兩階段提交協議(2PC)已經在企業軟體系統中使用了三十多年。它是一種非常有影響力的協議,用於確保訪問多個分割槽或分片中的資料的事務的原子性和永續性。它無處不在 – 無論是在舊的“古老的”分散式系統、資料庫系統和檔案系統,如Oracle,IBM DB2,PostgreSQL 和 Microsoft TxF(支援事務的 NTFS)還是在較年輕的“千禧”系統如 MariaDB、TokuDB、VoltDB、Cloud Spanner、Apache Flink、Apache Kafka 和 Azure SQL 資料庫。如果您的系統支援跨分片/分割槽/資料庫的 ACID 事務,那麼它很可能會在後臺執行 2PC(或其某些變體)。有時它甚至出現在“前臺” – 舊版本的 MongoDB 要求使用者在應用程式程式碼中為多檔案事務實現 2PC。
在這篇文章中,我們將首先介紹一下 2PC:它是如何工作的以及它解決了什麼問題。然後,我們將展示 2PC 的一些主要問題以及現代系統如何試圖解決它。不幸的是,這些嘗試的解決方案也帶來了一些其他問題。在文章最後,我將說明下一代分散式系統應該避免使用 2PC,以及如何實現這一點。
2PC 協議概述
2PC 有很多變種,但基本協議的工作原理如下:
背景假設:一個事務相關的工作已經劃分給儲存該事務資料的分片節點。我們將在每個分片中執行的工作,稱為節點“參與者”的工作。當事務準備好“提交”時,每個參與者都能夠獨立於彼此完成事務相應的職責。2PC 協議由單個獨立的、可協調的節點發起(可能是參與者之一)。
2PC 協議的基本流程如下圖所示。(協議從圖的頂部開始,然後向下進行。)
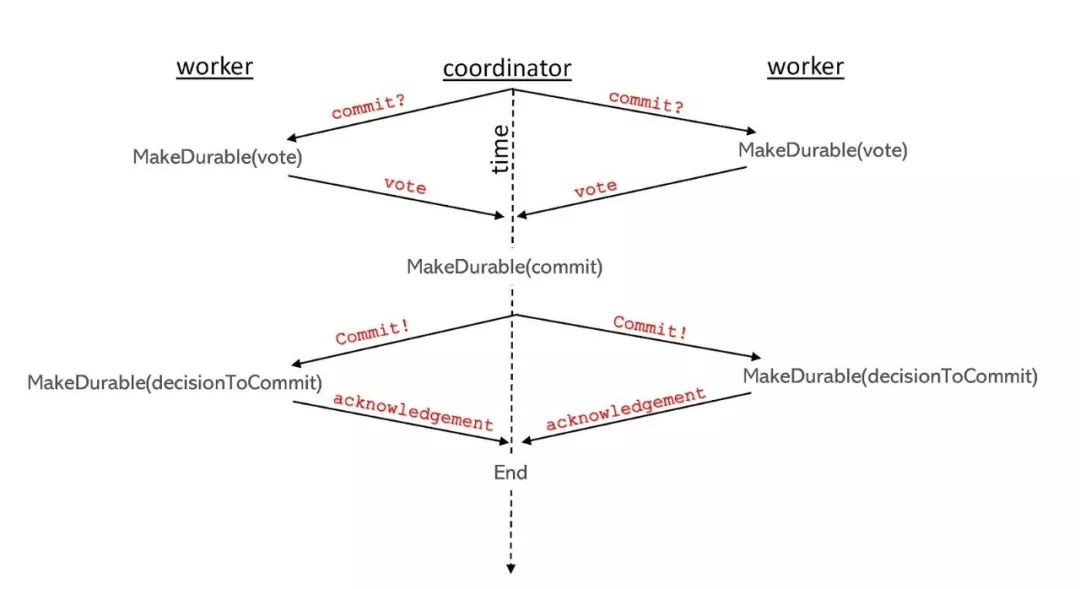
階段1:協調者詢問每個參與者,是否已成功完成其對該事務的職責,並達到可以提交的狀態。每個參與者都回答“同意”或“反對”。
階段2:協調者統計所有回應,如果每個參與者都回答“同意”,那麼就提交事務,否則就中止事務。協調者向每個具有提交最終決策權力的參與者傳送訊息,並接收參與者的確認訊息。
此機制確保事務的原子性屬性:整個事務將反映在系統的最終狀態中,或者不反映在系統的最終狀態中。即使只有一個參與者沒有提交,那麼整個事務將會被中止。換句話說:每個參與者對事務都有“否決權”。
它還確保了事務的永續性。每個參與者確保在階段1響應“同意”之前,已將所有事務持久地寫入儲存。這使協調者對事務做出最終決定時,無需擔心參與者在投票“同意”之後寫入失敗。在這篇文章中,當使用術語“持久寫入”時,我們有目的地模糊化了兩個區別 – 本地臨時性儲存,或是分散式的寫入到多個分片以“持久化”。
除了持久地寫入事務相關的資料之外,協議本身還需要額外的寫入,在處理訊息之前必須使其持久化。例如,一名參與者在第一階段投票“同意”之前擁有否決權,但在此之後,它不能改變其投票結果。但如果它在投票“同意”後立即崩潰怎麼辦? 當它恢復時,它可能不知道它投了“同意”,仍然認為它擁有否決權,並繼續流程並中止事務。為了防止這種情況,它必須在“同意”投票發給協調者之前,持久化相關投票結果。(除了這個例子,在標準的 2PC 流程中,還有另外兩種訊息需要傳送前持久化操作。)
