MySQL 對於很多 Linux 從業者而言,是一個非常棘手的問題,多數情況都是因為對資料庫出現問題的情況和處理思路不清晰。
在進行 MySQL 的最佳化之前必須要瞭解的就是 MySQL 的查詢過程,很多的查詢最佳化工作實際上就是遵循一些原則讓 MySQL 的最佳化器能夠按照預想的合理方式執行而已。
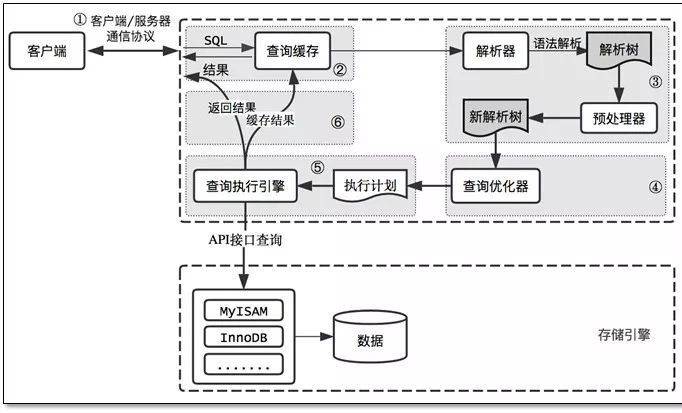
MySQL 查詢過程
最佳化的哲學
註:最佳化有風險,修改需謹慎。
最佳化可能帶來的問題:
-
最佳化不總是對一個單純的環境進行,還很可能是一個複雜的已投產的系統。
-
最佳化手段本來就有很大的風險,只不過你沒能力意識到和預見到。
-
任何的技術可以解決一個問題,但必然存在帶來一個問題的風險。
-
對於最佳化來說解決問題而帶來的問題,控制在可接受的範圍內才是有成果。
-
保持現狀或出現更差的情況都是失敗。
最佳化的需求:
-
穩定性和業務可持續性,通常比效能更重要。
-
最佳化不可避免涉及到變更,變更就有風險。
-
最佳化使效能變好,維持和變差是等機率事件。
-
切記最佳化,應該是各部門協同,共同參與的工作,任何單一部門都不能對資料庫進行最佳化。
所以最佳化工作,是由業務需求驅使的!
最佳化由誰參與?在進行資料庫最佳化時,應由資料庫管理員、業務部門代表、應用程式架構師、應用程式設計人員、應用程式開發人員、硬體及系統管理員、儲存管理員等,業務相關人員共同參與。
最佳化思路
最佳化什麼
在資料庫最佳化上有兩個主要方面:
-
安全:資料可持續性。
-
效能:資料的高效能訪問。
最佳化的範圍有哪些
儲存、主機和作業系統方面:
-
主機架構穩定性
-
I/O 規劃及配置
-
Swap 交換分割槽
-
OS 核心引數和網路問題
應用程式方面:
-
應用程式穩定性
-
SQL 陳述句效能
-
序列訪問資源
-
效能欠佳會話管理
-
這個應用適不適合用 MySQL
資料庫最佳化方面:
-
記憶體
-
資料庫結構(物理&邏輯)
-
實體配置
說明:不管是設計系統、定位問題還是最佳化,都可以按照這個順序執行。
最佳化維度
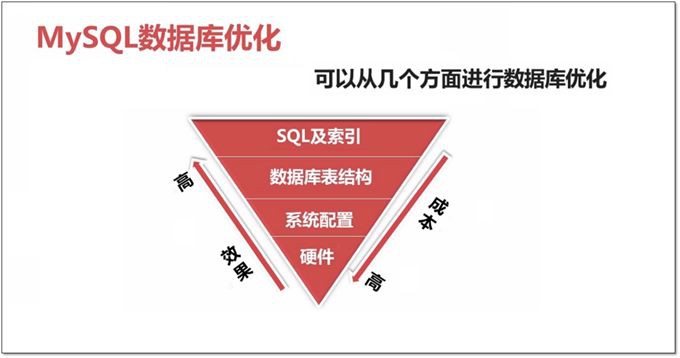
資料庫最佳化維度有如下四個:
-
硬體
-
系統配置
-
資料庫表結構
-
SQL 及索引
最佳化選擇:
-
最佳化成本:硬體>系統配置>資料庫表結構>SQL 及索引。
-
最佳化效果:硬體
最佳化工具有啥
資料庫層面
檢查問題常用的 12 個工具:
-
MySQL
-
mysqladmin:MySQL 客戶端,可進行管理操作
-
mysqlshow:功能強大的檢視 shell 命令
-
SHOW [SESSION | GLOBAL] variables:檢視資料庫引數資訊
-
SHOW [SESSION | GLOBAL] STATUS:檢視資料庫的狀態資訊
-
information_schema:獲取元資料的方法
-
SHOW ENGINE INNODB STATUS:Innodb 引擎的所有狀態
-
SHOW PROCESSLIST:檢視當前所有連線的 session 狀態
-
explain:獲取查詢陳述句的執行計劃
-
show index:查看錶的索引資訊
-
slow-log:記錄慢查詢陳述句
-
mysqldumpslow:分析 slowlog 檔案的工具
不常用但好用的 7 個工具:
-
Zabbix:監控主機、系統、資料庫(部署 Zabbix 監控平臺)
-
pt-query-digest:分析慢日誌
-
MySQL slap:分析慢日誌
-
sysbench:壓力測試工具
-
MySQL profiling:統計資料庫整體狀態工具
-
Performance Schema:MySQL 效能狀態統計的資料
-
workbench:管理、備份、監控、分析、最佳化工具(比較費資源)
關於 Zabbix 參考:http://www.cnblogs.com/clsn/p/7885990.html
資料庫層面問題解決思路
一般應急調優的思路:針對突然的業務辦理卡頓,無法進行正常的業務處理,需要馬上解決的場景。
1、show processlist
2、explain select id ,name from stu where name='clsn'; # ALL id name age sex
