作者:Pulkit Sharma,2019年1月21日;翻譯:陳之炎;校對:丁楠雅;
本文約11000字,建議閱讀10+分鐘。
本文為你詳細介紹序列模型,並分析其在不同的真實場景中的應用。
簡介
如何預測一個序列中接下來要發生什麼事情是一個非常吸引人的課題,這是我對資料科學如此著迷的原因之一!有趣的是——人類的頭腦確實擅長於此,但是機器卻不是這樣的。如果一本書中有一個神秘的情節,人類的大腦就會開始預測出結果,然而,如何教會機器來做類似的事情呢?
多虧了深度學習,我們今天能做的事情比幾年前要多的多。處理序列資料的能力,如音樂歌詞、句子翻譯、理解評論或構建聊天機器人-所有這些都要歸功於序列建模。
這便是我們在本文中需要學習的內容,由於這是deeplearning.ai專業系列課程的一部分,我希望讀者能夠瞭解到某些概念。如果你還沒有讀過前幾篇文章,或者還需要快速複習一下,可以訪問以下連結:
深度學習和神經網路入門指南(deeplearning.ai第1課)
https://www.analyticsvidhya.com/blog/2018/10/introduction-neuric-networks-deep-learning/
改進神經網路–超引數調整、正則化和其他(deeplearning.ai第2課)
https://www.analyticsvidhya.com/blog/2018/11/neuric-networks-hyperparameter-tuning-regularization-deeplearning/
從零開始學習摺積神經網路的綜合教程(deeplearning.ai第4課)
https://www.analyticsvidhya.com/blog/2018/11/neuric-networks-hyperparameter-tuning-regularization-deeplearning/
在本節課程中,我們將看到如何將序列模型應用到不同的真實場景中去,如情感分類、影象字幕等。

課程目錄
-
課程結構
-
課程內容:序列模型
序列模型課程內容如下:
一、模組1:迴圈神經網路(RNNs)
二、模組2:自然語言處理(NLP)和單詞嵌入
2.1 單詞嵌入簡介
2.2 學習單詞嵌入:Word2vec & GloVe
2.3 單詞嵌入的應用程式
三、模組3:序列模型與註意力(Attention)機制
課程結構
到目前為止,我們已經在這個系列課程中涵蓋了相當多的內容,以下是對所學概念的簡要概括:
-
深度學習和神經網路基礎。
-
淺層和深層神經網路的工作原理。
-
如何透過超引數調整、正則化和最佳化來提高深度神經網路的效能。
-
如何透過scratch實現摺積神經網路。
現在我們把重點轉向序列建模,本課程分為三個模組(官方課程名稱為:Andrew Ng教授的深度學習專業課程第5課):
-
在模組1中,我們將學習迴圈神經網路及其工作原理,此外,還將在本模組中介紹GRU和LSTM。
-
在模組2中,重點學習自然語言處理和單詞嵌入。我們將學到如何將Word2vec和Glove框架應用於學習單詞嵌入
-
最後,模組3將介紹註意力(Attention)模型的概念。我們將學到如何將大而複雜的句子從一種語言翻譯成另一種語言。
準備好了嗎?那我們便從模組1開始第5課序列模型的學習吧!
一、模組1:迴圈神經網路
第5課第一模組的標的是:
-
瞭解什麼是迴圈神經網路(RNN)
-
學習包括LSTM、GRUS和雙向RNN在內的多種演演算法
如果這些縮寫聽起來令人生畏,不要擔心——我們會很快把它們解決掉。
1. 首先,為什麼是序列模型?
為回答這個問題,將向你展示一些在真實場景中應用到的序列模型示例。
-
語音識別:
這是一個很常見的應用(每個有智慧手機的人都會知道這一點),在這裡,輸入是一個音訊剪輯板,模型生成文字轉錄。在這裡,音訊被認為是一個序列,隨著時間的推移,輸出為一系列單詞。

-
情感分類:
序列模型的另一個流行應用是情感分類。我們將一個文字句子作為輸入,模型必須預測出句子的情感(積極、消極、憤怒、興奮等),輸出可以為分級或標星。

-
DNA序列分析:
給定一個DNA序列作為輸入,期望模型能夠預測出哪一部分DNA屬於哪一種蛋白質。

-
機器翻譯:
用一種語言輸入一個句子,比如法語,希望模型能把它轉換成另一種語言,比如英語。在這裡,輸入和輸出都是序列:

-
影片活動識別:
這實際上是利用序列模型對即將到來的事件(和當前的趨勢)進行預測,該模型用來預測給定影片中正在進行的活動,在這裡,輸入是一個幀序列。

-
名稱物體識別:
這當然是我最喜歡的序列模型示例。如下圖所示,我們用一句話作為輸入,並希望模型能識別出該句子中的人名:

現在,在做進一步深入探討之前,需要討論幾個重要的符號,你會在整個文章中看到這些符號。
2. 將在本文中使用到的符號
我們用“x”來表示一個句子,為方便理解,以下麵的示例句子為例:

