公司內部的業務系統有近千個,基本上很少有比較孤立的;尤其外部系統,即便使用者在頁面上一個很普通的操作,後臺也需要少則幾個多則幾十個服務協同完成。以前我們定位呼叫鏈上的問題方式,基本上都是叫上呼叫鏈上所有對服務比較熟悉的技術人員,定位問題費時費力;由此,我們團隊決定引入一套全鏈路跟蹤中介軟體產品。
起初,我們全面調研了社群很多比較成熟的產品之後,發現這些產品與我們公司現存場景多有不符的地方,主要的一點就是我們公司內部應用之間通訊方式的多樣化。各業務部門之間技術棧極不統一,各業務部門內部的應用之間以及各業務部門應用之間的通訊方式自然也多種多樣,公開服務的方式包括:REST、RabbitMQ、Dubbo、RMI、Zookeeper等,呼叫服務的方式包括:OkHttp 2.x、OkHttp 3.x 、Apache HttpClient、Spring RestTemplate、RabbitMQ、Dubbo、RMI、Zookeeper等。我們在自研這套產品過程中,首先參考了谷歌公開的《Dapper大規模分散式系統的跟蹤系統》這篇論文,借鑒了社群類似產品的很多思路和理念,像Twitter的Zipkin、阿裡的鷹眼、去哪兒網的QTracer、GitHub上開源的PinPoint等產品。
設計標的是企業的設計部門根據設計戰略的要求組織各項設計活動預期取得的成果。在產品設計之初,我們就參考了谷歌公開的《Dapper大規模分散式系統的跟蹤系統》論文及我們的實際業務場景,制定瞭如下設計標的:
-
