作者:Piotr Krewski&Adam; Kawa 翻譯:陳之炎 校對:丁楠雅
本文約6000字,建議閱讀10分鐘。
本文為你介紹Hadoop的核心概念,描述其體系架構,指導您如何開始使用Hadoop以及在Hadoop上編寫和執行各種應用程式。
作者:GETINDATA公司創始人兼大資料顧問彼得亞·雷克魯斯基(Piotr Krewski)和GETINDATA公司執行長兼創始人亞當·卡瓦(Adam Kawa)
目錄
-
內容簡介
-
設計理念
-
HADOOP元件
-
HDFS
-
YARN
-
YARN 應用程式
-
監控 YARN 應用程式
-
用HADOOP處理資料
-
HADOOP 的其它工具
-
其它資源
內容簡介
Hadoop是目前最流行的大資料軟體框架之一,它能利用簡單的高階程式對大型資料集進行分散式儲存和處理。本文將介紹Hadoop的核心概念,描述其體系架構,指導您如何開始使用Hadoop以及在Hadoop上編寫和執行各種應用程式。
Hadoop是阿帕奇(Apache)軟體基金會釋出的一個開源專案,它可以安裝在伺服器叢集上,透過伺服器之間的通訊和協同工作來儲存和處理大型資料集。因為能夠高效地處理大資料,Hadoop近幾年獲得了巨大的成功。它使得公司可以將所有資料儲存在一個系統中,並對這些資料進行分析,而這種規模的大資料分析用傳統解決方案是無法實現或實現起來代價巨大的。
以Hadoop為基礎開發的大量工具提供了各種各樣的功能,Hadoop還出色地集成了許多輔助系統和實用程式,使得工作更簡單高效。這些元件共同構成了Hadoop生態系統。
Hadoop可以被視為一個大資料作業系統,它能在所有大型資料集上執行不同型別的工作負載,包括離線批處理、機器學習乃至實時流處理。
您可以訪問hadoop.apache.org網站獲取有關該專案的更多資訊和詳細檔案。
您可以從hadoop.apache.org獲取程式碼(推薦使用該方法)來安裝Hadoop,或者選擇Hadoop商業發行版。最常用的三個商業版有Cloudera(CDH)、Hortonworks(HDP)和MapR。這些商業版都基於Hadoop的框架基礎,將一些元件進行了打包和增強,以實現較好的整合和相容。此外,這些商業版還提供了管理和監控平臺的(開源或專有的)工具。
設計理念
Hadoop在解決大型資料集的處理和儲存問題上,根據以下核心特性構建:
-
分散式:儲存和處理並非構建在一臺大型超級計算機之上,而是分佈在一群小型電腦上,這些電腦之間可以相互通訊並協同工作。
-
水平可伸縮性:只需新增新機器就可以很容易地擴充套件Hadoop叢集。每臺新機器都相應地增加了Hadoop叢集的總儲存和處理能力。
-
容錯:即使一些硬體或軟體元件不能正常工作,Hadoop也能繼續執行。
-
成本最佳化:Hadoop不需要昂貴的高階伺服器,而且在沒有商業許可證的情況下也可以正常工作。
-
程式設計抽象:Hadoop負責處理與分散式計算相關的所有紛雜的細節。由於有高階API,使用者可以專註於實現業務邏輯,解決他們在現實世界中的問題。
-
資料本地化:Hadoop不會將大型資料集遷移到應用程式正在執行的位置,而是在資料所在位置執行應用程式。
Hadoop元件
Hadoop有兩個核心元件:
-
HDFS:分散式檔案系統
-
YARN:叢集資源管理技術
許多執行框架執行在YARN之上,每個框架都針對特定的用例進行調優。下文將在“YARN應用程式”中重點討論。
我們來看看它們的架構,瞭解一下它們是如何合作的。
HDFS
HDFS是Hadoop分散式檔案系統。
它可以在許多伺服器上執行,根據需要,HDFS可以輕鬆擴充套件到數千個節點和乃至PB(Petabytes 10的15次方位元組)量級的資料。
HDFS設定容量越大,某些磁碟、伺服器或網路交換機出故障的機率就越大。
