作者: 哈爾的資料城堡 / 佘志銘 (本文來自作者投稿)
在古老的 Hadoop1.0 中,MapReduce 的 JobTracker 負責了太多的工作,包括資源排程,管理眾多的 TaskTracker 等工作。這自然是不合理的,於是 Hadoop 在 1.0 到 2.0 的升級過程中,便將 JobTracker 的資源排程工作獨立了出來,而這一改動,直接讓 Hadoop 成為大資料中最穩固的那一塊基石。而這個獨立出來的資源管理框架,就是 Yarn 。
一. Hadoop Yarn 是什麼
在詳細介紹 Yarn 之前,我們先簡單聊聊 Yarn ,Yarn 的全稱是 Yet Another Resource Negotiator,意思是另一種資源排程器,這種命名和“有間客棧”這種可謂是異曲同工之妙。這裡多說一句,以前 Java 有一個專案編譯工具,叫做 Ant,他的命名也是類似的,叫做 “Another Neat Tool”的縮寫,翻譯過來是”另一種整理工具“。
既然都叫做資源排程器了,那麼自然,它的功能也是負責資源管理和排程的,接下來,我們就深入到 Yarn 這個東西內部一探究竟吧。
二. Yarn 架構
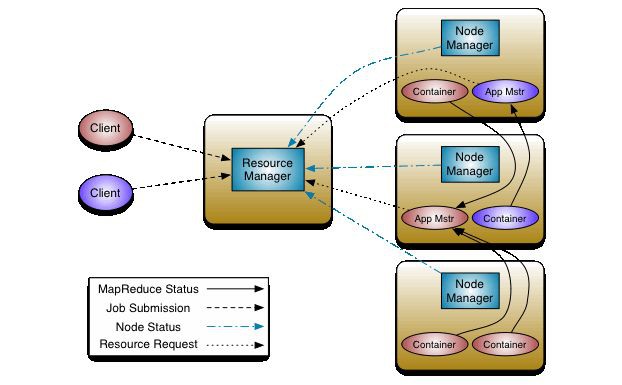
我們主要圍繞上面這張圖展開,不過在介紹圖中內容時,需要先瞭解 Yarn 中的 Container 的概念,然後會介紹圖中一個個元件,最後看看提交一個程式的流程。
2.1 Container
容器(Container)這個東西是 Yarn 對資源做的一層抽象。就像我們平時開發過程中,經常需要對底層一些東西進行封裝,只提供給上層一個呼叫介面一樣,Yarn 對資源的管理也是用到了這種思想。
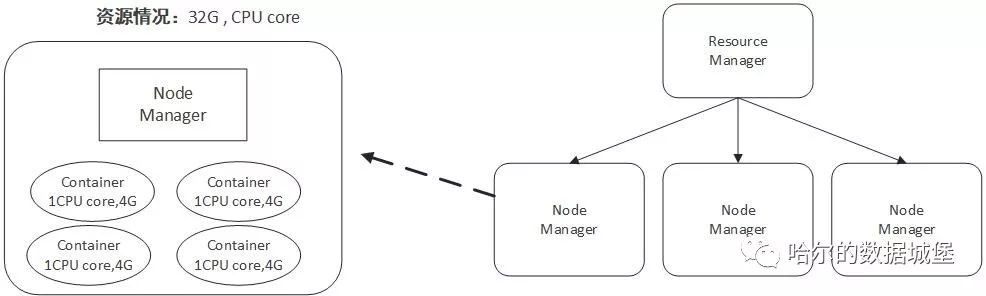
如上所示,Yarn 將CPU核數,記憶體這些計算資源都封裝成為一個個的容器(Container)。需要註意兩點:
1. 容器由 NodeManager 啟動和管理,並被它所監控。
2. 容器被 ResourceManager 進行排程。
NodeManager 和 ResourceManager 這兩個元件會在下麵講到。
2.2 三個主要元件
再看最上面的圖,我們能直觀發現的兩個主要的元件是 ResourceManager 和 NodeManager ,但其實還有一個 ApplicationMaster 在圖中沒有直觀顯示。我們分別來看這三個元件。
ResourceManager
