每當有機會寫故障類主題的時候,我都會在開始前靜靜地望著顯示器很久,經過多次煎熬和掙扎之後才敢提起筆來,為什麼呢?
因為這樣的話題很容易招來吐槽,比如 “說了半天,不就是配置沒配好嗎?”,或者 “這程式碼是佩奇寫的嗎?你們團隊有懂效能測試的同學嗎?”,這樣的評論略帶挑釁,而且充滿了鄙視之意。
不過我覺得,在技術的世界裡,多數情況都是客觀場景決定了主觀結果,而主觀結果又反映了客觀場景,把場景與結果串起來,用自己的方式寫下來,傳播出去,與有相同經歷的同學聊上一聊,也未嘗不是一件好事。
上個月,我們的系統因註冊中心崩塌而引發的一場事故,本是一件稀鬆平常的事件,可我們猜中了開始卻沒料到原因,始作俑者竟是已在產線執行多年的某分散式快取系統。
回顧一下故障過程
這到底是怎麼一回事呢?先來回顧一下故障過程。
11 月,某交易日的上午 10 點左右。在中介軟體監控系統沒有觸發任何報警的情況下,某應用團隊負責人突然跑過來說:“怎麼快取響應這麼慢?你們在乾什麼事嗎?”
由於此正在交易盤中,中介軟體運維團隊瞬間炸鍋,緊急查看了一系列監控資料,先是透過 Zabbix 檢視瞭如 CPU、記憶體、網路及磁碟等基礎預警,一切正常,再檢視服務健康狀況,經過一圈折騰之後,也沒發現任何疑點。
懵圈了,沒道理啊。10 點 30 分,收到一通報警資訊,內容為 “ZK 叢集中的某一個節點故障,埠不通,不能獲取 Node 資訊,請迅速處理!”。