select id,name from stu where id=2-1 函式 結果集>30;
show index from table;
3、透過執行計劃判斷,索引問題(有沒有、合不合理)或者陳述句本身問題
4、show status like '%lock%'; # 查詢鎖狀態
kill SESSION_ID; # 殺掉有問題的session
常規調優思路:針對業務週期性的卡頓,例如在每天 10-11 點業務特別慢,但是還能夠使用,過了這段時間就好了。
1)檢視slowlog,分析slowlog,分析出查詢慢的陳述句;
2)按照一定優先順序,一個一個排查所有慢陳述句;
3)分析top SQL,進行explain除錯,檢視陳述句執行時間;
4)調整索引或陳述句本身。
系統層面
CPU方面:vmstat、sar top、htop、nmon、mpstat。
記憶體:free、ps-aux。
IO 裝置(磁碟、網路):iostat、ss、netstat、iptraf、iftop、lsof。
vmstat 命令說明:
-
Procs:r 顯示有多少行程正在等待 CPU 時間。b 顯示處於不可中斷的休眠的行程數量。在等待 I/O。
-
Memory:swpd 顯示被交換到磁碟的資料塊的數量。未被使用的資料塊,使用者緩衝資料塊,用於作業系統的資料塊的數量。
-
Swap:作業系統每秒從磁碟上交換到記憶體和從記憶體交換到磁碟的資料塊的數量。s1 和 s0 最好是 0。
-
IO:每秒從裝置中讀入 b1 的寫入到裝置 b0 的資料塊的數量。反映了磁碟 I/O。
-
System:顯示了每秒發生中斷的數量(in)和背景關係交換(cs)的數量。
-
CPU:顯示用於執行使用者程式碼,系統程式碼,空閑,等待 I/O 的 CPU 時間。
iostat 命令說明:
-
實體命令:iostat -dk 1 5;iostat -d -k -x 5 (檢視裝置使用率(%util)和響應時間(await))。
-
TPS:該裝置每秒的傳輸次數。“一次傳輸”意思是“一次 I/O 請求”。多個邏輯請求可能會被合併為“一次 I/O 請求”。
-
iops :硬體出廠的時候,廠家定義的一個每秒最大的 IO 次數。
-
“一次傳輸”請求的大小是未知的。
-
KB_read/s:每秒從裝置(drive expressed)讀取的資料量。
-
KB_wrtn/s:每秒向裝置(drive expressed)寫入的資料量。
-
KB_read:讀取的總資料量。
-
KB_wrtn:寫入的總數量資料量;這些單位都為 Kilobytes。
系統層面問題解決辦法
你認為到底負載高好,還是低好呢?在實際的生產中,一般認為 CPU 只要不超過 90% 都沒什麼問題。當然不排除下麵這些特殊情況。
CPU 負載高,IO 負載低:
-
記憶體不夠
-
磁碟效能差
-
SQL 問題:去資料庫層,進一步排查 SQL 問題
-
IO 出問題了(磁碟到臨界了、raid 設計不好、raid 降級、鎖、在單位時間內 TPS 過高)
-
TPS 過高:大量的小資料 IO、大量的全表掃描
IO 負載高,CPU 負載低:
-
大量小的 IO 寫操作
-
autocommit,產生大量小 IO;IO/PS,磁碟的一個定值,硬體出廠的時候,廠家定義的一個每秒最大的 IO 次數。
-
大量大的 IO 寫操作:SQL 問題的機率比較大
IO和 CPU 負載都很高:
-
硬體不夠了或 SQL 存在問題
基礎最佳化
最佳化思路
定位問題點吮吸:硬體>系統>應用>資料庫>架構(高可用、讀寫分離、分庫分表)。
處理方向:明確最佳化標的、效能和安全的折中、防患未然。
硬體最佳化
①主機方面
根據資料庫型別,主機 CPU 選擇、記憶體容量選擇、磁碟選擇: 平衡記憶體和磁碟資源 隨機的 I/O 和順序的 I/O 主機 RAID 卡的 BBU(Battery Backup Unit)關閉
②CPU 的選擇
CPU 的兩個關鍵因素:核數、主頻。根據不同的業務型別進行選擇: CPU 密集型:計算比較多,OLTP 主頻很高的 CPU、核數還要多。 IO 密集型:查詢比較,OLAP 核數要多,主頻不一定高的。
③記憶體的選擇
