作者丨王喆
單位丨Hulu高階機器學習工程師
研究方向丨計算廣告、推薦系統
知乎專欄丨王喆的機器學習筆記
今天我們聊一聊 KDD 2018 的 Best Paper,Airbnb 的一篇極具工程實踐價值的文章 Real-time Personalization using Embeddings for Search Ranking at Airbnb。

相信大家已經比較熟悉我選擇計算廣告和推薦系統相關文章的標準:
-
工程導向的;
-
阿裡、Facebook、Google 等一線網際網路公司出品的;
-
前沿或者經典的。
Airbnb 這篇文章無疑又是一篇兼具實用性和創新性的工程導向的 paper。文章的作者 Mihajlo 發表這篇文章之前在 Recsys 2017 上做過一個 talk,其中涉及了文章中的大部分內容,我也將結合那次 talk 的 slides [1] 來講解這個論文。
廢話不多說,我們進入文章的內容。
Airbnb 作為全世界最大的短租網站,提供了一個連線房主(host)掛出的短租房(listing)和主要是以旅遊為目的的租客(guest/user)的中介平臺。這樣一個中介平臺的互動方式比較簡單,guest 輸入地點,價位,關鍵詞等等,Airbnb 會給出 listing 的搜尋推薦串列:
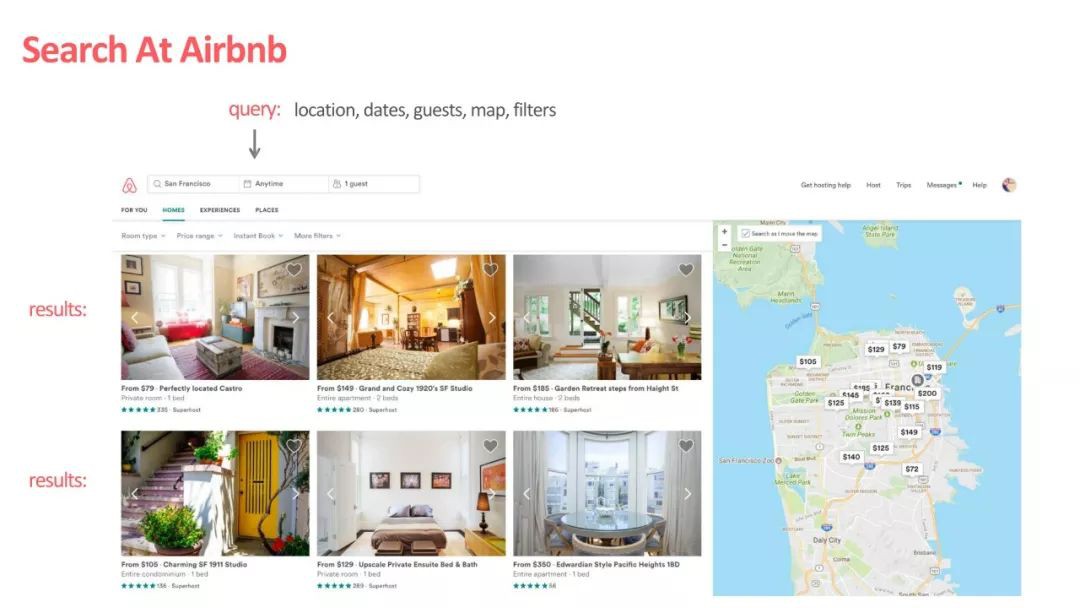
▲ Airbnb的業務場景
容易想見,接下來 guest 和 host 之間的互動方式無非有這樣幾種:
-
guest點選listing(click)
-
guest預定lising(book)
-
host有可能拒絕guest的預定請求(reject)
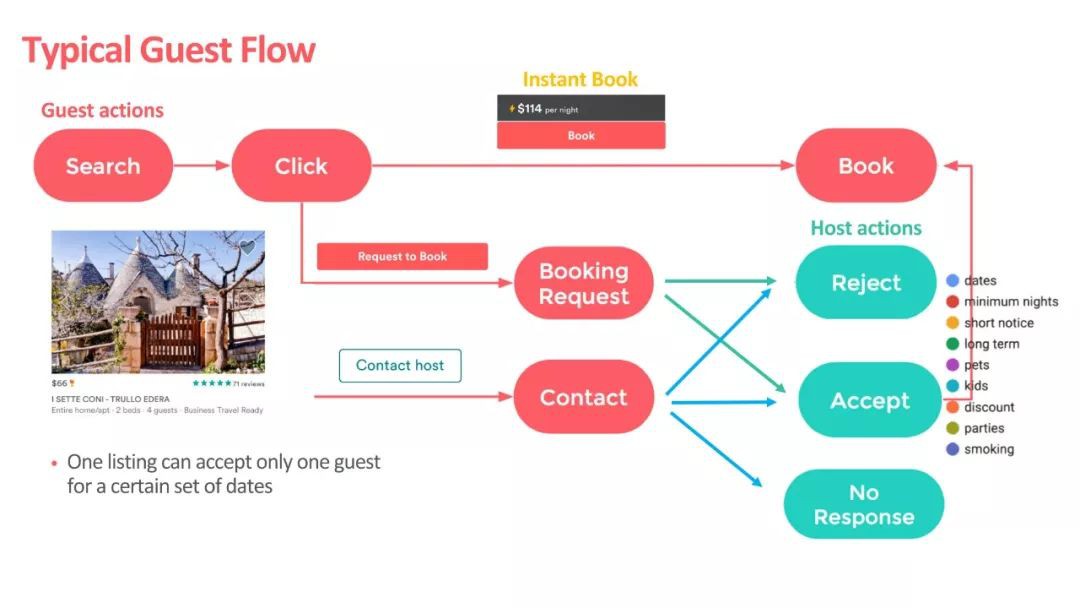
▲ Airbnb的互動方式
基於這樣的場景,利用幾種互動方式產生的資料,Airbnb 的 search 團隊要構建一個 real time 的 ranking model。
為了捕捉到使用者 short term 以及 long term 的興趣,Airbnb 並沒有把 user history 的 clicked listing ids 或者 booked listing ids 直接輸入 ranking model,而是先對 user 和 listing 進行了embedding,進而利用 embedding 的結果構建出諸多 feature,作為 ranking model 的輸入。這篇文章的核心內容就是介紹如何生成 listing 和 user 的embedding。
