導讀:不管是前幾年流行的手機安兔兔跑分,還是每年雙11各家電商曬成績,人們大概就像希望自己銀行卡上的餘額那樣——越大越好。對“大”數字總是持樂觀態度,資料出品方大概也知道大眾不會關心這些數字是怎麼計算出來的,輸出的數字要成為大家的談資才是更重要的。
用資料說話——資料思維在企業日常溝通中越顯重要,大有“Talk is cheap, show me the DATA”之勢,但實際上,某些場合下,數字成了裝點門面的“飾品”,不管對不對、有沒有用,放進報告裡就能增強自信,更有甚者,明目張膽地耍數字把戲來誤導大眾。 作者:Ahong 來源:CrossHands(ID:SmallWorldBigIdea)
通常來說,用資料說謊基本有如下套路:
樣本選擇,選擇不具有代表性(不能代表總體)的特殊樣本,樣本應該在空間上和時間上都要有代表性; 資料採集,資料來源不靠譜,例如不是專業的人員採集、採集工具不對、方式不對,誘導他人等; 指標選擇,濫用均值,虛榮指標等; 結論呈現,過度延伸結論,相關和因果不分,選擇性展示結果,或者改變圖表scale(讓不顯著的趨勢看起來很顯著); 01 樣本選擇
“如果想獲得贊同,那就找到那些會贊同你的人”——拿不具有代表性的樣本來說事通常都是耍流氓。
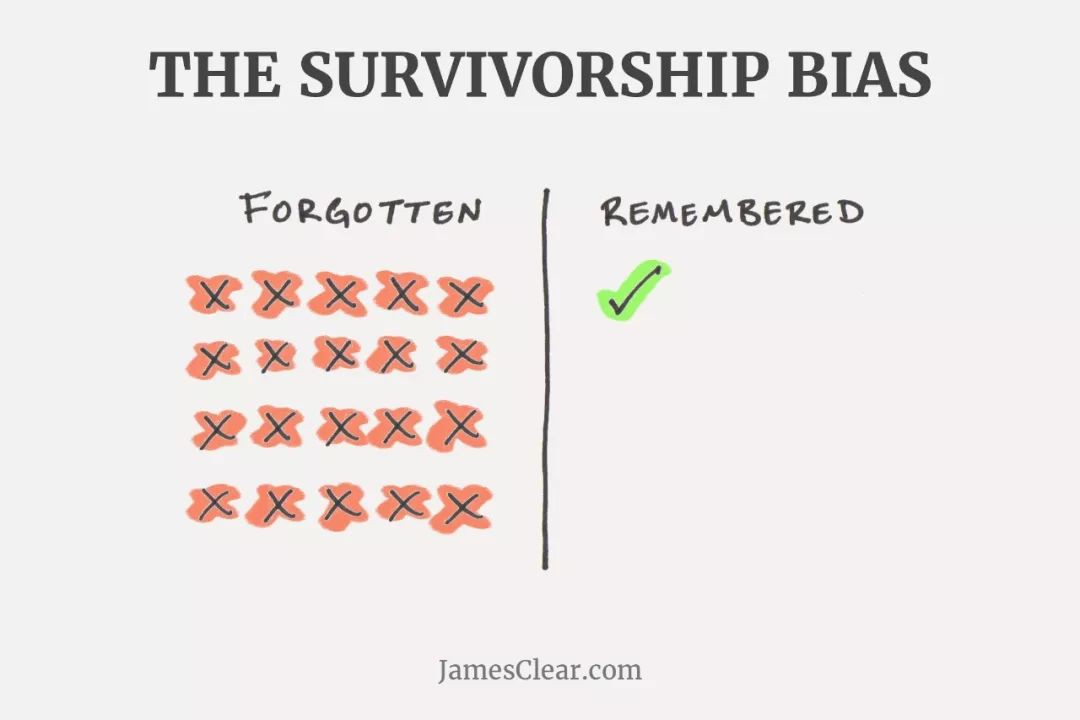
最常見的有偏樣本是商業廣告,其次是“倖存者偏差”。商業廣告永遠只展示好的那一面,“倖存者偏差”則只讓我們看到經過層層篩選後剩下的優秀選手,而誤以為他們身上的品質都是成功的必要條件(那些“沉默的被淘汰者”卻常常被忽視)。
e.g.
高考狀元代言補腦產品; “你看人家那誰誰,長年煙酒不離,照樣活了90多歲”; 公眾號文章下大多時候只放出對文章觀點有利的留言; 戰爭時期,軍隊的死亡率低於城市居民,所以參軍更安全?軍隊都是年輕力壯的年輕人呢,剩下的人群中的老弱病殘則是拉昇死亡率的主要因素; 問題的暴露性,打車遇到安全事件的機率整體是保持穩定的,只不過現在網路平臺上更容易暴露出來,就像以前說農村得癌症的人少,就認為農村是很健康的,其實不是,過去的農村醫療條件和健康意識缺乏,很多人得了癌症但是沒有去醫院或者被當做普通疾病,後來醫療條件好了暴露就更多了。
破解方法:
看樣本佔總體比例,少數不能代表大多數; 看事件發生的機率,警惕美好而不可控的小機率事件(不要一廂情願和自欺欺人); 找事件的反例,然後找正例和反例的相似性,e.g.成功的人喜歡吹牛(例如馬雲),不過失敗的的人也吹(賈布斯),可見吹牛和成功的關係並不大; 如果涉及到對比,要看抽樣的時間點、人群能不能匹配上,有沒有可比性;
這裡還要另外提一下,區域性不能代表整體,整體也不能代表區域性。
e.g.
