作者:ANKIT CHOUDHARY;翻譯:王雨桐;校對:丁楠雅;
本文約3000字,建議閱讀12分鐘。
本文將透過拆解Prophet的原理及程式碼實體來講解如何運用Prophet進行時間序列預測。
簡介
對於任何業務而言,基於時間進行分析都是至關重要的。庫存量應該保持在多少?你希望商店的客流量是多少?多少人會乘坐飛機旅遊?類似這樣待解決的問題都是重要的時間序列問題。
這就是時間序列預測被看作資料科學家必備技能的原因。從預測天氣到預測產品的銷售情況,時間序列是資料科學體系的一部分,並且是成為一個資料科學家必須要補充的技能。
如果你是菜鳥,時間序列為你提供了一個很好的途徑去實踐專案。你可以非常輕易地應用時間序列,它會帶領你進入更大的機器學習世界。

Prophet是Facebook釋出的基於可分解(趨勢+季節+節假日)模型的開源庫。它讓我們可以用簡單直觀的引數進行高精度的時間序列預測,並且支援自定義季節和節假日的影響。
本文中,我們將介紹Prophet如何產生快速可靠的預測,並透過Python進行演示。最終結果將會讓你大吃一驚!
本文目錄
1. Prophet有什麼創新點?
2. Prophet預測模型
-
趨勢
-
飽和增長
-
突變點
-
季節性
-
節假日及大事件
3. Prophet實戰(附Python和R程式碼)
-
趨勢引數
-
季節和節假日引數
-
透過Prophet預測客運量
Prophet有什麼創新點?
當預測模型沒有按預期執行時,我們希望針對問題來調整模型的引數。調整引數需要對時間序列的工作原理有全面的理解。例如automated ARIMA首先輸入的引數是差分的最大階數,自回歸分量和移動平均分量。普通分析師不知道如何調整順序來避免這種表現,這是一種很難掌握積累的專業知識。

Prophet包提供了直觀易調的引數,即使是對缺乏模型知識的人來說,也可以據此對各種商業問題做出有意義的預測。
Prophet預測模型
時間序列模型可分解為三個主要組成部分:趨勢,季節性和節假日。它們按如下公式組合:

-
g(t):用於擬合時間序列中的分段線性增長或邏輯增長等非週期變化。
-
s(t):週期變化(如:每週/每年的季節性)。
-
h(t):非規律性的節假日效應(使用者造成)。
-
et:誤差項用來反映未在模型中體現的異常變動。
Prophet使用時間為回歸元,嘗試擬合線性和非線性的時間函式項,採取類似霍爾特-溫特斯( Holt-Winters )指數平滑的方法,將季節作為額外的成分來建模。事實上,我們將預測問題類比為擬合曲線模型,而不是精確地去看時間序列中每個時點上的觀測值。
1. 趨勢
趨勢是對時間序列中的非週期部分或趨勢部分擬合分段線性函式,線性擬合會將特殊點和缺失資料的影響降到最小。
-
飽和增長
這裡要問一個重要問題-我們是否希望標的在整個預測區間內持續增長或下降?通常情況下,一些非線性增長的案例會有最大容量限制,比如以下案例:
假設我們要預測未來12個月某app在某地區的下載量,最大下載量總是受該地區智慧手機使用者總數的限制。然而,智慧手機使用者的數量也會隨著時間的推移而增加。
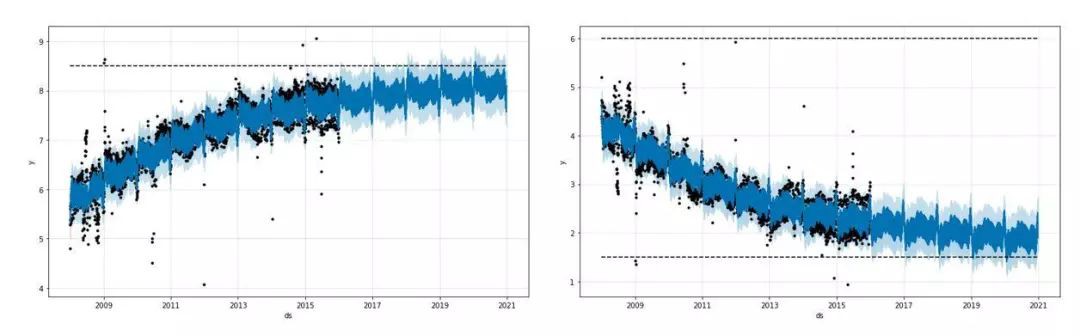
基於這樣的領域知識,分析師可以定義時間序列預測的容量限製為C(t)。
-
突變點
另一個要回答的問題是-時間序列是否會因為其他現象發生潛在變化,例如新產品釋出、不可預見的災難等。這種情況下,增長率是會改變的。這些突變點是自動選擇的,然而有需要的時候也可以手動輸入突變點。在下圖中,點線代表給定時間序列中的突變點。

隨著突變點數量的增多,擬合變得更靈活。在研究趨勢成分時,分析師要面臨兩個基本問題:
-
過擬合
-
欠擬合
引數changepoint_prior_scale可以用來調整趨勢的靈活性並解決以上兩個問題。引數的值越大,擬合的時間序列曲線越靈活。
2. 季節性
為了擬合併預測季節的效果,Prophet基於傅裡葉級數提出了一個靈活的模型。季節效應S(t)根據以下方程進行估算:
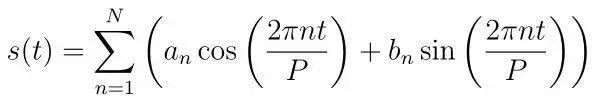
P是週期(年度資料的P是365.25,周資料的P是7)。
對季節性建模時,需要在給定N的情況下,估計引數[a1,b1……aN, bN]。