這簡單,ZK 服務埠不通,重啟,立即恢復。10 點 40 分,ZK 叢集全部癱瘓,無法獲取 Node 資料。
由於應用系統的 Dubbo 服務與分散式快取使用的是同一套 ZK 叢集,而且在此期間應用未重啟過,因此應用服務自身暫時未受到影響。
沒道理啊,無論應用側還是快取側,近一個月以來都沒有釋出過版本,而且分散式快取除了在 ZK 中存一些節點相關資訊之外,基本對 ZK 無依賴。
10 點 50 分,ZK 叢集全部重啟,10 分鐘後,再次癱瘓。神奇了,到底哪裡出了問題呢?
10 點 55 分,ZK 叢集全部重啟,1 分鐘後,發現 Node Count 達到近 22W+,再次崩潰。

10 點 58 分,透過增加監控指令碼,查明 Node 源頭來自分散式快取系統的本地快取服務。
11 點 00 分,透過控制檯關閉本地快取服務後,ZK 叢集第三次重啟,透過指令碼刪除本地化快取所產生的大量 Node 資訊。
11 點 05 分,產線 ZK 叢集全部恢復,無異常。一場風波雖說過去了,但每個人的臉上流露出茫然的表情。
邪了門了,這本地快取為什麼能把註冊中心搞崩塌?都上線一年多了,之前為什麼不出問題?為什麼偏偏今天出事?一堆的問號,充斥著每個人的大腦。
我們本地快取的工作機制
在這裡,我就透過系統流程示意圖的方式,簡要的說明下我們本地快取系統的一些核心工作機制。
①非本地快取的工作機制
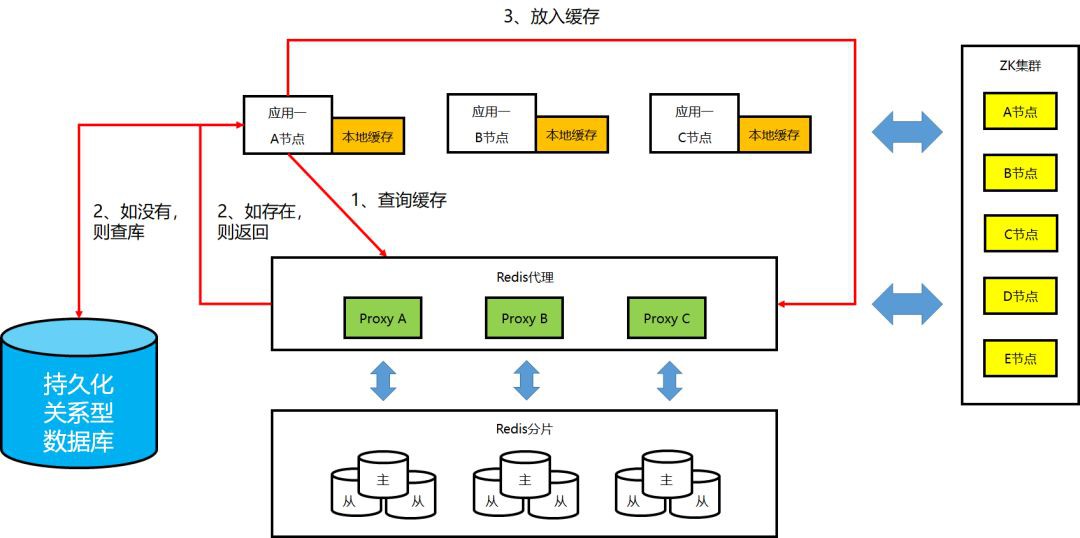
