectively.
path_input.append(top_raw_rep)
if top_label == 'p':
found_p = 1
parent_rep = path_input.pop()
composed_rep =
self.subtree_input_layer(dy.concatenate([dy.average(path_input),
parent_rep]))
stack_state, _, _ = stack[-1] if stack else (stack_top, 'ROOT',
stack_top)
stack_state = stack_state.add_input(composed_rep)
stack.append((stack_state, 'c', composed_rep))
reduced = 1
這部分的完整程式碼見附錄-程式碼-top_down_train。
5. 最後將 loss 反向傳播可更新所有的引數。
這裡先給出用於訓練預測動作序列的標的函式,其中 T 表示訓練樣本集。訓練邏輯表達預測的標的函式在下文給出。

測試過程
測試過程與訓練過程相比,每次狀態轉移用到的動作以及動作的引數都是經過類似過程取對數機率最大對應的來預測得到的,而非採用標註資訊。
根據問題答案標註獲得標註邏輯表示
給出了問題答案的標註,本文透過物體連結(entity linking),將自然語言問題中的物體與知識庫的物體進行匹配,可以得到一些候選子圖,這些子圖可以生成候選的邏輯表示,最終選擇可以搜尋的到正確答案的邏輯表示作為標註邏輯表示指導訓練。
對於沒有經過物體連結的訓練集,本文使用 7 個手工模版,配合知識庫,將訓練集的物體標註出來,然後用這些物體去訓練結構化感知機(structrued perceptron)來進行物體消歧。
中間邏輯表示與最終邏輯表示
對於有邏輯表示標註的訓練樣本,最終邏輯表示(也即匹配了知識庫的邏輯表示)和中間邏輯表示是一樣的;而適用於僅僅標註了答案的訓練樣本的版本的程式碼沒有完全給出(一些重要的部分沒有再程式碼裡實現)。這裡結合作者取用的另外一文章來討論可能的具體實現方式。
Tao Lei, Regina Barzilay, and Tommi Jaakkola. 2016. Rationalizing neural predictions. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing. Austin, Texas, pages 107–117.
中間邏輯表示(ungrounded representation)和最終邏輯表示(grounded representation)之間的對映關係:作者給出了一個假設,假設兩種同樣語意的邏輯表示是同構的,也即兩種表示的語法樹相同,只是謂詞或者終結符的字串可能不同。所以在這種假設下,兩者之間的轉換僅僅變成了一個詞彙對映的問題。
對映關係建模:使用雙線性神經網路來刻畫中間邏輯表示項 ut(ungrounded term)到最終邏輯表示項 gt(grounded term)的後驗機率:
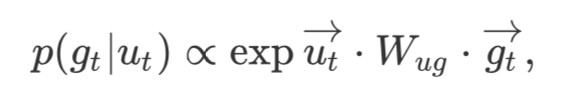
其中,![]() 為上文提到的以自然語言問題輸入為輸入的雙向 LSTM 的關於某一個中間邏輯表示項的輸出;
為上文提到的以自然語言問題輸入為輸入的雙向 LSTM 的關於某一個中間邏輯表示項的輸出;![]() 為最終邏輯表示項的嵌入表示,Wug 為權值矩陣。
為最終邏輯表示項的嵌入表示,Wug 為權值矩陣。
特定領域(closed domain)vs. 開放領域(open domain):對於特定領域,作者認為中間層的邏輯表示已經可為語意解析提供足夠多的背景關係資訊,可以直接選擇對應上述後驗機率最大的最終表達作為輸出(在特定領域內,一個中間表示項一般只匹配一個最終表示項);而對於開放領域,如Freebase,這種表示得建模顯得有些乏力。
對於開放領域語意解析,本文設計訓練了一個額外的排序模型,對可能的最終表示進行排序取序最靠前的解。這個排序模型使用最大熵分類器,以手工設計的關於兩種邏輯表示之間的關係的資訊表示為特徵,最佳化以使得預測的最終邏輯表示在知識庫上搜索的到的答案準確率最高。
標的函式:由於邏輯中間表示項是隱變數(latent variable),作者採用最大化邏輯最終表示項的期望對數似然 p(u|x)logp(g|u,x) 的方式來構建最佳化標的:

結合上文提到的對動作預測的最佳化標的 La,可以得到最終的最佳化標的:
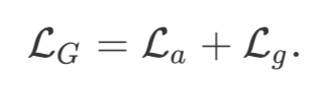
標的函式最佳化:作者採用了另一篇文獻最佳化有隱變數的模型的演演算法。在這篇取用文章中,處理的問題是文字分類,和本文的模型結構類似,有兩層結構(涉及到一個生成器和一個編碼器,生成器生成中間變數),中間連線的變數是隱變數。
這篇取用文章的求解任務是想要對文字提取一些原文的片段(對應 gen(⋅),generate)作為梗概資訊(rationales),使得這些梗概資訊儘量短的前提下盡可能與原始文字作為輸入進行文字分類(對應 enc(⋅),encode)的效果一致。這就涉及到了生成梗概資訊的問題,而取用文章的作者又試圖想把生成器和編碼器一起訓練(訓練enc(gen(x)))。
取用文章的最終的標的函式為:
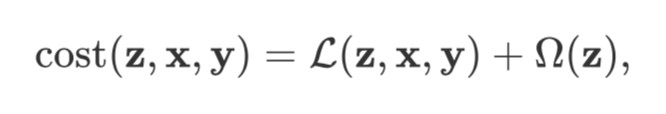
其中,z,x,y 分別表示梗概資訊,原始輸入以及標註結果;L 懲罰編碼器和標註結果的距離,Ω 懲罰中間生成的梗概的長度。由於中間項在訓練過程中不能被提供,所以作者試圖最小化期望損失(相當於把 z 消掉):

其中 θe,θg 分別表示編碼器和生成器的引數。作者假設用生成器取樣中間項對於問題是可行的。藉助恆等式:

可以求得上述期望損失對兩個引數的導數:

以及:

這樣對 z 使用生成器進行取樣,固定 z 就可以求得上述兩式裡邊的微分,進而可以求得對期望損失的微分,最後使用梯度最佳化的演演算法來更新引數。
從兩個微分等式可以看出,生成 z,可以利用編碼器的預測結果指導更新生成器的引數;生成器被最佳化後,中間項的分佈發生了改變,又會指導編碼器的最佳化過程,類似於 EM 演演算法互動更新來學習隱變數的過程。
類比取用文章的求解方式,可以假定使用之前提到的雙向 LSTM 來對邏輯中間表示項進行取樣可以滿足問題需求,則有:

其中,BiLSTM(x) 為邏輯中間表示的生成器,θu 為生成器的引數。
實驗
資料集
GEOQUERY:關於美國地理的 880 個問題以及知識庫,並標註有邏輯表示。這些問題句子雖然組合性(compositional)強,但語言過於簡單,詞彙量過於小,大多數問題涉及物體不超過一個。
SPADES:包含 93,319 個從資料集 CLUEWEB09 透過隨機去除物體獲得的問題集合,僅僅標註有問題答案。雖然語料的組合性不強,但規模很大,並且每個句子包含 2 個或多個物體。
WEBQUESTIONS:包含 5810 個問題-答案對。同樣組合性不強,但問題均來源於真實的網路資料。
GRAPHQUESTIONS:包含 5166 個問題-答案對,來源於將 500 個 Freebase 的圖查詢由亞馬遜員工轉換成的自然語言問題。
評價指標
本文使用準確率以及 F1 值作為評價指標,這裡透過計算預測得到的語意表達與真實標註的一致比率來得到。
實驗結果