具體到 embedding 上,文章透過兩種方式生成了兩種不同的 embedding 分別 capture 使用者的 short term 和 long term 的興趣。
一是透過 click session 資料生成 listing 的 embedding,生成這個 embedding 是為了進行 listing 的相似推薦,以及對使用者進行 session 內的實時個性化推薦。
二是透過 booking session 生成 user-type 和 listing-type 的 embedding,目的是捕捉不同 user-type 的 long term 喜好。由於 booking signal 過於稀疏,Airbnb 對同屬性的 user 和 listing 進行了聚合,形成了 user-type 和 listing-type 這兩個 embedding 的物件。
我們先討論第一個對 listing 進行 embedding 的方法:
Airbnb 採用了 click session 資料對 listing 進行 embedding,其中 click session 指的是一個使用者在一次搜尋過程中,點選的 listing 的序列,這個序列需要滿足兩個條件,一個是隻有停留時間超過 30s 的 listing page 才被算作序列中的一個資料點,二是如果使用者超過 30 分鐘沒有動作,那麼這個序列會斷掉,不再是一個序列。

▲ Click Session的定義和條件
這麼做的目的無可厚非,一是清洗噪聲點和負反饋訊號,二是避免非相關序列的產生。
有了由 clicked listings 組成的 sequence,就像我們在之前專欄文章中講過的 item2vec 方法一樣,我們可以把這個 sequence 當作一個“句子”樣本,開始 embedding 的過程。
Airbnb不出意外地選擇了 word2vec 的 skip-gram model 作為 embedding 方法的框架。透過修改 word2vec 的 objective 使其靠近 Airbnb 的業務標的。
