
作者丨蘇劍林
單位丨廣州火焰資訊科技有限公司
研究方向丨NLP,神經網路
個人主頁丨kexue.fm
在前一文從無監督構建詞庫看「最小熵原理」,套路是如何煉成的中,我們以最小熵原理為出發點進行了一系列的數學推導,最終得到 (2.15) 和 (2.17) 式,它告訴我們兩個互資訊比較大的元素我們應該將它們合併起來,這有利於降低“學習難度”。於是利用這一原理,我們透過鄰字互資訊來實現了詞庫的無監督生成。
由字到詞、由詞到片語,考察的是相鄰的元素能不能合併成一個好“套路”。可是套路為什麼非得要相鄰的呢?
當然不一定相鄰,我們學習語言的時候,不僅僅會學習到詞語、片語,還要學習到“固定搭配”,也就是說詞語怎麼運用才是合理的,這是語法的體現,是本文所要探究的,希望最終能達到一定的無監督句法分析的效果。
由於這次我們考慮的是跨鄰詞的語言關聯,因此我給它起個名字為“飛象過河”,正是:“套路寶典”第二式——“飛象過河”。
語言結構
對於大多數人來說,並不會真正知道什麼是語法,他們腦海裡就只有一些“固定搭配”、“定式”,或者更正式一點可以叫“模版”。大多數情況下,我們是根據模版來說出合理的話來。而不同的人的說話模版可能有所不同,這就是個人的說話風格,甚至是“口頭禪”。
句模版
比如,“X 的 Y 是什麼”就是一個簡單的模版,它有一些明確的詞語“的”、“是”、“什麼”,還有一些佔位符 X、Y,隨便將 X 和 Y 用兩個名詞代進去,得到的就是合乎語法的句子(合不合事實,那是另外一回事了)。這類模版還可以舉出很多,“X和Y”、“X的Y”、“X可以Y嗎”、“X有哪些Y”、“X是Y還是Z”等等。
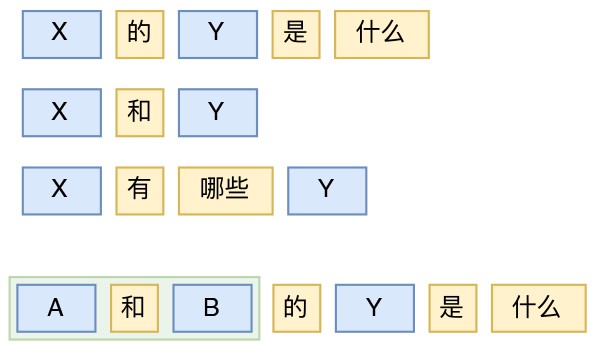
▲ 句模版及其相互巢狀示例
當然,雖然可以抽取盡可能多的模版,但有限的模版是無法改寫千變萬化的語言想象的,所以更重要的是基於模版的巢狀使用。比如“X 的 Y 是什麼”這個模版,X 可以用模版“A 和 B”來代替,從而得到“(A 和 B)的 Y 是什麼”。如此以來,模版相互巢狀,就可以得到相當多句子了。
等價類
接著,有了模版“X 的 Y 是什麼?”之後,我們怎麼知道 X 和 Y 分別可以填些什麼呢?
