人臉編輯可以在大多數影象編輯軟體上得到實現,但是這都需要專業知識,例如瞭解在特定情況下使用哪些特定工具,以便按照想要的方式有效地修改影象,同時操作影象編輯軟體也是耗時的。 基於深度學習下影象編輯得到越來越多的重視和應用,在 GAN 的推動下,影象風格轉換、影象修複、影象翻譯等等在近幾年有了長足的發展。這篇文章將介紹基於 GAN 損失的端到端可訓練生成網路,在人臉修複上取得了很棒的結果,同時該模型也適用於有趣的人臉編輯。
作者丨武廣
學校丨合肥工業大學碩士生
研究方向丨影象生成


論文引入
提到影象編輯,一定要說的就是 Photoshop 這款軟體,近乎可以處理日常所有的照片,但是 PS 不是這麼容易操作的,精通 PS 更是需要專業知識了。如何讓小白完成在影象上勾勾畫畫就能實現影象的編輯?這個任務當然可以交給深度學習來實現了。
生成對抗網路(GAN)的發展,促進了影象生成下一系列研究的發展。影象編輯下影象修複是一個難點,這對於影象編輯軟體來說也是很困難的。近幾年在深度學習發展下,影象修複在不斷進步,最典型的方法是使用普通(方形)掩模,然後用編碼器-解碼器恢復掩蔽區域,再使用全域性和區域性判別器來估計結果的真假。
然而,該系統限於低解析度影象,並且所生成的影象在掩蔽區域的邊緣不能很好的與原圖銜接。儘管 Deepfillv2 [1]、GuidedInpating [2]、Ideepcolor [3]、FaceShop [4] 在不斷改進實現結果,但是對於深度學習處理影象修複上的難點還是依舊存在,總的來說主要的挑戰有兩個:1)影象在恢復的部分上具有不和諧的邊緣;2)如果影象太多區域被改寫,修複的影象將會不合理。
本文要解讀的論文為瞭解決上述限制,提出了 SC-FEGAN,它具有完全摺積網路,可以進行端到端的訓練。提出的網路使用 SN-patchGAN [1] 判別器來解決和改善不和諧的邊緣。該系統不僅具有一般的 GAN 損失,而且還具有風格損失,即使在大面積缺失的情況下也可以編輯面部影象的各個部分。
這篇論文釋出在 arXiv 不到10天,其原始碼便已標星破千。文章的人臉編輯效果十分逼真,先一睹為快。
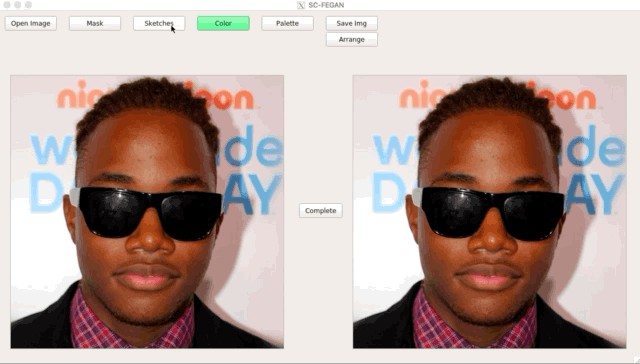
總結一下 SC-FEGAN 的貢獻:
1. 使用類似於 U-Net [5] 的網路體系結構,以及 gated convolutional layers [1]。對於訓練和測試階段,這種架構更容易,更快捷,與粗糙網路相比,它產生了優越而細緻的結果。
2. 建立瞭解碼圖,顏色圖和草圖的自由格式域資料,該資料可以處理不完整影象資料輸入而不是刻板形式輸入。
3. 應用了 SN-patchGAN 判別器,並對模型進行了額外的風格損失。該模型適應於擦除大部分的情況,並且在管理掩模邊緣時表現出穩健性。它還允許生成影象的細節,例如高質量的合成髮型和耳環。
訓練資料處理
決定模型訓練好壞的一個重要因素就是訓練資料的處理,SC-FEGAN 採用 CelebA-HQ [6] 資料集,並將圖片統一處理為 512 x 512 大小。
為了突顯面部影象中眼睛的複雜性,文章使用基於眼睛位置掩模來訓練網路。這主要用在掩碼的提取上,當對面部影象進行訓練時,隨機應用一個以眼睛位置為起點的 free-form mask,以表達眼睛的複雜部分。此外,文章還使用 GFC 隨機添加了人臉頭髮的輪廓。演演算法如下:

文章的又一個創新是在提取影象的草圖和顏色圖,使用 HED 邊緣檢測器 [7] 生成與使用者輸入相對應的草圖資料,之後,平滑曲線並擦除了小邊緣。建立顏色域資料,首先透過應用大小為 3 的中值濾波,然後應用雙邊濾波器來建立模糊影象。之後,使用 GFC [8] 對面部進行分割,並將每個分割的部分替換為相應部分的中間顏色。最後還提取噪聲表示。最終處理完得到的資料可由下圖展示,上面一行作為真實標準,下麵一行為處理得到的輸入資料。

模型結構
SC-FEGAN 採用的網路設計結構與 U-Net 類似,上取樣的思路是 U-Net 的那一套,透過 Concat 連線下取樣的特徵提取完成上取樣,整體框架如下所示:

網路的整體很好理解,圖示也很清晰,我們強調一下網路的輸入。
不像傳統的影象到影象的模型輸入是 512 x 512 x 3 的 RGB 輸入,這篇論文的輸入是尺寸為 512 × 512 × 9 的張量,這個張量是由 5 張圖片圖片構成的。
首先是被改寫殘缺的 RGB 影象,也就是我們在圖片上勾勾畫畫的影象,其尺寸為 512 x 512 x 3;其次是提取得到的草圖 512 x 512 x 1;影象的顏色域 RGB 圖 512 x 512 x 3;掩碼圖 512 x 512 x 1;最後就是噪聲對應的 512 x 512 x 1。按照通道連線的話得到最終的模型輸入 512 x 512 x 9。
摺積層採用的是 gated convolution,使用 3 x 3 核心,下取樣採取 2 個步幅核心摺積對輸入進行 7 次下取樣,上取樣透過 U-Net 思路進行解碼得到編輯好的影象。解碼得到的影象依舊是 5 張圖片,包括修複的 RGB 影象、草圖、顏色圖、掩碼圖、噪聲圖。透過判別器和真實的 5 張圖片進行 SN-patchGAN 結構設計進行真假判斷,最佳化模型。
在整個網路的摺積層後應用區域性訊號歸一化(LRN),生成器採用 Leaky Relu,判別器透過 SN 限制,並且施加梯度懲罰。SC-FEGAN 的損失函式由 5 部分組成,畫素損失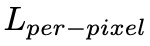 、感知損失、感知損失
、感知損失、感知損失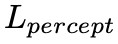 、風格損失、風格損失
、風格損失、風格損失![]() 、總方差損失、總方差損失
、總方差損失、總方差損失![]() 以及 GAN 的對抗損失。
以及 GAN 的對抗損失。
先來看一下 GAN 的對抗損失,文章採用的 WGAN 的損失設計:
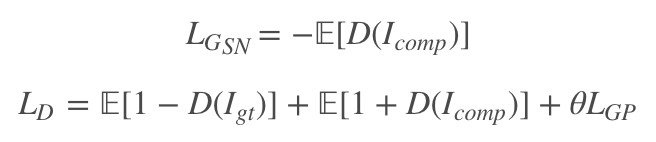
其中![]() 是生成器輸出的
是生成器輸出的![]() 的完成影象(包括草圖和顏色圖以後的),也就是送入判別器判別的輸入,最後判別器加上梯度懲罰項。
的完成影象(包括草圖和顏色圖以後的),也就是送入判別器判別的輸入,最後判別器加上梯度懲罰項。
對於生成器希望判別器判錯,故生成器損失最小值為 -1,判別器則希望真實判為真,生成判為假,上述損失還是很好理解的。生成器完整的損失為:
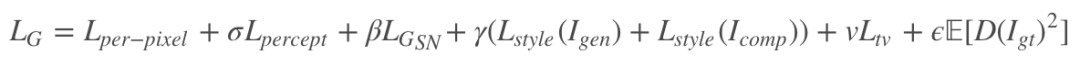
畫素損失保證影象編輯生成與真實的一致性:

其中 Na 是特徵 a 的數字元素,M 是二元掩模圖,用於控制修複影象的畫素,達到生成與真實的一致性。公式後一項給予擦除部分損失更多的權重。對於大區域下的擦除影象的修複時,風格損失和感知損失是必要的。感知損失在 GAN 中的應用已經很多了,就是對中間層進行特徵差異損失,這裡不做贅述。
風格損失使用 Gram 矩陣比較兩個影象的內容,風格損失表示為:

其中, ,Θ 為網路的中間層,Gq(x) 是用於在中間的每個特徵圖上執行自相關的 Gram 矩陣,Gram 矩陣的形狀是 Cq×Cq。總方差損失,反應的是相鄰畫素間是相似的,記為
,Θ 為網路的中間層,Gq(x) 是用於在中間的每個特徵圖上執行自相關的 Gram 矩陣,Gram 矩陣的形狀是 Cq×Cq。總方差損失,反應的是相鄰畫素間是相似的,記為 。其中:
。其中:

對於列 row 也是一樣,自此整體的損失函式構建完成,在實際實驗中引數設定為 σ=0.05,β=0.001,γ=120,v=0.1,ϵ=0.001,θ=10。
實驗
實驗首先對比了使用 U-Net 框架設計的優勢,對比的框架是 Coarse-Refined。論文測試了 Coarse-Refined 結構網路,並註意在一些需要精確輸出的卻是模糊的。

FaceShop 已經顯示出難以修改像整個頭髮區域那樣的巨大擦除影象。由於感知和風格損失的加入,SC-FEGAN 在這方面表現更好。下圖顯示了有和沒有 VGG 損失(感知和風格損失)的結果。

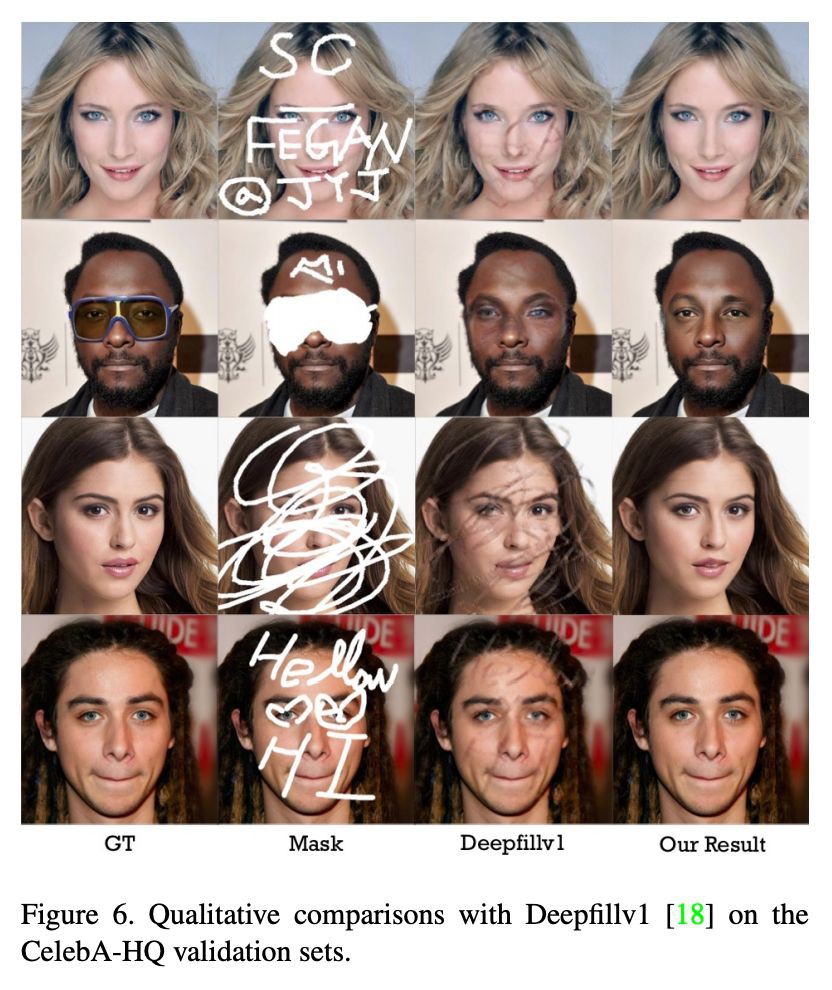
實驗還與最近的研究 Deepfillv1 進行了比較,下圖顯示模型在使用自由形狀的掩模在結構和形狀的質量方面產生更好的結果。意味著沒有附加資訊,如草圖和顏色,面部元素的形狀和位置具有一定的依賴值。因此,只需提供附加資訊即可在所需方向上恢復影象。
此外,即使輸入影象被完全擦除,我們的 SC-FEGAN 也可以生成僅具有草圖和顏色自由形式輸入的人臉影象(感興趣的可以參看論文中更多結果)。
下圖顯示了草圖和顏色輸入的各種結果,它表明模型允許使用者直觀地編輯臉部影象功能,如髮型,臉型,眼睛,嘴巴等。即使整個頭髮區域被刪除,它也能夠產生適當的結果。