低消耗:全鏈路跟蹤中介軟體在接入後應該做到對線上服務的影響足夠小,甚至可以忽略不計;
-
低侵入:不應該讓各線上服務顯示感受到跟蹤API的存在,至少不應該顯示侵入業務程式碼內部,也就是不能出現在類中的import處;
-
可開關:全鏈路跟蹤中介軟體的呼叫鏈引數傳遞及日誌落地時機要做到線上開關,以避免重大Bug影響線上服務;
-
延展性:全鏈路跟蹤中介軟體至少在未來幾年的服務體量和叢集規模都應該能完全把控住,主要針對的是儲存元件。
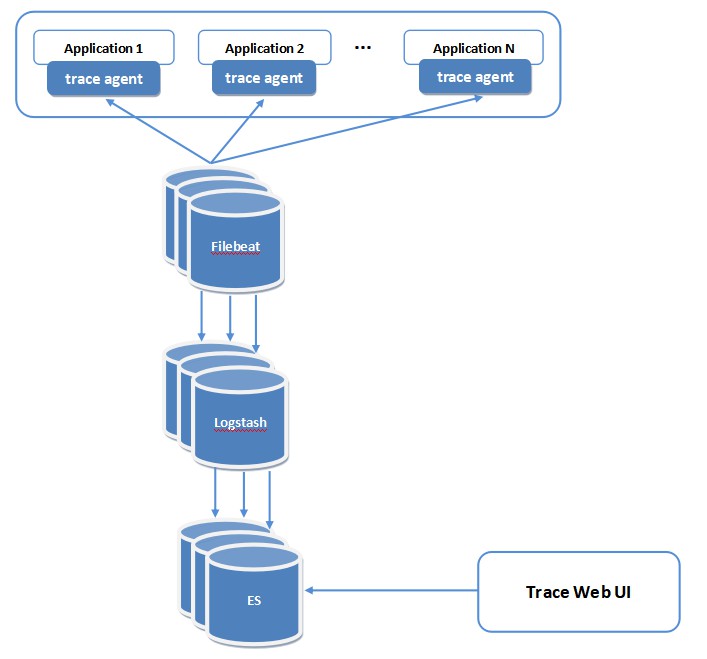
Trace Agent:各業務服務內部的埋點,其中包括各種通訊方式的引數傳遞、配置模組、接入模組等,最終將呼叫鏈節點資料以日誌形式落地;
Filebeat:採集Trace agent產生的呼叫鏈節點日誌並送給Logstash;
Logstash:對跟蹤日誌進行再處理,像屬性提取並結構化後輸出到ElasticSearch;
ElasticSearch:呼叫鏈節點日誌的最終儲存地,每個節點日誌以行為單位進行儲存;
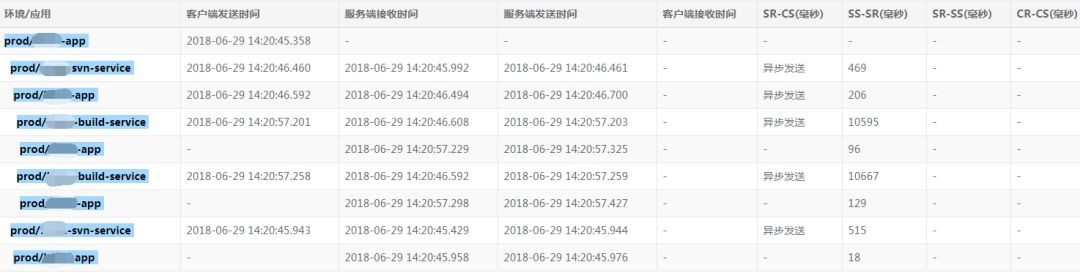
Trace Web UI:資料展現頁分為四部分,呼叫鏈TraceId串列、呼叫鏈串列、依賴分析圖(基於百度的Echarts)、節點詳情頁,如下:
-
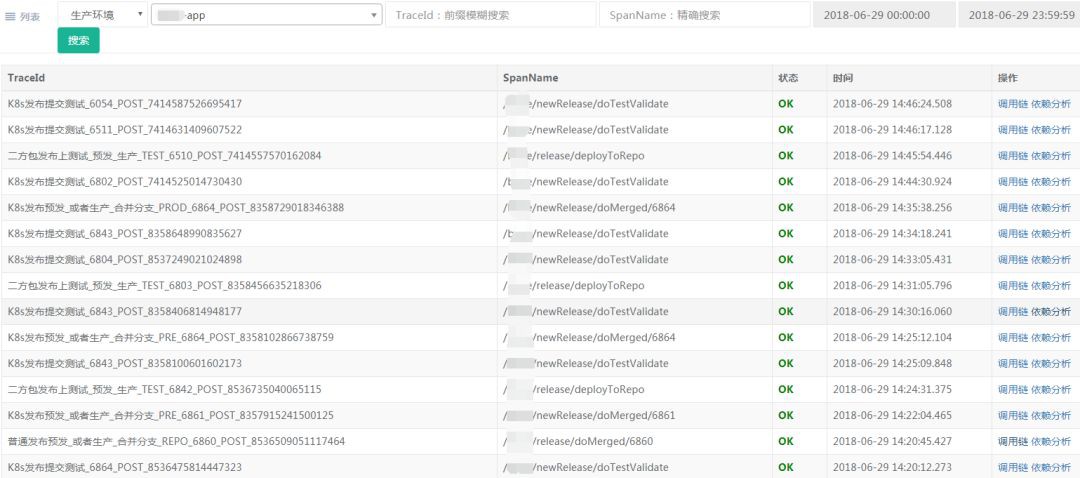
呼叫鏈TraceId串列
-
呼叫鏈串列
-
依賴分析圖

