
本文基於幾篇經典的論文,對 Attention 模型的不同結構進行分析、拆解。
先簡單談一談 attention 模型的引入。以基於 seq2seq 模型的機器翻譯為例,如果 decoder 只用 encoder 最後一個時刻輸出的 hidden state,可能會有兩個問題(我個人的理解)。
1. encoder 最後一個 hidden state,與句子末端詞彙的關聯較大,難以保留句子起始部分的資訊;
2. encoder 按順序依次接受輸入,可以認為 encoder 產出的 hidden state 包含有詞序資訊。所以一定程度上 decoder 的翻譯也基本上沿著原始句子的順序依次進行,但實際中翻譯卻未必如此,以下是一個翻譯的例子:
英文原句:space and oceans are the new world which scientists are trying to explore.
翻譯結果:空間和海洋是科學家試圖探索的新世界。
詞彙對照如下:

可以看到,翻譯的過程並不總是沿著原句從左至右依次進行翻譯,例如上面例子的定語從句。
為了一定程度上解決以上的問題,14 年的一篇文章 Sequence to Sequence Learning with Neural Networks 提出了一個有意思的 trick,即在模型訓練的過程中將原始句子進行反轉,取得了一定的效果。
為了更好地解決問題,attention 模型開始得到廣泛重視和應用。
下麵進入正題,進行對 attention 的介紹。
Show, Attend and Tell

■ 論文 | Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
■ 連結 | https://www.paperweekly.site/papers/812
■ 原始碼 | https://github.com/kelvinxu/arctic-captions
文章討論的場景是影象描述生成(Image Caption Generation),對於這種場景,先放一張圖,感受一下 attention 的框架。

文章提出了兩種 attention 樣式,即 hard attention 和 soft attention,來感受一下這兩種 attention。

可以看到,hard attention 會專註於很小的區域,而 soft attention 的註意力相對發散。模型的 encoder 利用 CNN (VGG net),提取出影象的 L 個 D 維的向量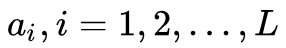 ,每個向量表示影象的一部分資訊。
,每個向量表示影象的一部分資訊。
decoder 是一個 LSTM,每個 timestep t 的輸入包含三個部分,即 context vector Zt 、前一個 timestep 的 hidden state 、前一個 timestep 的 output
、前一個 timestep 的 output 。 Zt 由 {ai} 和權重 {αti} 透過加權得到。這裡的權重 αti 透過attention模型 fatt 來計算得到,而本文中的 fatt 是一個多層感知機(multilayer perceptron)。
。 Zt 由 {ai} 和權重 {αti} 透過加權得到。這裡的權重 αti 透過attention模型 fatt 來計算得到,而本文中的 fatt 是一個多層感知機(multilayer perceptron)。
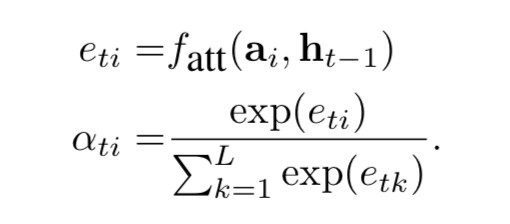
從而可以計算 。接下來文章重點討論 hard(也叫 stochastic attention)和 soft(也叫 deterministic)兩種 attention 樣式。
。接下來文章重點討論 hard(也叫 stochastic attention)和 soft(也叫 deterministic)兩種 attention 樣式。
1. Stochastic “Hard” Attention
記 St 為 decoder 第 t 個時刻的 attention 所關註的位置編號, Sti 表示第 t 時刻 attention 是否關註位置 i , Sti 服從多元伯努利分佈(multinoulli distribution), 對於任意的 t ,Sti,i=1,2,…,L 中有且只有取 1,其餘全部為 0,所以 [St1,St2,…,stL] 是 one-hot 形式。這種 attention 每次只 focus 一個位置的做法,就是“hard”稱謂的來源。 Zt 也就被視為一個變數,計算如下:

問題是 αti 怎麼算呢?把 αti 視為隱變數,研究模型的標的函式,進而研究標的函式對引數的梯度。直觀理解,模型要根據 a=(a1,…,aL) 來生成序列 y=(y1,…,yC) ,所以標的可以是最大化 log p(y|a) ,但這裡沒有顯式的包含 s ,所以作者利用著名的 Jensen 不等式(Jensen’s inequality)對標的函式做了轉化,得到了標的函式的一個 lower bound,如下:

這裡的 s ={ s1,…,sC },是時間軸上的重點 focus 的序列,理論上這種序列共有![]() 個。 然後就用 log p(y|a) 代替原始的標的函式,對模型的引數 W 算 gradient。
個。 然後就用 log p(y|a) 代替原始的標的函式,對模型的引數 W 算 gradient。