Table 5:下邊隔開的一塊內的模型均為神經模型。Dong and Lapata (2016) 將語意解析問題視為序列預測問題,使用 LSTM 直接將自然語言句子對映到邏輯形式。
Table 6:這裡之前的工作與本系統處理的總體思路類似,均是將自然語言句子對映到中間邏輯表示然後再匹配知識庫。
Table 3:隔開的第一塊內的模型均為符號系統(symbolic systems)模型。其中Bast and Haussmann (2015) 提出了一個相反的問答模型,不能產生語意表達。Berant and Liang (2015) 借鑒模仿學習(imitation learning)的思想,提出了一個複雜的基於智慧體(agenda-based)的解析器。Reddy et al. (2016) 與本文概念上相似,也是透過語意中間表示來訓練一個語意解析器,其中這個中間表示基於依存關係解析器的輸出構建。
隔開的第二塊內的模型為一些神經系統。Xu et al. (2016) 在這個資料集上到了目前最好的效能,他們的系統利用維基百科來過濾掉從 Freebase 抽取的錯誤候選答案。
Table 4:比較的是三個符號系統和一個神經系統基準。
中間邏輯表示分析
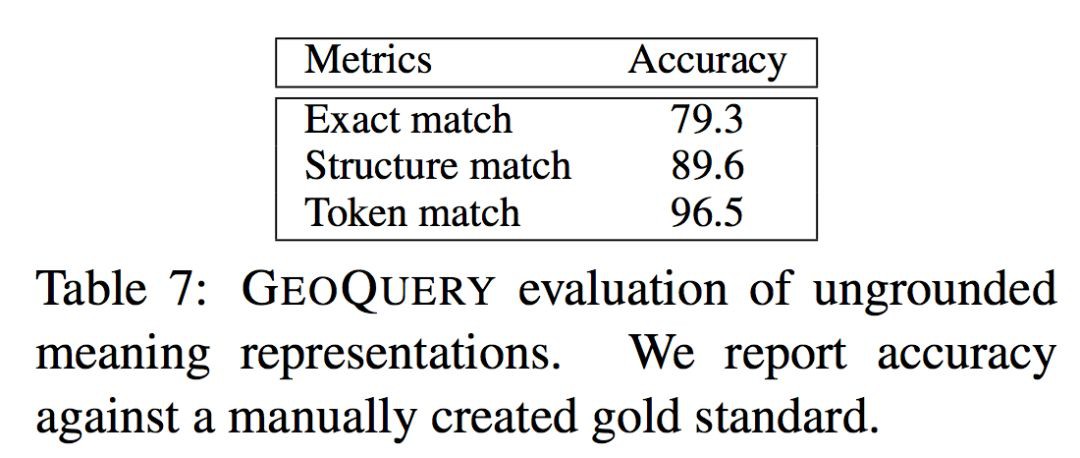