X:哈利和赫敏發明瞭一種新的咒語。
現在,我們用x來表示句子中的每個詞:
-
x<1> = 哈利
-
x<2>=赫敏,等等
上述句子的輸出將是:
Y=1 0 1 0 0 0 0
在這裡,1表示這個單詞代表一個人的名字(0表示它是其他)。下麵是我們經常用到的一些常用符號:
-
Tx = 輸入句長度
-
Ty = 輸出句長度
-
x(i) = ith 訓練樣本
-
x(i) = ith訓練樣本的tth訓練
-
Tx(i) = ith輸入句長度
此時,我們或許會問——如何在一個序列中表示一個單獨的單詞呢?嗯,這裡,我們要依靠詞彙表或字典,即我們在句子中使用到的單詞串列,詞彙表結構如下所示:

詞彙表的大小因不同的應用而異,通常從訓練集中挑選出現頻度最高的單詞來製作詞彙表。
現在,假設我們想表示單詞“Harry”這個詞,它在詞彙表中的位置是4075th 位,我們對這個詞彙進行一次編碼,以表示“Harry”:
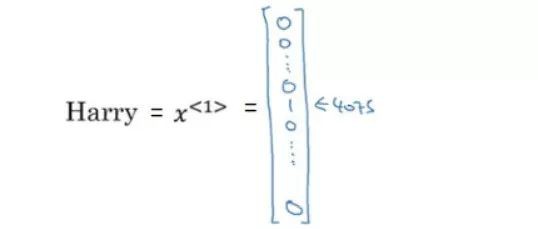
通常,x是一個獨熱編碼向量,我們將1放在第4075t位置,所有其餘的單詞將表示為0。
如果單詞不出現在詞彙表中,會建立一個未知的標記,並將其新增到詞彙表中。就這麼簡單!
3. 迴圈神經網路(RNN)模型
當X,Y之中有一個是序列,或者X和Y都是序列時,我們使用迴圈神經網路來學習從X到Y的對映。但是,為什麼不能用一個標準的神經網路來解決這些序列問題呢?
問得太好了!下麵,讓我用一個例子來做出解釋。假設我們需要構建下述神經網路:
這裡主要有兩個問題:
輸入和輸出沒有固定的長度,也就是說,一些輸入陳述句可以是10個單詞,而其他的可以是<>10(大於或小於)。最終輸出也是如此
如果使用一個標準的神經網路,我們將無法在不同的文字位置上共享所學的特徵。
為此,需要建立一種表示,用它來解析不同長度的句子,並減少模型中的引數數量。這就是我們要用到迴圈神經網路的地方,這便是典型RNN:
RNN獲取第一個單詞(x<1>),並將其饋送到預測輸出(y‘<1>)的神經網路層。重覆此過程,直到最後一步x生成最後的輸出y‘,這是輸入字數和輸出字數相等的網路。
RNN按從左到右的順序掃描資料。註意,RNN在每個時間步長中使用的引數是共享的,在每個輸入層和隱藏層(Wax)之間、每個時間步長(Waa)之間以及隱藏層和輸出層(Wya)之間共享引數。
因此,如果需要對x<3>進行預測,我們也會得到關於x<1>和x<2>的資訊。RNN的一個潛在缺點是:它只從先前的時間步長獲取資訊,而不是從後續的時間步長獲取資訊。這個問題可以用雙向RNN來解決,我們會在稍後進行討論。現在,我們來看看RNN模型中的前向傳播的步驟:
a<0> 是一個全零向量,我們計算與標準神經網路相類似的啟用函式:
-
a<0> = 0
-
a<1> = g(Waa * a<0> + Wax * x<1> + ba)
-
y<1> = g’(Wya * a<1> + by)
同樣,我們可以計算每個時間步長的輸出。這些公式的一般形式可以寫成:

可以用更為簡潔的方法列出這些方程:

水平疊加Waa 和Wya 以獲得Wa,a和x垂直疊加。目前只有一個矩陣,而不是帶著兩個引數的矩陣。簡言之,這便是迴圈神經網路的前向傳播原理。
3.1 時間軸上的反向傳播
接下來,你可能會看到這種情況-反向傳播步驟與前向傳播的方向正好相反。我們有一個損失函式,為了得到準確的預測,需要將它最小化。損失函式由以下公式給出:

我們計算每個時間步長裡的損失,最後對所有這些損失求和,以計算序列的最終損失:

在前向傳播中,我們從左向右移動,即增加時間t的步長。在反向傳播中,我們從右向左移動,即在時間軸上向後移動(因此稱為時間反向傳播)。
到目前為止,我們看到的是輸入和輸出序列長度相等的應用場景。但是如果輸入和輸出序列長度不等的情況又如何呢?我們將在下一節中看到這些不同的應用場景。
3.2 不同種類的RNN
可以用多種不同型別的RNN來處理序列長度不同的示例。這些問題可分為以下幾類:
-
多對多
前面看到的名稱物體識別示例屬於這個類別。假設我們有一系列的單詞,對於每個單詞,我們必須預測它是否是一個人名。針對此類問題的RNN架構如下:
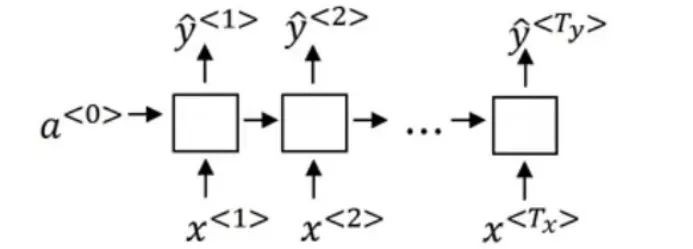
對於每個輸入字,我們預測它對應的輸出字。
-
多對一
來看看情緒分類問題:我們將一個句子傳遞給模型,它將傳回與該句子對應的情感或評級。這是一個多對一的問題,輸入序列可以有不同的長度,而輸出只有一個。針對此類問題的RNN架構如下所示:

這裡,我們在句子結束時會得到一個輸出。
-
一對多
以音樂生成為例,我們希望用音樂作為輸入來預測歌詞。在這種情況下,輸入只是一個單詞(或一個整數),輸出的長度可變。這類問題的RNN體系結構如下所示:

還有一種RNN在工業上廣泛使用,即機器翻譯,將一種語言的輸入句翻譯成另一種語言。這是一個多對多的問題,輸入序列的長度可能等於也可能不等於輸出序列的長度。
在這種情況下,我們有編碼器和解碼器。編碼器讀取輸入陳述句,解碼器將其轉換為輸出陳述句:

3.3 語言模型和序列生成
假設需要建立一個語音識別系統,我們聽到一句話:“蘋果和梨沙拉很好吃”。該模型將預測什麼——“蘋果配梨沙拉很美味”還是“蘋果和梨沙拉是美味”?
我希望是第二句話!語音識別系統透過預測每個句子的機率來選擇句子。
但是又如何來構建語言模型呢?
假設有一個輸入陳述句:

貓平均每天睡15小時
構建語言模型的步驟如下:
-
第1步:標記輸入,即建立字典
-
第2步:將這些單詞對映到一個編碼向量,可以新增的標記來表示句子的結束。
-
第3步:構建RNN模型
我們取第一個輸入詞並對其進行預測,輸出會告訴我們字典中任意單詞的機率是多少。第二個輸出會告訴我們給定第一個輸入字的預測詞的機率:
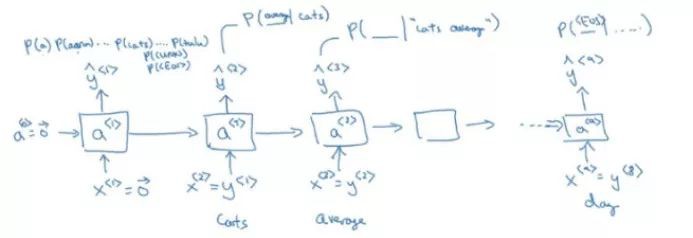
RNN模型中的每一步都會檢視前面的一組單詞,以預測下一個單詞。訓練RNN模型會遇到各種各樣的挑戰,這將在下一節進行討論。
3.4 RNN的梯度消失
迴圈神經網路的最大問題之一是它會陷入梯度消失。怎麼回事?我們來考慮這兩個句子:

那隻貓吃了一堆食物,已經吃飽了。
貓已經吃了一堆食物之後,都已經吃飽了。
以上兩個句子中哪一句語法正確?是第一句。(如果你錯過了請再讀一遍!)
基本RNN不擅長捕獲長期依賴項,這是因為在反向傳播過程中,來自輸出Y的梯度將很難傳播回來,從而影響先期層的權重。因此,在基本RNN中,輸出受到更接近該單詞的那個輸入的影響。
為避免這種情況的發生,我們可以透過設定一個預先定義的閾值來對它們進行剪輯。
3.5 門控迴圈單元(GRU)
GRU是RNN的一種改進形式。它們在捕獲更長範圍的依賴關係方面非常有效,並且有助於解決梯度消失問題。在時間步長t中計算啟用的公式為:

RNN的隱藏單元如下圖所示:

一個單元的輸入是來自前一個單元的啟用和該時間步長的輸入字。在計算該步長的啟用和輸出的時候,我們在這個RNN中新增一個儲存單元,以便記住當前單詞以外的單詞。來看看GRU的方程:
c = a
其中c是一個儲存單元。
在每個時間步長內,將c
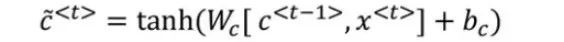
這便是更新c值的候選值。我們還定義了一個更新門,利用這個門的值來決定是否更新儲存單元,更新門的方程為:

請註意,因為使用sigmoid來計算更新值,所以,更新門的輸出總是在0和1之間。我們使用先前的儲存單元值和更新門輸出來更新儲存單元。c的更新方程如下:

當門值為0時,c = c,即不更新c;;當門值為1時,c = c,對值進行更新。舉一個例子來理解這一概念:

當遇到cat這個詞時,門(gate)值為1;對於序列中的所有其他單詞,門(gate)值為0,因此cat的資訊將被攜帶到單詞“was”。我們期望模型能預測到單詞were的地方應該是was。
GRUS就是透過這種方式來助力於記憶長期依賴關係,下麵是這個視覺化工具,會有助於你理解GRU工作原理:

每個單元均有三個輸入:a, c 和x,以及三個輸出:a, c 和 y(hat)。
3.6 長期短期記憶(LSTM)
當前,LSTM在深度學習中非常流行。由於它們的複雜性,現在可能沒有很多工業應用程式,但請相信我,它們很快就會出現。花點時間學習這個概念是值得的——將來它會派上用場。
為了更好地理解LSTM,讓我們一起回顧一下在GRU那個小節中看到的所有方程:

在計算c的相關性時,只是添加了一個門(gate),而這個門(gate)告訴我們c與c的更新值之間是如何相關的,對於GRUs來說, a = c。
LSTM是增強版的GRU,它的應用更為普遍。LSTM的方程式為:

這和GRU的類似,對吧?我們只是使用a取代了c。更新門的公式也可以寫為:
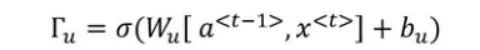
在LSTM中,還有一個遺忘門和一個輸出門。這些門的方程與更新門的方程相類似:

最後,將c的值更新為:
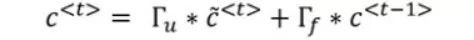
下一層的啟用將是:

你會使用哪種演演算法——GRU還是 LSTM?
每種演演算法都有各自的優點。你會發現:它們的準確度取決於你試圖解決的問題的型別。GRU的優勢在於它有一個更簡捷的架構,因此我們可以用它來構建一些大的模型,然而, LSTM則更為強大和有效,因為它有3個門。
3.7 雙向RNN
到目前為止,我們看到的RNN架構只關註序列中先前的資訊。如果我們的模型能夠同時考慮到序列的先前資訊和後續資訊,同時在特定的時間步長中進行預測,那會有多棒啊?
是的,這完全有可能做到!歡迎來到雙向RNN的世界。但是在介紹雙向RNN以及它們的工作原理之前,還是讓我們先看看為什麼需要它。
來看看一個命名物體識別問題,我們想知道序列中的一個單詞是否代表一個人名。看看下麵這個例子:

他說:“泰迪熊在打折!“
如果我們把這個句子輸入一個簡單的RNN,模型會預測“Teddy”是一個人的名字。它沒有考慮到這個詞後面會發生什麼。透過雙向RNN,可以解決這個問題。
現在假設我們有一個4個單詞的輸入序列,雙向RNN看起來像:

利用以下公式,計算RNN單元的輸出:
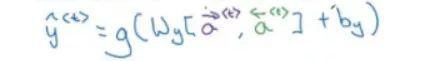
同樣,可以有雙向GRU和雙向LSTM。使用雙向RNN的缺點是,在進行預測之前,必須先檢視整個資料序列。但是,標準的B-RNN演演算法對於構建和設計大多數NLP應用程式時,效率是非常高的。
3.8 深度RNN
還記得深度神經網路的樣子嗎?

它有一個輸入層,一些隱藏層和一個輸出層。深度RNN也類似,它採用相似的網路架構併在時間軸上展開:
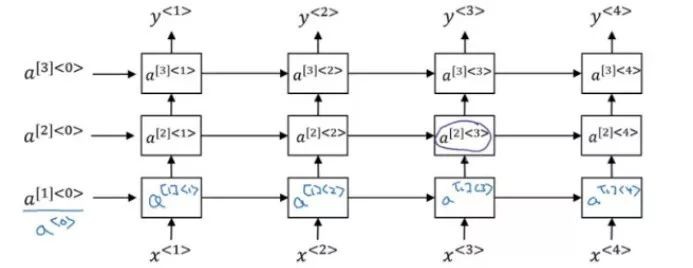
這裡,啟用函式的表示法如下:
假設需要計算a[2]<3> :

這是為深度RNN準備的。深呼吸,這些內容是不是不難消化?下麵,即將進入模組2內容的學習了!
二、模組2:自然語言處理 &單詞嵌入
學習第二個模組的目的是:
-
運用深度學習技術學習自然語言處理
-
瞭解如何使用單詞向量表達和嵌入
-
透過瞭解NLP的多種應用,如情感分析、命名物體識別和機器翻譯,來充實我們的學習。
2.1 第1部分-單詞嵌入簡介
-
文字表示法
在此,我們利用詞彙表來表示多個單詞:

建立一個獨熱向量(one-hot vector)來表示一個單詞:
現在,假設我們希望模型能實現將不同的單詞進行歸納,利用以下句子對模型進行訓練:


給我來杯蘋果汁
將“給我來杯蘋果汁”這句話作為訓練序列,將“果汁”這個單詞設為標的。希望模型生成如下的解決方案:

給我來杯橘子__
為什麼我們先前的詞彙方法在這裡行不通了?因為它缺乏歸納的靈活性,我們嘗試計算一下表示Apple和Orange兩個單詞向量之間的相似性。毋庸諱言,結果為零,因為任何兩個獨熱向量(one-hot vectors)的乘積總是零。
如果用一組特徵來表示每個單詞,而不是用一個獨熱向量(one-hot vectors)來表示,又該怎麼辦?查看下錶:

可以利用這種方法找到類似的單詞。很管用,對吧?
比方說,如果每個單詞有300個特性。例如,單詞“Man”將用一個名稱為e5391.的300維向量來表示。
還可以將這些表達方式進行視覺化,將300維向量轉換為二維向量,然後繪製出來。有多種演演算法可以用來實現這個任務,但是我最喜歡的演演算法是很容易上手的t-SNE。

-
採用單詞嵌入
單詞嵌入確實有助於處理單詞表達和歸納。
如果需要完成一個命名物體識別任務,並且訓練集中只有有限的幾條記錄。在這種情況下,可以採用線上提供的預訓練過的單詞嵌入,也可以建立自己的單詞嵌入。這些嵌入將具備該詞彙表中所有單詞的特徵。
以下兩個步驟,可以實現用單詞嵌入替換獨熱向量(one-hot vectors):
-
從大型文字語料庫中學習單詞嵌入(或下載預訓練的單詞嵌入)
-
將這些嵌入內容遷移到具有較小訓練集的新任務中
接下來,我們將研究單詞嵌入的屬性。
-
單詞嵌入的屬性
假設你有一個問題——“如果男人對應女人,那麼國王對應什麼呢?”大多數熱衷於解謎的人以前都會看到過類似這種問題!
這個問題的答案可能是女王。但是模型將如何決定呢?這實際上是理解單詞嵌入最廣泛使用的示例之一。我們為男人、女人、國王和王后準備了嵌入。男人的嵌入向量與女人的嵌入向量相似,國王的嵌入向量與女王的嵌入向量相似。
可以使用以下公式:
eman – ewoman = eking – ?
給出一個300維的向量用來解決這個問題,其值等於Queen的嵌入值。我們也可以使用相似度函式來確定兩個單詞嵌入之間的相似度。相似函式由以下公式給出:

這是一個餘弦相似性,也可以使用歐氏距離公式:
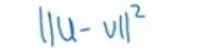
在核心推薦系統中,還可以找到其他幾種不同型別的相似性度量。
-
嵌入矩陣
實際上,當實現一個單詞嵌入演演算法時,我們最終會學習一個嵌入矩陣。如果有一個10,000個單詞的詞彙表,並且每個單詞都有300個特徵,則嵌入矩陣,表示為E,如下所示:

為了找到位於第6257位的“桔子”一詞的嵌入,我們將上面的嵌入矩陣與桔子的單熱向量相乘:
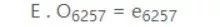
E為(300,10k),O為(10k,1),因此,嵌入向量e的為(300,1)。
2.2 第2部分-學習單詞嵌入:word2vec& GloVe
-
學習單詞嵌入
假設我們用神經網路構建語言模型,模型的輸入是“給我來杯橘子….”,需要模型預測下一個單詞。
首先使用預先訓練的詞嵌入矩陣來學習序列中每個單詞的嵌入,然後將這些嵌入傳遞給一個神經網路,該神經網路會有一個Softmax分類器來預測下一個單詞。

架構便是這樣,在這個例子中,我們有6個輸入單詞,每個單詞用一個300維向量表示,因此該序列的輸入為6*300=1800維,該模型的引數如下:
-
嵌入矩陣(E)
-
w[1],b[1]
-
w[2],b[2]
可以透過減少輸入單詞的數量,來降低輸入維度。如果希望模型只使用前面的4個單詞進行預測,此時,輸入的維度將是1200維。輸入也可以稱為背景關係,並且可以有各種選擇背景關係的方法。有以下幾種可選的方法:
-
選取最後4個單詞
-
選取左起4個單詞,右起4個單詞
-
最後1個單詞
-
可以選取最近的一個單詞
這就是我們透過輸入背景關係和預測標的詞來解決語言建模問題的方法。在下一節中,我們將研究Word2vec如何應用於學習單詞嵌入。
-
Word2VEC
這是學習單詞嵌入的一種簡單而有效的方法。假設訓練集中有一句話:

給我的穀類食品配一杯果汁
跳過語法(skip-gram)模型,來選取一些背景關係和標的詞。用這種方式,建立了一個有監督的學習問題,其中有一個輸入和相應的輸出。對於背景關係,我們不僅僅只有最後4個單詞或最後1個單詞,而是隨機選擇一個單詞作為背景關係單詞,然後在某個視窗中隨機選擇另一個單詞(比如:從左到右的5個單詞),並將其設定為標的單詞。背景關係-標的對可能是:
|
背景關係 |
標的 |
|
桔子 |
果汁 |
|
桔子 |
杯 |
|
桔子 |
我的 |
這裡只選取了部分背景關係-標的對,同樣還可以有更多的背景關係-標的對。下麵是該模型的細節:
Vocab size=10000K
現在,需要學習從背景關係(C)到標的(T)的對映。我們做如下對映:

這裡,ec = E.Oc
Softmax計算出給定背景關係詞(C)時,標的單詞(T)作為輸出的機率。

最後,計算出損失為:

使用SoftMax函式會給演演算法帶來一些問題,其中之一就是計算成本。每次計算機率時:
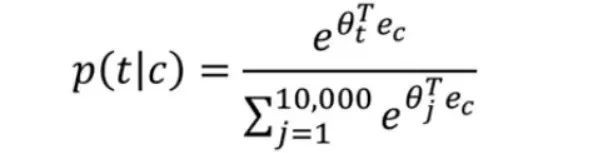
必須對詞彙表中的全部10,000個單詞進行求和。如果使用一個更大的詞彙表,比如100,000個單詞甚至更多,計算會變得非常緩慢。可以透過以下幾個方法解決這個問題:
使用分層的SoftMax分類器。所以,與其一次把一個單詞分為10000個類別,不如先把它分為前5000個類別或後5000個類別,依此類推。這樣就不必每次都計算10000個單詞的和了。分層SoftMax分類器的流程如下:

你腦海中可能會出現這樣一個問題:如何選擇背景關係C?一種方法是隨機抽取背景關係單詞樣本。隨機抽樣的問題是,像“是”(is)這樣的常用詞會出現得更為頻繁,而像“桔子”、“蘋果”這樣的詞甚至可能一次也不會出現。因此,我們試圖選擇這樣一種方法:令不太頻繁的詞具有更大的權重,而較頻繁的詞具有更小的權重。
在下一節中,我們將介紹一種有助於降低計算成本和一種更優的學習單詞嵌入的技術。
-
負抽樣
在跳過語法(skip-gram)模型中,正如前面所述,我們將背景關係單詞對映到標的單詞,這樣就可以學習單詞嵌入。該模型的一個缺點是,SoftMax的計算成本很高。來看一下我們前面所舉的例子:
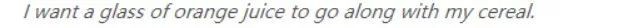
給我的穀類食品配一杯果汁
負抽樣將要做的是,它建立了一個新的有監督的學習問題,在這個問題中,給定一對單詞“桔子”(orange)和“果汁”(juice),我們來預測它是否是背景關係標的對?在上面的例子中,新的監督學習問題將如下所示:
|
背景關係(C) |
單詞(t) |
標的(Y) |
|
桔子 |
果汁 |
1 |
|
桔子 |
國王 |
0 |
|
桔子 |
書 |
0 |
|
桔子 |
這個 |
0 |
由於“桔子”(orange)和“果汁”(juice)是背景關係標的對,所以我們將標的值設定為1,而“桔子”(orange)和“國王”(king)不是上述例子中的背景關係標的對,因此標的值為0。0這個值表示它是負樣本。現在利用邏輯回歸來計算這兩個對是否是背景關係標的對的機率。機率由以下公式給出:

我們可以用K對單詞來訓練這個模型。對於較小的資料集,K的範圍在5-20之間,而對於較大的資料集,我們選擇較小的K(2-5)。所以,可以建立一個神經網路,輸入是“桔子”(orange) (桔子的獨熱向量):

我們將得到一個有10000種可能的分類問題,每個分類問題對應於詞彙表中不同的單詞。因此,這個網路將得出對應背景關係詞“桔子”(orange)的所有可能的標的詞。這裡,我們得到的是10000個二進位制分類問題,而不是一個碩大的10000路SoftMax,這是一個速度非常慢的問題。
背景關係詞從序列中選取,一旦被選定之後,再從序列中隨機選擇另一個單詞作為正樣本,然後從詞彙表中選擇其他幾個隨機單詞作為負樣本。這樣,便可以使用簡單的二進位制分類問題來學習單詞嵌入。接下來我們將看到更為簡單的學習單詞嵌入演演算法。
-
GloVe單詞向量
相同的例子:
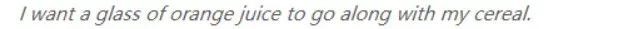
給我的穀類食品配一杯果汁
如前所述,我們從文字語料庫中提取兩個彼此接近的詞,來對單詞對(背景關係和標的)進行抽樣。利用GloVe(Global Vectors全域性向量)表示單詞會更為明晰。假設:
Xij =單詞I 出現在背景關係j 中的次數
其中,i類似於標的(t),而j類似於背景關係(c)。GloVe使以下各項最小化:

這裡,f(xij)為權重項,它為使用頻度大的單詞(如is,of,a,這樣的單詞…)分配較小的權重,為使用頻度小的單詞分配較大的權重,當(Xj)=0時,f(Xj)=0。透過對上述方程進行最小化,最終得到了一個很好的嵌入詞。目前為止,我們已經學到了許多學習單詞嵌入的演演算法。接下來將來學習單詞嵌入(word embeddings)的應用程式。
2.3 第3部分-採用單詞嵌入的應用程式
-
情感分類
經過以上內容的學習,你一定已經很清楚什麼是情感分類了,所以我會加快以下內容的進度。查看下錶,其中包含一些文字及其對應的情感:
|
X(文字) |
Y(情感) |
|
甜點很棒。 |
*** |
|
服務比較慢。 |
** |
|
很適合吃快餐,但沒什麼特別的。 |
*** |
|
完全沒有品味 |
* |
情感分類的應用多種多樣、量也比較大。但在大多數情況下,訓練沒有帶標簽。這就是單詞嵌入的救贖,讓我們來看看如何利用單詞嵌入構建情感分類模型。
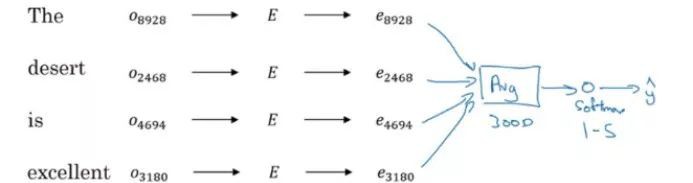
輸入是:“甜點很棒”
這裡,E是預先訓練好的嵌入矩陣,比如說有1000億字。我們用嵌入矩陣對每個單詞的一個獨熱編碼向量進行多重處理,得到單詞的表達形式。接下來,對所有這些嵌入進行總結,並應用Softmax分類器來確定評級。
因為是取所有單詞的平均值,所以即使獲得的是一個負數,但它也是代表肯定的單詞,模型可能會給它比較高的評級。這似乎有點不對勁,所以,我們應採用RNN來進行情感分類,而不是簡單地利用單詞嵌入來獲得輸出。
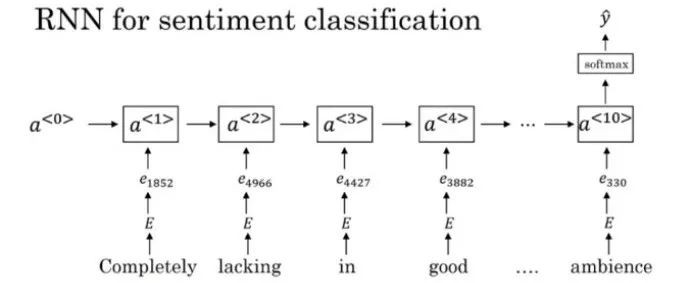
這是一個多對一的問題,我們有一個輸入序列(多個單詞)和一個輸出。到目前為止,你已具備解決此問題的能力。
三、模組3:序列模型與註意力機制(Attention Mechanism)
歡迎來到本課程的最後一個模組!以下是我們將在本單元中主要實現的兩個標的:
-
理解註意力機制
-
理解模型將註意力集中在輸入序列的何處
3.1 基本模型
我儘量保持本節內容與行業的相關性,在此會給出的一些模型,這些模型對機器翻譯、語音識別等應用程式將非常有用。來看一下這個例子——我們的任務是建立一個序列到序列模型,在這個模型中需要輸入一個法陳述句子並將其翻譯成英語。問題如下:

這裡x<1>,x<2>是輸入,y<1>,y<2>是輸出。為了建立一個模型,我們建立一個編碼器,用它接受輸入序列。編碼器架構可以為RNN、LSTM或GRU。在編碼器之後,再構建一個以編碼輸出為輸入的譯碼器網路,並對其進行訓練以生成譯文。

這個網路也普遍應用於影象字幕。作為輸入,我們獲取影象的特徵(使用摺積神經網路生成)。
3.2 選擇可能性最大的句子
機器翻譯系統的譯碼器模型與語言模型非常類似。但兩者之間有一個關鍵區別:在語言模型中,是從全零向量開始,而在機器翻譯中,則有一個編碼器網路:
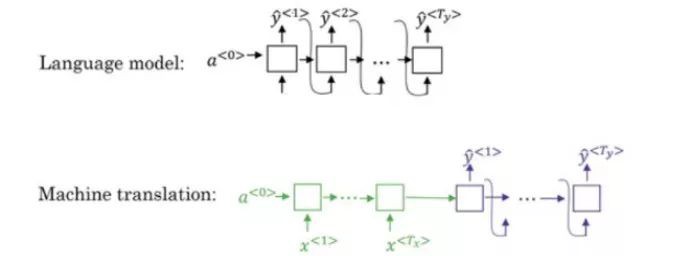
機器翻譯模型的編碼器部分是一個條件語言模型,在該模型中,需要計算出給定輸入的輸出機率:

對於下述輸入陳述句:

可以有多種翻譯,比如:

我們利用下麵的公式,從以上句子中找出最好的譯文。

好訊息是,有一種演演算法可以幫助我們選擇最有可能的翻譯。
3.3 定向搜尋
這是生成最優譯文的常用演演算法之一。該演演算法可以透過以下3個步驟來理解:
第1步:選擇第一個翻譯單詞並計算其機率:
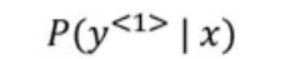
可以設定beam寬度(B)來表示,在這裡:B=3,我們不僅僅選擇一個單詞,可以選出前三個詞,這三個單詞均可能是第一個單詞的譯文。然後將這三個單詞儲存在計算機的記憶體中。
第2步: 對於步驟1中的每個選定單詞,用演演算法計算出第二個單詞的機率:

如果beam寬度(B)為3,詞彙表中有10000個單詞,則可能的組合總數為3*10000=30000。對這3萬種組合進行估算,選出了前3種組合。
第3步:重覆這個過程直到句子結束。
透過每次新增一個單詞,定向搜尋決定了任何給定句子最可能的譯文。可以對定向搜尋做的一些改進,以提高效率。
3.4 定向搜尋的改進
定向搜尋機率最大化:

這個機率是透過把不同單詞的機率相乘計算得到的。由於機率是非常小的數字(介於0和1之間),如果我們將這些小數字多次相乘,最終的輸出就會非常小,這會在計算中產生問題。為此,可以使用以下公式來計算機率:
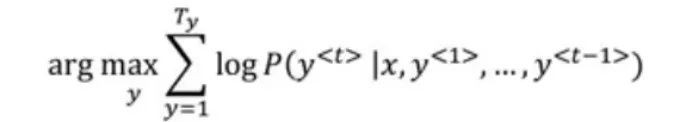
我們不是最大化乘積,而是最大化乘積的對數。但是,即使用這個標的函式,如果譯文中有更多的單詞,乘積的結果也會為負值,對此,可以將函式歸一化:

對於所有使用定向搜尋選擇的句子,計算出歸一化的對數機率,然後選擇計算結果最大的句子。還有一個細節值得分享,如何來決定beam寬度(B)?
beam寬度(B)越大,結果會更優,但演演算法速度會變慢;另一方面,選擇較小的beam寬度(B),將使演演算法執行更快,但結果卻不準確。beam寬度(B)的選擇沒有硬性規定,可以根據應用情況而變化。可以透過嘗試不同的值,然後選擇能生成最佳結果的值。
3.5 定向搜尋誤差分析
定向搜尋是一種近似演演算法,它根據beam寬度(B)輸出機率最大的譯文。但是,並非每次都生成正確的譯文。如果沒有得到正確的譯文,必須分析它的原因:是由於定向搜尋還是RNN模型引起的問題。如果是定向搜尋造成的這個問題,可以加大beam寬度(B),從而得出更好的結果。那麼,如何決定我們應該集中改進波束定向搜尋還是集中改進RNN模型呢?
假設實際的譯文是:

簡9月訪問非洲(y*)
從演演算法中得到的譯文是:

簡去年9月訪問了非洲(Y(Hat))
RNN將計算P(y* | x)和 P(y(hat) | x)
第一種情況:P(Y*X)>P(Y(Hat)X)
這意味著定向搜尋選擇了y(HAT),雖然y*的機率更高。因此,定向搜尋結果是錯誤的,我們可以考慮增加beam寬度(B)。
第二種情況: P(y* | x) <= P(y(hat) | x)
這意味著y*的譯文優於y(HAT),但RNN的預測正好相反。這時,問題出在RNN,應對RNN模型進行改進。
因此,對於每一個翻譯,應決定問題是出在RNN是還是出在定向搜尋。最後,我們分析了定向搜尋和RNN模型的誤差比例,併在此基礎上對定向搜尋或RNN模型進行了更新。這樣便就可以最佳化譯文。
3.6 註意力模型(Attention Model)
到目前為止,我們已經瞭解到了機器翻譯的編碼器-解碼器架構,其中一個RNN讀取輸入,另一個RNN輸出一個句子。但是當我們輸入很長的句子時,模型便很難記住整個句子。
註意力模型是從長句中抽取小樣本並翻譯,然後再抽取另一個樣本進行翻譯,等等。
在生成輸出時,我們使用alpha引數來決定對特定輸入字應該給予多少註意度。
⍺<1,2> = 為生成第一個詞,應給予第二個輸入詞多少關註?
讓我們用一個例子來理解這一點:

為了生成第一個輸出y<1>,應賦予每個單詞多少註意力權重,這就是計算註意力的方法:

如果有Tx輸入詞和Ty 輸出詞,那麼總註意力引數將是Tx * Ty。
你可能已經註意到了——註意力模型是深度學習中最強大的想法之一。
後記
序列模型真不錯,對吧?它們有大量的實際應用——我們只需要知道在特定情況下使用的正確技術。希望你能在本指南中學習到這些技巧。
單詞嵌入是表示單詞的一種很好的方法,我們看到瞭如何構建和使用這些單詞嵌入,與此同時,學習了單詞嵌入的不同應用,最後我們還介紹了註意力模型,這是構建序列模型的最強大的想法之一。
如果你對本文有任何疑問或反饋,請隨時在下麵的評論部分分享。期待你的回覆!
你也可以在Analytics Vidhya的Android應用程式上閱讀本文。
原文標題:
Must-Read Tutorial to Learn Sequence Modeling (deeplearning.ai Course #5)
原文連結:
https://www.analyticsvidhya.com/blog/2019/01/sequence-models-deeplearning/
編輯:黃繼彥
譯者簡介:陳之炎,北京交通大學通訊與控制工程專業畢業,獲得工學碩士學位,歷任長城計算機軟體與系統公司工程師,大唐微電子公司工程師,現任北京吾譯超群科技有限公司技術支援。目前從事智慧化翻譯教學系統的運營和維護,在人工智慧深度學習和自然語言處理(NLP)方面積累有一定的經驗。