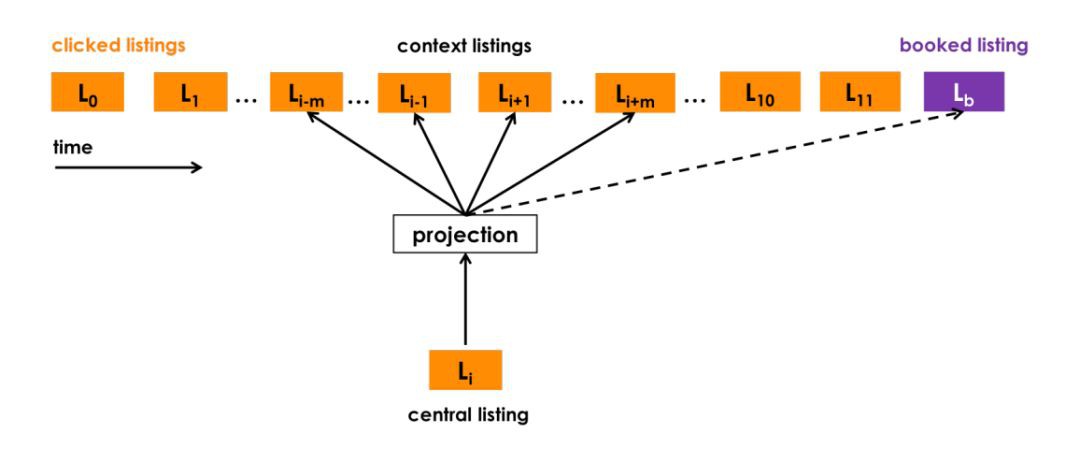
▲ Airbnb的類word2vec embedding方法
我們在之前的專欄文章《萬物皆embedding》[2] 中詳細介紹了 word2vec 的方法,不清楚的同學還是強烈建議先去弄明白 word2vec 的基本原理,特別是 objective 的形式再繼續下麵的閱讀。
我們假設大家已經具備了基本知識,這裡直接列出 word2vec 的 skip-gram model 的 objective 如下:
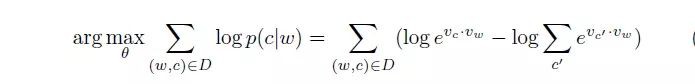
在採用 negative sampling 的訓練方式之後,objective 轉換成瞭如下形式:
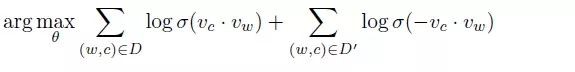
其中 σ 函式代表的就是我們經常見到的 sigmoid 函式,D 是正樣本集合,D’ 是負樣本集合。我們再詳細看一下上面 word2vec 這個 objective function,其中前面的部分是正樣本的形式,後面的部分是負樣本的形式(僅僅多了一個負號)。
為什麼原始的 objective 可以轉換成上面的形式,其實並不是顯然的,感興趣的同學可以參考這篇文章,Negative-Sampling Word-Embedding Method [3]。這裡,我們就以 word2vec 的 objective function 為起點,開始下麵的內容。
轉移到 Airbnb 這個問題上,正樣本很自然的取自 click session sliding window 裡的兩個 listing,負樣本則是在確定 central listing 後隨機從語料庫(這裡就是 listing 的集合)中選取一個 listing 作為負樣本。
因此,Airbnb 初始的 objective function 幾乎與 word2vec 的 objective 一模一樣,形式如下:
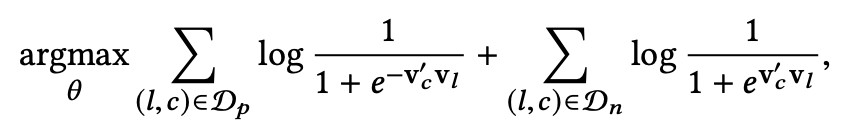
給大家出個腦筋急轉彎:為啥 Airbnb objective 的正樣本項前面是負號,原始的 word2vec objective 反而是負樣本項前面是負號,是 Airbnb 搞錯了嗎?