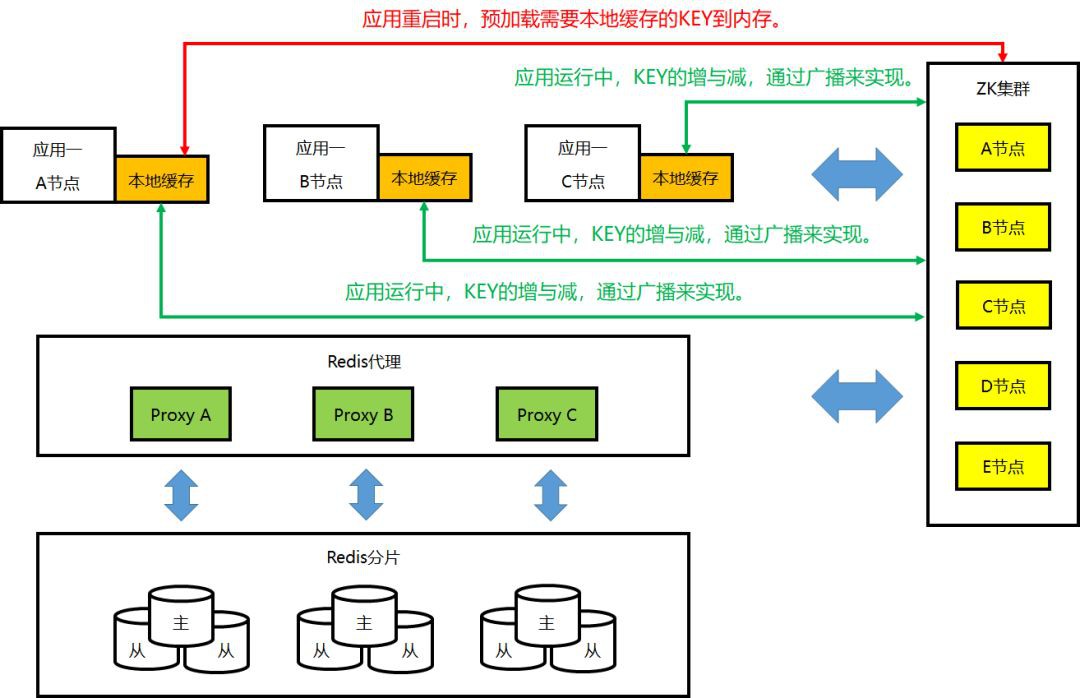
②本地快取的工作機制:Key 預載入/更新
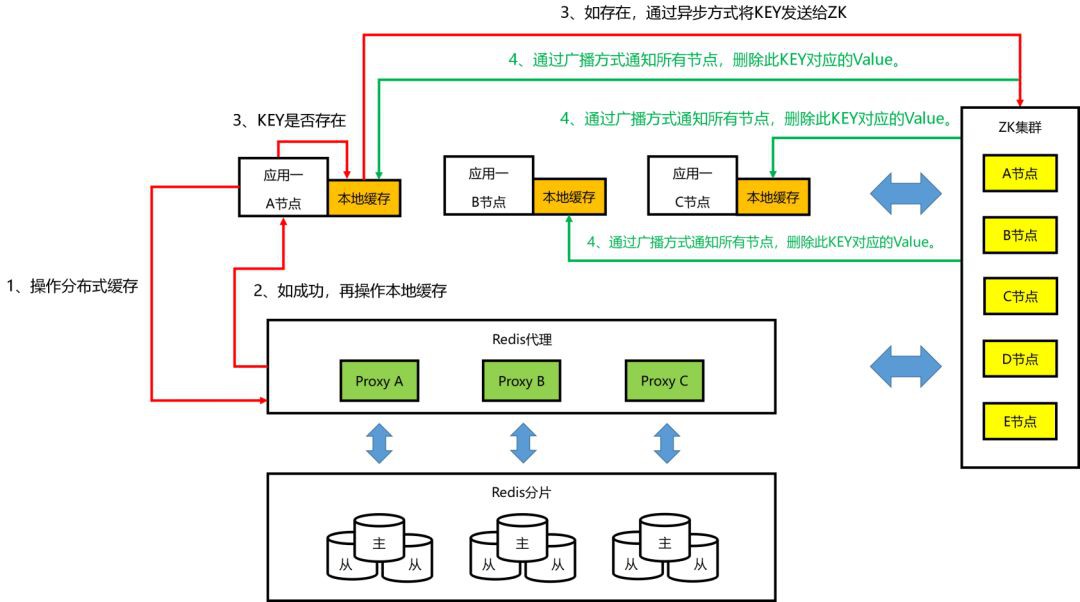
③本地快取的工作機制:Set/Delete 操作
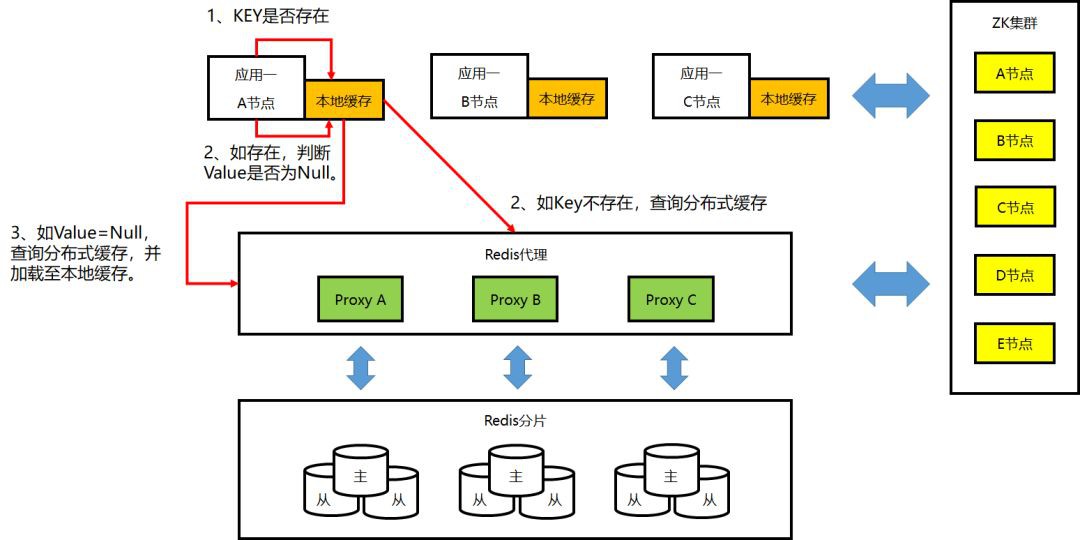
④本地快取的工作機制:Get 操作
順帶提一句,由於歷史性與資源緊缺的原因,我們部分快取系統與應用系統的 ZK 叢集是混用的,正因如此,給本次事故埋下了隱患。
ZK 叢集是怎樣被搞掛的呢?
說到這裡,相信對中介軟體有一定瞭解的人基本能猜出本事件的全貌。
簡單來說,就是在上線初期,由於流量小,應用系統接入量小,我們本地快取的訊息通知是利用 ZK 來實現的,而且還用到了廣播。
但隨著流量的增加與應用系統接入量的增多,訊息傳送量成倍增長,最終達到承載能力的上限,ZK 叢集崩潰。的確,原因基本猜對了,但訊息傳送量為什麼會成倍的增長呢?
根據本地快取的工作機制,我們一般會在裡面存些什麼呢?
-
更新頻率較低,但訪問卻很頻繁,比如系統引數或業務引數。
-
單個 Key/Value 較大,網路消耗比較大,效能下降明顯。
-
服務端資源匱乏或不穩定(如 I/O),但對穩定性要求極高。
懵圈了,就放些引數類資訊,而且更新頻率極低,這樣就把五個節點的 ZK 叢集打爆了?