剛才我們說“隨便用兩個名詞”代進去,可是按照我們的思路,到現在為止我們也就只會構建詞庫,我們連什麼是“名詞”都不知道,更不知道應該把名詞填進去。事實上,我們不需要預先知道什麼,我們可以透過大料的語料來抽取每個候選位置的“等價類”,其中 X 的候選片語成一個詞語等價類,Y 的候選詞也組成一個詞語等價類,等等。

▲ 句模版及等價類的概念
當然,這樣的設想是比較理想的,事實上目前我們能獲取的生語料情況糟糕得多,但不管怎樣,萬丈高樓平地起,我們先解決理想情況,實際使用時再去考慮一般情況。
下麵我們來逐一探究如何從大量的原始語料獲取句模版,並考慮如何識別句子中所用到的句模版,甚至挖掘出句子的層次結構。
生成模版
事實上,有了前一文的構建詞庫的經驗,事實上就不難構思生成句子模版的演演算法了。
在構建詞庫那裡,我們的統計物件是字,現在我們的統計物件是詞,此外,詞語是由相鄰的字組成的,但句子模版卻未必是由相鄰的片語成的(否則就退化為詞或片語),所以我們還要考慮跨詞共現,也就是 Word2Vec 中的 Skip Gram 模型。
有向無環圖
有向無環圖(Directed Acyclic Graph,DAG)其實是 NLP 中經常會遇到的一個圖論模型。事實上,一元分詞模型也可以直接抽象為有向無環圖上的最短路徑規劃問題。而這裡的候選模版集構建,也需要用到有向無環圖。
因為考慮了 Skip Gram 模型,因此我們可以把句子內比較“緊湊”(互資訊比較大)的“詞對”連線起來,用圖論的角度看,這就構成了一個“有向無環圖”:

我們直接將圖上的所有路徑都取出來,如果跨過了相鄰節點,那麼就插入一個佔位符(下麵全部用 X 表示佔位符),這樣就可以得到候選模版集了。比如從上圖中,抽取到的候選模版為:

演演算法步驟
我們可以把上述流程具體描述如下:
1. 將語料按句子切分,並分詞;
2. 選定一個視窗大小 window,從語料中統計每個詞的頻率 (pa,pb),以及在視窗大小內中任意兩詞的共現頻率 (pab);
3. 分別設定出現頻率的閾值 min_prob 和互資訊的閾值 min_pmi;
4. 遍歷所有句子:
4.1. 對每個句子構建一個圖,句子中的詞當作圖上的點;
4.2. 句子中視窗內的詞對 (a,b),如果滿足 pab>min_prob和![]() >mi_pmi,那麼就給圖上新增一條“a–>b”的有向邊;
>mi_pmi,那麼就給圖上新增一條“a–>b”的有向邊;
4.3. 找出圖上所有的路徑(孤立點也算路徑),作為候選模版加入統計;
5. 統計各個“準模版”的頻率,將“準模版”按頻率降序排列,取前面部分即可。
這個演演算法既可以用來句模版的抽取,也可以簡單地用來做片語(短語)的抽取,只需要將 window 設為 1。因此它也就基本上包含了前一文所說的詞庫構建了,所以上述演演算法是一個一般化的抽取框架。
效果演示
下麵是從百度知道的問題集中抽取出來的一些句模版(數字是統計出來的頻數,可以忽略):

註意,事實上“X 的 X”、“X 怎麼 X”這種兩個佔位符夾住一個詞的模版是平凡的,它只不過是告訴我們這個詞可以插入到句子中使用。因此,為了看出效果,我們排除掉這一類模版,得到:

從結果來看,我們的句模版生成算是確實是有效的。因為這些句模版就有助於我們發現語言的使用規律了。比如:
1. “X 嗎”、“X 了”、“X 怎麼樣”這些模版的佔位符出現在前面,說明這些詞可以放在問句的末尾(我們用到的語料是問句);
2. “我 X”、“求 X”、“為什麼 X”、“請問 X”等模版的佔位符出現在後面,說明這些詞可以放到問句的開頭;
3. “謝謝”、“怎麼辦”這類模版並沒有出現佔位符,表明它可以單獨成句;
4. “X 是 X 意思”、“X 有哪些 X”等模版則反映了語言的一些固定搭配。
用通用的觀點看,這些模版所描述的都是句法級的語言現象。當然,為了不至於跟目前主流的句法分析混淆,我們不妨就稱為語言結構規律,或者直接就稱為“句模版”。
結構解析
跟分詞一樣,當構建好句子模版後,我們也需要有演演算法來識別句子中用到了哪些模版,也只有做到了這一步,才有可能從語料中識別出詞語的等價類出來。
回顧分詞演演算法,分詞只是一個句子的切分問題,切分出來的詞是沒有“洞”(佔位符)的,而如果要識別句子中用了哪些模版,這些模版是有“洞”的,並且還可能相互巢狀,這就造成了識別上的困難。然而,一旦我們能夠完成這個事情,我們就得到了句子的一個層次結構分解,這是非常有吸引力的標的。
投射性假設
為了實現對句子的層次分解,我們首先可以借鑒的是句法分析一般都會使用的“投射性(projective)假設”。
語言的投射性大概意思是指如果句子可以分為幾個“語意塊”,那麼這些語意塊是不交叉的。也就是說,假如第 1、2、3 個片語成一個語意塊、第 4、5 個片語成一個語意塊,這種情況是允許的,而第 1、2、4 個片語成一個語意塊、第 3、5 個片語成一個語意塊,這種情況是不可能的。大多數語言,包括漢語和英語,基本上都滿足投射性。
結構假設
為了完成句子的層次結構分解,我們需要對句子的組成結構做更完整的假設。受到投射性假設的啟發,筆者認為可以將句子的結構做如下假設:
1. 每個語意塊是句子的一個連續子字串,句子本身也算是一個語意塊;
2. 每個語意塊由一個主的句模版生成,其中句模版的佔位符部分也是一個語意塊;
3. 每個單獨的詞可以看成是一個平凡的句模版,也可以看成是一個最小粒度的語意塊。