2PC 的問題
2PC 存在兩個主要問題。第一個是眾所周知的,併在所有講述 2PC 的教科書中都進行了討論。第二個不太知名,但仍然是一個大的問題。
眾所周知的問題被稱為“阻塞(block)問題”。當每個參與者都投了“同意”,但協調者在將最終決定的訊息未能傳送給至少一參與者之前就掛了,就會出現這種情況。問題的原因是,透過投票“同意”,每個參與者已經取消了否決事務的權力。但是,協調者仍有絕對權力來決定事務的最終狀態。如果協調者在向至少一名參與者傳送最終決定的訊息之前掛了,那麼參與者就無法做出最終決定 – 他們不能中止,因為協調者可能會在掛掉之前決定提交,並且他們無法提交,因為協調者可能決定在失敗之前中止。因此,他們必須等待—等到協調者恢復—以便得到最終決定。與此同時,他們無法處理與停滯衝突的事務,因為該事務的寫入的最終結果尚未確定。
阻塞問題有兩種解決方案。方案一是修改核心協議以消除阻塞問題。不幸的是,這些修改降低了效能 – 通常透過新增額外的一輪通訊來實現 – 因此很少在實踐中使用。
方案二是保持協議不變,但降低協調者失敗從而引發阻塞的可能性 – 例如,透過在副本共識協議上執行 2PC 並確保協議的重要狀態被覆制。不幸的是,這些解決方案再一次降低了效能,因為協議要求這些副本共識輪次按順序進行,因此它們可能會給協議增加顯著的延遲。
鮮為人知的問題是我稱之為“擁堵(cloggage)問題”。在處理事務之後進行 2PC,必然增加事務的等待時間,它等於執行協議所花費的時間。延遲的增加對於許多系統來說已經是一個問題,但更大的問題是,工作節點必須到第二階段中期才知道事務的最終結果。在他們得到最終結果之前,他們必須為可能中止事務的可能性做好準備,因此在事務得到確認之前,他們通常會暫停其他有衝突的事務進行。這些阻塞的事務同樣會進一步阻止其他事務執行,依此類推,直到 2PC 完成,所有被阻止的事務才可以恢復。這些擁堵問題進一步增加了事務平均延遲,並且降低了整體的事務吞吐量。
總結我們上面討論的問題:2PC 在四個方面汙染了系統架構:
- 延遲 (協議的時間加上衝突事務的停頓時間)
- 吞吐量(因為它碰到衝突的事務會停頓)
- 可擴充套件性 (系統越大,事務更需要多分割槽的支援,並且必須付出 2PC 的吞吐量和延遲成本以及
- 可用性(前面提到的阻塞問題)。
沒有人喜歡 2PC,但幾十年來,人們都認為它是一種必要的妥協。
是時候改變了
三十多年來,業界一直在分散式系統中使用兩階段提交。我們已經意識到引入 2PC 會帶來效能、可伸縮性和可用性問題,但在沒有更好的替代方案之前,仍需要選擇使用它。
真相就是,如果有更好的方案,2PC 就沒必要存在了。為了實現這一標的,無論是在學術界(如SIGMOD 2016論文)和工業界都在進行嘗試。通常的做法是避免分散式事務,例如透過在提交事務之前將資料重新分片,使得事務不再是分散式事務。不幸的是,這種重新分片的做法降低了系統的效能。
我倡導對分散式系統架構進行更深層次的最佳化。我堅持認為系統可以使用更簡單和高效的提交協議,在保證 ACID 的同時,能夠處理分散式事務。
