
關於作者:彭博,人工智慧、量化交易、區塊鏈領域的資深技術專家,有 20 年以上的研發經驗。在人工智慧與資訊科技方面,對深度學習、機器學習、計算機圖形學、智慧硬體等有較為深入的研究;在量化交易方面,曾在全球最大的外匯對沖基金負責程式化交易,對市場的微觀和宏觀行為有較為深入的理解;在區塊鏈方面,對智慧合約、DApp 開發和自動交易有較為深入的實踐。知乎上科技領域的大 V,在專欄撰有大量技術文章。
本文內容節選自《深度摺積網路:原理與實踐》第 8.5 節。
大家對於 GAN 都已經很熟悉了,但 GAN 的訓練目前仍然存在樣式坍塌等等難題。目前還有其他採用深度網路的生成模型方法,例如 AE,它們的思想可互補,提高生成影象的質量和穩定性,典型的例子是 CVAE-GAN。在此我們對這些方法做簡介。
自編碼器:從AE到VAE
自編碼器(auto-encoder,AE)是經典的生成模型方法,其架構如下圖所示。
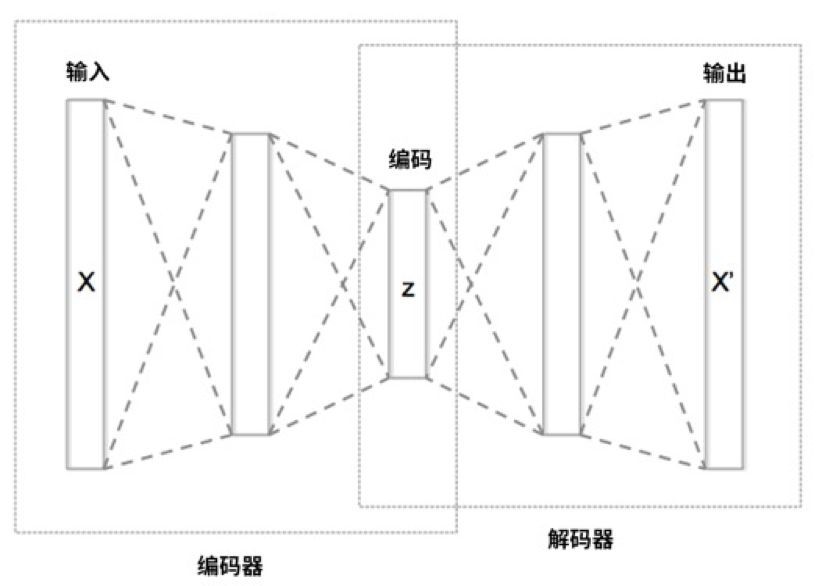
AE 可分為兩個網路:
-
編碼(encoder)網路,負責從 x 到 z,可稱為 E;
-
解碼(decoder)網路,負責從 z 到 x,可稱為 G,因為它和 GAN 中的生成網路都是從 z 到 x。
可將從 x 到 z 看成是壓縮資訊的過程,從 z 到 x 看成是解壓縮的過程。例如,如果 x 是 64*64 的彩色影象,那麼它有 3*64*64=12288 維。而 z 往往只有 50 到 200 維。
AE 和 GAN 的區別在於,AE 中沒有更先進的判別網路(D 網路),AE 的最佳化標的只是讓 x 和 G(E(x)) 儘量在畫素上接近。如本書的前文所述,這並不是個好標的,因此 AE 生成的影象往往很模糊,例如 AE 和 GAN 在 Fashion-MNIST 資料集的效果對比如下圖所示。

不過,AE 相對於 GAN 也有長處,就是生成的影象更均勻,光滑,訓練過程更穩定。因此研究人員提出了多種將 AE 和 GAN 結合的方法,後文會介紹的 CVAE-GAN 是效果出色的例子。
AE 的重要發展是 VAE(Variational Auto-Encoder,變分自編碼器,https://arxiv.org/pdf/1312.6114)。它能解決 AE 的一個缺點:AE 的 G 只能保證將由 x 生成的 z 還原為 x。如果我們隨機生成 1 個 z,經過 AE 的 G 後往往不會得到有效的影象。
而 VAE 可讓 E 生成的 z 儘量符合某個指定分佈,例如標準差為 1 的多維正態分佈。那麼此時只需從這個分佈取樣出 z,就能透過 G 得到有效的影象。具體而言,這是透過一個引數化技巧(reparameterization trick)實現,可參閱 VAE 的原始論文。
舉例,對於 MNIST 資料集,如果要求 z 是 2 維的,最終效果如下圖所示。