傅裡葉階數N是一個重要的引數,它用來定義模型中是否考慮高頻變化。對時間序列來說,如果分析師認為高頻變化的成分只是噪聲,沒必要在模型中考慮,可以把N設為較低的值。如果不是,N可以被設定為較高的值並用於提升預測精度。
3. 節假日和大事件
節假日和大事件會導致時間序列中出現可預測的波動。例如,印度的排燈節(Diwali)每年的日期都不同,在此期間人們大多會購買大量新商品。
Prophet允許分析師使用過去和未來事件的自定義串列。這些大事件前後的日期將會被單獨考慮,並且透過擬合附加的引數模擬節假日和事件的效果。
Prophet實戰(附Python程式碼)
目前Prophet只適用於Python和R,這兩者有同樣的功能。
Python中,使用Prophet()函式來定義Prophet預測模型。讓我們看一下最重要的引數。
1. 趨勢引數
|
引數 |
描述 |
|
growth |
‘linear’或‘logistic’用來規定線性或邏輯曲線趨勢 |
|
changepoints |
包括潛在突變點的日期串列(不指明則預設為自動識別) |
|
n_changepoints |
若不指定突變點,則需要提供自動識別的突變點數量 |
|
changepoint_prior_scale |
設定自動突變點選擇的靈活性 |
2. 季節&假日引數
|
引數 |
描述 |
|
yearly_seasonality |
週期為年的季節性 |
|
weekly_seasonality |
週期為周的季節性 |
|
daily_seasonality |
週期為日的季節性 |
|
holidays |
內建的節假日名稱和日期 |
|
seasonality_prior_scale |
改變季節模型的強度 |
|
holiday_prior_scale |
改變假日模型的強度 |
yearly_seasonality、weekly_seasonality和daily_seasonality取值為True或False,沒有上一節中討論的傅裡葉項。若值為True,預設取傅裡葉項為10。Prior scales用來定義擬合過程中季節或節假日的權重程度。
3. 透過Prophet預測客運交通
現在我們已經瞭解了這個神奇工具的細節,接下來讓我們透過實際的資料集來看看它的潛力。這裡我在Python中運用Prophet來解決下麵連結(DATAHACK平臺)中的實際問題。
DATAHACK平臺:
https://datahack.analyticsvidhya.com/contest/practice-problem-time-series-2/
該資料集是一個單變數的時間序列,即某新型公共交通服務的每小時客運量。基於給定的過去25個月的歷史交通流量資料,我們可以嘗試預測未來七個月的交通情況。
基本的探索性資料分析(EDA)可以透過以下課程獲取:
課程連結:
https://trainings.analyticsvidhya.com/courses/course-v1:AnalyticsVidhya+TS_101+TS_term1/about
Python實現如下:
匯入所需要的包並讀入資料集
#Importing datasets
import pandas as pd
import numpy as np
from fbprophet import Prophet
#Read train and test
train = pd.read_csv(‘Train_SU63ISt.csv’)
test = pd.read_csv(‘Test_0qrQsBZ.csv’)
#Convert to datetime format
train[‘Datetime’] = pd.to_datetime(train.Datetime,format=’%d-%m-%Y %H:%M’)
test[‘Datetime’] = pd.to_datetime(test.Datetime,format=’%d-%m-%Y %H:%M’)
train[‘hour’] = train.Datetime.dt.hour

我們可以看到時間序列中有很多噪聲。我們可以對其進行重取樣並彙總,得到一個噪聲更少的新序列,進而更易建模。