然後利用蒙特卡洛方法對 s 進行抽樣,我們做 N 次這樣的抽樣實驗,記每次取到的序列是![]() ,易知
,易知![]() 的機率為
的機率為![]() ,所以上面的求 gradient 的結果即為:
,所以上面的求 gradient 的結果即為:

接下來的一些細節涉及reinforcement learning,感興趣的同學可以去看這篇 paper。
2. Deterministic “Soft” Attention
說完“硬”的 attention,再來說說“軟”的 attention。 相對來說 soft attention 很好理解,在 hard attention 裡面,每個時刻 t 模型的序列 [ St1,…,StL ] 只有一個取 1,其餘全部為 0,也就是說每次只 focus 一個位置,而 soft attention 每次會照顧到全部的位置,只是不同位置的權重不同罷了。這時 Zt 即為 ai 的加權求和:
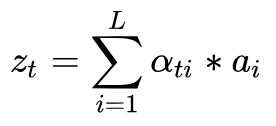
這樣 soft attention 是光滑的且可微的(即標的函式,也就是 LSTM 的標的函式對權重 αti 是可微的,原因很簡單,因為標的函式對 Zt 可微,而 Zt 對 αti 可微,根據 chain rule 可得標的函式對 αti 可微)。
文章還對這種 soft attention 做了微調:
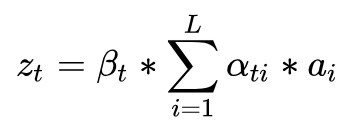
其中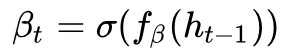 ,用來調節 context vector 在 LSTM 中的比重(相對於
,用來調節 context vector 在 LSTM 中的比重(相對於![]() 、
、 ![]() 的比重)。
的比重)。
btw,模型的 loss function 加入了 αti 的正則項。