我們先來說說上圖中最中央的那個 ResourceManager(RM)。從名字上我們就能知道這個元件是負責資源管理的,整個系統有且只有一個 RM ,來負責資源的排程。它也包含了兩個主要的元件:定時呼叫器(Scheduler)以及應用管理器(ApplicationManager)。
1. 定時排程器(Scheduler):從本質上來說,定時排程器就是一種策略,或者說一種演演算法。當 Client 提交一個任務的時候,它會根據所需要的資源以及當前叢集的資源狀況進行分配。註意,它只負責嚮應用程式分配資源,並不做監控以及應用程式的狀態跟蹤。
2. 應用管理器(ApplicationManager):同樣,聽名字就能大概知道它是幹嘛的。應用管理器就是負責管理 Client 使用者提交的應用。上面不是說到定時排程器(Scheduler)不對使用者提交的程式監控嘛,其實啊,監控應用的工作正是由應用管理器(ApplicationManager)完成的。
ApplicationMaster
每當 Client 提交一個 Application 時候,就會新建一個 ApplicationMaster 。由這個 ApplicationMaster 去與 ResourceManager 申請容器資源,獲得資源後會將要執行的程式傳送到容器上啟動,然後進行分散式計算。
這裡可能有些難以理解,為什麼是把執行程式傳送到容器上去執行?如果以傳統的思路來看,是程式執行著不動,然後資料進進出出不停流轉。但當資料量大的時候就沒法這麼玩了,因為海量資料移動成本太大,時間太長。但是中國有一句老話山不過來,我就過去。大資料分散式計算就是這種思想,既然大資料難以移動,那我就把容易移動的應用程式釋出到各個節點進行計算唄,這就是大資料分散式計算的思路。
NodeManager
NodeManager 是 ResourceManager 在每臺機器的上代理,負責容器的管理,並監控他們的資源使用情況(cpu,記憶體,磁碟及網路等),以及向 ResourceManager/Scheduler 提供這些資源使用報告。
三. 提交一個 Application 到 Yarn 的流程
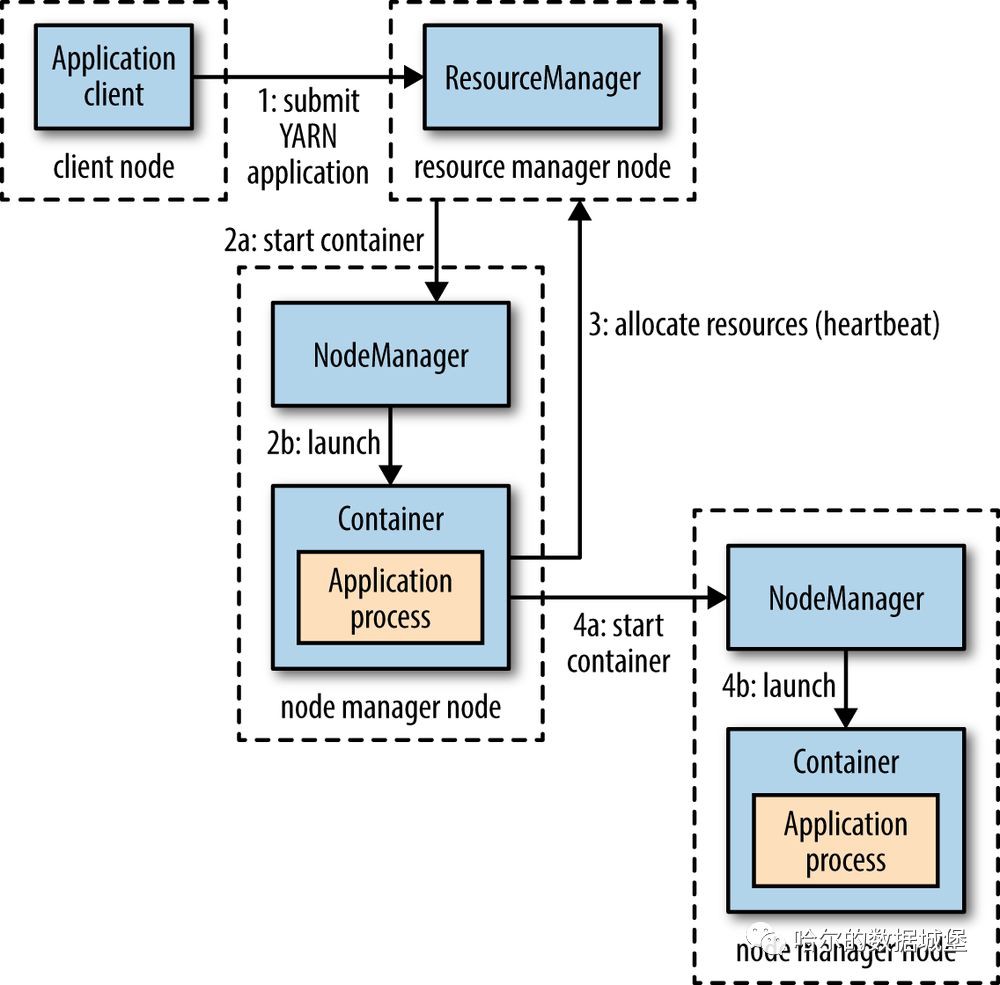
這張圖簡單地標明瞭提交一個程式所經歷的流程,接下來我們來具體說說每一步的過程。
1. Client 向 Yarn 提交 Application,這裡我們假設是一個 MapReduce 作業。