OLAP 型別資料庫,需要更多記憶體,和資料獲取量級有關。OLTP 型別資料一般記憶體是 CPU 核心數量的 2 倍到 4 倍,沒有最佳實踐。
④儲存方面
根據儲存資料種類的不同,選擇不同的儲存裝置,配置合理的 RAID 級別(raid5、raid10、熱備盤)。
對於作業系統來講,不需要太特殊的選擇,最好做好冗餘(raid1)(ssd、sas、sata)。
主機 raid 卡選擇: 實現作業系統磁碟的冗餘(raid1) 平衡記憶體和磁碟資源 隨機的 I/O 和順序的 I/O 主機 raid 卡的 BBU(Battery Backup Unit)要關閉
⑤網路裝置方面
使用流量支援更高的網路裝置(交換機、路由器、網線、網絡卡、HBA 卡)。註意:以上這些規劃應該在初始設計系統時就應該考慮好。
伺服器硬體最佳化
伺服器硬體最佳化關鍵點:
-
物理狀態燈
-
自帶管理裝置:遠端控制卡(FENCE裝置:ipmi ilo idarc)、開關機、硬體監控。
-
第三方的監控軟體、裝置(snmp、agent)對物理設施進行監控。
-
儲存裝置:自帶的監控平臺。EMC2(HP 收購了)、 日立(HDS)、IBM 低端 OEM HDS、高階儲存是自己技術,華為儲存。
系統最佳化
CPU:基本不需要調整,在硬體選擇方面下功夫即可。
記憶體:基本不需要調整,在硬體選擇方面下功夫即可。
SWAP:MySQL 儘量避免使用 Swap。阿裡雲的伺服器中預設 swap 為 0。
IO :raid、no lvm、ext4 或 xfs、ssd、IO 排程策略。
Swap 調整(不使用 swap 分割槽):
/proc/sys/vm/swappiness的內容改成0(臨時),/etc/sysctl. conf上新增vm.swappiness=0(永久)
這個引數決定了 Linux 是傾向於使用 Swap,還是傾向於釋放檔案系統 Cache。在記憶體緊張的情況下,數值越低越傾向於釋放檔案系統 Cache。
當然,這個引數只能減少使用 Swap 的機率,並不能避免 Linux 使用 Swap。
修改 MySQL 的配置引數 innodb_flush_ method,開啟 O_DIRECT 樣式。
這種情況下,InnoDB 的 buffer pool 會直接繞過檔案系統 Cache 來訪問磁碟,但是 redo log 依舊會使用檔案系統 Cache。
值得註意的是,Redo log 是覆寫樣式的,即使使用了檔案系統的 Cache,也不會佔用太多。
IO 排程策略:
#echo deadline>/sys/block/sda/queue/scheduler 臨時修改為deadline
永久修改:
vi /boot/grub/grub.conf
更改到如下內容:
kernel /boot/vmlinuz-2.6.18-8.el5 ro root=LABEL=/ elevator=deadline rhgb quiet
系統引數調整
Linux 系統核心引數最佳化:
vim/etc/sysctl.conf
net.ipv4.ip_local_port_range = 1024 65535:# 使用者埠範圍
net.ipv4.tcp_max_syn_backlog = 4096
net.ipv4.tcp_fin_timeout = 30
fs.file-max=65535:# 系統最大檔案控制代碼,控制的是能開啟檔案最大數量
使用者限制引數(MySQL 可以不設定以下配置):
vim/etc/security/limits.conf
* soft nproc 65535
* hard nproc 65535
* soft nofile 65535
* hard nofile 65535
應用最佳化
業務應用和資料庫應用獨立。
防火牆:iptables、selinux 等其他無用服務(關閉):
chkconfig --level 23456 acpid off
chkconfig --level 23456 anacron off
chkconfig --level 23456 autofs off
chkconfig --level 23456 avahi-daemon off
chkconfig --level 23456 bluetooth off
