
作者丨崔克楠
學校丨上海交通大學博士生
研究方向丨異構資訊網路、推薦系統
本文要介紹的兩篇論文在 metric learning 和 translation embedding 的角度對異構資訊網路中的節點進行學習,都受到了 knowledge graph 的模型如 TransE,TransR 的影響,所以在這裡一起來進行對比說明。
異構資訊網路專題論文集:
https://github.com/ConanCui/Research-Line
KDD 2018


待解決的問題
目前大多數異構資訊網路(HIN)對於點之間相似度的衡量方式,都是在低維空間使兩個點的 embedding 的內積 (dot product)盡可能的大。這種建模方式僅能考慮到一階關係(first-order proximity),這點在 node2vec 中也提到;
相比於同構資訊網路,異構資訊網路中包含多種 relationship,每種 relationship 有著不同的語意資訊。
同時 relationship 的種類分佈非常不均勻。
解決的方法
1. 使用 metric learning(具體可參見論文 Collaborative Metric Learning [1],它具有 triangle inequality 特性)來同時捕捉一階關係和二階關係(second-order proximity)。
2. 在 object space 學習 node 的 embedding,在 relation space 學習 relation 的 embedding。計算時,先將 node embedding 從 object space 轉移到 relation space,然後計算 proximity。
3. 提出 loss-aware 自適應取樣方法來進行模型最佳化。
模型的動機
相比於同構網路的 embedding,異構網路中節點之間的 proximity 不僅僅指兩個節點在 embedding space 的距離,同時也會受到 relation 中所包含關係的影響。
dot product 僅能夠保證一階關係,而 metric learning 能夠更好同時儲存一階關係和二階關係。
由於 metric learning 直接應用會存在 ill-posed algebraic 的問題,所以不能直接應用。同時我們還要考慮到異構網路中存在不同的 relation,這點也需要建模。
以往異構網路中,對於不同種類的 relation 比例差距懸殊的問題,有人提出對每一種 relation 進行等比例取樣, 但這會造成有的 relation 被欠取樣,有的過取樣,並且不同 relation 的難度不同,需要取樣的數量也不同。
模型
學習 embedding 的 loss 如下:

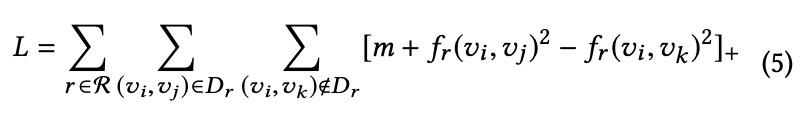
其中:

可以看出,上述 loss 的目的是讓不同的點在某一種 relation space 中盡可能地接近,同時是的學到的 embedding 保留一階和二階特性。需要學習的引數為 node embedding v, 和從 object space 對映到不同 relation space 的對映矩陣Mr。
上式中,所有負樣本都加入訓練集,會導致複雜度急劇上升,在這裡採用雙向負取樣(Bidirectional Negative Sampling Strategy),所以 loss 修改如下:

對於每個 epoch,我們會把每個種類的網路的 loss 記錄下來,如下 ,然後根據標的種類 r 的 loss 所佔的比例,來確定對該種類 r 的 edge 取樣出多少的比例。這樣為根據 loss 來自適應的調整取樣策略 (Loss-aware Adaptive Positive Sampling Strategy)。
,然後根據標的種類 r 的 loss 所佔的比例,來確定對該種類 r 的 edge 取樣出多少的比例。這樣為根據 loss 來自適應的調整取樣策略 (Loss-aware Adaptive Positive Sampling Strategy)。
最終整體的演演算法流程為:

實驗
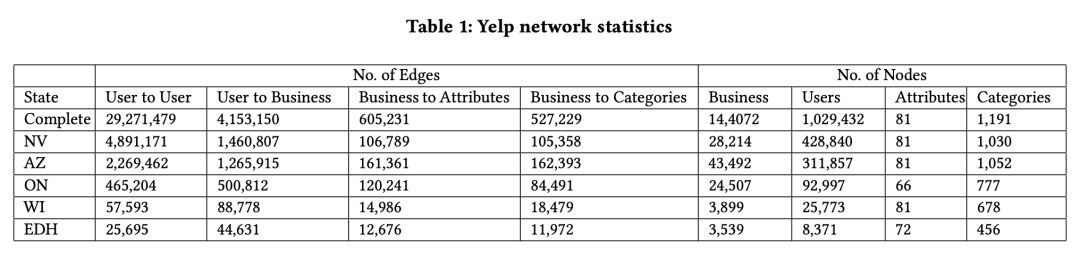
實驗採用了來自五個州的 Yelp 資料集,點的種類包括使用者(User),物品(Business),物品屬性(Attribute),物品種類(Category),如 Table 1 所示。
在 AZ 州的資料集上計算 Hits@K 和 MRR,結果如 Figure 2 和 Tabel 3 所示。


