
專欄介紹:Paddle Fluid 是用來讓使用者像 PyTorch 和 Tensorflow Eager Execution 一樣執行程式。在這些系統中,不再有模型這個概念,應用也不再包含一個用於描述 Operator 圖或者一系列層的符號描述,而是像通用程式那樣描述訓練或者預測的過程。
本專欄將推出一系列技術文章,從框架的概念、使用上對比分析 TensorFlow 和 Paddle Fluid,為對 PaddlePaddle 感興趣的同學提供一些指導。
上一篇我們透過 RNN 語言模型初識 PaddleFluid 和 TensorFlow 中的迴圈神經網路模型。瞭解了:
-
在 PaddleFluid 和 TensorFlow 平臺下如何組織序列輸入資料;
-
如何使用迴圈神經網路單元;
-
使用中的註意事項。
可以看到 PaddleFluid 中的各種迴圈神經網路單元都直接支援非填充序列作為輸入,使用者在使用時無需對 mini-batch 中的不等長序列進行填充,無需關心填充位是否會對代價(loss)計算產生影響,從而需要在計算損失時對填充位置進行過濾這樣的細節,對使用來說無疑是十分方便的。
迴圈神經網路的是深度學習模型中最為重要的一部分,這一篇我們以序列標註任務為例將會構造一個更加複雜的迴圈神經網路模型用於命名物體識別任務。我們的關註點始終放在:在兩個平臺下:(1)如何組織序列資料;(2)如何使用序列處理單元(不限於迴圈神經網路)。
這一篇會看到:
1. PaddleFluid Data Feeder vs. 使用 TensorFlow r1.4 之後 release 的 Dataset API 讀取資料;
2. 在 PaddleFluid 和 TensorFlow 中,使用條件隨機場(Conditional Random Field,CRF)單元;
3. 在 PaddleFluid 和 TensorFlow 中,透過資料並行方式使用多塊 GPU 卡進行訓練。
如何使用程式碼
本篇文章配套有完整可執行的程式碼, 請隨時從 github [1] 上獲取最新程式碼。程式碼包括以下幾個檔案:

在執行訓練任務前,請首先在終端執行下麵的命令進行訓練資料下載以及預處理。
sh download.sh在終端執行以下命令便可以使用預設結構和預設引數執行 PaddleFluid 訓練序列標註模型。
python sequence_tagging_fluid.py在終端執行以下命令便可以使用預設結構和預設引數執行 TensorFlow 訓練序列標註模型。
python sequence_tagging_tensorflow.py背景介紹
序列標註和命名物體識別
序列標註是自然語言處理任務中的重要基礎任務之一。常見的分詞,詞性標註,語意角色標註,命名物體識別,甚至自動問答(QA)都可以透過序列標註模型來實現。這一篇我們將訓練一個序列標註模型完成命名物體識別的任務。
我們先來看看,什麼是序列標註問題呢?請看下麵一幅圖:
 ▲ 圖1. 序列標註問題
▲ 圖1. 序列標註問題
序列標註任務是為一個一維的線性輸入序列中的每個元素打上標簽集合中的某個標簽。在上面的例子中,序列標註就是為影象序列中的每個元素貼上一個描述它們形狀的標簽。而序列標註任務的難點在於:序列中 元素的標記和 它們在序列中的位置密切相關。
那麼, 什麼是命名物體識別呢?命名物體識別(Named Entity Recognition,NER)又稱作“專名識別”,是指識別文字中具有特定意義的物體,主要包括:人名、地名、機構名、專有名詞等。
BIO 表示法
序列標註任務一般都會採用 BIO 表示方式來定義序列標註的標簽集,B 代表句子的開始,I 代表句子中間,O 代表句子結束。透過 B、I、O 三種標記將不同的語塊賦予不同的標簽,例如:對於一個標記為 A 的命名物體,將它所包含的第一個語塊賦予標簽 B-A,將它所包含的其它語塊賦予標簽 I-A,不屬於任何命名物體的語塊賦予標簽 O。圖 2 是用 BIO 表示標註序列中命名物體的具體示例。

