(點選上方公眾號,可快速關註)
來源:程式設計迷思
www.cnblogs.com/kismetv/p/9236731.html
前言
在前面的兩篇文章中,分別介紹了Redis的記憶體模型和Redis的持久化。
在Redis的持久化中曾提到,Redis高可用的方案包括持久化、主從複製(及讀寫分離)、哨兵和叢集。其中持久化側重解決的是Redis資料的單機備份問題(從記憶體到硬碟的備份);而主從複製則側重解決資料的多機熱備。此外,主從複製還可以實現負載均衡和故障恢復。
這篇文章中,將詳細介紹Redis主從複製的方方面面,包括:如何使用主從複製、主從複製的原理(重點是全量複製和部分複製、以及心跳機制)、實際應用中需要註意的問題(如資料不一致問題、複製超時問題、複製緩衝區上限溢位問題)、主從複製相關的配置(重點是repl-timeout、client-output-buffer-limit slave)等。
一、主從複製概述
主從複製,是指將一臺Redis伺服器的資料,複製到其他的Redis伺服器。前者稱為主節點(master),後者稱為從節點(slave);資料的複製是單向的,只能由主節點到從節點。
預設情況下,每臺Redis伺服器都是主節點;且一個主節點可以有多個從節點(或沒有從節點),但一個從節點只能有一個主節點。
主從複製的作用
主從複製的作用主要包括:
-
資料冗餘:主從複製實現了資料的熱備份,是持久化之外的一種資料冗餘方式。
-
故障恢復:當主節點出現問題時,可以由從節點提供服務,實現快速的故障恢復;實際上是一種服務的冗餘。
-
負載均衡:在主從複製的基礎上,配合讀寫分離,可以由主節點提供寫服務,由從節點提供讀服務(即寫Redis資料時應用連線主節點,讀Redis資料時應用連線從節點),分擔伺服器負載;尤其是在寫少讀多的場景下,透過多個從節點分擔讀負載,可以大大提高Redis伺服器的併發量。
-
高可用基石:除了上述作用以外,主從複製還是哨兵和叢集能夠實施的基礎,因此說主從複製是Redis高可用的基礎。
二、如何使用主從複製
為了更直觀的理解主從複製,在介紹其內部原理之前,先說明我們需要如何操作才能開啟主從複製。
1. 建立複製
需要註意,主從複製的開啟,完全是在從節點發起的;不需要我們在主節點做任何事情。
從節點開啟主從複製,有3種方式:
(1)配置檔案
在從伺服器的配置檔案中加入:slaveof
(2)啟動命令
redis-server啟動命令後加入 –slaveof
(3)客戶端命令
Redis伺服器啟動後,直接透過客戶端執行命令:slaveof
上述3種方式是等效的,下麵以客戶端命令的方式為例,看一下當執行了slaveof後,Redis主節點和從節點的變化。
2. 實體
準備工作:啟動兩個節點
方便起見,實驗所使用的主從節點是在一臺機器上的不同Redis實體,其中主節點監聽6379埠,從節點監聽6380埠;從節點監聽的埠號可以在配置檔案中修改:

啟動後可以看到:

兩個Redis節點啟動後(分別稱為6379節點和6380節點),預設都是主節點。
建立複製
此時在6380節點執行slaveof命令,使之變為從節點:

觀察效果
下麵驗證一下,在主從複製建立後,主節點的資料會複製到從節點中。
(1)首先在從節點查詢一個不存在的key:

(2)然後在主節點中增加這個key:
![]()
(3)此時在從節點中再次查詢這個key,會發現主節點的操作已經同步至從節點:

(4)然後在主節點刪除這個key:

(5)此時在從節點中再次查詢這個key,會發現主節點的操作已經同步至從節點:

3. 斷開複製
透過slaveof
從節點執行slaveof no one後,列印日誌如下所示;可以看出斷開複製後,從節點又變回為主節點。

主節點列印日誌如下:

三、主從複製的實現原理
上面一節中,介紹瞭如何操作可以建立主從關係;本小節將介紹主從複製的實現原理。
主從複製過程大體可以分為3個階段:連線建立階段(即準備階段)、資料同步階段、命令傳播階段;下麵分別進行介紹。
1. 連線建立階段
該階段的主要作用是在主從節點之間建立連線,為資料同步做好準備。
步驟1:儲存主節點資訊
從節點伺服器內部維護了兩個欄位,即masterhost和masterport欄位,用於儲存主節點的ip和port資訊。
需要註意的是,slaveof是非同步命令,從節點完成主節點ip和port的儲存後,向傳送slaveof命令的客戶端直接傳回OK,實際的複製操作在這之後才開始進行。
這個過程中,可以看到從節點列印日誌如下:

步驟2:建立socket連線
從節點每秒1次呼叫複製定時函式replicationCron(),如果發現了有主節點可以連線,便會根據主節點的ip和port,建立socket連線。如果連線成功,則:
從節點:為該socket建立一個專門處理複製工作的檔案事件處理器,負責後續的複製工作,如接收RDB檔案、接收命令傳播等。
主節點:接收到從節點的socket連線後(即accept之後),為該socket建立相應的客戶端狀態,並將從節點看做是連線到主節點的一個客戶端,後面的步驟會以從節點向主節點傳送命令請求的形式來進行。
這個過程中,從節點列印日誌如下:

步驟3:傳送ping命令
從節點成為主節點的客戶端之後,傳送ping命令進行首次請求,目的是:檢查socket連線是否可用,以及主節點當前是否能夠處理請求。
從節點傳送ping命令後,可能出現3種情況:
(1)傳回pong:說明socket連線正常,且主節點當前可以處理請求,複製過程繼續。
(2)超時:一定時間後從節點仍未收到主節點的回覆,說明socket連線不可用,則從節點斷開socket連線,並重連。
(3)傳回pong以外的結果:如果主節點傳回其他結果,如正在處理超時執行的指令碼,說明主節點當前無法處理命令,則從節點斷開socket連線,並重連。
在主節點傳回pong情況下,從節點列印日誌如下:

步驟4:身份驗證
如果從節點中設定了masterauth選項,則從節點需要向主節點進行身份驗證;沒有設定該選項,則不需要驗證。從節點進行身份驗證是透過向主節點傳送auth命令進行的,auth命令的引數即為配置檔案中的masterauth的值。
如果主節點設定密碼的狀態,與從節點masterauth的狀態一致(一致是指都存在,且密碼相同,或者都不存在),則身份驗證透過,複製過程繼續;如果不一致,則從節點斷開socket連線,並重連。
步驟5:傳送從節點埠資訊
身份驗證之後,從節點會向主節點傳送其監聽的埠號(前述例子中為6380),主節點將該資訊儲存到該從節點對應的客戶端的slave_listening_port欄位中;該埠資訊除了在主節點中執行info Replication時顯示以外,沒有其他作用。
2. 資料同步階段
主從節點之間的連線建立以後,便可以開始進行資料同步,該階段可以理解為從節點資料的初始化。具體執行的方式是:從節點向主節點傳送psync命令(Redis2.8以前是sync命令),開始同步。
資料同步階段是主從複製最核心的階段,根據主從節點當前狀態的不同,可以分為全量複製和部分複製,下麵會有一章專門講解這兩種複製方式以及psync命令的執行過程,這裡不再詳述。
需要註意的是,在資料同步階段之前,從節點是主節點的客戶端,主節點不是從節點的客戶端;而到了這一階段及以後,主從節點互為客戶端。原因在於:在此之前,主節點只需要響應從節點的請求即可,不需要主動發請求,而在資料同步階段和後面的命令傳播階段,主節點需要主動向從節點傳送請求(如推送緩衝區中的寫命令),才能完成複製。
3. 命令傳播階段
資料同步階段完成後,主從節點進入命令傳播階段;在這個階段主節點將自己執行的寫命令傳送給從節點,從節點接收命令並執行,從而保證主從節點資料的一致性。
在命令傳播階段,除了傳送寫命令,主從節點還維持著心跳機制:PING和REPLCONF ACK。由於心跳機制的原理涉及部分複製,因此將在介紹了部分複製的相關內容後單獨介紹該心跳機制。
延遲與不一致
需要註意的是,命令傳播是非同步的過程,即主節點傳送寫命令後並不會等待從節點的回覆;因此實際上主從節點之間很難保持實時的一致性,延遲在所難免。資料不一致的程度,與主從節點之間的網路狀況、主節點寫命令的執行頻率、以及主節點中的repl-disable-tcp-nodelay配置等有關。
repl-disable-tcp-nodelay no:該配置作用於命令傳播階段,控制主節點是否禁止與從節點的TCP_NODELAY;預設no,即不禁止TCP_NODELAY。當設定為yes時,TCP會對包進行合併從而減少頻寬,但是傳送的頻率會降低,從節點資料延遲增加,一致性變差;具體傳送頻率與Linux內核的配置有關,預設配置為40ms。當設定為no時,TCP會立馬將主節點的資料傳送給從節點,頻寬增加但延遲變小。
一般來說,只有當應用對Redis資料不一致的容忍度較高,且主從節點之間網路狀況不好時,才會設定為yes;多數情況使用預設值no。
四、【資料同步階段】全量複製和部分複製
在Redis2.8以前,從節點向主節點傳送sync命令請求同步資料,此時的同步方式是全量複製;在Redis2.8及以後,從節點可以傳送psync命令請求同步資料,此時根據主從節點當前狀態的不同,同步方式可能是全量複製或部分複製。後文介紹以Redis2.8及以後版本為例。
-
全量複製:用於初次複製或其他無法進行部分複製的情況,將主節點中的所有資料都傳送給從節點,是一個非常重型的操作。
-
部分複製:用於網路中斷等情況後的複製,只將中斷期間主節點執行的寫命令傳送給從節點,與全量複製相比更加高效。需要註意的是,如果網路中斷時間過長,導致主節點沒有能夠完整地儲存中斷期間執行的寫命令,則無法進行部分複製,仍使用全量複製。
1. 全量複製
Redis透過psync命令進行全量複製的過程如下:
(1)從節點判斷無法進行部分複製,向主節點傳送全量複製的請求;或從節點傳送部分複製的請求,但主節點判斷無法進行全量複製;具體判斷過程需要在講述了部分複製原理後再介紹。
(2)主節點收到全量複製的命令後,執行bgsave,在後臺生成RDB檔案,並使用一個緩衝區(稱為複製緩衝區)記錄從現在開始執行的所有寫命令
(3)主節點的bgsave執行完成後,將RDB檔案傳送給從節點;從節點首先清除自己的舊資料,然後載入接收的RDB檔案,將資料庫狀態更新至主節點執行bgsave時的資料庫狀態
(4)主節點將前述複製緩衝區中的所有寫命令傳送給從節點,從節點執行這些寫命令,將資料庫狀態更新至主節點的最新狀態
(5)如果從節點開啟了AOF,則會觸發bgrewriteaof的執行,從而保證AOF檔案更新至主節點的最新狀態
下麵是執行全量複製時,主從節點列印的日誌;可以看出日誌內容與上述步驟是完全對應的。
主節點的列印日誌如下:

從節點列印日誌如下圖所示:

其中,有幾點需要註意:從節點接收了來自主節點的89260個位元組的資料;從節點在載入主節點的資料之前要先將老資料清除;從節點在同步完資料後,呼叫了bgrewriteaof。
透過全量複製的過程可以看出,全量複製是非常重型的操作:
(1)主節點透過bgsave命令fork子行程進行RDB持久化,該過程是非常消耗CPU、記憶體(頁表複製)、硬碟IO的;關於bgsave的效能問題,可以參考 深入學習Redis(2):持久化
(2)主節點透過網路將RDB檔案傳送給從節點,對主從節點的頻寬都會帶來很大的消耗
(3)從節點清空老資料、載入新RDB檔案的過程是阻塞的,無法響應客戶端的命令;如果從節點執行bgrewriteaof,也會帶來額外的消耗
2. 部分複製
由於全量複製在主節點資料量較大時效率太低,因此Redis2.8開始提供部分複製,用於處理網路中斷時的資料同步。
部分複製的實現,依賴於三個重要的概念:
(1)複製偏移量
主節點和從節點分別維護一個複製偏移量(offset),代表的是主節點向從節點傳遞的位元組數;主節點每次向從節點傳播N個位元組資料時,主節點的offset增加N;從節點每次收到主節點傳來的N個位元組資料時,從節點的offset增加N。
offset用於判斷主從節點的資料庫狀態是否一致:如果二者offset相同,則一致;如果offset不同,則不一致,此時可以根據兩個offset找出從節點缺少的那部分資料。例如,如果主節點的offset是1000,而從節點的offset是500,那麼部分複製就需要將offset為501-1000的資料傳遞給從節點。而offset為501-1000的資料儲存的位置,就是下麵要介紹的複製積壓緩衝區。
(2)複製積壓緩衝區
複製積壓緩衝區是由主節點維護的、固定長度的、先進先出(FIFO)佇列,預設大小1MB;當主節點開始有從節點時建立,其作用是備份主節點最近傳送給從節點的資料。註意,無論主節點有一個還是多個從節點,都只需要一個複製積壓緩衝區。
在命令傳播階段,主節點除了將寫命令傳送給從節點,還會傳送一份給複製積壓緩衝區,作為寫命令的備份;除了儲存寫命令,複製積壓緩衝區中還儲存了其中的每個位元組對應的複製偏移量(offset)。由於複製積壓緩衝區定長且是先進先出,所以它儲存的是主節點最近執行的寫命令;時間較早的寫命令會被擠出緩衝區。
由於該緩衝區長度固定且有限,因此可以備份的寫命令也有限,當主從節點offset的差距過大超過緩衝區長度時,將無法執行部分複製,只能執行全量複製。反過來說,為了提高網路中斷時部分複製執行的機率,可以根據需要增大複製積壓緩衝區的大小(透過配置repl-backlog-size);例如如果網路中斷的平均時間是60s,而主節點平均每秒產生的寫命令(特定協議格式)所佔的位元組數為100KB,則複製積壓緩衝區的平均需求為6MB,保險起見,可以設定為12MB,來保證絕大多數斷線情況都可以使用部分複製。
從節點將offset傳送給主節點後,主節點根據offset和緩衝區大小決定能否執行部分複製:
-
如果offset偏移量之後的資料,仍然都在複製積壓緩衝區裡,則執行部分複製;
-
如果offset偏移量之後的資料已不在複製積壓緩衝區中(資料已被擠出),則執行全量複製。
(3)伺服器執行ID(runid)
每個Redis節點(無論主從),在啟動時都會自動生成一個隨機ID(每次啟動都不一樣),由40個隨機的十六進位制字元組成;runid用來唯一識別一個Redis節點。透過info Server命令,可以檢視節點的runid:

主從節點初次複製時,主節點將自己的runid傳送給從節點,從節點將這個runid儲存起來;當斷線重連時,從節點會將這個runid傳送給主節點;主節點根據runid判斷能否進行部分複製:
-
如果從節點儲存的runid與主節點現在的runid相同,說明主從節點之前同步過,主節點會繼續嘗試使用部分複製(到底能不能部分複製還要看offset和複製積壓緩衝區的情況);
-
如果從節點儲存的runid與主節點現在的runid不同,說明從節點在斷線前同步的Redis節點並不是當前的主節點,只能進行全量複製。
3. psync命令的執行
在瞭解了複製偏移量、複製積壓緩衝區、節點執行id之後,本節將介紹psync命令的引數和傳回值,從而說明psync命令執行過程中,主從節點是如何確定使用全量複製還是部分複製的。
psync命令的執行過程可以參見下圖(圖片來源:《Redis設計與實現》):
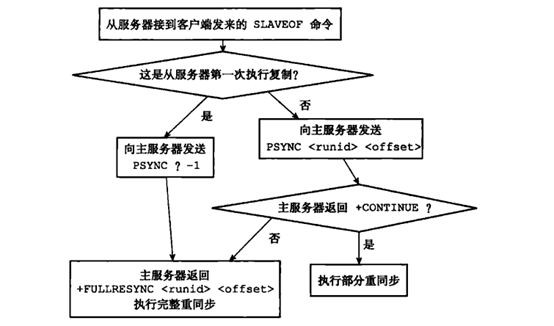
(1)首先,從節點根據當前狀態,決定如何呼叫psync命令:
-
如果從節點之前未執行過slaveof或最近執行了slaveof no one,則從節點傳送命令為psync ? -1,向主節點請求全量複製;
-
如果從節點之前執行了slaveof,則傳送命令為psync
,其中runid為上次複製的主節點的runid,offset為上次複製截止時從節點儲存的複製偏移量。
(2)主節點根據收到的psync命令,及當前伺服器狀態,決定執行全量複製還是部分複製:
-
如果主節點版本低於Redis2.8,則傳回-ERR回覆,此時從節點重新傳送sync命令執行全量複製;
-
如果主節點版本夠新,且runid與從節點傳送的runid相同,且從節點傳送的offset之後的資料在複製積壓緩衝區中都存在,則回覆+CONTINUE,表示將進行部分複製,從節點等待主節點傳送其缺少的資料即可;
-
如果主節點版本夠新,但是runid與從節點傳送的runid不同,或從節點傳送的offset之後的資料已不在複製積壓緩衝區中(在佇列中被擠出了),則回覆+FULLRESYNC
,表示要進行全量複製,其中runid表示主節點當前的runid,offset表示主節點當前的offset,從節點儲存這兩個值,以備使用。
4. 部分複製演示
在下麵的演示中,網路中斷幾分鐘後恢復,斷開連線的主從節點進行了部分複製;為了便於模擬網路中斷,本例中的主從節點在區域網中的兩臺機器上。
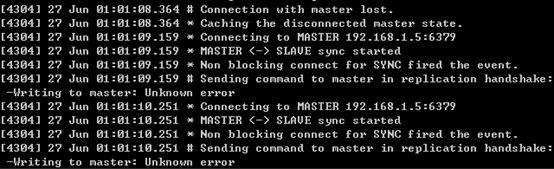
網路中斷
網路中斷一段時間後,主節點和從節點都會發現失去了與對方的連線(關於主從節點對超時的判斷機制,後面會有說明);此後,從節點便開始執行對主節點的重連,由於此時網路還沒有恢復,重連失敗,從節點會一直嘗試重連。
主節點日誌如下:

從節點日誌如下:
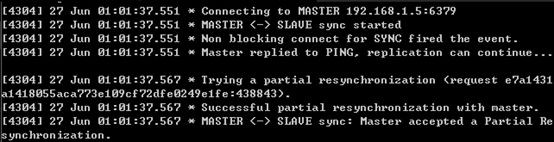
網路恢復
網路恢復後,從節點連線主節點成功,並請求進行部分複製,主節點接收請求後,二者進行部分複製以同步資料。
主節點日誌如下:

從節點日誌如下:
五、【命令傳播階段】心跳機制
在命令傳播階段,除了傳送寫命令,主從節點還維持著心跳機制:PING和REPLCONF ACK。心跳機制對於主從複製的超時判斷、資料安全等有作用。
1.主->從:PING
每隔指定的時間,主節點會向從節點傳送PING命令,這個PING命令的作用,主要是為了讓從節點進行超時判斷。
PING傳送的頻率由repl-ping-slave-period引數控制,單位是秒,預設值是10s。
關於該PING命令究竟是由主節點發給從節點,還是相反,有一些爭議;因為在Redis的官方檔案中,對該引數的註釋中說明是從節點向主節點傳送PING命令,如下圖所示:

但是根據該引數的名稱(含有ping-slave),以及程式碼實現,我認為該PING命令是主節點發給從節點的。相關程式碼如下:
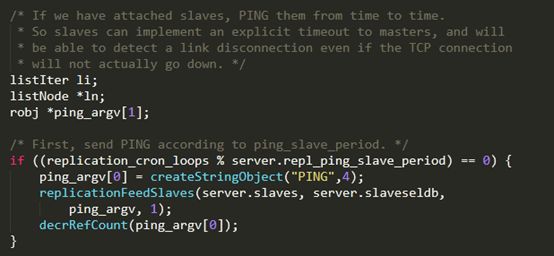
2. 從->主:REPLCONF ACK
在命令傳播階段,從節點會向主節點傳送REPLCONF ACK命令,頻率是每秒1次;命令格式為:REPLCONF ACK {offset},其中offset指從節點儲存的複製偏移量。REPLCONF ACK命令的作用包括:
(1)實時監測主從節點網路狀態:該命令會被主節點用於複製超時的判斷。此外,在主節點中使用info Replication,可以看到其從節點的狀態中的lag值,代表的是主節點上次收到該REPLCONF ACK命令的時間間隔,在正常情況下,該值應該是0或1,如下圖所示:

(2)檢測命令丟失:從節點發送了自身的offset,主節點會與自己的offset對比,如果從節點資料缺失(如網路丟包),主節點會推送缺失的資料(這裡也會利用複製積壓緩衝區)。註意,offset和複製積壓緩衝區,不僅可以用於部分複製,也可以用於處理命令丟失等情形;區別在於前者是在斷線重連後進行的,而後者是在主從節點沒有斷線的情況下進行的。
(3)輔助保證從節點的數量和延遲:Redis主節點中使用min-slaves-to-write和min-slaves-max-lag引數,來保證主節點在不安全的情況下不會執行寫命令;所謂不安全,是指從節點數量太少,或延遲過高。例如min-slaves-to-write和min-slaves-max-lag分別是3和10,含義是如果從節點數量小於3個,或所有從節點的延遲值都大於10s,則主節點拒絕執行寫命令。而這裡從節點延遲值的獲取,就是透過主節點接收到REPLCONF ACK命令的時間來判斷的,即前面所說的info Replication中的lag值。
六、應用中的問題
1. 讀寫分離及其中的問題
在主從複製基礎上實現的讀寫分離,可以實現Redis的讀負載均衡:由主節點提供寫服務,由一個或多個從節點提供讀服務(多個從節點既可以提高資料冗餘程度,也可以最大化讀負載能力);在讀負載較大的應用場景下,可以大大提高Redis伺服器的併發量。下麵介紹在使用Redis讀寫分離時,需要註意的問題。
(1)延遲與不一致問題
前面已經講到,由於主從複製的命令傳播是非同步的,延遲與資料的不一致不可避免。如果應用對資料不一致的接受程度程度較低,可能的最佳化措施包括:最佳化主從節點之間的網路環境(如在同機房部署);監控主從節點延遲(透過offset)判斷,如果從節點延遲過大,通知應用不再透過該從節點讀取資料;使用叢集同時擴充套件寫負載和讀負載等。
在命令傳播階段以外的其他情況下,從節點的資料不一致可能更加嚴重,例如連線在資料同步階段,或從節點失去與主節點的連線時等。從節點的slave-serve-stale-data引數便與此有關:它控制這種情況下從節點的表現;如果為yes(預設值),則從節點仍能夠響應客戶端的命令,如果為no,則從節點只能響應info、slaveof等少數命令。該引數的設定與應用對資料一致性的要求有關;如果對資料一致性要求很高,則應設定為no。
(2)資料過期問題
在單機版Redis中,存在兩種刪除策略:
-
惰性刪除:伺服器不會主動刪除資料,只有當客戶端查詢某個資料時,伺服器判斷該資料是否過期,如果過期則刪除。
-
定期刪除:伺服器執行定時任務刪除過期資料,但是考慮到記憶體和CPU的折中(刪除會釋放記憶體,但是頻繁的刪除操作對CPU不友好),該刪除的頻率和執行時間都受到了限制。
在主從複製場景下,為了主從節點的資料一致性,從節點不會主動刪除資料,而是由主節點控制從節點中過期資料的刪除。由於主節點的惰性刪除和定期刪除策略,都不能保證主節點及時對過期資料執行刪除操作,因此,當客戶端透過Redis從節點讀取資料時,很容易讀取到已經過期的資料。
Redis 3.2中,從節點在讀取資料時,增加了對資料是否過期的判斷:如果該資料已過期,則不傳回給客戶端;將Redis升級到3.2可以解決資料過期問題。
(3)故障切換問題
在沒有使用哨兵的讀寫分離場景下,應用針對讀和寫分別連線不同的Redis節點;當主節點或從節點出現問題而發生更改時,需要及時修改應用程式讀寫Redis資料的連線;連線的切換可以手動進行,或者自己寫監控程式進行切換,但前者響應慢、容易出錯,後者實現複雜,成本都不算低。
(4)總結
在使用讀寫分離之前,可以考慮其他方法增加Redis的讀負載能力:如儘量最佳化主節點(減少慢查詢、減少持久化等其他情況帶來的阻塞等)提高負載能力;使用Redis叢集同時提高讀負載能力和寫負載能力等。如果使用讀寫分離,可以使用哨兵,使主從節點的故障切換盡可能自動化,並減少對應用程式的侵入。
2. 複製超時問題
主從節點複製超時是導致複製中斷的最重要的原因之一,本小節單獨說明超時問題,下一小節說明其他會導致複製中斷的問題。
超時判斷意義
在複製連線建立過程中及之後,主從節點都有機制判斷連線是否超時,其意義在於:
(1)如果主節點判斷連線超時,其會釋放相應從節點的連線,從而釋放各種資源,否則無效的從節點仍會佔用主節點的各種資源(輸出緩衝區、頻寬、連線等);此外連線超時的判斷可以讓主節點更準確的知道當前有效從節點的個數,有助於保證資料安全(配合前面講到的min-slaves-to-write等引數)。
(2)如果從節點判斷連線超時,則可以及時重新建立連線,避免與主節點資料長期的不一致。
判斷機制
主從複製超時判斷的核心,在於repl-timeout引數,該引數規定了超時時間的閾值(預設60s),對於主節點和從節點同時有效;主從節點觸發超時的條件分別如下:
(1)主節點:每秒1次呼叫複製定時函式replicationCron(),在其中判斷當前時間距離上次收到各個從節點REPLCONF ACK的時間,是否超過了repl-timeout值,如果超過了則釋放相應從節點的連線。
(2)從節點:從節點對超時的判斷同樣是在複製定時函式中判斷,基本邏輯是:
-
如果當前處於連線建立階段,且距離上次收到主節點的資訊的時間已超過repl-timeout,則釋放與主節點的連線;
-
如果當前處於資料同步階段,且收到主節點的RDB檔案的時間超時,則停止資料同步,釋放連線;
-
如果當前處於命令傳播階段,且距離上次收到主節點的PING命令或資料的時間已超過repl-timeout值,則釋放與主節點的連線。
主從節點判斷連線超時的相關原始碼如下:
/* Replication cron function, called 1 time per second. */
void replicationCron(void) {
static long long replication_cron_loops = 0;
/* Non blocking connection timeout? */