辛普森悖論 偏態分佈(例如收入)中,“拖後腿”的弱勢群體經常“被代表”(整體的資料),經濟增長可能代表收入處於top5%的那群人增加了,實際上剩下的95%的收入都有下降
02 資料採集
關於具身認知的“吊橋試驗”告訴我們,心跳的感覺不一定是因為對方令人心動,而是當時的情境真的是讓人心跳加速(嚇死個人啊
身處環境、社交面具(社會認同、社交禮貌等)、利益誘導等,都會讓人變得不客觀,所以這時給到的回答往往也不可信。
當然,做調研時可能人員都沒經過培訓、提的問題可能也經不起推敲。
“你覺得自己是個好人嗎?” “填完這個問卷,將獲得50元超市購物券”
破解方法:
資料來源是哪?誰採集的? 用的什麼工具?靠譜麼? 怎麼開展的調研?會不會引導調研物件? 03 指標選擇
指標選擇上常出現的Trick有:
濫用均值,無視資料分佈及28法則; 絕對量和比例的誤導; 虛榮指標,有量無質;
1. 濫用均值
樣本中混入極端值,那就不要用均值(否則應該提出極端值)。
e.g.
如果富豪們都是農村戶口,那麼農村人均收入應該能上升很多。 人均收入,不管是算行業、城市、應屆生等,總會有大部分的人發現自己“拖後腿”了,因為收入是符合28法則的。
2. 絕對量和比例的誤導
公眾號關註人數,昨天有10人,今天新增10人,如果看增長率那就是100%,看著很好,其實一般。
如果基數很小的時候,報絕對量通常是更好的選擇。一般基數很大的時候使用比例,e.g. 企業的銷售額,去年1000億,今年1200億,說同比增加20%是可以的。
涉及到比例的時候還需要註意分子和分母各自的限定範圍。
3. 虛榮指標
虛榮指標通常的特徵就是越大越好(滿足虛榮心),然並卵,大都是有“量”無“質”,其背後往往都是“自定義的口徑”,而不是行業公認的準確計算口徑。
e.g.
沒有一支球隊能夠在世界盃上擊敗中國隊兩次以上; 雙11電商曬成績,預付、預熱、退款前的都可能在裡面; app下載量、存量使用者數,歷史訪問UV(甚至爬蟲、刷量也在裡面)等; 營業額中有很大一塊是在經銷商的庫存中,實際賣到消費者手中的產品並沒有那麼多。
破解方法:
怎麼算的?計算口徑(公式)是啥? 價值是什麼?反應了什麼問題,有何啟示? 04 結論呈現
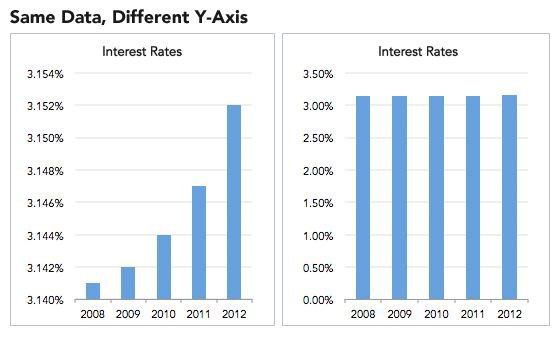
第一層次是選擇性展示結果以及在資料視覺化上動手腳,e.g. 只展示對自己有利或者符合預期的結果、改變坐標軸尺度、截斷坐標軸起點等。
更多參考 https://www.huffingtonpost.com/raviparikh/lie-with-data-visualization_b_5169715.html
第二層次是混淆相關和因果,e.g.我和一條狗都往同一個方向走,但不能說明狗子就是我的,我們只是順路而已。
共變背後都有第三方的潛在因素,“時間”是最容易被忽視的潛變數之一。
區分因果和相關需要註意,歸因的時候要註意區分充分必要條件,此外,大部分的因果關係是在“試驗對比”下發現並驗證的(沒有對比就下結論的通常是在耍流氓)。
第三層次是過度延伸結論,e.g. 有個妹子表示對某男生有好感,但不能說這個妹子願意和這個男生結婚,可能妹子只是想讓這個男生幫忙輔導她某門功課
▲大眾媒體並不是那麼專業,畢竟粉絲數量不代表其發文的質量 更多參考 https://www.guokr.com/question/577066/
 ,只不過整體看起來是增長了。
,只不過整體看起來是增長了。 )。
)。

 ,簡而言之,“想多了”。
,簡而言之,“想多了”。
歡迎光臨
每天分享高質量文章
每天分享高質量文章