為了找到真相,我們立即進行了程式碼走讀,最終發現了蹊蹺。
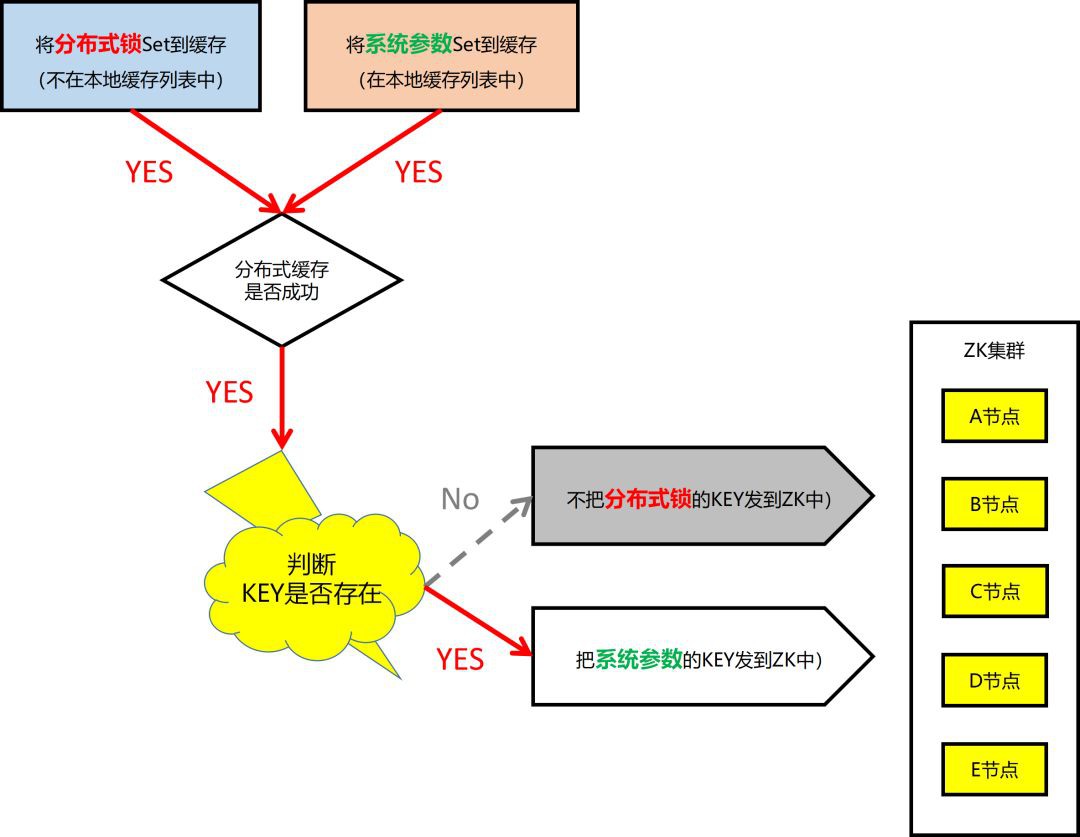
根據設計,在 “本地快取的工作機制 – Set/Delete 操作” 的工作機制中,當一個 Key 完成服務端快取操作後,如果沒有被加到本地快取規則串列中的 Key,是不可能被觸發訊息通知的。
但這裡明視訊記憶體在 Bug,導致把所有的 Key 都發到了 ZK 中。
這樣就很好理解了,雖然應用系統近期沒有釋出版本,但卻透過快取控制檯,悄悄地把分散式鎖加到了這套快取分片中,所以交易一開盤,只需幾十分鐘,立馬打爆。
另外,除了發現 Bug 之外,透過事後測試驗證,我們還得出了以下幾點結論:
-
利用 ZK 進行訊息同步,ZK 本身的負載能力較弱,是否切換到 MQ?
-
監控手段的單一,監控的薄弱。
-
系統部署結構不合理,基礎架構的 ZK 不應該與應用的 ZK 混用。

說到這裡,這個故事也該結束了。
講在最後
看完這個故事,一些愛好懟人的小夥伴也許會忍不住發問。你們自己設計的架構,你們自己編寫的程式碼,難道不知道其中的邏輯嗎?這麼低階的錯誤,居然還有臉拿出來說?
那可未必,對每個技術團隊而言,核心成員的離職與業務形態的變化,都或多或少會引發技術團隊對現有系統形成 “知其然,而不知其所以然” 的情況,雖說每個團隊都在想方設法進行避免,但想完全杜絕,絕非易事。
作為技術管理者,具備良好的心態,把每次故障都看成是一次蟬變的過程,從中得到總結與經驗,並加以傳承,今後不再犯,那就是好樣的。
不過,萬一哪天失手,給系統來了個徹底癱瘓,該怎麼辦呢?祝大家一切順利吧。
轉載自:吃草的羅漢

已傳送
朋友將在看一看看到
分享你的想法…
分享想法到看一看