if (server.masterhost &&
(server.repl_state == REDIS_REPL_CONNECTING ||
slaveIsInHandshakeState()) &&
(time(NULL)–server.repl_transfer_lastio) > server.repl_timeout)
{
redisLog(REDIS_WARNING,“Timeout connecting to the MASTER…”);
undoConnectWithMaster();
}
/* Bulk transfer I/O timeout? */
if (server.masterhost && server.repl_state == REDIS_REPL_TRANSFER &&
(time(NULL)–server.repl_transfer_lastio) > server.repl_timeout)
{
redisLog(REDIS_WARNING,“Timeout receiving bulk data from MASTER… If the problem persists try to set the ‘repl-timeout’ parameter in redis.conf to a larger value.”);
replicationAbortSyncTransfer();
}
/* Timed out master when we are an already connected slave? */
if (server.masterhost && server.repl_state == REDIS_REPL_CONNECTED &&
(time(NULL)–server.master->lastinteraction) > server.repl_timeout)
{
redisLog(REDIS_WARNING,“MASTER timeout: no data nor PING received…”);
freeClient(server.master);
}
//此處省略無關程式碼……
/* Disconnect timedout slaves. */
if (listLength(server.slaves)) {
listIter li;
listNode *ln;
listRewind(server.slaves,&li);
while((ln = listNext(&li))) {
redisClient *slave = ln->value;
if (slave->replstate != REDIS_REPL_ONLINE) continue;
if (slave->flags & REDIS_PRE_PSYNC) continue;
if ((server.unixtime – slave->repl_ack_time) > server.repl_timeout)
{
redisLog(REDIS_WARNING, “Disconnecting timedout slave: %s”,
replicationGetSlaveName(slave));
freeClient(slave);
}
}
}
//此處省略無關程式碼……
}
需要註意的坑
下麵介紹與複製階段連線超時有關的一些實際問題:
(1)資料同步階段:在主從節點進行全量複製bgsave時,主節點需要首先fork子行程將當前資料儲存到RDB檔案中,然後再將RDB檔案透過網路傳輸到從節點。如果RDB檔案過大,主節點在fork子行程+儲存RDB檔案時耗時過多,可能會導致從節點長時間收不到資料而觸發超時;此時從節點會重連主節點,然後再次全量複製,再次超時,再次重連……這是個悲傷的迴圈。為了避免這種情況的發生,除了註意Redis單機資料量不要過大,另一方面就是適當增大repl-timeout值,具體的大小可以根據bgsave耗時來調整。
(2)命令傳播階段:如前所述,在該階段主節點會向從節點傳送PING命令,頻率由repl-ping-slave-period控制;該引數應明顯小於repl-timeout值(後者至少是前者的幾倍)。否則,如果兩個引數相等或接近,網路抖動導致個別PING命令丟失,此時恰巧主節點也沒有向從節點傳送資料,則從節點很容易判斷超時。
(3)慢查詢導致的阻塞:如果主節點或從節點執行了一些慢查詢(如keys *或者對大資料的hgetall等),導致伺服器阻塞;阻塞期間無法響應複製連線中對方節點的請求,可能導致複製超時。
3. 複製中斷問題
主從節點超時是複製中斷的原因之一,除此之外,還有其他情況可能導致複製中斷,其中最主要的是複製緩衝區上限溢位問題。
複製緩衝區上限溢位
前面曾提到過,在全量複製階段,主節點會將執行的寫命令放到複製緩衝區中,該緩衝區存放的資料包括了以下幾個時間段內主節點執行的寫命令:bgsave生成RDB檔案、RDB檔案由主節點發往從節點、從節點清空老資料並載入RDB檔案中的資料。當主節點資料量較大,或者主從節點之間網路延遲較大時,可能導致該緩衝區的大小超過了限制,此時主節點會斷開與從節點之間的連線;這種情況可能引起全量複製->複製緩衝區上限溢位導致連線中斷->重連->全量複製->複製緩衝區上限溢位導致連線中斷……的迴圈。
複製緩衝區的大小由client-output-buffer-limit slave {hard limit} {soft limit} {soft seconds}配置,預設值為client-output-buffer-limit slave 256MB 64MB 60,其含義是:如果buffer大於256MB,或者連續60s大於64MB,則主節點會斷開與該從節點的連線。該引數是可以透過config set命令動態配置的(即不重啟Redis也可以生效)。
當複製緩衝區上限溢位時,主節點列印日誌如下所示:

需要註意的是,複製緩衝區是客戶端輸出緩衝區的一種,主節點會為每一個從節點分別分配複製緩衝區;而複製積壓緩衝區則是一個主節點只有一個,無論它有多少個從節點。
4. 各場景下複製的選擇及最佳化技巧
在介紹了Redis複製的種種細節之後,現在我們可以來總結一下,在下麵常見的場景中,何時使用部分複製,以及需要註意哪些問題。
(1)第一次建立複製
此時全量複製不可避免,但仍有幾點需要註意:如果主節點的資料量較大,應該儘量避開流量的高峰期,避免造成阻塞;如果有多個從節點需要建立對主節點的複製,可以考慮將幾個從節點錯開,避免主節點頻寬佔用過大。此外,如果從節點過多,也可以調整主從複製的拓撲結構,由一主多從結構變為樹狀結構(中間的節點既是其主節點的從節點,也是其從節點的主節點);但使用樹狀結構應該謹慎:雖然主節點的直接從節點減少,降低了主節點的負擔,但是多層從節點的延遲增大,資料一致性變差;且結構複雜,維護相當困難。
(2)主節點重啟
主節點重啟可以分為兩種情況來討論,一種是故障導致宕機,另一種則是有計劃的重啟。
主節點宕機
主節點宕機重啟後,runid會發生變化,因此不能進行部分複製,只能全量複製。
實際上在主節點宕機的情況下,應進行故障轉移處理,將其中的一個從節點升級為主節點,其他從節點從新的主節點進行複製;且故障轉移應儘量的自動化,後面文章將要介紹的哨兵便可以進行自動的故障轉移。
安全重啟:debug reload
在一些場景下,可能希望對主節點進行重啟,例如主節點記憶體碎片率過高,或者希望調整一些只能在啟動時調整的引數。如果使用普通的手段重啟主節點,會使得runid發生變化,可能導致不必要的全量複製。
為瞭解決這個問題,Redis提供了debug reload的重啟方式:重啟後,主節點的runid和offset都不受影響,避免了全量複製。
如下圖所示,debug reload重啟後runid和offset都未受影響:
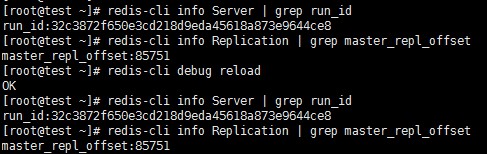
但debug reload是一柄雙刃劍:它會清空當前記憶體中的資料,重新從RDB檔案中載入,這個過程會導致主節點的阻塞,因此也需要謹慎。
(3)從節點重啟
從節點宕機重啟後,其儲存的主節點的runid會丟失,因此即使再次執行slaveof,也無法進行部分複製。
(4)網路中斷
如果主從節點之間出現網路問題,造成短時間內網路中斷,可以分為多種情況討論。
第一種情況:網路問題時間極為短暫,只造成了短暫的丟包,主從節點都沒有判定超時(未觸發repl-timeout);此時只需要透過REPLCONF ACK來補充丟失的資料即可。
第二種情況:網路問題時間很長,主從節點判斷超時(觸發了repl-timeout),且丟失的資料過多,超過了複製積壓緩衝區所能儲存的範圍;此時主從節點無法進行部分複製,只能進行全量複製。為了盡可能避免這種情況的發生,應該根據實際情況適當調整複製積壓緩衝區的大小;此外及時發現並修複網路中斷,也可以減少全量複製。
第三種情況:介於前述兩種情況之間,主從節點判斷超時,且丟失的資料仍然都在複製積壓緩衝區中;此時主從節點可以進行部分複製。
5. 複製相關的配置
這一節總結一下與複製有關的配置,說明這些配置的作用、起作用的階段,以及配置方法等;透過瞭解這些配置,一方面加深對Redis複製的瞭解,另一方面掌握這些配置的方法,可以最佳化Redis的使用,少走坑。
配置大致可以分為主節點相關配置、從節點相關配置以及與主從節點都有關的配置,下麵分別說明。
(1)與主從節點都有關的配置
首先介紹最特殊的配置,它決定了該節點是主節點還是從節點:
1) slaveof
2) repl-timeout 60:與各個階段主從節點連線超時判斷有關,見前面的介紹。
(2)主節點相關配置
1) repl-diskless-sync no:作用於全量複製階段,控制主節點是否使用diskless複製(無盤複製)。所謂diskless複製,是指在全量複製時,主節點不再先把資料寫入RDB檔案,而是直接寫入slave的socket中,整個過程中不涉及硬碟;diskless複製在磁碟IO很慢而網速很快時更有優勢。需要註意的是,截至Redis3.0,diskless複製處於實驗階段,預設是關閉的。
2) repl-diskless-sync-delay 5:該配置作用於全量複製階段,當主節點使用diskless複製時,該配置決定主節點向從節點傳送之前停頓的時間,單位是秒;只有當diskless複製開啟時有效,預設5s。之所以設定停頓時間,是基於以下兩個考慮:(1)向slave的socket的傳輸一旦開始,新連線的slave只能等待當前資料傳輸結束,才能開始新的資料傳輸 (2)多個從節點有較大的機率在短時間內建立主從複製。