2. ResourceManager 向 NodeManager 通訊,為該 Application 分配第一個容器。併在這個容器中執行這個應用程式對應的 ApplicationMaster。
3. ApplicationMaster 啟動以後,對 作業(也就是 Application) 進行拆分,拆分 task 出來,這些 task 可以執行在一個或多個容器中。然後向 ResourceManager 申請要執行程式的容器,並定時向 ResourceManager 傳送心跳。
4. 申請到容器後,ApplicationMaster 會去和容器對應的 NodeManager 通訊,而後將作業分發到對應的 NodeManager 中的容器去執行,這裡會將拆分後的 MapReduce 進行分發,對應容器中執行的可能是 Map 任務,也可能是 Reduce 任務。
5. 容器中執行的任務會向 ApplicationMaster 傳送心跳,彙報自身情況。當程式執行完成後, ApplicationMaster 再向 ResourceManager 登出並釋放容器資源。
以上就是一個作業的大體執行流程。
為什麼會有 Yarn ?
上面說了這麼多,最後我們來聊聊為什麼會有 Yarn 吧。
直接的原因呢,就是因為 Hadoop1.0 中架構的缺陷,在 MapReduce 中,jobTracker 擔負起了太多的責任了,接收任務是它,資源排程是它,監控 TaskTracker 執行情況還是它。這樣實現的好處是比較簡單,但相對的,就容易出現一些問題,比如常見的單點故障問題。
要解決這些問題,只能將 jobTracker 進行拆分,將其中部分功能拆解出來。彼時業內已經有了一部分的資源管理框架,比如 mesos,於是照著這個思路,就開發出了 Yarn。這裡多說個冷知識,其實 Spark 早期是為了推廣 mesos 而產生的,這也是它名字的由來,不過後來反正是 Spark 火起來了。。。
閑話不多說,其實 Hadoop 能有今天這個地位,Yarn 可以說是功不可沒。因為有了 Yarn ,更多計算框架可以接入到 Hdfs 中,而不單單是 MapReduce,到現在我們都知道,MapReduce 早已經被 Spark 等計算框架趕超,而 Hdfs 卻依然屹立不倒。究其原因,正式因為 Yarn 的包容,使得其他計算框架能專註於計算效能的提升。Hdfs 可能不是最優秀的大資料儲存系統,但卻是應用最廣泛的大資料儲存系統,Yarn 功不可沒。
【本文作者】
佘志銘,現在在廣告行業的網際網路公司任職研發工程師。愛好思考,寫作。