
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @spider。不同於傳統推薦方法將社交資訊作為使用者的附加資訊,在同一個域預測使用者偏好。本文選擇在資訊域中學習使用者偏好,然後將其沿社交網路進行傳播,使原本不在該域的使用者也可以學到他的偏好資訊,角度新穎。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:黃若孜,復旦大學軟體學院碩士生,研究方向為推薦系統。
■ 論文 | Item Silk Road: Recommending Items from Information Domains to Social Users
■ 連結 | http://www.paperweekly.site/papers/1885
■ 作者 | Xiang Wang / Xiangnan He / Liqiang Nie / Tat-Seng Chua
論文動機
線上平臺一般分為兩種,一種是資訊導向的,比如一些電商的網站,強調 user-item 的相互作用;另一種是社交導向的,比如推特等提供社交網路服務,有豐富的 user-user 連結。雖然這兩種 domain 是異構的,但是他們會共有一些使用者,稱為橋梁使用者(bridge users),透過他們我們可以進行跨域社交推薦,也就是在社交網路中的一些潛在使用者推薦資訊 domain 中的相關 items。
當前大部分的 cross domain 的推薦方法都是對同構的域,而針對本文的 task,存在的困難有:
-
資料集中橋梁使用者的不足
-
在資訊域中的 attribute 充足,但是很少有人關註利用這些 attribute 來提高對社交網路中使用者的推薦結果
本文提出了一種稱為 Neural Social Collaborative Ranking (NSCR) 的方法來利用資訊域中 user-item connection 和社交域中的 user-user connection。在資訊域,利用屬性增強對 user 和 item embedding 的效果,在社交域中,將橋梁使用者的 embedding 結果透過社交網路傳播給非橋梁使用者。
問題描述
在資訊域中,使用者集合 U1,專案集合 I,使用者給專案的打分資訊為矩陣 Y,關於使用者和專案的 attributes 分別為 Gu 和 Gi 表示;在社交域中,使用者集合 U2,社交關係為 S。兩個域的橋梁使用者為 U=U1∩U2。
輸入:資訊域 {U1,I,Y,Gu,Gi},社交域 {S,U2},U1∩U2 非空。
輸出:為社交域中每一個使用者 u’ 確定一個對 items 的排名函式。
NSCR Solution
矩陣分解模型(MF)是推薦系統重要的一個模型,這裡先引入一個觀點,即 CF 模型可以看做是一個淺層神經網路模型。
如下圖所示,我們輸入使用者\專案 ID 的 one-hot 的表示,然後將其對映到一個 embedding 層,將兩者 embedding 向量進行逐元素相乘,得到向量 h(如果直接將 h 對映到一個打分值的話,那麼這個模型就是 MF 模型)。

本文認為,MF 的表現受限於使用內積來捕捉 user-item 互動作用;同樣,在常規的對 attributes 的利用上,單純的讓使用者 embedding 和 attribute embedding 相加,也不足以捕捉 user、item、attribute 之間的聯絡。
由於 task 是為社交網路中的使用者進行跨域推薦,本文使用了基於表示學習(embedding)的方法,認為問題的關鍵在於如何將 item 和來自社交網路的使用者對映到相同的 embedding 空間。
由於兩個域的使用者只有少量的重合,本文給出的解決方案是分開學習兩個域的 embedding,而強迫兩個學習過程共享相同橋梁使用者的 embedding。最佳化標的為 ,等號右邊分別是兩個域各自的標的函式。
,等號右邊分別是兩個域各自的標的函式。
1. Learning of Information Domain
學習 cf 模型的引數,有兩種標的函式:point-wise 和 pair-wise 標的函式,前者最小化預測分值和真實分值之間的損失,後者本質上是負取樣,適合於本文中使用隱式反饋,同時要得到每個使用者的個性化 item 排序的任務。
首先取三元組 (u,i,j),其中 u 是一個使用者,i 是該使用者評分過的專案 (yui = 1),j 是使用者沒有評分過的專案 (yuj = 0)。標的函式想要學到 (i,j) 的正確順序:

其中 yuij = yui – yuj,^yuij = ^yui – ^yuj,其中 ^yui 是預測打分值。
確定標的函式之後,我們來看預測值 ^yui 是透過怎樣的模型得到的。本文在 Neural Collaborative Filtering 模型的基礎上,進一步加入了 attribute 的資訊,結構如下圖所示:

輸入層:輸入四種資訊的 id,用 one-hot 向量表示。
embedding:將四種資訊分別進行 embedding。
pooling 層:由於 attributes 的數量不確定,embedding 後的向量集大小不確定,為了給後面的 nn 一個定長的資訊,進行 pooling 操作。
由於最大\平均 pooling 不能捕捉使用者和各 attributes 之間的互動作用,所以設計了一種 pairwise pooling 的方法:

對專案也做類似處理,最後將 pu⊙qi 的結果作為後面 MLP 的輸入,MLP 輸出預測結果。
2. Learning of Social Domain
在社交域中,本文使用了半監督學習的方法將資訊域中使用者 embedding 結果從橋梁使用者傳播到非橋梁使用者。這基於這樣的一個假設:如果兩個使用者有很強的社交關係,那麼他們可能會有相似的偏好,從而在 latent space 有相似的特徵表示。
學習包括兩部分:
平滑約束(smoothness constrain):定義了結構一致性損失,希望相鄰的使用者的表示相似;su’,u” 是兩個使用者社交關係的強度,du’ 是節點 u’ 的出度,稱為平滑約束是因為為每個使用者的特徵表示除以了出度的開方,進行了平滑,如果沒有這個處理,那麼社交關係多的活躍使用者將會產生更有效的傳播。

擬合約束:為了使兩個域的 latent space 保持一致,迫使橋梁使用者的兩種表示接近,也就是擬合損失:


訓練完成後,將 pu’ 輸入資訊域中的預測框架,得到預測 item 的排名。
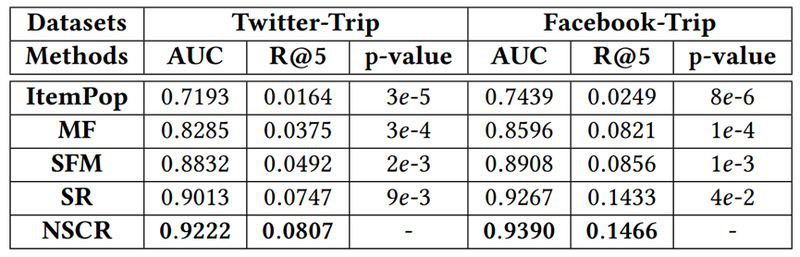
實驗結果
資訊域資料集來自 trip.com,同時找到其中一些使用者相關的 Facebook 和 Twitter 資訊。評估指標為個性化排序的指標 AUC 和 Recall@k。
由於非橋梁使用者沒有評分資訊,無法驗證預測是否正確,所以使用了一部分的橋梁使用者作為測試集。可以看到預測結果優於 state of art。
評價
不同於傳統推薦方法將社交資訊作為使用者的附加資訊,在同一個域預測使用者偏好,本文是在資訊域中學習了使用者偏好,然後將其沿社交網路進行了傳播,使原本不在該域的使用者也可以學到他的偏好資訊,角度新穎。
關於異構的推薦,是一個很有意思的 task,值得去 follow。
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:

▲ 戳我檢視招募詳情
 #作 者 招 募#
#作 者 招 募#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文