3) client-output-buffer-limit slave 256MB 64MB 60:與全量複製階段主節點的緩衝區大小有關,見前面的介紹。
4) repl-disable-tcp-nodelay no:與命令傳播階段的延遲有關,見前面的介紹。
5) masterauth
6) repl-ping-slave-period 10:與命令傳播階段主從節點的超時判斷有關,見前面的介紹。
7) repl-backlog-size 1mb:複製積壓緩衝區的大小,見前面的介紹。
8) repl-backlog-ttl 3600:當主節點沒有從節點時,複製積壓緩衝區保留的時間,這樣當斷開的從節點重新連進來時,可以進行全量複製;預設3600s。如果設定為0,則永遠不會釋放複製積壓緩衝區。
9) min-slaves-to-write 3與min-slaves-max-lag 10:規定了主節點的最小從節點數目,及對應的最大延遲,見前面的介紹。
(3)從節點相關配置
1) slave-serve-stale-data yes:與從節點資料陳舊時是否響應客戶端命令有關,見前面的介紹。
2) slave-read-only yes:從節點是否只讀;預設是隻讀的。由於從節點開啟寫操作容易導致主從節點的資料不一致,因此該配置儘量不要修改。
6. 單機記憶體大小限制
在 深入學習Redis(2):持久化 一文中,講到了fork操作對Redis單機記憶體大小的限制。實際上在Redis的使用中,限制單機記憶體大小的因素非常之多,下麵總結一下在主從複製中,單機記憶體過大可能造成的影響:
(1)切主:當主節點宕機時,一種常見的容災策略是將其中一個從節點提升為主節點,並將其他從節點掛載到新的主節點上,此時這些從節點只能進行全量複製;如果Redis單機記憶體達到10GB,一個從節點的同步時間在幾分鐘的級別;如果從節點較多,恢復的速度會更慢。如果系統的讀負載很高,而這段時間從節點無法提供服務,會對系統造成很大的壓力。
(2)從庫擴容:如果訪問量突然增大,此時希望增加從節點分擔讀負載,如果資料量過大,從節點同步太慢,難以及時應對訪問量的暴增。
(3)緩衝區上限溢位:(1)和(2)都是從節點可以正常同步的情形(雖然慢),但是如果資料量過大,導致全量複製階段主節點的複製緩衝區上限溢位,從而導致複製中斷,則主從節點的資料同步會全量複製->複製緩衝區上限溢位導致複製中斷->重連->全量複製->複製緩衝區上限溢位導致複製中斷……的迴圈。
(4)超時:如果資料量過大,全量複製階段主節點fork+儲存RDB檔案耗時過大,從節點長時間接收不到資料觸發超時,主從節點的資料同步同樣可能陷入全量複製->超時導致複製中斷->重連->全量複製->超時導致複製中斷……的迴圈。
此外,主節點單機記憶體除了絕對量不能太大,其佔用主機記憶體的比例也不應過大:最好只使用50%-65%的記憶體,留下30%-45%的記憶體用於執行bgsave命令和建立複製緩衝區等。
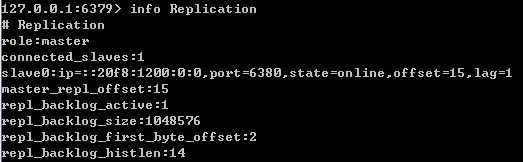
7. info Replication
在Redis客戶端透過info Replication可以檢視與複製相關的狀態,對於瞭解主從節點的當前狀態,以及解決出現的問題都會有幫助。
主節點:
從節點:
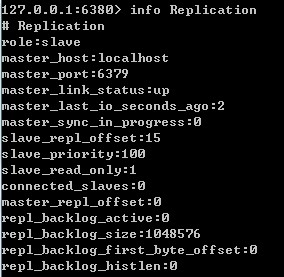
對於從節點,上半部分展示的是其作為從節點的狀態,從connectd_slaves開始,展示的是其作為潛在的主節點的狀態。
info Replication中展示的大部分內容在文章中都已經講述,這裡不再詳述。
七、總結
下麵回顧一下本文的主要內容:
1、主從複製的作用:宏觀的瞭解主從複製是為瞭解決什麼樣的問題,即資料冗餘、故障恢復、讀負載均衡等。
2、主從複製的操作:即slaveof命令。
3、主從複製的原理:主從複製包括了連線建立階段、資料同步階段、命令傳播階段;其中資料同步階段,有全量複製和部分複製兩種資料同步方式;命令傳播階段,主從節點之間有PING和REPLCONF ACK命令互相進行心跳檢測。
4、應用中的問題:包括讀寫分離的問題(資料不一致問題、資料過期問題、故障切換問題等)、複製超時問題、複製中斷問題等,然後總結了主從複製相關的配置,其中repl-timeout、client-output-buffer-limit slave等對解決Redis主從複製中出現的問題可能會有幫助。
主從複製雖然解決或緩解了資料冗餘、故障恢復、讀負載均衡等問題,但其缺陷仍很明顯:故障恢復無法自動化;寫操作無法負載均衡;儲存能力受到單機的限制;這些問題的解決,需要哨兵和叢集的幫助,我將在後面的文章中介紹,歡迎關註。
系列回顧
看完本文有收穫?請轉發分享給更多人
關註「資料分析與開發」,提升資料技能