可見,無論選取怎樣的 z 坐標,都能得到較為合理的數字影象。
逐點生成:PixelRNN和PixelCNN系列
由 Google 提出的 PixelRNN(https://arxiv.org/abs/1601.06759)和 PixelCNN(https://arxiv.org/abs/1606.05328)是生成模型的另一種思路。
它的方法非常直接:從左到右,從上到下,逐步生成一個個畫素,最終生成整張影象。如果讀者對於迴圈神經網路(RNN)熟悉,會意識到這是一個很適合 RNN 的問題。
基本原理如下圖所示,以之前生成的畫素作為輸入,輸出對於下一個畫素的值的統計分佈的預測,然後從分佈取樣出下一個畫素。

可以想象,它會很適合生成小圖。例如下圖中是它生成的珊瑚礁影象,色彩很鮮艷。

而它的缺點無疑就是速度,以及目前仍然難以生成大圖。於是讀者可能會問,是否可構建出 PixelGAN?答案是肯定的(https://arxiv.org/abs/1706.00531)。
最後,Pixel 系列的思想尤其適合生成音訊和文字,例如 WaveNet(https://deepmind.com/blog/wavenet-generative-model-raw-audio/),它用此前生成的音訊取樣作為輸入,生成下一個取樣,不斷重覆此過程,最終可生成高質量的語音和音樂,如下圖所示。

將VAE和GAN結合:CVAE-GAN
CVAE-GAN 架構的論文是《 CVAE-GAN: Fine-Grained Image Generation through Asymmetric Training》(https://arxiv.org/pdf/1703.10155v1.pdf),其中 C 代表能用分類作為輸入,生成指定分類的影象。它在各個分類上生成的影象效果都相當好,如下圖所示。

上述影象都是由 CVAE-GAN 生成。它有 4 大元件,對應到 4 個神經網路,互為補充,互相促進:
-
E:編碼器(Encoder),輸入影象 x,輸出編碼 z。
如果還給定了類別 c,那麼生成的 z 就會質量更高,即更隨機,因為可移除c中已包含的資訊。
-
G:生成器(Generator)。輸入編碼 z,輸出影象 x。
如果還給定了類別 c,那麼就會生成屬於類別 c 的影象。
-
C:分類器(Classifier)。輸入影象 x,輸出所屬類別 c。這是我們的老朋友。
-
D:辨別器(Discriminator)。輸入影象 x,判斷它的真實度。
我們先看如果只使用部分元件會是怎樣。首先是 CVAE,如下圖所示:

然後是 CGAN,其中 y 代表對於真實度的判別,如下圖所示:

它們的效果如下圖所示。

可見:
-
CVAE 生成的影象中規中矩,但是模糊。
-
CGAN 生成的影象清晰,但有時會有明顯錯誤。
所以 AE 和 GAN 的方法剛好是互補。
CVAE-GAN 的架構如下圖所示:

其中的 G 有 3 個主要標的:
-
對於從 x 生成的 z,G 應能還原出接近 x 的 x’(畫素上的接近)。這來自 AE 的思想。
-
G 生成的影象應可由 D 鑒別為屬於真實影象。這來自 GAN 的思想。
-
G 生成的影象應可由 C 鑒別為屬於 c 類別。這與 InfoGAN 的思想有些相似。
最終得到的 z 可相當好地刻畫影象。例如,同樣的 z 在不同 c 下的效果如下圖所示。

這裡的不同 c,代表不同的明星。相同的 z,代表其他的一切語意特徵(如表情,角度,光照等等)都一模一樣。
於是,透過保持 z,改變 c,可輕鬆實現真實的換臉效果,如下圖所示。

CVAE-GAN 在語意插值上的效果也很出色,如下圖所示。

由於 CVAE-GAN 生成的樣本質量很高,還可用於增強訓練樣本集,使其他模型(如影象分類網路)得到更好的效果。
 #福 利 時 間#
#福 利 時 間#
以下是簡單粗暴送書環節
PaperWeekly × 機械工業出版社
深度摺積網路
原理與實踐
<3本>

技術理論√工作原理√實踐方法√
作者:彭博
20 年開發經驗資深專家/知乎大 V,從技術理論、工作原理、實踐方法、架構技巧、訓練策略和技術前瞻 6 個維度系統、深入講解 DCNN 和 GAN。
深度摺積網路(DCNN)是目前十分流行的深度神經網路架構,它的構造清晰直觀,效果引人入勝,在影象、影片、語音、語言領域都有廣泛應用。
本書以 AI 領域最新的技術研究和和實踐為基礎,從技術理論、工作原理、實踐方法、架構技巧、訓練方法、技術前瞻等 6 個維度對深度摺積網路進行了系統、深入、詳細地講解。
以實戰為導向,深入分析 AlphaGo 和 GAN 的實現過程、技術原理、訓練方法和應用細節,為讀者依次揭開神經網路、摺積網路和深度摺積網路的神秘面紗,讓讀者瞭解 AI 的“思考過程”,以及與人類思維的相同和不同之處。
參與方式
請在文末留言分享
關於GAN的訓練,你有什麼心得體會?
小編將隨機抽取3位同學
送出機械工業出版社新書
截止時間:6月15日(週五)20:00
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 訂購《深度摺積網路》