在原始 word2vec embedding 的基礎上,針對其業務特點,Airbnb 的工程師希望能夠把 booking 的資訊引入 embedding。這樣直觀上可以使 Airbnb 的搜尋串列和 similar item 串列中更傾向於推薦之前 booking 成功 session 中的listing。
從這個 motivation 出發,Airbnb 把 click session 分成兩類,最終產生 booking 行為的叫 booked session,沒有的稱做 exploratory session。
因為每個 booked session 只有最後一個 listing 是 booked listing,所以為了把這個 booking 行為引入 objective,不管這個 booked listing 在不在 word2vec 的滑動視窗中,我們都會假設這個 booked listing 與滑動視窗的中心 listing 相關,也就相當於引入了一個 global context 到 objective 中,因此,objective 變成了下麵的樣子:
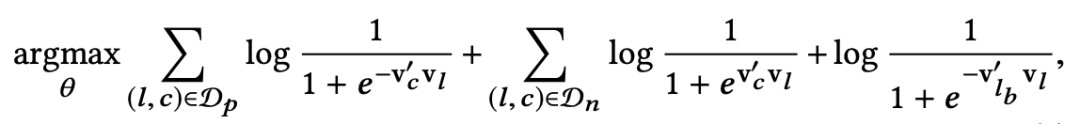
其中最後一項的 lb 就是代表著 booked listing,因為 booking 是一個正樣本行為,這一項前也是有負號的。
需要註意的是最後一項前是沒有 sigma 符號的,前面的 sigma 符號是因為滑動視窗中的中心 listing 與所有滑動視窗中的其他 listing 都相關,最後一項沒有 sigma 符號直觀理解是因為 booked listing 只有一個,所以 central listing 只與這一個 listing 有關。
但這裡 objective 的形式我仍然是有疑問的,因為這個 objective 寫成這種形式應該僅代表了一個滑動視窗中的 objective,並不是整體求解的 objective。如果是整體的 objective,理應是下麵的形式:
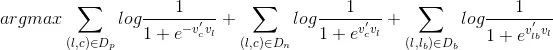
其中 Db 代表了所有 booked session 中所有滑動視窗中 central listing 和 booked listing 的 pair 集合。
不知道大家有沒有疑問,我們可以在這塊多進行討論。
下麵這一項就比較容易理解了,為了更好的發現同一市場(marketplace)內部 listing 的差異性,Airbnb 加入了另一組 negative sample,就是在 central listing 同一市場的 listing 集合中進行隨機抽樣,獲得一組新的 negative samples。
同理,我們可以用跟之前 negative sample 同樣的形式加入到 objective 中。
