

執行平臺: Windows
Python版本: Python3.x
IDE: Sublime text3
作者:Jack-Cui
源自:https://blog.csdn.net/c406495762/article/details/72331737
前言
大家都應該有過從百度文庫下載東西的經歷,對於下載需要下載券的文章,我們可以辦理文庫VIP(土豪的選擇):

有的人也會在某寶購買一定的下載券,然後進行下載。而另一些勤勤懇懇的人,則會選擇上傳文章,慢慢攢下載券。任勞任怨的人,則會自己一點一點的複製貼上,複製到word裡文字太大,那就複製到txt檔案裡。而既不想花錢又不想攢下載券,也不想一點一點複製貼上的人,會選擇“冰點文庫”這樣的下載軟體,不過貌似現在“冰點文庫”已經不能使用了。當然,還有一些其他破解方法,比如放到手機的百度文庫APP裡,另存為文章,不需要下載券就可以下載文章。諸如此類的方法,可謂五花八門。而對於學習爬蟲的人來說,面對怎樣免費下載一個付費的word文章的問題,第一個想到的應該就是:自己寫個程式搞下來。
問題分析
我們以如何下載下麵這篇文章為例,分析問題:
URL : https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html
看到這樣的一個文章,如果爬取當前頁面的內容還是很好爬的吧。
感覺so easy!至少我當時是這麼想的,但是當把文章翻到最下方的時候,我看到瞭如下內容:

需要點選“繼續閱讀”才能顯示後續的內容,我單爬這一頁內容,是爬不到後續的內容的。第一個想到的方法是,抓包分析下,然後我又一次蒙逼了:

Request URL這麼長!!最後的expire時間資訊好解決,其他的資訊呢?不想做無謂的掙扎,因此,我果斷地放棄這個方法。
問題:獲取當前頁的內容好辦,怎麼獲取接下來頁面的內容?
帶著這個思考,Selenium神器走入了我的視線。
Selenium
Selenium 是什麼?一句話,自動化測試工具。它支援各種瀏覽器,包括 Chrome,Safari,Firefox 等主流介面式瀏覽器,如果你在這些瀏覽器裡面安裝一個 Selenium 的外掛,那麼便可以方便地實現Web介面的測試。換句話說叫 Selenium 支援這些瀏覽器驅動。Selenium支援多種語言開發,比如 Java,C,Ruby等等,而對於Python,當然也是支援的!
安裝
pip install selenium
詳細內容可檢視官網檔案:
http://selenium-python.readthedocs.io/index.html
1/ 小試牛刀
我們先來一個小例子感受一下 Selenium,這裡我們用 Chrome 瀏覽器來測試。
from selenium import webdriver
browser = webdriver.Chrome()
browser.get(‘http://www.baidu.com/’)
執行這段程式碼,會自動開啟瀏覽器,然後訪問百度。
如果程式執行錯誤,瀏覽器沒有開啟,那麼應該是沒有裝 Chrome 瀏覽器或者 Chrome 驅動
沒有配置在環境變數裡。下載驅動,然後將驅動檔案路徑配置在環境變數即可。
驅動下載地址:https://sites.google.com/a/chromium.org/chromedriver/downloads
windows下設定環境變數的方法:
win+r,輸入sysdm.cpl,點選確定,出現如下對話方塊:
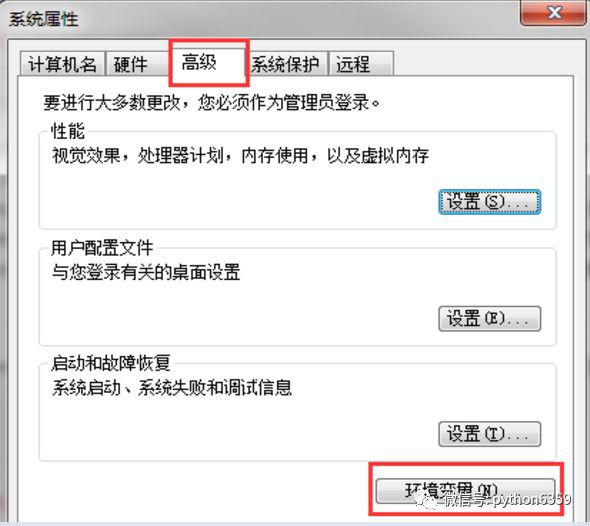
選擇高階->環境變數。在系統變數的Path變數中,新增驅動檔案路徑即可(註意:分號)。
Linux的環境變數也好設定,在~/.bashrc檔案中export即可,記得source ~/.bashrc。
當然,你不設定環境變數也是可以的,程式可以這樣寫:
from selenium import webdriver
browser = webdriver.Chrome(‘path\to\your\chromedriver.exe’)
browser.get(‘http://www.baidu.com/’)
path\to\your\chromedriver.exe 是你的chrome驅動檔案位置,可以使用絕對路徑。
我們透過驅動的位置傳遞引數,也可以呼叫驅動,結果如下圖所示:
2/ 模擬提交
下麵的程式碼實現了模擬提交提交搜尋的功能,首先等頁面載入完成,然後輸入到搜尋框文字,點選提交,然後使用page_source列印提交後的頁面的資訊。

全自動的哦,程式操控!是不是很酷炫?