HDFS透過在多個伺服器上複製資料來修複這些故障。
HDFS會自動檢測給定元件是否發生故障,並採取一種對使用者透明的方式進行必要的恢復操作。
HDFS是為儲存數百兆位元組或千兆位元組的大型檔案而設計的,它提供高吞吐量的流式資料訪問,一次寫入多次讀取。因此對於大型檔案而言,HDFS工作起來是非常有魅力的。但是,如果您需要儲存大量具有隨機讀寫訪問許可權的小檔案,那麼RDBMS和Apache HBASE等其他系統可能更好些。
註:HDFS不允許修改檔案的內容。只支援在檔案末尾追加資料。不過,Hadoop將HDFS設計成其許多可插拔的儲存選件之一。例如:專用檔案系統MapR-Fs的檔案就是完全可讀寫的。其他HDFS替代品包括Amazon S3、Google Cloud Storage和IBM GPFS等。
HDFS架構
HDFS由在選定叢集節點上安裝和執行的下列行程組成:
-
NameNode:負責管理檔案系統名稱空間(檔案名、許可權和所有權、上次修改日期等)的主行程。控制對儲存在HDFS中的資料的訪問。如果NameNode關閉,則無法訪問資料。幸運的是,您可以配置多個NameNodes,以確保此關鍵HDFS過程的高可用性。
-
DataNodes:安裝在負責儲存和服務資料的叢集中的每個工作節點上的從行程。

圖1說明瞭在一個4節點的叢集上安裝HDFS。一個節點的主機節點為NameNode行程而其他三節點為DataNode行程
註:NameNode和DataNode是在Linux作業系統 (如RedHat、CentOS、Ubuntu等)之上執行的Java行程。它們使用本地磁碟儲存HDFS資料。
HDFS將每個檔案分成一系列較小但仍然較大的塊(預設的塊大小等於128 MB–更大的塊意味著更少的磁碟查詢操作,從而導致更大的吞吐量)。每個塊被冗餘地儲存在三個DataNode上,以實現容錯(每個檔案的副本數量是可配置的)。
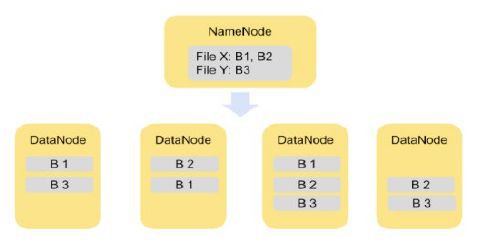
圖2演示了將檔案分割成塊的概念。檔案X被分割成B1和B2塊,Y檔案只包含一個塊B3。在叢集上將所有塊做兩個備份。
與HDFS互動
HDFS提供了一個簡單的類似POSIX的介面來處理資料。使用HDFS DFS命令執行檔案系統操作。
要開始使用Hadoop,您不必經歷設定整個叢集的過程。Hadoop可以在一臺機器上以
所謂的偽分散式樣式執行。您可以下載sandbox虛擬機器,它自帶所有HDFS元件,使您可以隨時開始使用Hadoop!只需按照以下連結之一的步驟:
-
mapr.com/products/mapr-sandbox-hadoop
-
hortonworks.eom/products/hortonworks-sandbox/#install
-
cloudera.com/downloads/quickstart_vms/5-12.html
HDFS使用者可以按照以下步驟執行典型操作:
-
列出主目錄的內容:
$ hdfs dfs -ls /user/adam
-
將檔案從本地檔案系統載入到HDFS:
$ hdfs dfs -put songs.txt /user/adam
-
從HDFS讀取檔案內容:
$ hdfs dfs -cat /user/adam/songs.txt
-
更改檔案的許可權:
$ hdfs dfs -chmod 700 /user/adam/songs.txt
-
將檔案的複製因子設定為4:
$ hdfs dfs -setrep -w 4 /user/adam/songs.txt
-
檢查檔案的大小:
‘$ hdfs dfs -du -h /user/adam/songs.txt Create a subdirectory in your home directory.
