導語:區塊鏈技術中,共識演演算法是其中核心的一個組成部分,比特幣使用的是POW(Proof of Work,工作量證明),以太幣將來使用POS(Proof of Stake,權益證明)。對於不需要貨幣體系的聯盟鏈或者私鏈而言,傳統的一致性演演算法成為首選,常見的有:PBFT(拜占庭容錯)、PAXOS、RAFT。本文將詳細闡述私鏈的raft演演算法和聯盟鏈的PBFT演演算法,從演演算法的基本流程切入,深入介紹PBFT演演算法,並對比分析raft演演算法和PBFT演演算法的區別。
作者簡介:梁敏鴻,美圖區塊鏈架構師,專註於區塊鏈技術研究與產品應用落地。
區塊鏈技術中,共識演演算法是其中核心的一個組成部分。首先我們來思考一個問題:什麼是共識?對於現實世界,共識就是一群人對一件或者多件事情達成一致的看法或者協議。那麼在計算機世界當中,共識是什麼呢?
我的理解包含兩個層面,第一個層面是點的層面,即多個節點對某個資料達成一致共識。第二個層面是線的層面,即多個節點對多個資料的順序達成一致共識。這裡的節點可以是任意的計算機裝置,比如pc電腦,筆記本,手機,路由器等,這裡的資料可以是交易資料,狀態資料等。其中對資料順序達成一致共識是很多共識演演算法要解決的本質問題。
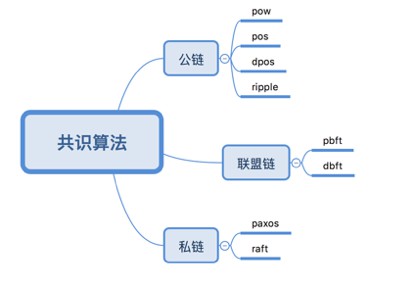
常見的共識演演算法都有哪些呢?現階段的共識演演算法主要可以分成三大類:公鏈,聯盟鏈和私鏈。下麵描述這三種類別的特徵。
私鏈:私鏈的共識演演算法即區塊鏈這個概念還沒普及時的傳統分散式系統裡的共識演演算法,比如zookeeper的zab協議,就是類paxos演演算法的一種。私鏈的適用環境一般是不考慮叢集中存在作惡節點,只考慮因為系統或者網路原因導致的故障節點。
聯盟鏈:聯盟鏈中,經典的代表專案是Hyperledger組織下的Fabric專案,Fabric0.6版本使用的就是pbft演演算法。聯盟鏈的適用環境除了需要考慮叢集中存在故障節點,還需要考慮叢集中存在作惡節點。對於聯盟鏈,每個新加入的節點都是需要驗證和審核的。
公鏈:公鏈不僅需要考慮網路中存在故障節點,還需要考慮作惡節點,這一點和聯盟鏈是類似的。和聯盟鏈最大的區別就是,公鏈中的節點可以很自由的加入或者退出,不需要嚴格的驗證和審核。
本文接下來將會主要闡述私鏈的raft演演算法和聯盟鏈的pbft演演算法,以及它們的區別和對比。
【一.raft演演算法】
因為網上已經有大量文章對raft演演算法進行過詳細的介紹,因此這部分只會簡單的闡述演演算法的基本原理和流程。raft演演算法包含三種角色,分別是:跟隨者(follower),候選人(candidate)和領導者(leader)。叢集中的一個節點在某一時刻只能是這三種狀態的其中一種,這三種角色是可以隨著時間和條件的變化而互相轉換的。
raft演演算法主要有兩個過程:一個過程是領導者選舉,另一個過程是日誌複製,其中日誌複製過程會分記錄日誌和提交資料兩個階段。raft演演算法支援最大的容錯故障節點是(N-1)/2,其中N為 叢集中總的節點數量。
國外有一個動畫介紹raft演演算法介紹的很透徹,連結地址在這裡[1]。這個動畫主要包含三部分內容,第一部分介紹簡單版的領導者選舉和日誌複製的過程,第二部分內容介紹詳細版的領導者選舉和日誌複製的過程,第三部分內容介紹的是如果遇到網路分割槽(腦裂),raft演演算法是如何恢復網路一致的。有興趣的朋友可以結合這個動畫來更好的理解raft演演算法。
【二.pbft演演算法】
pbft演演算法的提出主要是為瞭解決拜占庭將軍問題。什麼是拜占庭將軍問題呢?拜占庭位於如今的土耳其的伊斯坦布林,是古代東羅馬帝國的首都。拜占庭羅馬帝國國土遼闊,為了達到防禦目的,每塊封地都駐扎一支由將軍統領的軍隊,每個軍隊都分隔很遠,將軍與將軍之間只能靠信差傳遞訊息。 在戰爭的時候,拜占庭軍隊內所有將軍必需達成一致的共識,決定是否有贏的機會才去攻打敵人的陣營。但是,在軍隊內有可能存有叛徒和敵軍的間諜,左右將軍們的決定影響將軍們達成一致共識。在已知有將軍是叛徒的情況下,其餘忠誠的將軍如何達成一致協議的問題,這就是拜占庭將軍問題。
