
筆者邀請您,先思考:
1 您怎麼理解LDA演演算法?
2 您怎麼應用LDA演演算法?
3 LDA演演算法的優劣是什麼?
思想簡介
Latent Dirichlet Allocation是Blei等人於2003年提出的基於機率模型的主題模型演演算法,LDA是一種非監督機器學習技術,可以用來識別大規模檔案集或語料庫中的潛在隱藏的主題資訊。該方法假設每個詞是由背後的一個潛在隱藏的主題中抽取出來。
對於語料庫中的每篇檔案,LDA定義瞭如下生成過程(generative process):
1.對每一篇檔案,從主題分佈中抽取一個主題
2. 從上述被抽到的主題所對應的單詞分佈中抽取一個單詞
3. 重覆上述過程直至遍歷檔案中的每一個單詞。

當求解出tassign-model.txt後,其他輸出都可以透過tassign-model.txt計算得出。
LDA圖模型

圖中的陰影圓圈表示可觀測變數(observed variable),非陰影圓圈表示潛在變數(latent variable),箭頭表示兩變數間的條件依賴性(conditional dependency),方框表示重覆抽樣,重覆次數在方框的右下角。這裡對應了LDA的生產過程。
![]()
每次生成一篇新的檔案前,上帝從服從α為引數的Dir分佈的罈子中抽取出一個doc->topic骰子,然後重覆以下步驟:
i. 投擲這個doc->topic骰子,得到一個topic編號z。
ii. 從服從β為引數的dir分佈的罈子裡共K個topic-word骰子中選擇編號為z的那個,投擲這枚骰子,於是得到一個詞。
Gibbs Sampling
怎麼得到θ和φ的後驗估計?有貝葉斯公司知道,後驗透過先驗和似然進行計算。

直接計算θ和φ的分佈是有困難的,這裡採用透過計算每篇文章的每個詞所屬的主題,然後在計算θ和φ的分佈。這裡是多維隨機過程,可以證明在經過多輪抽樣後隨即變數收斂。證明過程這裡不作討論。在初始情況下,對每篇文章的每個單詞設定隨即的主題,然後開始抽樣過程,我們從程式碼來解讀sampling過程。
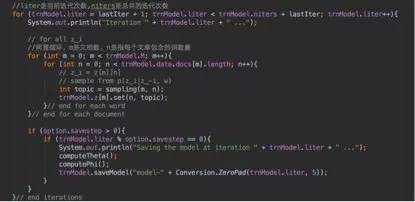
這裡的第一層迴圈是每次迭代,第二層迴圈是語料集的每一篇文章,第三層迴圈是文章的每一個詞,訓練裡是sampling函式,來具體看看裡面是什麼:

註意第一個紅框,求的值為第m篇文章的第n個詞選取k為主題(乘號後面的值)並且在k主題下選取w作為詞(乘號前面的值)的機率。每個值都是似然加上先驗,似然即為從語料中和上一層迭代得到的結果,先驗即為超參alpha和beta。為什麼是直接相加,則是dir分佈的引數被稱為偽計數的原因。(這裡不作證明)。
第二個紅框是怎麼得到下一個抽樣的過程,由上已經得到主題k的所有機率,把這裡值加和在一起,然後在[0,sum(p(k))]的均勻分佈抽樣u,如果u在哪個p(k)裡那麼k即為抽樣值。
結果展示:

LDA應用
1、 相似檔案發現
這個方法可以被用作新聞推薦中,正文詳情頁的“相關推薦”,該方法所述的相似檔案是指的“主題層面”上的相似,這就比其他的基於word來挖掘的相似度更有意義。