Attention-based NMT

■ 論文 | Effective Approaches to Attention-based Neural Machine Translation
■ 連結 | https://www.paperweekly.site/papers/806
■ 原始碼 | https://github.com/lmthang/nmt.matlab
文章提出了兩種 attention 的改進版本,即 global attention 和 local attention。先感受一下 global attention 和 local attention 長什麼樣子。
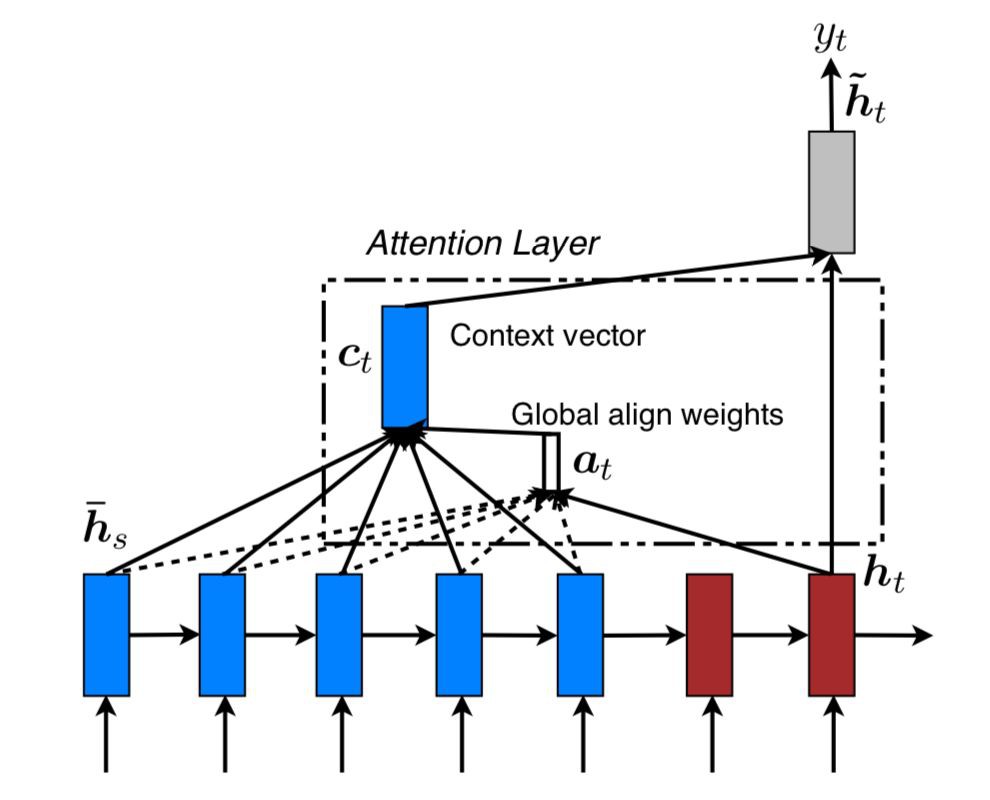
▲ Global Attention
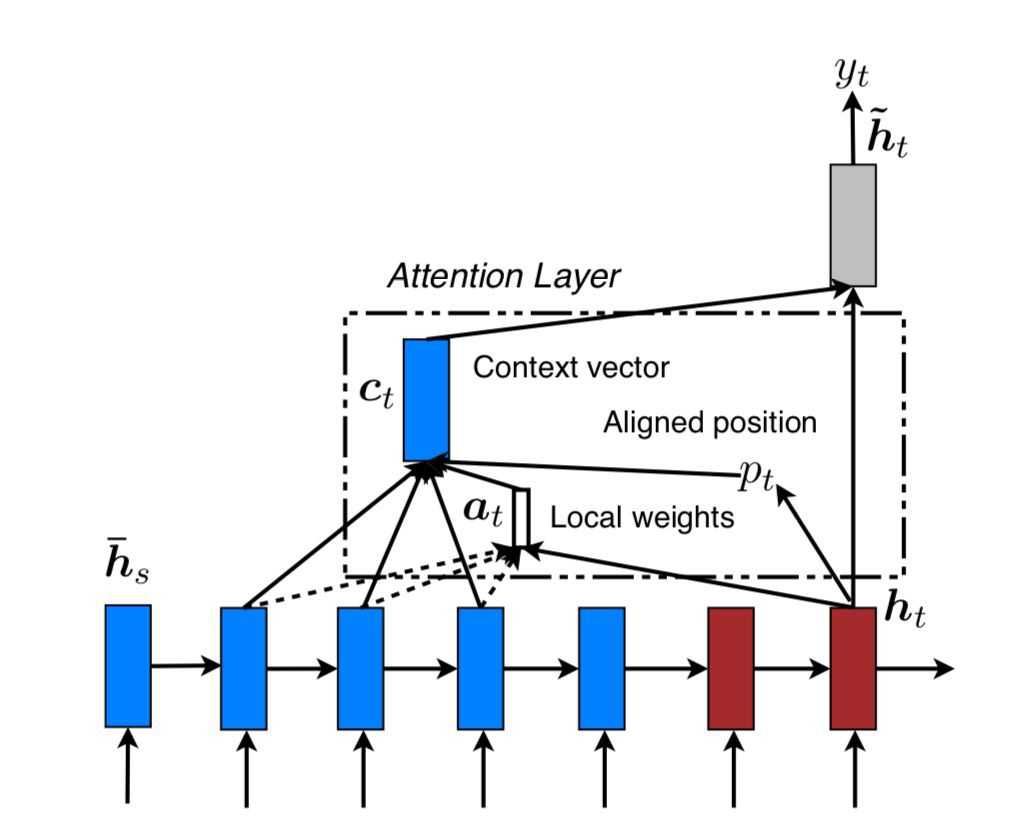
▲ Local Attention
文章指出,local attention 可以視為 hard attention 和 soft attention 的混合體(優勢上的混合),因為它的計算複雜度要低於 global attention、soft attention,而且與 hard attention 不同的是,local attention 幾乎處處可微,易與訓練。 文章以機器翻譯為場景, x1,…,xn 為 source sentence, y1,…,ym 為 target sentence, c1,…,cm 為 encoder 產生的 context vector,objective function 為:
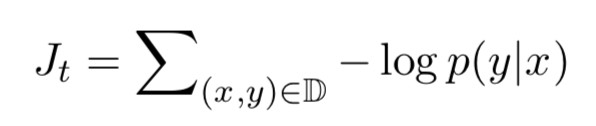
Ct 來源於 encoder 中多個 source position 所產生的 hidden states,global attention 和 local attention 的主要區別在於 attention 所 forcus 的 source positions 數目的不同:如果 attention forcus 全部的 position,則是 global attention,反之,若只 focus 一部分 position,則為 local attention。
由此可見,這裡的 global attention、local attention 和 soft attention 並無本質上的區別,兩篇 paper 模型的差別隻是在 LSTM 結構上有微小的差別。
在 decoder 的時刻 t ,在利用 global attention 或 local attention 得到 context vector Ct 之後,結合 ht ,對二者做 concatenate 操作,得到 attention hidden state。

最後利用 softmax 產出該時刻的輸出:

下麵重點介紹 global attention、local attention。
1. global attention
global attention 在計算 context vector ct 的時候會考慮 encoder 所產生的全部hidden state。記 decoder 時刻 t 的 target hidden為 ht,encoder 的全部 hidden state 為 ,對於其中任意
,對於其中任意![]() ,其權重 αts 為:
,其權重 αts 為:

而其中的 ,文章給出了四種種計算方法(文章稱為 alignment function):
,文章給出了四種種計算方法(文章稱為 alignment function):


四種方法都比較直觀、簡單。在得到這些權重後, ct 的計算是很自然的,即為![]() 的 weighted summation。
的 weighted summation。
2. local attention
global attention 可能的缺點在於每次都要掃描全部的 source hidden state,計算開銷較大,對於長句翻譯不利,為了提升效率,提出 local attention,每次只 focus 一小部分的 source position。
這裡,context vector ct 的計算只 focus 視窗 [pt-D,pt+D] 內的 2D+1 個source hidden states(若發生越界,則忽略界外的 source hidden states)。
其中 pt 是一個 source position index,可以理解為 attention 的“焦點”,作為模型的引數, D 根據經驗來選擇(文章選用 10)。 關於 pt 的計算,文章給出了兩種計算方案:
-
Monotonic alignment (local-m)

-
Predictive alignment (local-p)
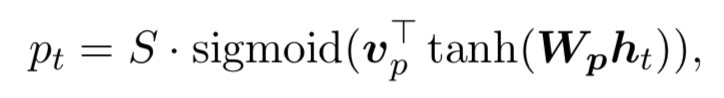
其中 Wp 和 vp 是模型的引數, S 是 source sentence 的長度,易知 pt∈[0,S] 。 權重 αt(s) 的計算如下:

可以看出,距離中心 pt 越遠的位置,其位置上的 source hidden state 對應的權重就會被壓縮地越厲害。
Jointly Learning

■ 論文 | Neural Machine Translation by Jointly Learning to Align and Translate
■ 連結 | https://www.paperweekly.site/papers/434
■ 原始碼 | https://github.com/spro/torch-seq2seq-attention
這篇文章沒有使用新的 attention 結構,其 attention 就是 soft attention 的形式。文章給出了一些 attention 的視覺化效果圖。

上面 4 幅圖中,x 軸代表原始英文句子,y 軸代表翻譯為法文的結果。每個畫素代表的是縱軸的相應位置的 target hidden state 與橫軸相應位置的 source hidden state 計算得到的權重 αij,權重越大,對應的畫素點越亮。可以看到,亮斑基本處在對角線上,符合預期,畢竟翻譯的過程基本是沿著原始句子從左至右依次進行翻譯。
Attention Is All You Need

■ 論文 | Attention Is All You Need
■ 連結 | https://www.paperweekly.site/papers/224
■ 原始碼 | https://github.com/Kyubyong/transformer

■ 論文 | Weighted Transformer Network for Machine Translation
■ 連結 | https://www.paperweekly.site/papers/2013
■ 原始碼 | https://github.com/JayParks/transformer
作者首先指出,結合了 RNN(及其變體)和註意力機制的模型在序列建模領域取得了不錯的成績,但由於 RNN 的迴圈特性導致其不利於平行計算,所以模型的訓練時間往往較長,在 GPU 上一個大一點的 seq2seq 模型通常要跑上幾天,所以作者對 RNN 深惡痛絕,遂決定捨棄 RNN,只用註意力模型來進行序列的建模。
作者提出一種新型的網路結構,並起了個名字 Transformer,裡面所包含的註意力機制稱之為 self-attention。作者驕傲地宣稱他這套 Transformer 是能夠計算 input 和 output 的 representation 而不借助 RNN 的唯一的 model,所以作者說有 attention 就夠了。
模型同樣包含 encoder 和 decoder 兩個 stage,encoder 和 decoder 都是拋棄 RNN,而是用堆疊起來的 self-attention,和 fully-connected layer 來完成,模型的架構如下:

從圖中可以看出,模型共包含三個 attention 成分,分別是 encoder 的 self-attention,decoder 的 self-attention,以及連線 encoder 和 decoder 的 attention。
這三個 attention block 都是 multi-head attention 的形式,輸入都是 query Q 、key K 、value V 三個元素,只是 Q 、 K 、 V 的取值不同罷了。接下來重點討論最核心的模組 multi-head attention(多頭註意力)。
multi-head attention 由多個 scaled dot-product attention 這樣的基礎單元經過 stack 而成。