要讓這個問題有解,有一個十分重要的前提,那就是通道必須是可靠的。如果通道不能保證可靠,那麼拜占庭問題無解。關於通道可靠問題,會引出兩軍問題。兩軍問題的結論是,在一個不可靠的通訊鏈路上試圖透過通訊以達成一致是基本不可能或者十分困難的。
那麼如果在通道可靠的情況下,要如何解這個問題呢?拜占庭將軍問題其實有很多種解法,接下來先介紹兩位大牛,這兩位大牛都在解決拜占庭問題上做出了突出的貢獻。

如上圖所示,拜占庭將軍問題最早是由Leslie Lamport與另外兩人在1982年發表的論文《The Byzantine Generals Problem 》提出的, 他證明瞭在將軍總數大於3f ,背叛者為f 或者更少時,忠誠的將軍可以達成命令上的一致,即3f+1<=n。演演算法複雜度為o(n^(f+1))。而Miguel Castro (卡斯特羅)和Barbara Liskov(利斯科夫)在1999年發表的論文《Practical Byzantine Fault Tolerance》中首次提出pbft演演算法,該演演算法容錯數量也滿足3f+1<=n,演演算法複雜度為o(n^2)。
網上關於pbft的演演算法介紹基本上是基於liskov在1999年發表的論文《Practical Byzantine Fault Tolerance》來進行解釋的。當前網上介紹pbft的中文文章不算太多,基本上只有那幾篇,並且感覺有些關鍵點解釋得不夠清晰,因此接下來會詳細描述下pbft演演算法的過程和原理。
2.1 推論:raft演演算法的2f+1<=n和pbft的3f+1<=n
首先我們先來思考一個問題,為什麼pbft演演算法的最大容錯節點數量是(n-1)/3,而raft演演算法的最大容錯節點數量是(n-1)/2?
對於raft演演算法,raft演演算法的的容錯只支援容錯故障節點,不支援容錯作惡節點。什麼是故障節點呢?就是節點因為系統繁忙、宕機或者網路問題等其它異常情況導致的無響應,出現這種情況的節點就是故障節點。那什麼是作惡節點呢?作惡節點除了可以故意對叢集的其它節點的請求無響應之外,還可以故意傳送錯誤的資料,或者給不同的其它節點傳送不同的資料,使整個叢集的節點最終無法達成共識,這種節點就是作惡節點。
raft演演算法只支援容錯故障節點,假設叢集總節點數為n,故障節點為f,根據小數服從多數的原則,集群裡正常節點只需要比f個節點再多一個節點,即f+1個節點,正確節點的數量就會比故障節點數量多,那麼叢集就能達成共識。因此raft演演算法支援的最大容錯節點數量是(n-1)/2。
對於pbft演演算法,因為pbft演演算法的除了需要支援容錯故障節點之外,還需要支援容錯作惡節點。假設叢集節點數為N,有問題的節點為f。有問題的節點中,可以既是故障節點,也可以是作惡節點,或者只是故障節點或者只是作惡節點。那麼會產生以下兩種極端情況:
第一種情況,f個有問題節點既是故障節點,又是作惡節點,那麼根據小數服從多數的原則,集群裡正常節點只需要比f個節點再多一個節點,即f+1個節點,確節點的數量就會比故障節點數量多,那麼叢集就能達成共識。也就是說這種情況支援的最大容錯節點數量是(n-1)/2。
第二種情況,故障節點和作惡節點都是不同的節點。那麼就會有f個問題節點和f個故障節點,當發現節點是問題節點後,會被叢集排除在外,剩下f個故障節點,那麼根據小數服從多數的原則,集群裡正常節點只需要比f個節點再多一個節點,即f+1個節點,確節點的數量就會比故障節點數量多,那麼叢集就能達成共識。所以,所有型別的節點數量加起來就是f+1個正確節點,f個故障節點和f個問題節點,即3f+1=n。