一切問題的根源來自一個存在數十年的假設:事務可能隨時以任何理由中止。即使我在相同的初始系統狀態下執行相同的事務,在下午 2:00 它可能可以成功提交,但在 3:00 時卻會提交失敗。
為什麼需要該假設?大多數架構師認為有以下幾個原因。首先,節點可能在任何時候失敗,包括在事務處理過程中。系統故障恢復過程中,由於無法獲取故障前的記憶體狀態,因此也無法恢復事務失敗之前的現場。因此係統需要中止故障出現時所有相關事務。由於任何時候都可能發生故障,這意味著事務可能隨時中止。
其次,大多數併發控制協議都需要能夠隨時中止事務。樂觀協議在處理事務後執行“驗證”,如果驗證失敗,則中止事務。悲觀協議通常使用鎖來防止併發異常,這種鎖的使用可能會導致死鎖,然後又需要透過中止(至少)事務的方法來解決死鎖問題。由於可能隨時出現死鎖,因此事務需要保留隨時中止的能力。
如果來重新審視兩階段提交協議,您將看到隨時中止事務的可能性,是 2PC 協議中複雜和延遲的主要原因。參與者不能輕易地告訴其他方是否同意提交,因為他可能在此之後(在事務提交前)出現故障,然後在故障恢復期間中止此事務。因此,他們必須等到事務結束(當所有重要狀態都已經持久化)並且嚴格按照兩個階段進行處理:在第一階段,每個參與者公開放棄其控制以中止事務,然後才能進入第二階段,作出最終決定併進行廣播。
在我看來,我們需要從參與者中移除否決權,並且以系統無法在執行期間隨時中止事務的假設來進行架構設計。只接受以業務邏輯需要來否決事務的情況。如果在給定資料庫當前狀態下,理論上可以提交事務情況下,無論發生何種型別的故障,該事務都必須可以提交。此外也不接受由於其他併發執行導致的競爭條件而不能最終提交或中止事務。
消除隨意中止事務的靈活性聽起來很難。我們將很快討論如何實現這一標的。但首先讓我們觀察在不能隨意中止事務的情況下,提交協議會如何變化。
當事務不能隨意中止時,提交協議是什麼樣的
我們來看兩個例子:
在第一個例子中,假設儲存變數 X 的節點需要執行一個任務:將 X 的值更改為 42。假設在 X 上沒有定義完整性約束或觸發器(這可能會阻止系統將 X 設為 42)。在這種情況下,該參與方永遠沒有中止事務的權力。無論發生什麼,該參與方必須將 X 更改為42,如果修改過程中出現系統故障,則必須在故障恢復後將 X 設成 42。由於參與方沒有隨意中止事務的能力,因此在提交協議期間,不需要檢測參與方是否可以提交。
在第二個例子中,假設儲存變數 Y 和 Z 值的節點接收到兩個事務任務:從前一個 Y 值中減去 1 並將 Z 設定為 Y 的新值。此外,假設 Y 上存在完整性約束,表明 Y 永遠不會低於 0(例如它代表零售應用程式中的庫存)。因此,此參與方必須執行以下程式碼:
IF (Y > 0)
Subtract 1 from Y
ELSE
ABORT the transaction
Z = Y
因為應用程式的邏輯需要這樣做,所以必須賦予參與者中止事務的權力。但是這種權力是受限的。只有當 Y 的初始值為 0 時,才能中止該事務,否則必須提交。因此,參與方不必等到完成事務之後才知道它是否需要提交。相反:一旦它完成了事務中第一行程式碼的執行,它就已經知道了最終需要提交還是中止。這意味著相比於 2PC 而言,提交協議將能夠更早地啟動。