chkconfig --level 23456 cups off
chkconfig --level 23456 firstboot off
chkconfig --level 23456 haldaemon off
chkconfig --level 23456 hplip off
chkconfig --level 23456 ip6tables off
chkconfig --level 23456 iptables off
chkconfig --level 23456 isdn off
chkconfig --level 23456 pcscd off
chkconfig --level 23456 sendmail off
chkconfig --level 23456 yum-updatesd off
安裝圖形介面的伺服器不要啟動圖形介面 runlevel 3。
另外,思考將來我們的業務是否真的需要 MySQL,還是使用其他種類的資料庫。用資料庫的最高境界就是不用資料庫。
資料庫最佳化
SQL 最佳化方向:
-
執行計劃
-
索引
-
SQL 改寫
架構最佳化方向:
-
高可用架構
-
高效能架構
-
分庫分表
資料庫引數最佳化
①調整
實體整體(高階最佳化,擴充套件):
thread_concurrency:# 併發執行緒數量個數
sort_buffer_size:# 排序快取
read_buffer_size:# 順序讀取快取
read_rnd_buffer_size:# 隨機讀取快取
key_buffer_size:# 索引快取
thread_cache_size:# (1G—>8, 2G—>16, 3G—>32, >3G—>64)
②連線層(基礎最佳化)
設定合理的連線客戶和連線方式:
max_connections # 最大連線數,看交易筆數設定
max_connect_errors # 最大錯誤連線數,能大則大
connect_timeout # 連線超時
max_user_connections # 最大使用者連線數
skip-name-resolve # 跳過域名解析
wait_timeout # 等待超時
back_log # 可以在堆疊中的連線數量
③SQL 層(基礎最佳化)
query_cache_size: 查詢快取 >>> OLAP 型別資料庫,需要重點加大此記憶體快取,但是一般不會超過 GB。
對於經常被修改的資料,快取會馬上失效。我們可以使用記憶體資料庫(redis、memecache),替代它的功能。
儲存引擎層最佳化
innodb 基礎最佳化引數:
default-storage-engine
innodb_buffer_pool_size # 沒有固定大小,50%測試值,看看情況再微調。但是儘量設定不要超過物理記憶體70%
innodb_file_per_table=(1,0)
innodb_flush_log_at_trx_commit=(0,1,2) # 1是最安全的,0是效能最高,2折中
binlog_sync
Innodb_flush_method=(O_DIRECT, fdatasync)
innodb_log_buffer_size # 100M以下
innodb_log_file_size # 100M 以下
innodb_log_files_in_group # 5個成員以下,一般2-3個夠用(iblogfile0-N)
innodb_max_dirty_pages_pct # 達到百分之75的時候刷寫 記憶體臟頁到磁碟。
log_bin
max_binlog_cache_size # 可以不設定
max_binlog_size # 可以不設定
innodb_additional_mem_pool_size #小於2G記憶體的機器,推薦值是20M。32G記憶體以上100M
參考文章:
-
https://www.cnblogs.com/zishengY/p/6892345.html
-
https://www.jianshu.com/p/d7665192aaaf
出處:https://www.cnblogs.com/clsn/p/8214048.html
轉載自:51CTO技術棧


已傳送
朋友將在看一看看到
分享你的想法…
分享想法到看一看