結合上述兩種情況,因此pbft演演算法支援的最大容錯節點數量是(n-1)/3。下圖展示了論文裡證明pbft演演算法為什麼3f+1<=n的一段原文,以及根據原文提到的兩種情況對應的示意圖。

3f+1<=n這個結論在pbft演演算法的流程中會大量使用到,因此在介紹pbft演演算法流程前先解釋下這個推論。
2.2 演演算法基本流程
pbft演演算法的基本流程主要有以下四步:
-
客戶端傳送請求給主節點
-
主節點廣播請求給其它節點,節點執行pbft演演算法的三階段共識流程。
-
節點處理完三階段流程後,傳回訊息給客戶端。
-
客戶端收到來自f+1個節點的相同訊息後,代表共識已經正確完成。
為什麼收到f+1個節點的相同訊息後就代表共識已經正確完成?從上一小節的推導裡可知,無論是最好的情況還是最壞的情況,如果客戶端收到f+1個節點的相同訊息,那麼就代表有足夠多的正確節點已全部達成共識並處理完畢了。
2.3 演演算法核心三階段流程
下麵介紹pbft演演算法的核心三階段流程,如下圖所示:

演演算法的核心三個階段分別是pre-prepare階段(預準備階段),prepare階段(準備階段),commit階段(提交階段)。圖中的C代表客戶端,0,1,2,3代表節點的編號,打叉的3代表可能是故障節點或者是問題節點,這裡表現的行為就是對其它節點的請求無響應。0是主節點。整個過程大致是:
首先,客戶端向主節點發起請求,主節點0收到客戶端請求,會向其它節點傳送pre-prepare訊息,其它節點就收到了pre-prepare訊息,就開始了這個核心三階段共識過程了。
Pre-prepare階段:節點收到pre-prepare訊息後,會有兩種選擇,一種是接受,一種是不接受。什麼時候才不接受主節點發來的pre-prepare訊息呢?一種典型的情況就是如果一個節點接到了一條pre-pre訊息,訊息裡的v和n在之前收到裡的訊息是曾經出現過的,但是d和m卻和之前的訊息不一致,或者請求編號不在高低水位之間(高低水位的概念在2.4節會進行解釋),這時候就會拒絕請求。拒絕的邏輯就是主節點不會傳送兩條具有相同的v和n,但d和m卻不同的訊息。
Prepare階段:節點同意請求後會向其它節點傳送prepare訊息。這裡要註意一點,同一時刻不是隻有一個節點在進行這個過程,可能有n個節點也在進行這個過程。因此節點是有可能收到其它節點傳送的prepare訊息的。在一定時間範圍內,如果收到超過2f個不同節點的prepare訊息,就代表prepare階段已經完成。
Commit階段:於是進入commit階段。向其它節點廣播commit訊息,同理,這個過程可能是有n個節點也在進行的。因此可能會收到其它節點發過來的commit訊息,當收到2f+1個commit訊息後(包括自己),代表大多數節點已經進入commit階段,這一階段已經達成共識,於是節點就會執行請求,寫入資料。
處理完畢後,節點會傳回訊息給客戶端,這就是pbft演演算法的全部流程。
為了更清晰的展現這個過程和一些細節,下麵以流程圖來表示這個過程。

註解:
V:當前檢視的編號。檢視的編號是什麼意思呢?比如當前主節點為A,檢視編號為1,如果主節點換成B,那麼檢視編號就為2.這個概念和raft的term任期是很類似的。
N:當前請求的編號。主節點收到客戶端的每個請求都以一個編號來標記。
M:訊息的內容
d或D(m):訊息內容的摘要
i: 節點的編號
2.4 checkpoint、stable checkpoint和高低水位
什麼是checkpoint呢?checkpoint就是當前節點處理的最新請求序號。前文已經提到主節點收到請求是會給請求記錄編號的。比如一個節點正在共識的一個請求編號是101,那麼對於這個節點,它的checkpoint就是101.
