本文講述調整sql邏輯達到最佳化目的案例
一前言
前面一篇文章說過在有贊的資料庫運維體系裡面,每個實體會部署相應的sql-killer工具,實時處理耗時比較長的查詢。 業務方報執行某個功能時,系統報錯Query execution was interrupted,顯然sql被kill了。和開發溝通業務邏輯如下:
系統會獲取滿足參加特定活動且滿足一定次數的商家,然後做其他相關操作。
二 分析
前文<業務最佳化案例一則>分析過sql變慢的原因大概有如下幾種:
-
sql 陳述句本身索引不合理,導致執行緩慢。
-
使用合理的索引但是獲取的資料量非常多,依然會慢查。
-
網路丟包重傳導致sql變慢,被kill。
-
併發比較高的場景,請求排隊處理,等待時間長。
進過排查排除3,4兩個因素。我們檢視sql
SELECT count(*) = 7 has_match,t_id
FROM xxx
where status = 1
and task_id in (301, 302, 305, 306, 307, 308, 309) and t_id > 2019
group by t_id order by t_id desc limit 10000
該sql的功能是獲取t_id大於某些值的所有記錄並且做聚合,然後把參加過task_id且次數等於7的t_id取出來。拿到sql,然後去查看錶結構只有task_id 一個索引。和明顯慢查的一個原因是沒有合理的索引。
三 最佳化
首先根據sql的where條件我們可以針對該sql加上索引
KEY `idx_taskid_st_tid` (`task_id`,`status`,`t_id`)
其次 原sql是將所有的記錄取出來,透過count(*) = 7 運算式判斷是否為1,再拿到程式中處理has_match為1的t_id。針對此我們可以利用 having 函式計算滿足條件的記錄。最佳化後的結果如下:
SELECT t_id,count(*) as num
FROM xxx
where status = 1
AND task_id IN (301,302,305,306,307,308,309)
group by t_id having num=7;
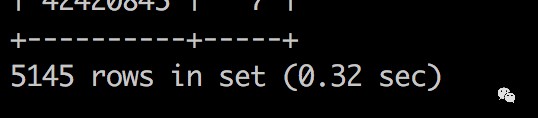
最佳化之前

最佳化之後
四 總結
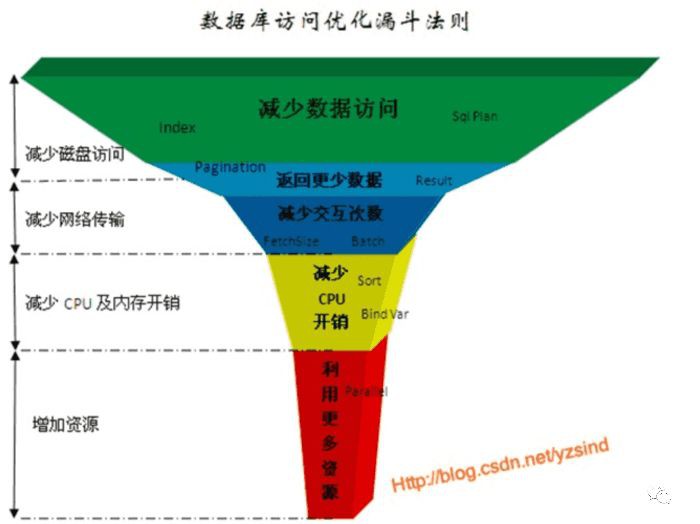
這個案例相對比較簡單,拓展一下資料庫最佳化的核心思想: 三減少,一增加

已傳送
朋友將在看一看看到
分享你的想法…
分享想法到看一看