現在讓我們將這兩個例子組合成一個例子,其中一個事務由兩個參與者執行 – 其中一個參與者正在完成第一個例子中描述的工作,另一個參與者正在完成第二個例子中描述的工作。由於我們保證原子性,第一個參與者不能簡單地將 X 設定為 42,相反,它自己的工作依賴於 Y 的值。實際上,第一個參與者的事務程式碼變為:
temp = Do_Remote_Read(Y)
if (temp > 0)
X = 42
請註意,如果第一個參與者的程式碼如上的話,那麼另一個參與者的程式碼可以簡化為:
IF (Y > 0)
Subtract 1 from Y
Z = Y
透過以這種方式編寫事務程式碼,兩個參與方都刪除了顯式中止邏輯。相反,兩個參與方都有 if 陳述句來檢查是否會導致原始事務中止的約束。如果原始事務中止,兩個參與方最終都無所作為。否則,兩個參與方都會根據事務邏輯更改其本地狀態。
此時需要註意的一點是,在上面的程式碼中完全消除了對提交協議的需求。除了應用程式程式碼在給定資料狀態下定義的條件邏輯以外的任何原因,系統都不允許中止事務。並且所有參與者都在這個相同的條件上調整他們的動作,這樣他們就可以獨立地決定,在由於當前系統狀態而無法完成事務的情況下“什麼也不做”。因此,已經消除了事務中止的所有可能性,並且在事務處理結束時不需要任何型別的分散式協議來做出關於事務組合的最終決定。2PC 的所有問題都已消除。因為沒有協調者,所以也沒有阻塞(block)問題。因為所有必要的檢查都與事務處理時候完成,而非在事務完成之後檢查,所以沒有擁堵(cloggage)問題。
此外,只要不允許系統因應用程式邏輯之外的任何原因而中止事務,總是可以像上面那樣重寫任何事務以替換程式碼中的中止邏輯,即 if 陳述句有條件地檢查中止條件。此外,可以在重寫應用程式程式碼的情況下實現此目的。(有關如何執行此操作的詳細資訊超出了本文的範圍,但可以高屋建瓴地總結為:當一個節點執行了導致中止的條件邏輯時,它可以設定特殊的標記,其他節點可以在遠端讀取這些標記。)
實質上:在事務處理系統中有兩種型別中止:(1)由資料狀態引起的中止和(2)由系統本身引起的中止(例如故障或死鎖)。如上所述,類別(1)總是可以根據資料的條件邏輯來編寫。因此,如果您可以消除類別(2)中止,則可以消除提交協議。
所以現在,我們所要做的就是解釋如何消除類別(2)中止。
消除系統本身中止
我花了將近十年的時間來設計沒有系統引發中止的系統。此類系統的示例是 Calvin,CalvinFS,Orthrus,PVW 以及惰性處理事務系統。這一特性的推動力來自於— Calvin —因為它是一個確定性資料庫系統。確定性資料庫保證在給定一組定義的輸入請求的情況下,資料庫中只有一個可能的最終資料狀態。因此,如果將相同的輸入傳送到系統的兩份不同的副本,兩份副本將獨立地處理該輸入,並將最終達到一致的結果。