$ hdfs dfs -mkdir songs
註意,相對路徑總是取用執行命令的使用者的主目錄。HDFS上沒有“當前”目錄的概念(換句話說,沒有“CD”命令):
-
將檔案移到新建立的子目錄:
$ hdfs dfs -mv songs.txt songs
-
從HDFS中刪除一個目錄:
$ hdfs dfs -rm -r songs
註:刪除的檔案和目錄被移動到trash中 (HDFS上主目錄中的.trash),並保留一天才被永久刪除。只需將它們從.Trash複製或移動到原始位置即可恢復它們。
您可以在沒有任何引數的情況下鍵入HDFS DFS以獲得可用命令的完整串列。
如果您更喜歡使用圖形介面與HDFS互動,您可以檢視免費的開源HUE (Hadoop使用者體驗)。它包含一個方便的“檔案瀏覽器”元件,允許您瀏覽HDFS檔案和目錄並執行基本操作。
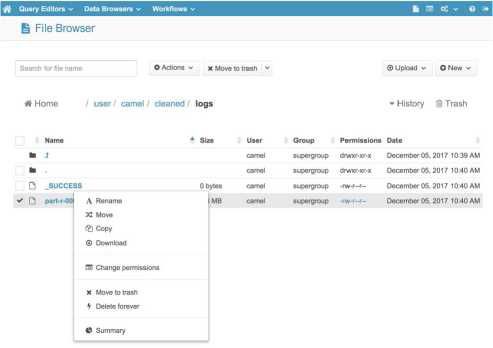
您也可以使用HUE的“上傳”按鈕,直接從您的計算機上傳檔案到HDFS。
YARN
YARN (另一個資源協商器)負責管理Hadoop叢集上的資源,並允許執行各種分散式應用程式來處理儲存在HDFS上的資料。
YARN類似於HDFS,遵循主從設計,ResourceManager行程充當主程式,多個NodeManager充當工作人員。它們的職責如下:
ResourceManager
-
跟蹤叢集中每個伺服器上的LiveNodeManager和可用計算資源的數量。
-
為應用程式分配可用資源。
-
監視Hadoop叢集上所有應用程式的執行情況。
NodeManager
-
管理Hadoop叢集中單個節點上的計算資源(RAM和CPU)。
-
執行各種應用程式的任務,並強制它們在限定的計算資源範圍之內。
YARN以資源容器的形式將叢集資源分配給各種應用程式,這些資源容器代表RAM數量和CPU核數的組合。
在YARN叢集上執行的每個應用程式都有自己的ApplicationMaster行程。當應用程式被安排在叢集上並協調此應用程式中所有任務的執行時,此過程就開始了。
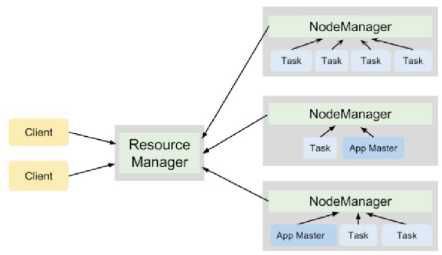
圖3展示了YARN行程在4節點叢集上執行兩個應用程式的協作情況,共計產生7個任務。
HADOOP = HDFS + YARN
在同一個叢集上執行的HDFS和YARN為我們提供了一個儲存和處理大型資料集的強大平臺。
DataNode和NodeManager行程配置在相同的節點上,以啟用本地資料。這種設計允許在儲存資料的機器上執行計算,從而將透過網路傳送大量資料的必要性降到最低,使得執行時間更快。

YARN 應用程式
YARN僅僅是一個資源管理器,它知道如何將分散式計算資源分配給執行在Hadoop叢集上的各種應用程式。換句話說,YARN本身不提供任何處理邏輯來分析HDFS中的資料。因此,各種處理框架必須與YARN整合(透過提供ApplicationMaster實現),以便在Hadoop叢集上執行,並處理來自HDFS的資料。
下麵介紹幾個最流行的分散式計算框架,這些框架都可以在由YARN驅動的Hadoop叢集上執行。
-
MapReduce:Hadoop的最傳統和古老的處理框架,它將計算表示為一系列對映和歸約的任務。它目前正在被更快的引擎,如Spark或Flink所取代。
-
Apache Spark:用於處理大規模資料的快速通用引擎,它透過在記憶體中快取資料來最佳化計算(下文將詳細介紹)。
-
Apache Flink:一個高吞吐量、低延遲的批處理和流處理引擎。它以其強大的實時處理大資料流的能力脫穎而出。下麵這篇綜述文章介紹了Spark和Flink之間的區別:dzone.com/ports/apache-Hadoop-vs-apache-smash
-
Apache Tez:一個旨在加速使用Hive執行SQL查詢的引擎。它可在Hortonworks資料平臺上使用,在該平臺中,它將MapReduce替換為Hive.k的執行引擎。
監控YARN應用程式
使用ResourceManager WebUI可以跟蹤執行在Hadoop叢集上的所有應用程式的執行情況,預設情況下,它在埠8088。

每個應用程式都可以讀取大量重要資訊。
使用ResourceManager WebUI,可以檢查RAM總數、可用於處理的CPU核數量以及