那重點就變成 scaled dot-product attention 是什麼鬼了。按字面意思理解,scaled dot-product attention 即縮放了的點乘註意力,我們來對它進行研究。
在這之前,我們先回顧一下上文提到的傳統的 attention 方法(例如 global attention,score 採用 dot 形式)。
記 decoder 時刻 t 的 target hidden state 為 ht,encoder 得到的全部 source hidden state為 ,則 decoder 的 context vector ct 的計算過程如下:
,則 decoder 的 context vector ct 的計算過程如下:

作者先丟擲三個名詞 query Q、key K、value V,然後計算這三個元素的 attention。

我的寫法與論文有細微差別,但為了接下來說明的簡便,我姑且簡化成這樣。這個 Attention 的計算跟上面的 (*) 式有幾分相似。
那麼 Q、K、V 到底是什麼?論文裡講的比較晦澀,說說我的理解。encoder 裡的 attention 叫 self-attention,顧名思義,就是自己和自己做 attention。
拋開這篇論文的做法,讓我們啟用自己的創造力,在傳統的 seq2seq 中的 encoder 階段,我們得到 n 個時刻的 hidden states 之後,可以用每一時刻的 hidden state hi,去分別和任意的 hidden state hj,j=1,2,…,n 計算 attention,這就有點 self-attention 的意思。
回到當前的模型,由於拋棄了 RNN,encoder 過程就沒了 hidden states,那拿什麼做 self-attention 來自嗨呢?
可以想到,假如作為 input 的 sequence 共有 n 個 word,那麼我可以先對每一個 word 做 embedding 吧?就得到 n 個 embedding,然後我就可以用 embedding 代替 hidden state 來做 self-attention 了。所以 Q 這個矩陣裡面裝的就是全部的 word embedding,K、V 也是一樣。
所以為什麼管 Q 叫query?就是你每次拿一個 word embedding,去“查詢”其和任意的 word embedding 的 match 程度(也就是 attention 的大小),你一共要做 n 輪這樣的操作。
我們記 word embedding 的 dimension 為 dmodel ,所以 Q 的 shape 就是 n*dmodel, K、V 也是一樣,第 i 個 word 的 embedding 為 vi,所以該 word 的 attention 應為:

那同時做全部 word 的 attention,則是:

scaled dot-product attention 基本就是這樣了。基於 RNN 的傳統 encoder 在每個時刻會有輸入和輸出,而現在 encoder 由於拋棄了 RNN 序列模型,所以可以一下子把序列的全部內容輸進去,來一次 self-attention 的自嗨。
理解了 scaled dot-product attention 之後,multi-head attention 就好理解了,因為就是 scaled dot-product attention 的 stacking。
先把 Q、K、V 做 linear transformation,然後對新生成的 Q‘、K’、V’ 算 attention,重覆這樣的操作 h 次,然後把 h 次的結果做 concat,最後再做一次 linear transformation,就是 multi-head attention 這個小 block 的輸出了。

以上介紹了 encoder 的 self-attention。decoder 中的 encoder-decoder attention 道理類似,可以理解為用 decoder 中的每個 vi 對 encoder 中的 vj 做一種交叉 attention。
decoder 中的 self-attention 也一樣的道理,只是要註意一點,decoder 中你在用 vi 對 vj 做 attention 時,有一些 pair 是不合法的。原因在於,雖然 encoder 階段你可以把序列的全部 word 一次全輸入進去,但是 decoder 階段卻並不總是可以,想象一下你在做 inference,decoder 的產出還是按從左至右的順序,所以你的 vi 是沒機會和 vj ( j>i ) 做 attention 的。
那怎麼將這一點體現在 attention 的計算中呢?文中說只需要令 score(vi,vj)=-∞ 即可。為何?因為這樣的話:
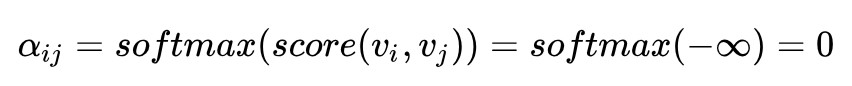
所以在計算 vi 的 self-attention 的時候,就能夠把 vj 遮蔽掉。所以這個問題也就解決了。
模型的其他模組,諸如 position-wise feed-forward networks、position encoding、layer normalization、residual connection 等,相對容易理解,感興趣的同學可以去看 paper,此處不再贅述。
總結
本文對 attention 的五種結構,即 hard attention、soft attention、global attention、local attention、self-attention 進行了具體分析。五種 attention 在計算複雜度、部署難度、模型效果上會有一定差異,實際中還需根據業務實際合理選擇模型。

點選標題檢視更多相關文章:

▲ 戳我檢視招募詳情
 #作 者 招 募#
#作 者 招 募#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群刷論文