那什麼是stable checkpoint(穩定檢查點)呢?stable checkpoint就是大部分節點(2f+1)已經共識完成的最大請求序號。比如系統有4個節點,三個節點都已經共識完了的請求編號是213.那麼這個213就是stable checkpoint了。
那設定這個stable checkpoint有什麼作用呢?最大的目的就是減少記憶體的佔用。因為每個節點應該記錄下之前曾經共識過什麼請求,但如果一直記錄下去,資料會越來越大,所以應該有一個機制來實現對資料的刪除。那怎麼刪呢?很簡單,比如現在的穩定檢查點是213,那麼代表213號之前的記錄已經共識過的了,所以之前的記錄就可以刪掉了。
那什麼是高低水位呢?下麵以一個示意圖來進行解釋。

圖中A節點的當前請求編號是1039,即checkpoint為1039,B節點的checkpoint為1133.當前系統stable checkpoint為1034.那麼1034這個編號就是低水位,而高水位H=低水位h+L,其中L是可以設定的數值。因此圖中系統的高水位為1034+100=1134。
舉個例子:如果B當前的checkpoint已經為1034,而A的checkpoint還是1039,假如有新請求給B處理時,B會選擇等待,等到A節點也處理到和B差不多的請求編號時,比如A也處理到1112了,這時會有一個機制更新所有節點的stabel checkpoint ,比如可以把stabel checkpoint設定成1100,於是B又可以處理新的請求了,如果L保持100不變,這時的高水位就會變成1100+100=1200了。
2.5 ViewChange(檢視更改)事件
當主節點掛了(超時無響應)或者從節點集體認為主節點是問題節點時,就會觸發ViewChange事件,ViewChange完成後,檢視編號將會加1。
下圖展示ViewChange的三個階段流程。

如圖所示,viewchange會有三個階段,分別是view-change,view-change-ack和new-view階段。從節點認為主節點有問題時,會向其它節點傳送view-change訊息,當前存活的節點編號最小的節點將成為新的主節點。當新的主節點收到2f個其它節點的view-change訊息,則證明有足夠多人的節點認為主節點有問題,於是就會向其它節點廣播
New-view訊息。註意:從節點不會發起new-view事件。對於主節點,傳送new-view訊息後會繼續執行上個檢視未處理完的請求,從pre-prepare階段開始。其它節點驗證new-view訊息透過後,就會處理主節點發來的pre-prepare訊息,這時執行的過程就是前面描述的pbft過程。到這時,正式進入 v+1(檢視編號加1)的時代了。
為了更清晰的展現ViewChange這個過程和一些細節,下麵以流程圖來表示這個過程。
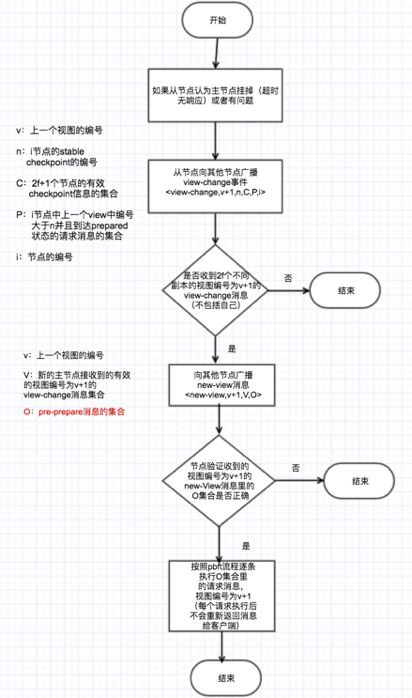
上圖裡紅色字型部分的O集合會包含哪些pre-prepare訊息呢?假設O集合裡訊息的編號範圍:(min~max),則Min為V集合最小的stable checkpoint,Max為V集合中最大序號的prepare訊息。最後一步執行O集合裡的pre-preapare訊息,每條訊息會有兩種情況: 如果max-min>0,則產生訊息
【三.raft和pbft的對比】
下圖列出了raft演演算法和pbft演演算法在適用環境,通訊複雜度,最大容錯節點數和流程上的對比。

關於兩個演演算法的適用環境和最大容錯節點數,前文已經做過闡述,這裡不再細說。而對於演演算法通訊複雜度,為什麼raft是o(n),而pbft是o(n^2)呢?這裡主要考慮演演算法的共識過程。