當前Hadoop叢集負載。檢視頁面頂部的“叢集度量”。
單擊”ID”列中的條目,可以獲得有關所選應用程式執行的更詳細的度量和統計資料。
用HADOOP處理資料
有許多框架可以簡化在Hadoop上實現分散式應用程式的過程。在本節中,我們將重點介紹最流行的幾種:HIVE和Spark。
HIVE
Hive允許使用熟悉的SQL語言處理HDFS上的資料。
在使用Hive時,HDFS中的資料集表示為具有行和列的表。因此,對於那些已經瞭解SQL並有使用關係資料庫經驗的人來說,Hive很容易學習。
Hive不是獨立的執行引擎。每個Hive查詢被翻譯成MapReduce,Tez或Spark程式碼,隨後在Hadoop叢集中得以執行。
HIVE 例子
讓我們處理一個關於使用者在一段時間裡聽的歌曲的資料集。輸入資料由一個名為Song s.tsv的tab分隔檔案組成:
Creep” Radiohead piotr 2017-07-20 Desert Rose” Sting adam 2017-07-14 Desert Rose” Sting piotr 2017-06-10 Karma Police” Radiohead adam 2017-07-23 Everybody” Madonna piotr 2017-07-01 Stupid Car” Radiohead adam 2017-07-18 All This Time” Sting adam 2017-07-13
現在用Hive尋找2017年7月份兩位最受歡迎的藝術家。
將Song s.txt檔案上傳HDFS。您可以在HUE中的“File Browser”幫助下完成此操作,也可以使用命令列工具鍵入以下命令:
# hdfs dfs -mkdir /user/training/songs
# hdfs dfs -put songs.txt /user/training/songs
使用Beeline客戶端進入Hive。您必須向HiveServer 2提供一個地址,該行程允許遠端客戶端(如Beeline)執行Hive查詢和檢索結果。
# beeline
beeline> !connect jdbc:hive2://localhost:10000
在Hive中建立一個指向HDFS資料的表(請註意,我們需要指定檔案的分隔符和位置,以便Hive可以將原始資料表示為表):

使用Beeline開始會話後,您建立的所有表都將位於“預設”資料庫下。您可以透過提供特定的資料庫名稱作為表名的字首,或者鍵入“use
Check if the table was created successfully: beeline> SHOW tables; Run a query that finds the two most popular artists in July, 2017:
檢查表建立是否成功:beeline>>顯示表;執行一個查詢,找到在2017年7月份兩位最受歡迎的藝術家:
SELECT artist, COUNT(\*) AS total FROM songs
WHERE year(date) = 2017 AND month(date) = 7 GROUP BY artist ORDER BY total DESC LIMIT 2;
您可以使用ResourceManager WebUI監視查詢的執行情況。根據配置,您將看到MapReduce作業或Spark應用程式在叢集上的執行情況。
註:您還可以從HUE中編寫和執行Hive查詢。有一個專門用於Hive查詢的編輯器,具有語法自動完成和著色、儲存查詢、以及以行、條形或餅圖形顯示結果等基本功能。
SPARK
Apache Spark是一個通用的分散式計算框架。它與Hadoop生態系統友好整合,Spark應用程式可以很容易地在YARN上執行。
與傳統的Hadoop計算正規化MapReduce相比,Spark在滿足不同的資料處理需求的同時提供了出色的效能、易用性和通用性。
Spark的速度主要來自它在RAM中儲存資料的能力,在後續執行步驟中對執行策略和序列資料進行最佳化。
讓我們直接到程式碼中去體驗一下Spark。我們可以從Scala、Java、Python、SQL或RAPI中進行選擇。這個例子是用Python寫的。啟動Spark Python shell(名為pyspark)
輸入 # pyspark.