系統本身中止,例如系統故障或併發控制競態條件,從根本上說是不確定性事件。一個副本很可能碰見系統呼叫失敗或進入競態條件,而另一個副本則不會。如果允許這些非確定性事件導致事務中止,則一個副本會中止事務而另一個副本將提交事務 – 這是對確定性的違背。因此,我們必須以系統故障和競態條件不能導致事務中止的方式設計 Calvin。對於併發控制,Calvin 使用了避免死鎖技術的悲觀鎖定,該技術確保系統永遠不會陷入由於死鎖導致的事務中止的狀況。面對系統故障,Calvin 無法從中斷的位置重啟事務(因為在故障期間失去了記憶體狀態)。儘管如此,透過從相同的原始輸入重新啟動事務,它依然能夠完成該事務的處理而不必中止它。
這些解決方案(包括防止死鎖以及故障重啟恢復事務),都不侷限於在確定性資料庫系統中使用。在非確定性系統中,如果失敗期間,丟失的事務狀態被其他非故障節點偵測到,那麼事務重啟變得略微棘手。但是也有一些簡單的方法來解決這個問題,但這些方法已經超出了本文討論的範圍。實際上,我上面提到的其他系統都是非確定性系統。一旦我們意識到消除系統本身故障所帶來的威力,我們就將設計植入到 Calvin 之後構建的每個系統中 – 甚至是非確定性系統。
結論
系統架構師繼續在分散式系統中使用 2PC 的好處微乎其微。我認為,忽略系統本身中止以及狀態寫入故障是更好的前進方法。確定性資料庫系統(如 Calvin 或 FaunaDB)總是會規避系統本身中止,因此通常可避免 2PC。但是這種優勢僅發揮在確定性資料庫是一個巨大的浪費。從非確定性系統中消除系統本身引起的中止並不困難。最近的專案表明,甚至可以在不使用悲觀併發控制技術的系統中消除系統引起的中止。例如,我們上面連結的 PVW 和惰性事務處理系統都使用多版本併發控制(MVCC)的變體。FaunaDB 使用樂觀併發控制的變體。
在我看來,幾乎沒有理由堅持過時的系統性中止假設,當系統在單臺機器上執行時,這種假設是合理的。然而,很多現代系統已經擴充套件到到多臺可以故障隔離的機器上。維持該假設就需要成本高昂類似 2PC 的協調和提交協議。2PC 的效能問題一直是非 ACID 系統興起的主要推動力,這些系統放棄了強一致性保證,以達到更好的可擴充套件性、可用性和效能。2PC 太慢了!它增加了所有事務的延遲,不僅僅是協議本身的時間佔用,還阻止了訪問相同資料的其他事務的併發執行。此外,2PC 還限制了可伸縮性(透過降低併發性)和可用性(我們上面討論的阻塞問題)。前進的道路已經很明確:我們需要在設計系統時重新審視過時的假設,並對兩階段提交說“再見”!
英文版地址:
http://dbmsmusings.blogspot.com/2019/01/its-time-to-move-on-from-two-phase.html
最新譯文地址:
https://timyang.net/distributed/time-to-move-on-from-two-phase/
由於對分散式理論理解有限,部分翻譯未必貼切,最新譯文以上述部落格地址為準。
本文作者 DANIEL ABADI ,由 Tim 翻譯,方圓對本文翻譯亦有貢獻。轉載本文請註明出處,GIAC全球網際網路架構大會深圳站將於2019年6月舉行,屆時將有分散式專題深入探討相關話題,敬請期待。


已傳送
朋友將在看一看看到
分享你的想法…
分享想法到看一看