文章還做了給人物加上耳環的有趣實驗,這種人臉編輯確實蠻有意思:

實驗
SC-FEGAN 提出了一種新穎的影象編輯系統,用於自由形式的蒙版,草圖,顏色輸入,它基於具有新穎 GAN 損失的端到端可訓練生成網路。與其他研究相比,網路架構和損失功能顯著改善了修複效果。
論文基於 celebA-HQ 資料集進行了高解析度影象的訓練,併在許多情況下顯示了各種成功和逼真的編輯結果。實驗證明瞭系統能夠一次性修改和恢復大區域,並且只需要使用者細緻的勾畫就可以產生高質量和逼真的結果。
模型的框架採用 U-Net 思想,在 Decoder 端結合 Encoder 端特徵實現上取樣過程下精確影象的生成。引入感知損失和風格損失更是幫助模型實現了大區域擦除的修複。
在判別器採用 SN-patchGAN 思想,使得恢復的影象在邊緣上更加和諧,生成器和判別器都結合了影象的草圖、顏色圖和掩模圖進行判斷,使得修複的影象更加逼真,同時也是論文的一個創新。實驗上的炫彩也是使得原始碼得到了廣泛的關註。
參考文獻
[1] J. Yu, Z. Lin, J. Yang, X. Shen, X. Lu, and T. S. Huang.Free-form image inpainting with gated convolution. arXiv preprint arXiv:1806.03589, 2018. 2, 3, 4, 6, 7
[2] Y. Zhao, B. Price, S. Cohen, and D. Gurari. Guided image inpainting: Replacing an image region by pulling content from another image. arXiv preprint arXiv:1803.08435, 2018. 2
[3] R. Zhang, J.-Y. Zhu, P. Isola, X. Geng, A. S. Lin, T. Yu, and A. A. Efros. Real-time user-guided image colorization with learned deep priors. arXiv preprint arXiv:1705.02999, 2017.2, 3
[4] T. Portenier, Q. Hu, A. Szabo, S. Bigdeli, P. Favaro, and M. Zwicker. Faceshop: Deep sketch-based face image editing. arXiv preprint arXiv:1804.08972, 2018. 2, 3, 4, 6, 7
[5] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical image computing andcomputer-assisted intervention, pages 234–241. Springer,2015. 2, 3, 4
[6] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196, 2017. 3, 4
[7] S. ”Xie and Z. Tu. Holistically-nested edge detection. In Proceedings of IEEE International Conference on Computer Vision, 2015. 3
[8] Y. Li, S. Liu, J. Yang, and M.-H. Yang. Generative face completion. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), volume 1, page 3, 2017. 1,3, 4

點選以下標題檢視更多往期內容:
讓你的論文被更多人看到 如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。 總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。 PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。 ? 來稿標準: • 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向) • 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結 • PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌 ? 投稿郵箱: • 投稿郵箱:hr@paperweekly.site • 所有文章配圖,請單獨在附件中傳送 • 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通  #投 稿 通 道#
#投 稿 通 道#
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