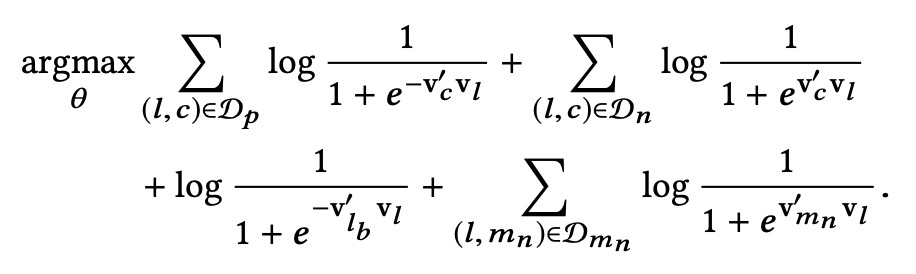
其中 Dmn 就是新的同一地區的 negative samples 的集合。
至此,lisitng embedding 的 objective 就定義完成了,embedding 的訓練過程就是 word2vec negative sampling 模型的標準訓練過程,這裡不再詳述。
除此之外,文章多介紹了一下 cold start 的問題。簡言之,如果有 new listing 缺失 embedding vector,就找附近的 3 個同樣型別、相似價格的 listing embedding 進行平均得到,不失為一個實用的工程經驗。
為了對 embedding 的效果進行檢驗,Airbnb 還實現了一個 tool,我們簡單貼一個相似 embedding listing 的結果。
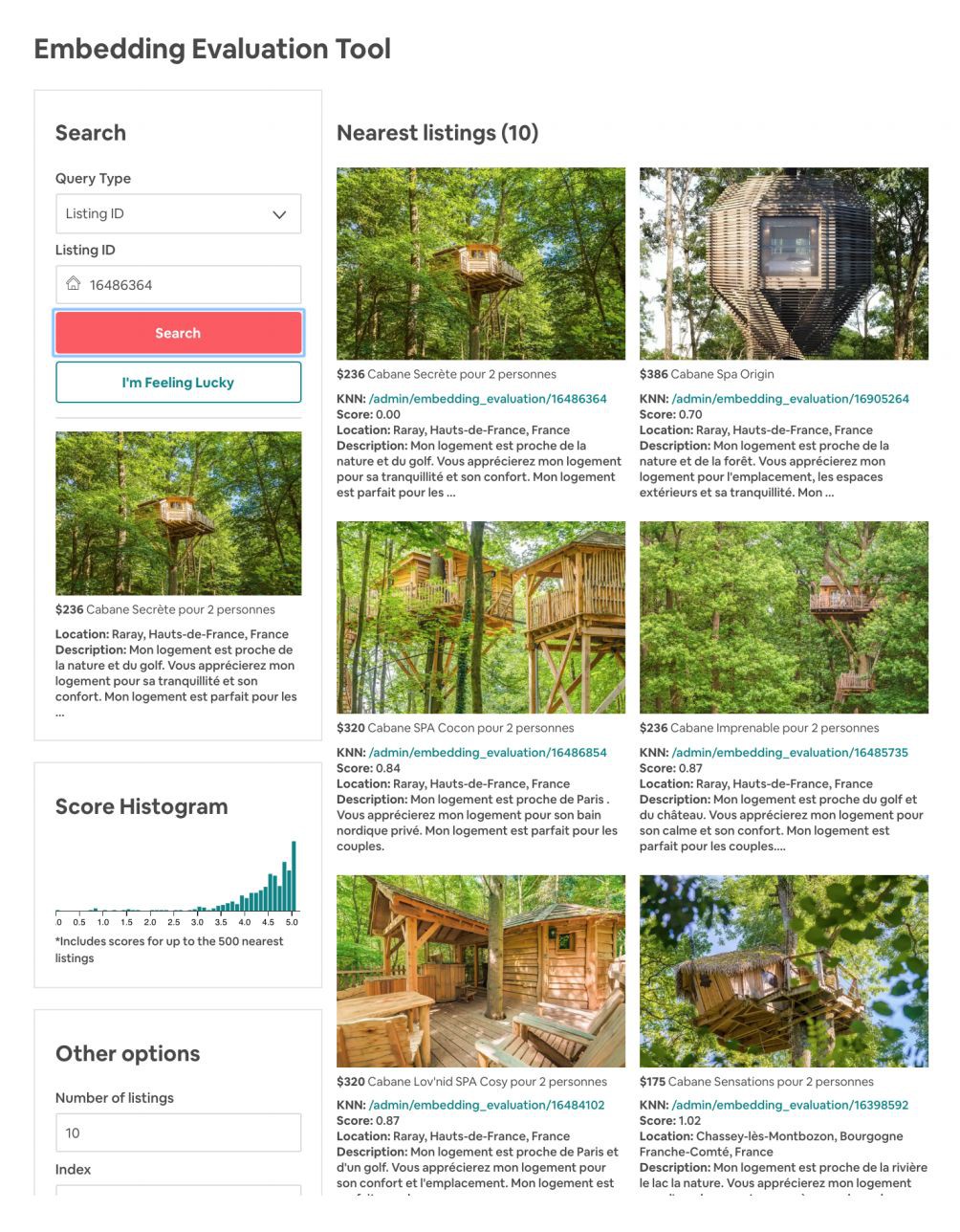
▲ Airbnb Similar Listing
從中可以看到,embedding 不僅 encode 了 price,listing-type 等資訊,甚至連 listing 的風格資訊都能抓住,說明即使我們不利用圖片資訊,也能從使用者的 click session 中挖掘出相似風格的 listing。
至此我們介紹完了 Airbnb 利用 click session 資訊對 listing 進行 embedding 的方法。寫到這裡筆者基本要斷氣了,下一篇我們再接著介紹利用 booking session 進行 user-type 和 listing-type embedding 的方法,以及 Airbnb 如何把這些 embedding feature 整合到最終的 search ranking model 中的方法。
最後給大家三個問題以供討論:
1. 為什麼 Airbnb objective 中正負樣本的正負號正好跟 word2vec objective 的正負號相反?
2. Airbnb 加入 booked listing 作為 global context,為什麼在 objective 中不加 sigma 加和符號?
3. 這裡我們其實只得到了 listing 的 embedding,如果是你,你會怎樣在 real time search ranking 過程中使用得到的 listing embedding?
參考資料
[1] https://astro.temple.edu/~tua95067/Mihajlo_RecSys2017.pptx
[2] https://zhuanlan.zhihu.com/p/53194407
[3] https://arxiv.org/pdf/1402.3722.pdf
[4] https://github.com/wzhe06/Reco-papers