在 NV 州資料集做 link prediction 任務,具體為判斷當前便是否存在在測試集當中,具體指標使用 AUC,結果如 Tabel 4 所示。

總結
該篇文章整體的貢獻點為:
1. 使用 metric learning 來解決 HIN 中的二階關係,並借用 TransR 中的對映矩陣來解決 metric learning 存在的 ill-posed algebraic 問題,對於多種 relation 建立多個 relation space。
2. 提出 loss-aware adaptive 取樣方法,解決了 HIN 中存在的 relation skewed 的問題。
但是可能存在的問題是,該篇文章僅僅考慮基礎的 relation,另外在 HIN 中還有常見的 composite relations 是使用 meta-paths 來表示的。
比如在 DBLP 這樣的參考文獻資料集上,存在 (A, author,P,paper,C,conference) 這些節點。而像 APA (co-author relation),以及 APC (authors write pa- pers published in conferences) 這樣包含著豐富的資訊的 composite relations,在這篇文章中沒有考慮到。
AAAI 2019


待解決的問題
1. 異構網路中存在著很多的 relations,不同的 relations 有著不同的特性,如 AP 表現的是 peer-to-peer,而 PC 代表的是 one-centered-by-another 關係。如何區分不同的 relations?
2. 針對不同的 relations,目前的模型都採用相同的方法來對他們進行處理。如何區分建模?
3. 如果建立多個模型,如何協調最佳化?
解決的方法
1. 根據結構特性定義了兩種 relations,Affiliation Relations (ARs) 代表 one-centered-by-another 的結構,而 Interaction Relations (IRs) 代表 peer-to-peer的關係。
2. 對於 AR,這些點應當有共同的特性,所以直接用節點的歐幾裡得距離作為 proximity。對於 IR,將這種關係定義為節點之間的轉移(translation)。前者借鑒了 collaborative metric learning,後者借鑒了模型 TransE。
3. 因為兩個模型在數學形式上相似,所以可以一起最佳化。
資料分析
不同於上篇文章,這篇文章從資料分析入手,並給出兩種 structural relation 的定義。三個資料集整合如 Table 1 所示。

對於一個 relation 的三元組 ,其中作者定義了一個指標如下:

該指標由 u 和 v 種類的節點的平均度(degrees)來決定。如果 D(r) 越大,代表由 r 連線的兩類節點的不平衡性越大,越傾向於 AR 型別,否則傾向 IR 型別。同時定義了另外一個稀疏度指標如下:

其中![]() 代表該種類 relation 的數量,
代表該種類 relation 的數量,![]() 代表頭節點所在種類節點的數量,如果資料越稠密,則越傾向於 AR,因為是 one-centered-by-another,而 IR 關係的相對來說應該較為稀疏。
代表頭節點所在種類節點的數量,如果資料越稠密,則越傾向於 AR,因為是 one-centered-by-another,而 IR 關係的相對來說應該較為稀疏。
模型
對於 AR 型別,採用類似於上篇文章 PME 中的 metric learning 角度建模,原因除了 metric learning 能夠保留 second- order proximities 外,metric learning 和 AR 的定義契合,及被該關係連線的節點之間歐式距離要儘量的小。
而對於 IR 型別為何用 translation 來進行建模,沒有更好的說明,只是在模型的數學形式上和 metric learning 較為接近,容易結合。
則對於 AR 型別的 loss 為:


而對於 IR 型別的 loss 為:
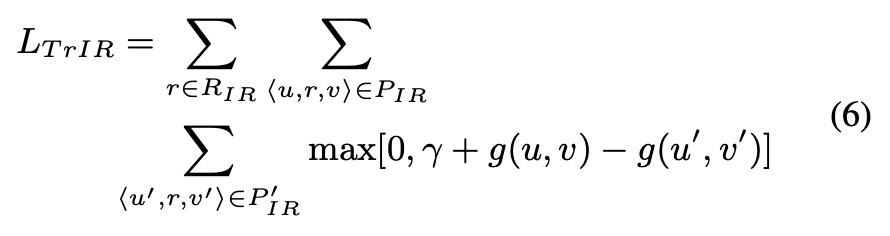

對於整個模型來說,就是簡單的把兩部分的 loss 相加,沒有上一篇 PME 中考慮的更合理。

正負取樣的方法也沒有上一篇當中有過多的技巧,relation 的正取樣就直接按照資料集中的比例來進行取樣,不考慮 relation 種類是 skewed 的情況。而對於負取樣,和 TransE 和上篇文章中 PME 相同的方法,即雙向負取樣。
實驗
實驗採用 Table 1 中的資料集,首先看在聚類任務上效果的好壞,具體指標採用 NMI,結果在表格 2 中所示。