這裡進行了一些額外的實驗來檢驗邏輯中間表示的生成質量。
Table 7:作者手工標註了一些邏輯中間表示,以此來觀察人的介入對邏輯中間表示的生成效果的影響。三行結果分別對應了不同的匹配標準。
Table 8:為了在其他 3 個資料集上也能夠進行類似的實驗,作者將評價方式換為對比生成的邏輯中間表示與句法分析器分析結果。作者用 EasyCCG 將自然語言問題句子轉換為事件-引數(event-argument)的結構。分析看出對於組合性強的資料集 GRAPHQUESTIONS,本文的系統效能差一些。
Table 9:展示了一些謂詞預測結果的事例,並與 EasyCCG 的結果相對比。對於例子:
ceo johnthain agreed to leave_.
本文的系統會難以區分控制(control)動詞和真正的謂詞。
附錄
通用謂詞
適用於 GEOQUERY 的通用謂詞表如下:(還需要再進行擴充套件,才能夠使用於通用領域)
coutryid
cityid
stateid
riverid
placeid
answer
largest
smallest
highest
lowest
longest
shortest
count
fewest
intersect
union
exclude
all
_
程式碼
parse_list
def parse_list(tokens):
# expect '(' always as first token for this function
if len(tokens) == 0 or tokens[0] != '(':
raise SyntaxError("(parse_list) Error: expected '(' token, found " % str(tokens))
first = tokens.pop(0) # consume the opening '('
# consume the operator and all operands
operator = tokens.pop(0) # operator always after opening ( syntatically
operands, tokens = parse_operands(tokens)
ast = [operator]
ast.extend(operands)
# consume the matching ')'
if len(tokens) == 0 or tokens[0] != ')':
raise SyntaxError("(parse_list) Error: expected ')' token, found : " % str(tokens))
first = tokens.pop(0)
return ast, tokens
parseo_perands
def parse_operands(tokens):
operands = []
while len(tokens) > 0:
# peek at next token, and if not an operand then stop
if tokens[0] == ')':
break
# if next token is a '(', need to get sublist/subexpression
if tokens[0] == '(':
subast, tokens = parse_list(tokens)
operands.append(subast)
continue # need to continue trying to see if more operands after the sublist
# otherwise token must be some sort of an operand
operand = tokens.pop(0) # consume the token and parse it
operands.append(decode_operand(operand))
return operands, tokens
construct_from_list
def construct_from_list(self, content):
'''build the tree from hierarchical list'''
if sexp.is_string(content):
identifier = self.node_count
new_node = Node(identifier, content)
self[identifier] = new_node
self.node_count += 1
return identifier
else:
identifier = self.node_count
new_node = Node(identifier, content[0])
self[identifier] = new_node
self.node_count += 1
for child in content[1:]:
child_identifier = self.construct_from_list(child)
self[identifier].add_child(child_identifier)
return identifier
top_down
def top_down(self, identifier, general_predicates):
'''
pre-order traversal, return a list of node content and a list of transition actions
ACT: reduce top elements on the stack into a subtree
NT: creates a subtree root node which is to be expanded, and push it to the stack
TER: generates terminal node under the current subtree
'''
data = []
action = []
def recurse(identifier):
node = self[identifier]
if len(node.children) == 0:
data.append(node.content)
action.append('TER')
else:
data.append(node.content)
if node.content in general_predicates:
action.append("{}({})".format('NT', node.content))
else:
action.append('NT')
for child in node.children:
recurse(child)
action.append('ACT')
recurse(identifier)
return data, action
top_down_train
def top_down_train(self, words, oracle_actions, oracle_tokens, options, buffer, stack_top, action_top):
stack = []
losses = []
reducable = 0
reduced = 0
#recursively generate the tree until training data is exhausted
while not (len(stack) == 1 and reduced != 0):
valid_actions = []
if len(stack) == 0:
valid_actions += [self._ROOT]
if len(stack) >= 1:
valid_actions += [self._TER, self._NT] + self._NT_general
if len(stack) >= 2 and reducable != 0:
valid_actions += [self._ACT]
action = self.act_vocab[oracle_actions.pop(0)] # Get the action identifier.
word_weights = None
#we make predictions when stack is not empty and _ACT is not the only valid action
if len(stack) > 0 and valid_actions[0] != self._ACT:
stack_embedding = stack[-1][0].output() # stack[-1] means the last one in the list 'stack'.
action_summary = action_top.output()
word_weights = self.attention(stack_embedding, buffer) # Get the attention weight list of the encoding words.
buffer_embedding, _ = attention_output(buffer, word_weights, 'soft_average')
# Get the attention-weighted word embedding vectors (a vector).
for i in range(len(stack)):
if stack[len(stack)-1-i][1] == 'p':
parent_embedding = stack[len(stack)-1-i][2]