片刻之後,你會看到一個Spark提示。這意味著Spark應用程式已在YARN上啟動。(您可以轉到ResourceManager WebUI進行確認;查詢一個名為“PySparkShell”的正在執行的應用程式)。
如果您不喜歡使用shell,則可以檢視基於web的筆記本,如jupyter.org或Zeppelin(zeppelin.apache.org)。
作為使用Spark的Python DataFrame API的一個示例,我們實現與Hive相同的邏輯,找到2017年7月兩位最受歡迎的藝術家。
首先,我們必須從Hive表中讀取資料# songs = spark.table(MsongsM)
Spark中的資料物件以所謂的dataframe的方式呈現。Dataframes是不可變的,是透過從不同的源系統讀取資料或對其他資料檔案應用轉換而生成的。
呼叫Show()方法預覽dataframe的內容:

為了獲得預期的結果,我們需要使用多個直觀的函式:
# from pyspark.sql.functions import desc
# songs.filter(Myear(date) = 2017 AND month(date) = 7″) \
.groupBy(MartistM) \
.count() \
.sort(desc(“count”)) \
.limit(2) \
.show()
Spark的dataframe轉換看起來類似於SQL運運算元,因此它們非常容易使用和理解。
如果您對相同的dataframe執行多個轉換(例如建立一個新的資料集),您可以透過呼叫dataframe上的cache()方法(例如Song s.cache()),告訴Spark在記憶體中儲存它。Spark會將您的資料儲存在RAM中,併在執行後續查詢時避免觸及磁碟,從而使您獲得更好的效能。
Dataframes只是Spark中可用的API之一。此外,還有用於近實時處理(Spark流)、機器學習(MLIB)或圖形處理(圖形幀)的API和庫。
由於Spark的功能豐富,您可以使用它來解決各種各樣的處理需求,保持在相同的框架內,併在不同的背景關係(例如批處理和流)之間共享程式碼片段。
Spark可以直接將資料讀寫到許多不同的資料儲存區,而不僅僅是HDFS。您可以輕鬆地從MySQL或Oracle表中的記錄、HBASE中的行、本地磁碟上的JSON檔案、ElasticSearch中的索引資料以及許多其他的資料中建立資料。
Hadoop的其他工具
Hadoop生態系統包含許多不同的工具來完成現代大資料平臺的特定需求。下文列舉了一些前面章節中沒有提到的流行和重要專案的串列。
-
Sqoop:從關係資料儲存區和HDFS/HFE及其他方式遷移資料的不可缺少的工具。
您可以使用命令列與Sqoop互動,選擇所需的操作並提供一系列控制資料遷移過程的必要引數。
從MySQL表匯入有關使用者的資料只需鍵入以下命令:
# sqoop import \
–connect jdbc:mysql://localhost/streamrock \
–username $(whoami) -P \
–table users \
–hive-import
註:Sqoop使用MapReduce在關係型資料庫和Hadoop之間傳輸資料。你可以跟蹤由ResourceManager WebUI Sqoop提交的MapReduce應用。
-
Oozie:Hadoop的協調和編排服務。
使用Oozie,您可以構建一個在Hadoop叢集上執行的不同操作的工作流(例如HDFS命令、Spark應用程式、Hive查詢、Sqoop匯入等等),然後為自動執行安排工作流。
-
HBase:一個建立在HDFS之上的NoSQL資料庫。它允許使用行鍵對單個記錄進行非常快速的隨機讀寫。