# Calculate average hourly fraction
hourly_frac = train.groupby([‘hour’]).mean()/np.sum(train.groupby([‘hour’]).mean())
hourly_frac.drop([‘ID’], axis = 1, inplace = True)
hourly_frac.columns = [‘fraction’]
# convert to time series from dataframe
train.index = train.Datetime
train.drop([‘ID’,’hour’,’Datetime’], axis = 1, inplace = True)
daily_train = train.resample(‘D’).sum()
Prophet要求時間序列中的變數名為:
y -> 標的(Target)
ds -> 時間(Datetime)
因此,下一步是基於上述規範來轉換資料檔案:
daily_train[‘ds’] = daily_train.index
daily_train[‘y’] = daily_train.Count
daily_train.drop([‘Count’],axis = 1, inplace = True)
擬合Prophet模型:
m = Prophet(yearly_seasonality = True, seasonality_prior_scale=0.1)
m.fit(daily_train)
future = m.make_future_dataframe(periods=213)
forecast = m.predict(future)
我們可以透過以下命令來檢視各個成分:
m.plot_components(forecast)
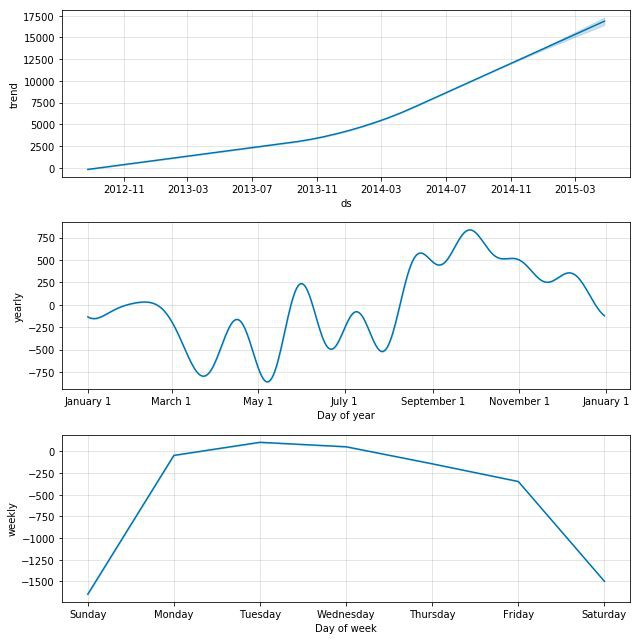
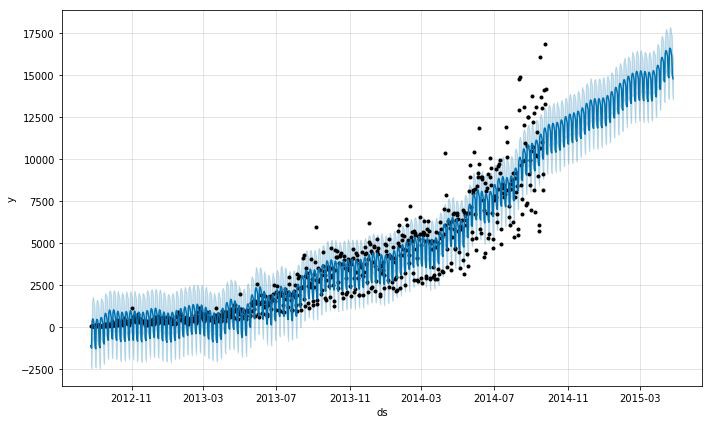
將0到23作為節點均等劃分每小時,接下來我們可以把每日預測轉化為每小時預測。基於每日資料的預測如下。
# Extract hour, day, month and year from both dataframes to merge
for df in [test, forecast]:
df[‘hour’] = df.Datetime.dt.hour
df[‘day’] = df.Datetime.dt.day
df[‘month’] = df.Datetime.dt.month
df[‘year’] = df.Datetime.dt.year
# Merge forecasts with given IDs
test = pd.merge(test,forecast, on=[‘day’,’month’,’year’], how=’left’)
cols = [‘ID’,’hour’,’yhat’]
test_new = test[cols]
# Merging hourly average fraction to the test data
test_new = pd.merge(test_new, hourly_frac, left_on = [‘hour’], right_index=True, how = ‘left’)
# Convert daily aggregate to hourly traffic
test_new[‘Count’] = test_new[‘yhat’] * test_new[‘fraction’]
test_new.drop([‘yhat’,’fraction’,’hour’],axis = 1, inplace = True)
test_new.to_csv(‘prophet_sub.csv’,index = False)
我在公共積分榜上得到了206分,並得到了一個穩定的模型。讀者可以繼續調整超引數(季節性或變化性的傅裡葉階數)以得到更好的分數。讀者也可以嘗試使用不同的方法將每日轉化為每小時的資料,可能會得到更好的分數。
R程式碼實現如下:
應用R解決同樣的問題。