# parent_embedding is just the embeding vector computed from
# the word vector into a linear layer Wx+b.
# Just the word vector without processing
# into the hidden state.
break
parser_state = dy.concatenate([buffer_embedding, stack_embedding, parent_embedding, action_summary])
h = self.mlp_layer(parser_state)
if options.dropout > 0:
h = dy.dropout(h, options.dropout)
if len(valid_actions) > 0:
log_probs = dy.log_softmax(self.act_proj_layer(h), valid_actions)
assert action in valid_actions, "action not in scope"
losses.append(-dy.pick(log_probs, action))
# Append the corresponding log probability of the action
# annotated by the training examples.
# Carrying on dealing with the action from the training example.
if action == self._NT:
# If the aciton is NT, then caculate the log probability of
# the corresponding annotated term choices.
#generate non-terminal
nt = self.nt_vocab[oracle_tokens.pop(0)]
#no need to predict the ROOT (assumed ROOT is fixed)
if word_weights is not None:
train_selection = self.train_selection if np.random.randint(10) > 5 else "soft_average"
output_feature, output_logprob = attention_output(buffer, word_weights, train_selection)
log_probs_nt = dy.log_softmax(self.nt_proj_layer(output_feature))
losses.append(-dy.pick(log_probs_nt, nt))
# Append the corresponding log probability of the NT
# annotated by the training examples.
if train_selection == "hard_sample":
baseline_feature, _ = attention_output(buffer, word_weights, "soft_average")
log_probs_baseline = dy.log_softmax(self.nt_proj_layer(baseline_feature))
r = dy.nobackprop(dy.pick(log_probs_nt, nt) - dy.pick(log_probs_baseline, nt))
losses.append(-output_logprob * dy.rectify(r))
stack_state, label, _ = stack[-1] if stack else (stack_top, 'ROOT', stack_top)
nt_embedding = self.nt_input_layer(self.nt_lookup[nt])
stack_state = stack_state.add_input(nt_embedding)
stack.append((stack_state, 'p', nt_embedding)) # 'p' for parent.
elif action in self._NT_general:
nt = self.nt_vocab[oracle_tokens.pop(0)]
stack_state, label, _ = stack[-1] if stack else (stack_top, 'ROOT', stack_top)
nt_embedding = self.nt_input_layer(self.nt_lookup[nt])
stack_state = stack_state.add_input(nt_embedding)
stack.append((stack_state, 'p', nt_embedding))
elif action == self._TER:
#generate terminal
ter = self.ter_vocab[oracle_tokens.pop(0)]
output_feature, output_logprob = attention_output(buffer, word_weights, self.train_selection)
log_probs_ter = dy.log_softmax(self.ter_proj_layer(output_feature))
losses.append(-dy.pick(log_probs_ter, ter))
if self.train_selection == "hard_sample":
baseline_feature, _ = attention_output(buffer, word_weights, "soft_average")
#baseline_feature, _ = attention_output(buffer, word_weights, self.train_selection, argmax=True)
log_probs_baseline = dy.log_softmax(self.ter_proj_layer(baseline_feature))
r = dy.nobackprop(dy.pick(log_probs_ter, ter) - dy.pick(log_probs_baseline, ter))
losses.append(-output_logprob * dy.rectify(r))
stack_state, label, _ = stack[-1] if stack else (stack_top, 'ROOT', stack_top)
ter_embedding = self.ter_input_layer(self.ter_lookup[ter])
stack_state = stack_state.add_input(ter_embedding)
stack.append((stack_state, 'c', ter_embedding)) # 'c' for child.
else:
# Into this branch means having met a reduce(ACT) action.
#subtree completion
found_p = 0
path_input = []
#keep popping until the parent is found
while found_p != 1:
top = stack.pop()
top_raw_rep, top_label, top_rep = top[2], top[1], top[0]
# Raw representation, label('c' or 'p') and representation respectively.
path_input.append(top_raw_rep)
if top_label == 'p':
found_p = 1
parent_rep = path_input.pop()
composed_rep = self.subtree_input_layer(dy.concatenate([dy.average(path_input), parent_rep]))
stack_state, _, _ = stack[-1] if stack else (stack_top, 'ROOT', stack_top)
stack_state = stack_state.add_input(composed_rep)
stack.append((stack_state, 'c', composed_rep))
reduced = 1
action_embedding = self.act_input_layer(self.act_lookup[action])
action_top = action_top.add_input(action_embedding)
reducable = 1
#cannot reduce after an NT
if stack[-1][1] == 'p':
reducable = 0
return dy.esum(losses)

點選標題檢視更多論文解讀:

▲ 戳我檢視招聘詳情
 #崗 位 推 薦#
#崗 位 推 薦#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文