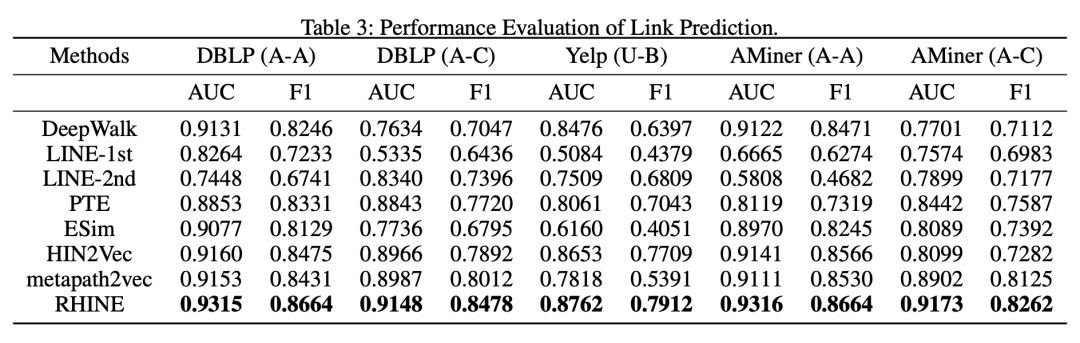
接著看了模型在 Link prediction 上的效果好壞,具體為判斷當前邊是否在測試集中。具體指標採用 AUC 和 F1,結果見 Table 3。
另外看了模型在 multi-class classification 任務上的表現,看學到的節點是否保留有節點種類資訊,具體為對已經學習到的節點 embedding,訓練一個分類器,結果如 Table 4 所示。

另外,為了探討區分兩種 relation,並利用 metric learning 和 translation 進行建模是否有效,作者進行了 ablation study。提出如下三種 variants:

其實驗結果如 Figure 2 所示:
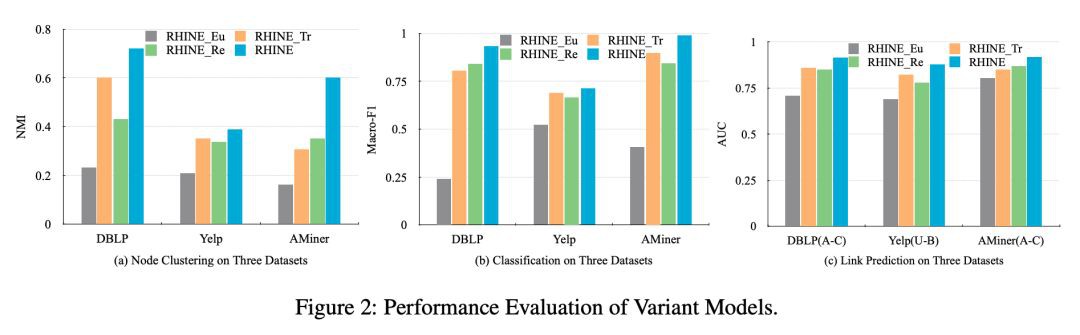
總結
總的來說,作者從分析資料入手,對於 HIN 中具有不同 structural 的 relation 進行了區分,並且分別採用不同的方法對不同 structural 的 relation 進行建模,在一定程度上給出了這兩種方法的建模 motivation。
相比於 PME,作者對於兩部分的 relation 的 loss 結合較為粗糙,不過作者的重點也不在於此,沒有什麼問題。
參考文獻
[1]. Hsieh C K, Yang L, Cui Y, et al. Collaborative metric learning[C]//Proceedings of the 26th international conference on world wide web. International World Wide Web Conferences Steering Committee, 2017: 193-201.

點選以下標題檢視更多往期內容:
讓你的論文被更多人看到 如何才能讓更多的優質內容以更短路徑到達讀者群體,縮短讀者尋找優質內容的成本呢? 答案就是:你不認識的人。
總有一些你不認識的人,知道你想知道的東西。PaperWeekly 或許可以成為一座橋梁,促使不同背景、不同方向的學者和學術靈感相互碰撞,迸發出更多的可能性。
PaperWeekly 鼓勵高校實驗室或個人,在我們的平臺上分享各類優質內容,可以是最新論文解讀,也可以是學習心得或技術乾貨。我們的目的只有一個,讓知識真正流動起來。
? 來稿標準: • 稿件確系個人原創作品,來稿需註明作者個人資訊(姓名+學校/工作單位+學歷/職位+研究方向) • 如果文章並非首發,請在投稿時提醒並附上所有已釋出連結 • PaperWeekly 預設每篇文章都是首發,均會新增“原創”標誌
? 投稿郵箱: • 投稿郵箱:hr@paperweekly.site • 所有文章配圖,請單獨在附件中傳送 • 請留下即時聯絡方式(微信或手機),以便我們在編輯釋出時和作者溝通
 #投 稿 通 道#
#投 稿 通 道#
?
現在,在「知乎」也能找到我們了
進入知乎首頁搜尋「PaperWeekly」
點選「關註」訂閱我們的專欄吧
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