-
節點詳情頁

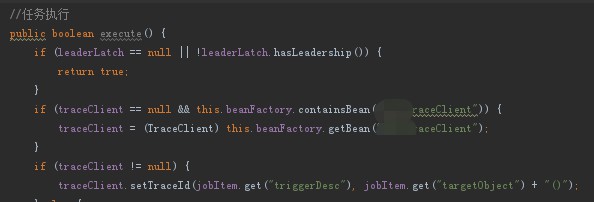
全鏈路跟蹤中介軟體產品要解決的第一個非常重要的問題就是呼叫鏈源頭的追溯,隨著對產品的理解逐漸加深,關於呼叫鏈源頭我們梳理出兩點,一是人為呼叫(觸發頁面上某事件),二是系統定時呼叫(定時任務觸發):
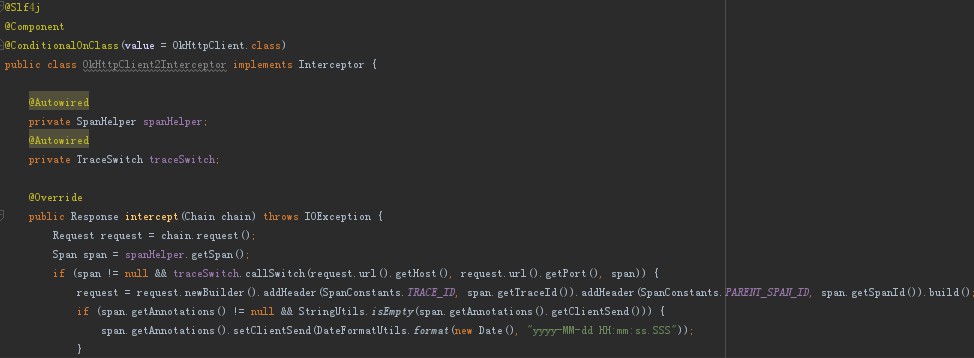
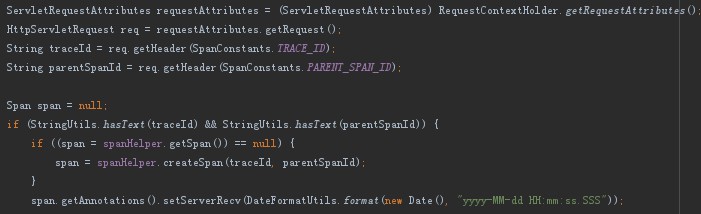
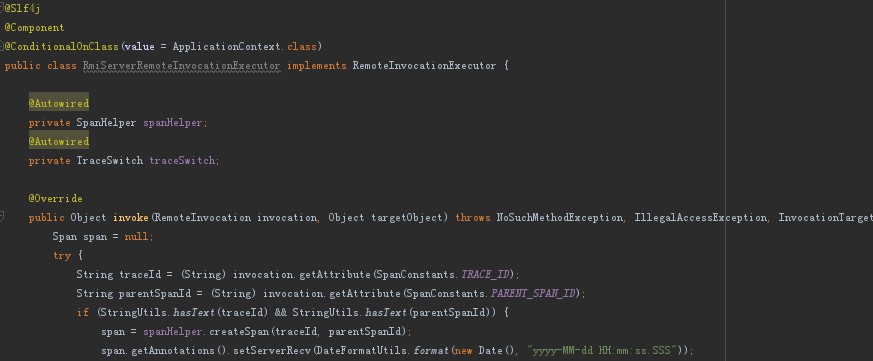
全鏈路跟蹤中介軟體產品要解決的第二個非常重要的問題就是呼叫鏈引數(traceId和父spanId)向下遊服務傳遞。在呼叫下游服務時,有些呼叫是不需要跟蹤的,比如呼叫Kubernetes的REST介面、ES的REST介面,所以我們設計了三級開關處理:機器級開關(跳掉某個IP的跟蹤)、應用級開關(跳掉某個應用的跟蹤)、介面級開關(跳掉應用內某個介面的跟蹤)。各種通訊方式呼叫鏈引數傳遞邏輯如下:
-
OkHttp2.x、OkHttp3.x(HTTP)
-
Apache HttpClient(HTTP)

-
Spring RestTemplate(HTTP)

-
REST介面(HTTP)
-
RabbitMQ Send(MQ)

-
RabbitMQ Recv(MQ)

-
Dubbo Provider(RPC)

-
Dubbo Consumer(RPC)

-
RMI Server(RPC)
-
RMI Client(RPC)

-
非同步呼叫時,執行緒池內的執行緒是獲取不到與主執行緒關聯的物件資料的,需要用使用阿裡開源的一個類庫(transmittable-thread-local)對原有執行緒池進行包裝:


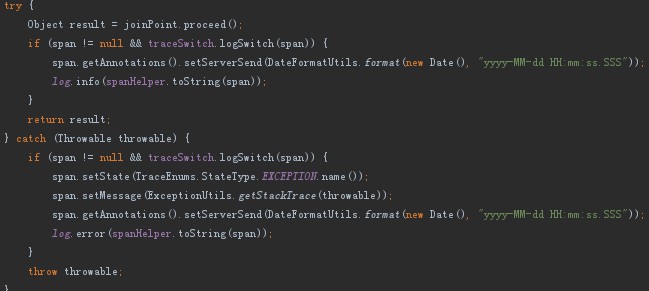
全鏈路跟蹤中介軟體產品要解決的第三個非常重要的問題就是呼叫鏈節點日誌的落地時機,客戶端在某個呼叫的點進行落地(防止多點重覆落地),而服務端在響應點邏輯執行完進行落地。各種通訊方式呼叫鏈節點日誌落地邏輯如下:
在產品設計之初,我們就將“低侵入”作為一個明確的設計標的,產品最終做到了隱式侵入,也就是在產品上線之後,要求業務系統重新釋出即可,無需任何業務程式碼上的改動(OkHttp3、Apache HttpClient、Dubbo使用方式需調整)。
-
BeanPostProcessor(Spring的擴充套件點實現隱式改造)
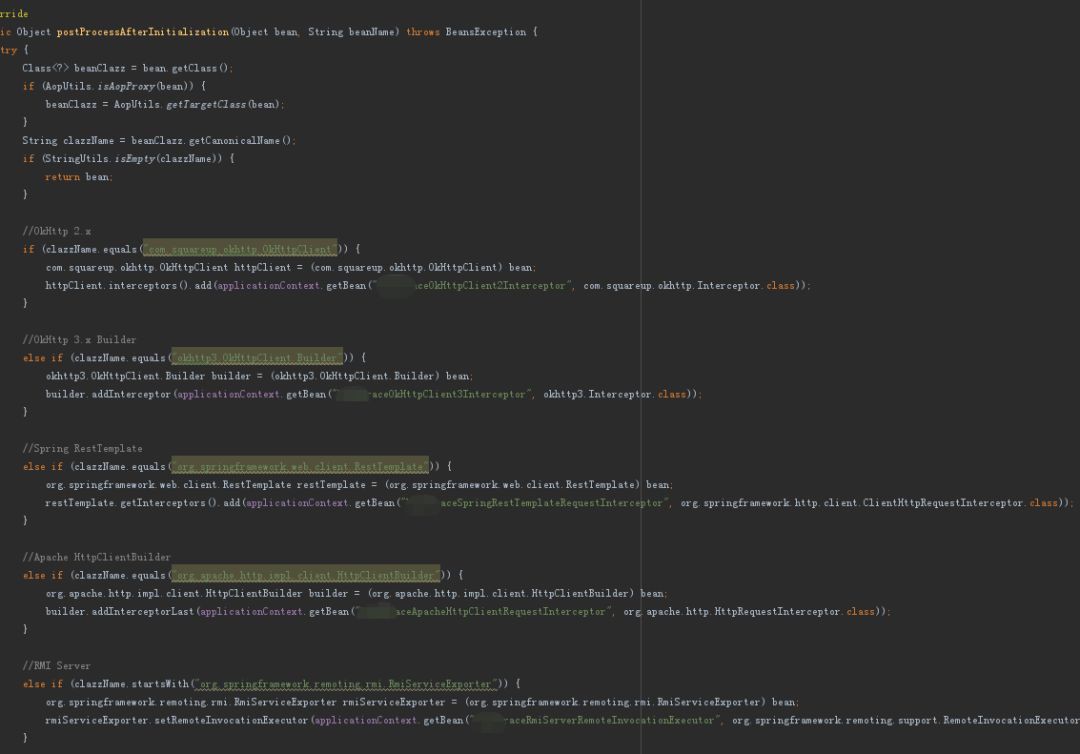

-
OkHttp3註冊方式調整(OkHttp3的攔截器鏈List是不可能更改的):

-
Apached HttpClient註冊方式調整(Apached HttpClient的攔截器鏈沒有公開新增的方法):
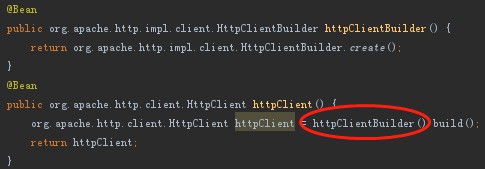
-
Dubbo服務改造(Dubbo的Filter介面沒有納入Spring體系)

Q:這種鏈路追蹤好像沒有深入到訪問資料庫層,以及某個方法執行的時間和方法內部之間呼叫的關係吧?另外在Web上是怎麼展示鏈路的呢?我看到有SpanId、TraceId這些都是寫到log,然後用ES查詢出來,再根據時間判斷整個鏈路條,再顯示在Web頁面麼?
A:暫時沒有到資料訪問層,後期我們會考慮加進去的;Web上的展示分享的內容裡面有,我們是基於百度的Echarts;ES儲存的資料是一個節點一條資料,然後將查出來的資料構造成多叉樹使用百度的Echarts進行資料展現。
A:TraceId的生成我們融入了業務語意,業務描述部分+System.nanoTimes,業務語意部分儲存在ZK中,是動態可配置的。
A:TraceId串列是按環境、應用、TraceId模糊查詢、介面名、時間段查出來的。
本次培訓包括:Docker介紹、Docker映象、網路、儲存、容器安全;Kubernetes架構、設計理念、常用物件、網路、儲存、網路隔離、服務發現與負載均衡;Kubernetes核心元件、Pod、外掛、微服務、雲原生、Kubernetes Operator、叢集災備、Heml等,點選瞭解具體培訓內容。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
![]()
微信掃一掃
使用小程式