(點選上方公眾號,可快速關註)
來源:笨狐狸,
blog.csdn.net/liweisnake/article/details/78790537
如何靈活高效的接入?
平臺化
-
搭建平臺而不是搭建專案——做一個“淘寶”而不是做只針對某幾項業務的網站
-
從業務中抽象及通用——如果一種業務有可能在今後重覆出現,那就將其模組化,系統化(如批處理系統),發展成為平臺能力
動態化
-
流程動態化——不同的業務型別對應的流程可以隨意調整,無須調整程式碼
-
程式碼動態化——採用groovy指令碼動態調整線上程式碼,無鬚髮版;規則配置除了使用各種靈活預配置外,還可以使用groovy指令碼程式碼化規則;指標函式groovy化,不需要每次發版。
-
配置動態化——配置動態化可以考慮虛擬表的形式,透過虛擬表將任意表的結構儲存到一個統一的表結構中去,從而完成配置的動態化,有些類似NoSQL的檔案化思想。
如何降低響應時間提高吞吐量?
善用儲存及快取
-
配置資料載入到本地記憶體
-
頻繁重覆訪問的資料放redis
-
數量較大穩定性要求較高的放hbase
-
需要快速搜尋的明細資料放es
-
需要解耦削峰的資料放kafka
如下圖,不同的儲存讀取時間是有很大差別的,應當利用好各種儲存,盡可能的用耗時小的儲存

下圖是hbase的一個基準效能測試,千萬不要忽略hbase哦,它既能存取海量資料,又能以極短的時間響應,實在是風控系統效能提升的利器。目前的風控系統最重要的累積資料,就是基於hbase存取的

非同步化
-
從系統架構層面,將可非同步的程式碼儘量非同步,但忌濫用非同步
下麵是一個實際的例子,在壓測過程中,發現CPU的sy和wa很高,大體可以判斷是執行緒過多,並且浪費在執行緒切換,據觀察,啟用非同步執行緒呼叫3個外部呼叫的耗時並不低,於是該分支執行緒等待時間過長,導致佔用大量執行緒在等待IO,執行緒也頻繁切換。
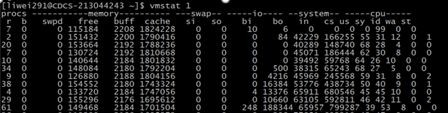

基於動態流程配置,將主系統中3個外部呼叫合併為一個之後,sy和wa大大降低,不再出現被壓垮的情況,而被合併的剩下兩個呼叫,放到kafka解耦之後繼續呼叫。

-
單機TPS 2,644.6->3,079
-
單機平均響應時間149.3->126.03
-
日誌列印非同步化–log4j2 all async,大大提高吞吐
日誌對於TPS的影響絕對無法忽視,曾試過禁止列印所有日誌,系統TPS直接從3000飆升到4200。
如果不列印日誌,線上系統就沒法運維。在風控系統裡,日誌是很重要的排查工具和手段。log4j2的出現,就是為了大吞吐列印日誌的,其中all async實現全非同步列印,中間用到了disruptor來提速,至於disruptor為什麼快,參考之前的文章disruptor框架為什麼這麼強大。
http://blog.csdn.net/liweisnake/article/details/9113119
-
單機TPS 3,079 ->3,686.1
-
單機平均響應時間126.03->79.35

-
降低執行緒數量,從而降低系統cpu時間,非同步網路呼叫–netty的客戶端應用
為保障主執行緒的吞吐和執行時間,經常需要把網路呼叫非同步化,一些重要的非同步化網路呼叫也需要佔用執行緒池中大量執行緒,執行緒數量一多,sy就居高不下,既浪費cpu,又會導致整個tps全線崩潰。
採用nio的netty客戶端無疑是解決這個問題的利器。如下圖,左邊是每個執行緒一個連線等待,耗費大量執行緒在等待,會導致sy和wa提升,採用基於netty框架的客戶端之後,將連線執行緒限制到一個很小的數目,而回呼的業務執行緒也會保持在一個較小範圍並且保持忙的狀態,而不是把時間耗費在sy和wa上

-
用好執行緒池,保持系統穩定
執行緒池實際上是保持系統穩定的重要方式,保持資源在一個可控的範圍內而不是無限制的增加資源壓垮機器,這點尤為重要。
如何應對大資料?
增量化思維
-
問題:需要從原始表計算到結果表,由於增量的結果表無法被覆用,只能每天計算全量的結果表,計算任務看似巨大(計算任務為182小時)
-
解決:將每次需要全量計算轉化為:每次增量計算到明細表,再從明細表全量計算到結果表(實際計算第一次跑得較慢,後續每次跑只需要幾小時)

海量關聯關係查詢
-
問題:在關聯關係查詢中,經常從幾個簡單的關聯查到大量資料,如何處理大量資料,將其排序,分頁,供人工調查?
-
解決:利用es多次查詢,redis快取分頁資訊。演演算法很簡單,實際過程會遇到很多問題,比如ip關聯出來經常是海量資料,資料查詢會超時,後續查詢更加龐大。一些小技巧是:資料儘早剪枝;業務查詢限制,如限制查詢時間;ES的多重查詢,可以一次性將資料作為查詢條件輸入。分散式的TOPK問題比較有意思,ES的原理中闡述了這一點,有興趣的人可以研究

另一種方式是將關係直接儲存為圖,即頂點和邊關係,查詢時將極其簡單,這方便的代表是圖資料庫neo4j,由於儲存需要再匯入,因此並未做深入研究,同樣供有興趣的同學參考。
如何保持系統穩定性?
限流
大促期間如遇大流量可以針對業務渠道限流開關推送標誌以限流。
降級
在高峰期間將一些運營查詢相關的需求停止,減小資料系統負擔,並排程到半夜12點繼續查詢。
預案
每次大促前都得準備預案。預案需要準備各種極端失敗情況,確保失敗時不手忙腳亂。
看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