-
Zookeeper:Hadoop的分散式同步和配置管理服務。大量的Hadoop服務利用Zookeeper正確有效地在分散式環境中工作。
小結
Apache Hadoop是用於大資料處理的最流行的平臺,這得益於諸如線性可伸縮性、高階APIs、能夠在異構硬體上執行(無論是在前端還是在雲中)、容錯和開源等特性。十多年來,Hadoop已經被許多公司成功地應用於生產中。
Hadoop生態系統提供了各種開源工具,用於收集、儲存和處理資料,以及叢集部署、監視和資料安全。多虧了這個令人驚嘆的工具生態系統,每一家公司現在都可以以一種分散式和高度可伸縮的方式輕鬆、廉價地儲存和處理大量的資料。
其他資源
-
hadoop.apache.org
-
hive.apache.org
-
spark.apache.org
-
spark.apache.org/docs/latest/sql-programming-guide.html
-
dzone.com/articles/apache-hadoop-vs-apache-spark
-
dzone.com/articles/hadoop-and-spark-synergy-is-real
-
sqoop.apache.orgdzone.com/articles/sqoop-import-data-from-mysql-to-hive
-
oozie.apache.org
-
tez.apache.org
主要的工具包:
-
Cloudera: cloudera.com/content/cloudera/en/products- and-services/cdh.html
-
MapR: mapr.com/products/mapr-editions
-
Hortonworks: hortonworks.com/hadoop/
本文由GetInData的創始人兼大資料顧問彼得亞·雷克魯斯基(PiotrKrewski)與GetInData執行長兼創始人亞當·卡瓦(Adam Kawa)撰寫
彼得亞(Piotr)在編寫執行於Hadoop叢集上的應用程式以及維護、管理和擴充套件Hadoop叢集方面具有豐富的實踐經驗。他是GetInData的聯合創始人之一,幫助公司構建可伸縮的分散式體系結構,用於儲存和處理大資料。Piotr還擔任Hadoop講師,為管理員、開發人員和使用大資料解決方案的分析師提供GetInData專業培訓。
亞當(Adam)於2010找到他在 Hadoop的首份工作後,成為了大資料的粉絲。自那以後,他一直在Spotify(他自豪地經營著歐洲最大和發展最快的Hadoop叢集之一)、Truecaller、華沙大學、Cloudera培訓合作伙伴等大資料公司工作。三年前,他創立了GetinData:一家幫助客戶運用資料驅動的公司,並提出了創新的大資料解決方案。亞當也是一位博主,華沙Hadoop使用者組的聯合組織者,並經常在大型資料會議上發言。
譯者簡介:陳之炎,北京交通大學通訊與控制工程專業畢業,獲得工學碩士學位,歷任長城計算機軟體與系統公司工程師,大唐微電子公司工程師,現任北京吾譯超群科技有限公司技術支援。目前從事智慧化翻譯教學系統的運營和維護,在人工智慧深度學習和自然語言處理(NLP)方面積累有一定的經驗。業餘時間喜愛翻譯創作,翻譯作品主要有:IEC-ISO 7816、伊拉克石油工程專案、新財稅主義宣言等等,其中中譯英作品“新財稅主義宣言”在GLOBAL TIMES正式發表。能夠利用業餘時間加入到THU 資料派平臺的翻譯志願者小組,希望能和大家一起交流分享,共同進步。
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