其中 driver.get 方法會開啟請求的URL,WebDriver 會等待頁面完全載入完成之後才會傳回,即程式會等待頁面的所有內容載入完成,JS渲染完畢之後才繼續往下執行。註意:如果這裡用到了特別多的 Ajax 的話,程式可能不知道是否已經完全載入完畢。
WebDriver 提供了許多尋找網頁元素的方法,譬如 find_element_by_* 的方法。例如一個輸入框可以透過 find_element_by_name 方法尋找 name 屬性來確定。
然後我們輸入來文字然後模擬點選了回車,就像我們敲擊鍵盤一樣。我們可以利用 Keys 這個類來模擬鍵盤輸入。
最後最重要的一點是可以獲取網頁渲染後的原始碼。透過,輸出 page_source 屬性即可。這樣,我們就可以做到網頁的動態爬取了。
3/ 元素選取
關於元素的選取,有如下API:
單個元素選取:
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
多個元素選取:
find_elements_by_name
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
另外還可以利用 By 類來確定哪種選擇方式:
from selenium.webdriver.common.by
import Bydriver.find_element(By.XPATH, ‘//button[text()=”Some text”]’)
driver.find_elements(By.XPATH, ‘//button’)
By類的一些屬性如下:
ID = “id”
XPATH = “xpath”
LINK_TEXT = “link text”
PARTIAL_LINK_TEXT = “partial link text”
NAME = “name”
TAG_NAME = “tag name”
CLASS_NAME = “class name”
CSS_SELECTOR = “css selector”
這些方法跟JavaScript的一些方法有相似之處,find_element_by_id,就是根據標簽的
id屬性查詢元素,find_element_by_name,就是根據標簽的name屬性查詢元素。
舉個簡單的例子,比如我想找到下麵這個元素:
type=“text” name=“passwd” id=“passwd-id” />
我們可以這樣獲取它:
element = driver.find_element_by_id(“passwd-id”)
element = driver.find_element_by_name(“passwd”)
element = driver.find_elements_by_tag_name(“input”)
element = driver.find_element_by_xpath(“//input[@id=’passwd-id’]”)
前三個都很好理解,最後一個xpath什麼意思?這個無需著急,xpath是非常強大的元素查
找方式,使用這種方法幾乎可以定位到頁面上的任意元素,在後面我會進行單獨講解。
4/ 介面互動
透過元素選取,我們能夠找到元素的位置,我們可以根據這個元素的位置進行相應的事件操作,例如輸入文字框內容、滑鼠單擊、填充表單、元素拖拽等等。由於篇幅原因,我就不一一講解了,主要講解本次實戰用到的滑鼠單擊,更詳細的內容,可以檢視官方檔案。
elem = driver.find_element_by_xpath(“//a[@data-fun=’next’]”)
elem.click()
比如上面這句話,我使用
find_element_by_xpath()找到元素位置,暫且不用理會這句話什麼意思,暫且理解為找到了一個按鍵的位置。然後我們使用click()方法,就可以觸發滑鼠左鍵單擊事件。是不是很簡單?但是有一點需要註意,就是在點選的時候,元素不能有遮擋。什麼意思?就是說我在點選這個按鍵之前,視窗最好移動到那裡,因為如果這個按鍵被其他元素遮擋,click()就觸發異常。因此穩妥起見,在觸發滑鼠左鍵單擊事件之前,滑動視窗,移動到按鍵上方的一個元素位置:page = driver.find_elements_by_xpath(“//div[@class=’page’]”)
driver.execute_script(‘arguments[0].scrollIntoView();’, page[-1])#拖動到可見的元素去
上面的程式碼,就是將視窗滑動到page這個位置,在這個位置,我們能夠看到我們需要點
擊的按鍵。
5/ 新增User-Agent
使用webdriver,是可以更改User-Agent的,程式碼如下:

使用Android的User-Agent開啟瀏覽器,畫風是這樣的

Selenium就先介紹這麼多,對於本次實戰內容,已經足夠。那麼接下來,讓我們聊聊xpath。
Xpath
這個方法是非常強大的元素查詢方式,使用這種方法幾乎可以定位到頁面上的任意元素。在正式開始使用XPath進行定位前,我們先瞭解下什麼是XPath。XPath是XML Path的簡稱,由於HTML檔案本身就是一個標準的XML頁面,所以我們可以使用XPath的語法來定位頁面元素。
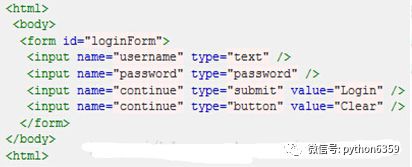
假設我們現在以圖所示HTML程式碼為例,要取用對應的物件,XPath語法如下:
絕對路徑寫法(只有一種),寫法如下:
取用頁面上的form元素(即原始碼中的第3行):
/html/body/form[1]
註意
-
元素的xpath絕對路徑可透過firebug直接查詢。
-
一般不推薦使用絕對路徑的寫法,因為一旦頁面結構發生變化,該路徑也隨之失效,必須重新寫。
-
絕對路徑以單/號表示,而下麵要講的相對路徑則以
//表示,這個區別非常重要。另外需要多說一句的是,當xpath的路徑以/開頭時,表示讓Xpath解析引擎從檔案的根節點開始解析。當xpath路徑以//開頭時,則表示讓xpath引擎從檔案的任意符合的元素節點開始進行解析。而當/出現在xpath路徑中時,則表示尋找父節點的直接子節點,當//出現在xpath路徑中時,表示尋找父節點下任意符合條件的子節點,不管嵌套了多少層級(這些下麵都有例子,大家可以參照來試驗)。弄清這個原則,就可以理解其實xpath的路徑可以絕對路徑和相對路徑混合在一起來進行表示,想怎麼玩就怎麼玩。
下麵是相對路徑的取用寫法:

Xpath功能很強大,所以也可以寫得更加複雜一些,如下麵圖所示的HTML原始碼。

如果我們現在要取用id為“J_password”的input元素,該怎麼寫呢?我們可以像下麵這樣寫:
//*[@id=’J_login_form’]/dl/dt/input[@id=‘J_password’]
也可以寫成:
//*[@id=‘J_login_form’]/*/*/input[@id=‘J_password’]
這裡解釋一下,其中//*[@id=’ J_login_form’]這一段是指在根元素下查詢任意id為J_login_form的元素,此時相當於取用到了form元素。後面的路徑必須按照原始碼的層級依次往下寫。按照圖(3)所示程式碼中,我們要找的input元素包含在一個dt標簽內,而dt又包含在dl標簽內,所以中間必須寫上dl和dt兩層,才到input這層。當然我們也可以用*號省略具體的標簽名稱,但元素的層級關係必須體現出來,比如我們不能寫成//*[@id='J_login_form']/input[@id='J_password'],這樣肯定會報錯的。
前面講的都是xpath中基於準確元素屬性的定位,其實xpath作為定位神器也可以用於模糊匹配。本次實戰,可以進行準確元素定位,因此就不講模糊匹配了。如果有興趣,可以自行瞭解。
以上面提到的文章為例,進行爬取講解。
URL : https://wenku.baidu.com/view/aa31a84bcf84b9d528ea7a2c.html
由於網頁的百度文庫頁面複雜,可能抓取內容不全,因此使用User-Agent,模擬手機登入,然後列印文章標題,文章頁數,併進行翻頁。先看下這個網站。

我們需要找到兩個元素的位置,一個是頁碼元素的位置,我們根據這個元素的位置,將瀏覽器的滑動視窗移動到這個位置,這樣就可以避免click()下一頁元素的時候,有元素遮擋。然後找到下一頁元素的位置,然後根據下一頁元素的位置,觸發滑鼠左鍵單擊事件。
我們審查元素看一下,這兩個元素:


我們根據這兩個元素,就可以透過xpath查詢元素位置,程式碼分別如下:
page = driver.find_elements_by_xpath(“//div[@class=’page’]”)
nextpage = driver.find_element_by_xpath(“//a[@data-fun=’next’]”)
由於page元素有很多,所以我們使用find_elements_by_xpath()方法查詢,然後使用
page[-1],也就是連結串列中的最後一個元素的資訊進行瀏覽器視窗滑動,程式碼如下:

執行效果,自動翻頁有了
爬取內容這裡,用BeautifulSoup就可以。這裡不再細獎,審查元素,自己分析下就有了。程式碼如下:
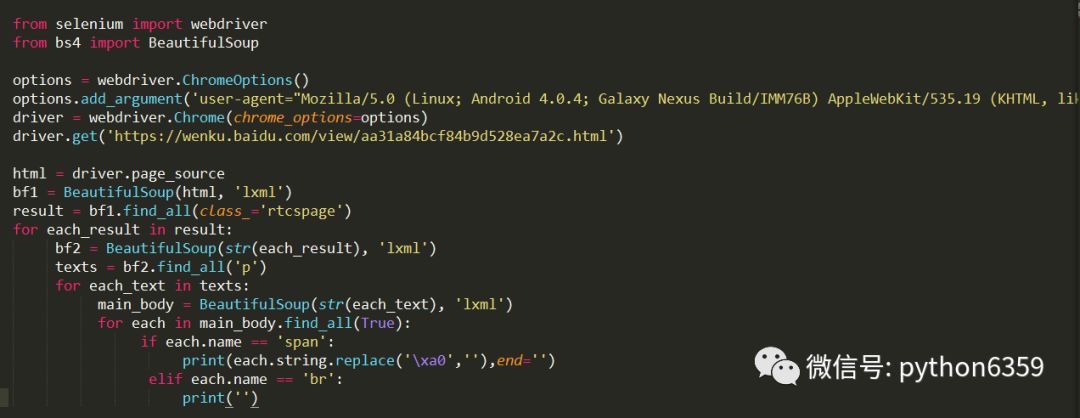
爬取結果如下:
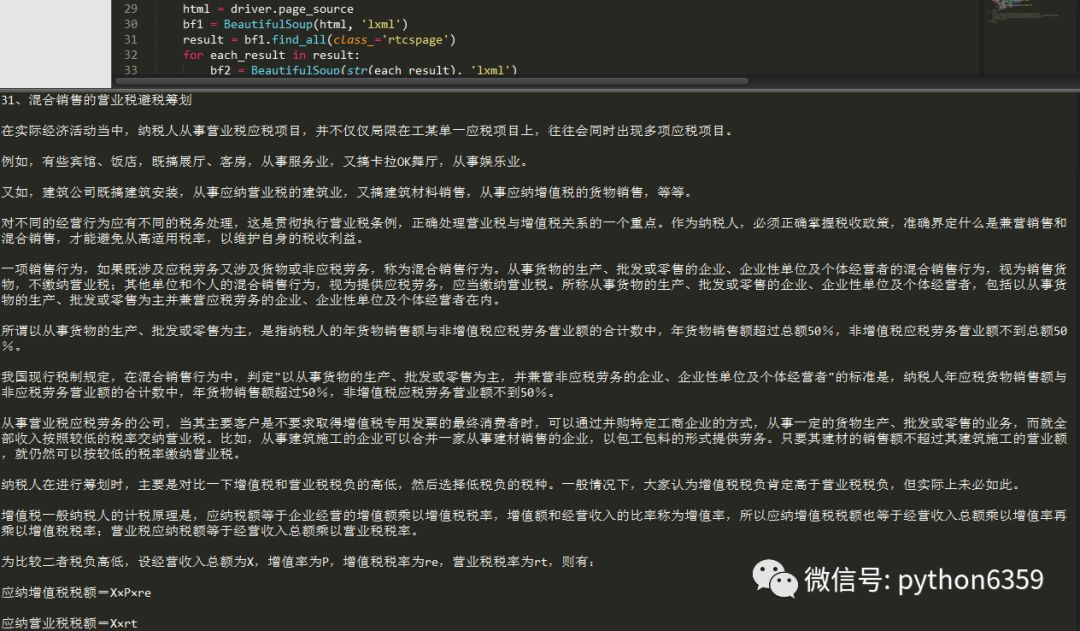
爬取的內容還是蠻規整的,對吧?
我們能夠翻頁,也能夠爬取當前頁面內容,程式碼稍作整合,就可以爬取所有頁面的內容了!找下網頁的規律就會發現,5頁文章放在一個網頁裡。思路:爬取正文內容,再根據爬取到的文章頁數,計算頁數/5.0,得到一個分數,如果這個分數大於1,則翻頁繼續爬,如果小於或等於1,代表到最後一頁了。停止翻頁。有一點註意一下,翻頁之後,等待延時一下,等待頁面載入之後在爬取內容,這裡,我們使用最簡單的辦法,用sleep()進行延時。因此總體程式碼如下:

執行結果:

瞧,最後一頁的內容也爬取下來了,接下來的工作就簡單了,把這個結果寫到txt檔案中,我這裡就不再進行講解了。
至此,整篇的內容,我們都爬取下來了。是不是很酷?那就開始動手實踐吧!
這樣爬取是可以爬取到內容,但是缺點也很明顯:
1、沒有處理圖片內容,可以後續完善;
2、程式碼通用性不強,有的文章結構不是這樣,需要對程式碼進行略微修改,才能爬取到內容;
3、對於上百頁的內容爬取有些問題,翻頁方式變了,需要換種方法處理,有興趣的可以自己看下;
4、等待頁面切換方法太out,可以使用顯示等待的方式,等待頁面載入;
5、selenium雖好,但是有些耗時,可以使用PhantomJS對這部分程式碼進行替換;
最後,我感覺我的方法可能有些low,如果有更好的方法,歡迎交流。
PS:如果覺得本篇本章對您有所幫助,歡迎關註、評論