library(prophet)
library(data.table)
library(dplyr)
library(ggplot2)
# read data
train = fread(“Train_SU63ISt.csv”)
test = fread(“Test_0qrQsBZ.csv”)
# Extract date from the Datetime variable
train$Date = as.POSIXct(strptime(train$Datetime, “%d-%m-%Y”))
test$Date = as.POSIXct(strptime(test$Datetime, “%d-%m-%Y”))
# Convert ‘Datetime’ variable from character to date-time format
train$Datetime = as.POSIXct(strptime(train$Datetime, “%d-%m-%Y %H:%M”))
test$Datetime = as.POSIXct(strptime(test$Datetime, “%d-%m-%Y %H:%M”))
# Aggregate train data day-wise
aggr_train = train[,list(Count = sum(Count)), by = Date]
# Visualize the data
ggplot(aggr_train) + geom_line(aes(Date, Count))
# Change column names
names(aggr_train) = c(“ds”, “y”)
# Model building
m = prophet(aggr_train)
future = make_future_dataframe(m, periods = 213)
forecast = predict(m, future)
# Visualize forecast
plot(m, forecast)
# proportion of mean hourly ‘Count’ based on train data
mean_hourly_count = train %>%
group_by(hour = hour(train$Datetime)) %>%
summarise(mean_count = mean(Count))
s = sum(mean_hourly_count$mean_count)
mean_hourly_count$count_proportion = mean_hourly_count$mean_count/s
# variable to store hourly Count
test_count = NULL
for(i in 763:nrow(forecast)){
test_count = append(test_count, mean_hourly_count$count_proportion * forecast$yhat[i])
}
test$Count = test_count
尾記
Prophet確實是進行快速準確的時間序列預測的好選擇。對於具備良好領域知識但是缺少預測模型技能的人來說,Prophet可以讓他們直觀地調整引數。讀者可以直接在Prophet中擬合以小時為單位的資料並且在評論中討論是否能得到更好的結果。
原文標題:Generate Quick and Accurate Time Series Forecasts using Facebook’s Prophet (with Python & R codes)
原文連結:https://www.analyticsvidhya.com/blog/ 2018/05/generate-accurate-forecasts-facebook-prophet-python-r/
譯者簡介:王雨桐,統計學在讀,資料科學碩士預備,跑步不停,彈琴不止。夢想把資料視覺化當作藝術,目前日常是摸著下巴看機器學習。
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