說白了,這三點假設可以歸納為一句話:每個句子是由句模版相互巢狀生成的。
咋看之下這個假設不夠合理,但仔細思考就會發現,這個假設已經足夠描述大多數句子的結構了。讀者可能有疑慮的是“有沒有可能並行地使用兩個句模版,而不是巢狀”?答案是:應該不會。
因為如果出現這種情況,只需要將“並行”本身視為一個模版就行了,比如將“X 和 X”也視為一個模版,那麼“X 和 X”這個模版中的兩個語意塊就是並行的了,甚至它可以與自身巢狀得到“X 和(X 和 X)”描述更多的並行現象。
也正因為我們對語言結構做了這種假設,所以一旦我們識別出某個句子的最優句模版組合,我們就得到了句子的層次結構——因為根據假設,模版是按照巢狀的方式組合的,巢狀意味著遞迴,遞迴就是一種層次樹的結構了。
分解演演算法
有了對句子結構的假設,我們就可以描述句模版識別演演算法了。首先來重述一下分詞演演算法,一元分詞演演算法的思路為:對句子切分成詞,使得這些詞的機率對數之和最大(資訊量之和最小)。
它還可以換一種表述:找一系列的詞來不重不漏地改寫句子中的每個字,使得這些詞的機率對數之和最大(資訊量之和最小)。
以往我們會認為分詞是對句子進行切分,這種等價的表述則是反過來,要對句子進行改寫。有了這個逆向思維,就可以提出模版識別演演算法了:
找一系列的句模版來不重、不漏、不交叉地改寫句子中的每個詞,使得這些模版的機率對數之和最大(資訊量之和最小)。
當然,這隻是思路,在實現過程中,主要難點是對佔位符的處理,也就是說,句子中的每個詞既代表這個詞本身,也可以代表佔位符,這種二重性使得掃描和識別都有困難。
而不幸中的萬幸是,如果按照上面所假設的語言結構,我們可以轉化為一個遞迴運算:最優的結構分解方案中,主模版下的每個語意塊的分解方案也是最優的。

▲ 句子的層次結構解析,包含了句模版的巢狀呼叫
因此我們可以得到演演算法:
1. 掃描中句子中所有可能出現的模版(透過 Trie 樹結構可以快速掃描);
2. 每種分解方案的得分,等於句子的主模版得分,加上每個語料塊的最優分解方案的得分。
結果展示
下麵是一些簡單例子的演示,是透過有限的幾個模版進行的分析,可以看到,的確初步實現了句子的層次結構解析。
+---> (雞蛋)可以(吃)嗎
| +---> 雞蛋
| | +---> 雞蛋
| +---> 可以
| +---> 吃
| | +---> 吃
| +---> 嗎
+---> (牛肉雞蛋)可以(吃)嗎
| +---> 牛肉雞蛋
| | +---> 牛肉
| | +---> 雞蛋
| +---> 可以
| +---> 吃
| | +---> 吃
| +---> 嗎
+---> (蘋果)的(顏色)是(什麼)呢
| +---> 蘋果
| | +---> 蘋果
| +---> 的
| +---> 顏色
| | +---> 顏色
| +---> 是
| +---> 什麼
| | +---> 什麼
| +---> 呢
+---> (雪梨和蘋果和香蕉)的(顏色)是(什麼)呢
| +---> (雪梨和蘋果)和(香蕉)
| | +---> (雪梨)和(蘋果)
| | | +---> 雪梨
| | | | +---> 雪梨
| | | +---> 和
| | | +---> 蘋果
| | | | +---> 蘋果
| | +---> 和
| | +---> 香蕉
| | | +---> 香蕉
| +---> 的
| +---> 顏色
| | +---> 顏色
| +---> 是
| +---> 什麼
| | +---> 什麼
| +---> 呢
當然,不能報喜不報憂,也有一些失敗的例子:
+---> (我的美味)的(蘋果的顏色)是(什麼)呢
| +---> (我)的(美味)
| | +---> 我
| | | +---> 我
| | +---> 的
| | +---> 美味
| | | +---> 美味
| +---> 的
| +---> (蘋果)的(顏色)
| | +---> 蘋果
| | | +---> 蘋果
| | +---> 的
| | +---> 顏色
| | | +---> 顏色
| +---> 是
| +---> 什麼
| | +---> 什麼
| +---> 呢
+---> (蘋果)的(顏色)是(什麼的意思是什麼)呢
| +---> 蘋果
| | +---> 蘋果
| +---> 的
| +---> 顏色
| | +---> 顏色
| +---> 是
| +---> (什麼)的(意思)是(什麼)
| | +---> 什麼
| | | +---> 什麼
| | +---> 的
| | +---> 意思
| | | +---> 意思
| | +---> 是
| | +---> 什麼
| | | +---> 什麼
| +---> 呢
失敗的例子我們後面再分析。
文章總結
看到一臉懵逼的,有各種話要吐槽的,還請先看到這一節。
拼圖遊戲
從詞、片語都句模版,我們都像是在玩拼圖:拼著拼著發現這兩塊合在一起效果還行,那麼就將它合起來吧。因為將互資訊大的項合起來,作為一個整體來看,就有助於降低整體的資訊熵,也就能降低整體的學習難度。
對於句模版,如果在中文的世界裡想不通,那麼就回顧一下我們在小學、初中時學英語是怎麼學過來的吧,那會我們應該學習了很多英語的句模版。
有什麼用
“句模版”算是本文提出的新概念,用它來識別語言結果也算是一種新的嘗試。讀者不禁要問:這玩意有什麼用?