對於raft演演算法,核心共識過程是日誌複製這個過程,這個過程分兩個階段,一個是日誌記錄,一個是提交資料。兩個過程都只需要領導者傳送訊息給跟隨者節點,跟隨者節點傳回訊息給領導者節點即可完成,跟隨者節點之間是無需溝通的。所以如果叢集總節點數為 n,對於日誌記錄階段,通訊次數為n-1,對於提交資料階段,通訊次數也為n-1,總通訊次數為2n-2,因此raft演演算法複雜度為O(n)。
對於pbft演演算法,核心過程有三個階段,分別是pre-prepare(預準備)階段,prepare(準備)階段和commit(提交)階段。對於pre-prepare階段,主節點廣播pre-prepare訊息給其它節點即可,因此通訊次數為n-1;對於prepare階段,每個節點如果同意請求後,都需要向其它節點再 廣播parepare訊息,所以總的通訊次數為n*(n-1),即n^2-n;對於commit階段,每個節點如果達到prepared狀態後,都需要向其它節點廣播commit訊息,所以總的通訊次數也為n*(n-1),即n^2-n。所以總通訊次數為(n-1)+(n^2-n)+(n^2-n),即2n^2-n-1,因此pbft演演算法複雜度為O(n^2)。
流程的對比上,對於leader選舉這塊,raft演演算法本質是誰快誰當選,而pbft演演算法是按編號依次輪流做主節點。對於共識過程和重選leader機制這塊,為了更形象的描述這兩個演演算法,接下來會把raft和pbft的共識過程比喻成一個團隊是如何執行命令的過程,從這個角度去理解raft演演算法和pbft的區別。
一個團隊一定會有一個老大和普通成員。對於raft演演算法,共識過程就是:只要老大還沒掛,老大說什麼,我們(團隊普通成員)就做什麼,堅決執行。那什麼時候重新老大呢?只有當老大掛了才重選老大,不然生是老大的人,死是老大的鬼。
對於pbft演演算法,共識過程就是:老大向我傳送命令時,當我認為老大的命令是有問題時,我會拒絕執行。就算我認為老大的命令是對的,我還會問下團隊的其它成員老大的命令是否是對的,只有大多數人(2f+1)都認為老大的命令是對的時候,我才會去執行命令。那什麼時候重選老大呢?老大掛了當然要重選,如果大多數人都認為老大不稱職或者有問題時,我們也會重新選擇老大。
【四.結語】
raft演演算法和pbft演演算法是私鏈和聯盟鏈中經典的共識演演算法,本文主要介紹了raft和pbft演演算法的流程和區別。raft和pbft演演算法有兩點根本區別:
-
raft演演算法從節點不會拒絕主節點的請求,而pbft演演算法從節點在某些情況下會拒絕主節點的請求 ;
-
raft演演算法只能容錯故障節點,並且最大容錯節點數為(n-1)/2,而pbft演演算法能容錯故障節點和作惡節點,最大容錯節點數為(n-1)/3。
本文沒有涉及演演算法正確性和收斂性的證明,從演演算法設計的角度來講,是需要做這兩方面工作的。
文中連結:
[1]http://thesecretlivesofdata.com/raft/
相關閱讀:
新一代開源分散式賬本專案R3 Corda 技術揭秘:基於JVM開發
活動預告:
6 月 1 ~ 2 日,GIAC 全球網際網路架構大會將於深圳舉行。GIAC 是高可用架構技術社群推出的面向架構師、技術負責人及高階技術從業人員的技術架構大會。今年的 GIAC 已經有騰訊、阿裡巴巴、百度、今日頭條、科大迅飛、新浪微博、小米、美圖、Oracle、鏈家、唯品會、京東、餓了麼、美圖點評、羅輯思維、ofo、LinkedIn, Pivotal 等公司專家出席。
本期 GIAC 大會上,區塊鏈部分精彩的議題如下:

參加 GIAC,盤點2018最新技術。點選“閱讀原文”瞭解大會更多詳情。