模型輸出文件下主題的分佈檔案theta-model.txt,計算兩個檔案分佈的差異。常用的距離有:海林格距離和KL距離(相對熵)。
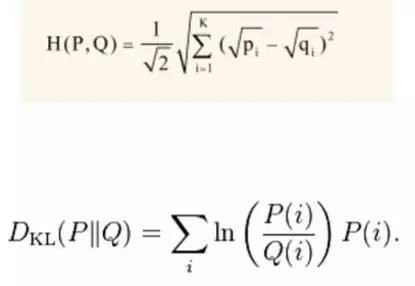
2、 新聞個性化推薦
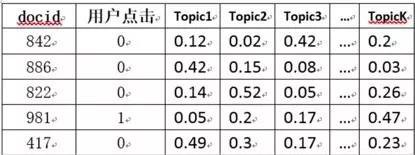
方法一:LDA+LR.透過LDA訓練得到的theta檔案,可以得到上圖右部分。再透過使用者的點選為標簽,透過LR做有監督訓練,得到所有主題的權重Wi,再用這個weight向量對每篇新的新聞文章使用線性加權公式: doc_score = w1 * topic1 + w2 * topic2 + …,從大到小按照score排序後,可以立即為使用者提供個性化推薦。
方法2:user profile記錄喜好topic法演演算法步驟:
1.提取topic:文章LDA訓練後的theta檔案,提取每篇文章機率最大的前3個topic主題
2.save topic—>user profile:當使用者訪問文章A後,就把文章A的top 3的topic貼到使用者興趣檔案裡,並將機率分值相加,如果過了1天使用者沒有訪問網站或訪問這個topic的文章,就按照該topic乘以0.8衰減,直至衰減到0。
3.產生推薦:下次使用者再次訪問網站時,從使用者興趣檔案找出使用者最感興趣(分值最大)的k個topic,然後選取這幾個topic下熱門的文章為使用者推薦。
3、 自動打標簽
演演算法實現也很簡單,需要模型輸出的theta和phi檔案。根據該文章最大主題編號找出該文章下該機率最大主題編號下的機率最大n個word詞(max top n),(換句話說:該文章最大主題下的最大機率的n個詞)作為該文章標簽輸出。
4、 wordRank
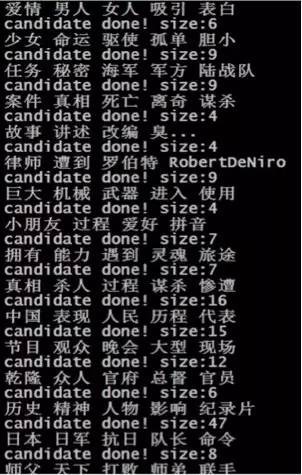
目的:是選取當前檔案下具有代表性特徵的詞。方法:讀取phi檔案,由於phi中的機率值是topic—>word 的,而我們需要的是word—>topic的反向關係,因此計算Wc={Wc1,…Wck},計算公式如下,也即是將 phi 檔案矩陣轉置後歸一化(這裡的大寫K是主題總數,c是當前詞)。然後計算與噪音向量[1/k,…,1/k]的距離。下麵是一個汽車語料得到的結果:

wordRank的結果可以幫助分類器作特徵選擇。例如我們需要按照店家給出的商品標題描述分類,但是,如果你仔細觀察店家給出的商品標題,會發現如下情況:店家為了增加他們被搜尋命中的機會,通常在標題上填寫很多重覆冗餘無用的資訊,比如圖上的標題中“套頭”這個詞的意思是:沒有釦子或者拉鏈的,必須從頭上套著穿的。但是這個詞是不能用作分類的依據的,搜尋時我只想按照商品的主要特徵詞來分類,而非“套頭”。

LDA的應用有很多,它只是一個中間結果,我們可以在這個中間結果基礎上做出自己的運用,上面的應用也可以進行最佳化。
文章推薦:
您有什麼見解,請留言。
加入資料人圈子或者商務合作,請新增筆者微信。

資料人網是資料人學習、交流和分享的平臺http://shujuren.org 。專註於從資料中學習到有用知識。
平臺的理念:人人投稿,知識共享;人人分析,洞見驅動;智慧聚合,普惠人人。
您在資料人網平臺,可以1)學習資料知識;2)建立資料部落格;3)認識資料朋友;4)尋找資料工作;5)找到其它與資料相關的乾貨。
我們努力堅持做原創,聚合和分享優質的省時的資料知識!
我們都是資料人,資料是有價值的,堅定不移地實現從資料到商業價值的轉換!
點選閱讀原文,進入資料人網,獲取資料知識。
公眾號推薦:
區塊鏈傳達,專註於分享區塊鏈內容。

腳印英語,專註於分享英語口語內容。