我想,回答這個問題的最好方式,是取用牛頓的一段話:
我自己認為,我好像只是一個在海邊玩耍的孩子,不時為撿到比通常更光滑的石子或更美麗的貝殼而歡欣,而展現在我面前的是完全未被探明的真理之海。
我取用這段話是想表明,做這個探究的最根本原因,並不是出於某種實用目的,而是為了純粹地探究自然語言的奧秘。
當然,如果與此同時,研究出來的結果能具備一定的應用價值,那就更加完美了。從現在的結果來看,這種應用價值可能是存在的。
因為我們在 NLP 中,面對的句子千變萬化,但事實上“句式”卻是有限的,這也意味著句模版也是有限的,如果有必要,我們可以對各個句模板的佔位符含義進行人工標註,這就能將句模板的結構跟常規的句法描述對應起來了。透過有限的句模版來對句子進行(無限的)分解,能讓 NLP 可面對的場景更加靈活多變一些。
也許以往的傳統自然語言處理中,也出現過類似的東西,但本文所描述的內容純粹是無監督的結果,並且也有自洽的理論描述,算是一個比較完整的框架,初步的結果也差強人意,因此值得進一步去思考它的應用價值。
艱難前進
瀏覽完這篇文章,讀者最大的感覺也許是“一臉懵逼”:能再簡化一點嗎?
要回答這個問題,就不得不提到:距離這個系列的上一篇文章已經過了一個多月,這篇文章才正式發出,這似乎有點久了?從形式上看,本文只不過是前文的簡單推廣:不就是將相鄰關聯推廣到非相鄰關聯嗎?
的確,形式上確實如此。但為了將這個想法推廣至同時具備理論和實用價值,卻並不是那麼簡單和順暢的事情。比如,在句模版生成時,如何不遺漏地得到所有的候選模版,這便是一個難題;其次,在得到句模版(不管是自動生成還是人工錄入)後,如何識別出句子中的句模版,這更加艱難了,不論在理論思考還是程式設計實現上,都具有相當多的障礙,需要對樹結構、遞迴程式設計有清晰的把握。我也是陸陸續續除錯了半個多月,才算是把整個流程調通了,但估計還不完備。
所以,你看得一臉懵逼是再正常不過了,我自己做完、寫完這篇文章,還感覺很懵呢。
改進思路
在結果結果展示一節中,我們也呈現一些失敗的例子。事實上,失敗的例子可能還更多。
我們要從兩個角度看待這個事情。一方面,我們有成功的例子,對應純粹無監督挖掘的探索,我們哪怕只能得到一小部分成功的結果,也是值得高興的;另外一方面,對於失敗的例子,我們需要思考失敗的原因,並且考慮解決方案。
筆者認為,整體的句模版思路是沒有問題的,而問題在於我們沒有達到真正的語意級別的理解。比如第一個失敗的例子,結果是:(我的美味)的(蘋果的顏色)是(什麼)呢。
我們能說這個分解完全錯嗎?顯然不是,嚴格來講,這種分解在語法上並沒有任何錯誤,只是它不符合語意,不符合我們的常識。因此,並非是句模版的錯,而是還不能充分地結合語意來構建句模版。
回顧目前主流的句法分析工作,不管是有監督的還是無監督的,它們基本上都要結合“詞性”來完成句法分析。所以這給我們提供了一個方向:最小熵系列下一步的工作就是要探究詞語的聚類問題,以便更好地捕捉詞義和語言共性。
基於最小熵原理的NLP庫:NLP Zero
陸陸續續寫了幾篇最小熵原理的文章,致力於無監督做 NLP 的一些基礎工作。為了方便大家實驗,把文章中涉及到的一些演演算法封裝為一個庫,供有需要的讀者測試使用。
由於面向的是無監督 NLP 場景,而且基本都是 NLP 任務的基礎工作,因此命名為NLP Zero。
地址
Github: https://github.com/bojone/nlp-zero
Pypi: https://pypi.org/project/nlp-zero/
可以直接透過:
pip install nlp-zero==0.1.6
進行安裝。整個庫純 Python 實現,沒有第三方呼叫,支援 Python 2.x 和 3.x。
使用
預設分詞
庫內帶了一個詞典,可以作為一個簡單的分詞工具用。
from nlp_zero import *
t = Tokenizer()
t.tokenize(u'掃描二維碼,關註公眾號')自帶的詞典加入了一些透過新詞發現挖掘出來的新詞,並且經過筆者的人工最佳化,質量相對來說還是比較高的。
詞庫構建
透過大量的原始語料來構建詞庫。
首先我們需要寫一個迭代容器,這樣就不用一次性把所有語料載入到記憶體中了。迭代器的寫法很靈活,比如我的資料存在 MongoDB 中,那就是:
import pymongo
db = pymongo.MongoClient().weixin.text_articles
class D:
def __iter__(self):
for i in db.find().limit(10000):
yield i['text']如果資料存在文字檔案中,大概就是:
class D:
def __iter__(self):
with open('text.txt') as f:
for l in f:
yield l.strip() # python2.x還需要轉編碼然後就可以執行了。
from nlp_zero import *
import logging
logging.basicConfig(level = logging.INFO, format = '%(asctime)s - %(name)s - %(message)s')
f = Word_Finder(min_proba=1e-8)
f.train(D()) # 統計互資訊
f.find(D()) # 構建詞庫透過 Pandas 檢視結果:
import pandas as pd
words = pd.Series(f.words).sort_values(ascending=False)直接用統計出來的詞庫建立一個分詞工具:
t = f.export_tokenizer()
t.tokenize(u'今天天氣不錯')句模版構建
跟前面一樣,同樣要寫一個迭代器,這裡不再重覆。 因為構建句模版是基於詞來統計的,因此還需要一個分詞函式,可以用自帶的分詞器,也可以用外部的,比如結巴分詞。
from nlp_zero import *
import logging
logging.basicConfig(level = logging.INFO, format = '%(asctime)s - %(name)s - %(message)s')
tokenize = Tokenizer().tokenize # 使用自帶的分詞工具
# 透過 tokenize = jieba.lcut 可以使用結巴分詞
f = Template_Finder(tokenize, window=3)
f.train(D())
f.find(D())透過 Pandas 檢視結果:
import pandas as pd
templates = pd.Series(f.templates).sort_values(ascending=False)
idx = [i for i in templates.index if not i.is_trivial()]
templates = templates[idx] # 篩選出非平凡的模版每個模版已經被封裝為一個類了。
層次分解
基於句模版來進行句子結構解析。
from nlp_zero import *
# 建立一個字首樹,並加入模版
# 模版可以透過tuple來加入,
# 也可以直接透過“tire[模版類]=10”這樣來加入
trie = XTrie()
trie[(None, u'呢')] = 10
trie[(None, u'可以', None, u'嗎')] = 9
trie[(u'我', None)] = 8
trie[(None, u'的', None, u'是', None)] = 7
trie[(None, u'的', None, u'是', None, u'呢')] = 7
trie[(None, u'的', None)] = 12
trie[(None, u'和', None)] = 12
tokenize = Tokenizer().tokenize # 使用自帶的分詞工具
p = Parser(trie, tokenize) # 建立一個解析器
p.parse(u'雞蛋可以吃嗎') # 對句子進行解析
"""輸出:
>>> p.parse(u'雞蛋可以吃嗎')
+---> (雞蛋)可以(吃)嗎
| +---> 雞蛋
| | +---> 雞蛋
| +---> 可以
| +---> 吃
| | +---> 吃
| +---> 嗎
"""為了方便對結果進行呼叫以及視覺化,輸出結果已經被封裝為一個 SentTree 類。這個類有三個屬性:template(當前主模版)、content(當前主模版改寫的字串)、modules(語意塊的 list,每個語意塊也是用 SentTree 來描述)。總的來說,就是按照本文對語言結構的假設來設計的。

點選以下標題檢視作者其他文章:

▲ 戳我檢視招募詳情
 #作 者 招 募#
#作 者 招 募#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 進入作者部落格