▲ 圖2. BIO標註方法示例
模型概覽
圖 3 是本篇模型的模型結構概覽。
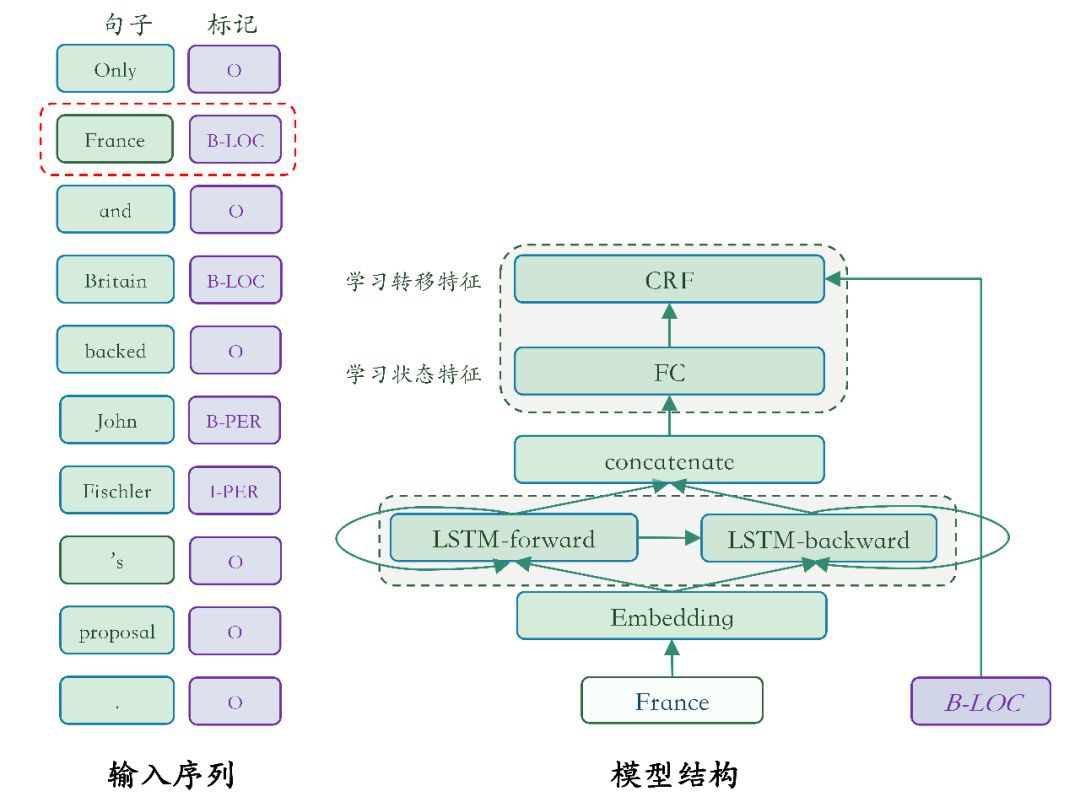
▲ 圖3. 序列標註模型結構概覽
我們要訓練的序列標註模型,接受:一個文字序列作為輸入,另一個與輸入文字序列等長的標記序列作為學習的標的。首先透過上一篇介紹過的 word embedding 層的取詞作用得到詞向量, 接著經過一個雙向 LSTM 單元學習序列的特徵表示,這個特別表示最終作為條件隨機場 CRF 的輸入完成最終的序列標註任務。
下麵是對各個子模組的進一步說明。
雙向迴圈神經網路
在迴圈神經網路模型中,t 時刻輸出的隱藏層向量編碼了到 t 時刻為止所有輸入的資訊,但由於迴圈神經網路單元計算的序列行:t 時刻迴圈神經網路但願可以看到歷史(t 時刻之前),卻無法看到未來(t 時刻之後)。
一些自然語言處理任務總是能一次性拿到整個句子,這種情況下,在 t 時刻計算時,如果能夠像獲取歷史資訊一樣得到未來的資訊,對序列學習任務會有很大幫助,雙向迴圈神經網路的出現正是為瞭解決這一問題。
它的思想簡單且直接:使用兩個迴圈神經網路單元( simple RNN,GRU 或者 LSTM 均可)分別以正向和反向順序學習輸入序列,再將兩者的輸出 向量進行橫向拼接。這樣的一個輸出向量中就既包含了 t 時刻之前的資訊,也包含了 t 時刻之後的資訊。
條件隨機場
使用神經網路模型解決問題的思路通常都是:前層網路學習輸入的特徵表示,網路的最後一層在特徵基礎上完成最終任務。在序列 標註任務中,雙向迴圈神經網路學習輸入的特徵表示,條件隨機場(Conditional Random Filed, CRF)正是在特徵的基礎上完成序列標註的一種計算單元,處於整個網路的末端。
CRF 是一種機率化結構模型,可以看作是一個機率無向圖模型(也叫作馬爾科夫隨機場),結點表示隨機變數,邊表示隨機變數之間的機率依賴關係。簡單來講 CRF 學習條件機率:P(X|Y),其中 X=(x1,x2,…,xn) 是輸入序列,Y=(y1,y2,…,yn) 是標記序列;解碼過程是給定 X 序列求解令 P(Y|X) 最大的 Y 序列,即 。
。
條件隨機場是的定義:設 G=(V,E) 是一個無向圖, V 是結點的集合,E 是無向邊的集合。V 中的每個結點對應一個隨機變數 Yv, ,其取值範圍為可能的標記集合 {y},如果以隨機變數 X 為條件,每個隨機變數 Yv 都滿足以下馬爾科夫特性:
,其取值範圍為可能的標記集合 {y},如果以隨機變數 X 為條件,每個隨機變數 Yv 都滿足以下馬爾科夫特性:

其中,ω∼v 表示兩個結點在圖 G 中是鄰近結點,那麼,(X,Y) 是一個條件隨機場。
線性鏈條件隨機場
上面的定義並沒有對 X 和 Y 的結構給出更多約束,理論上來講只要標記序串列示了一定的條件獨立性,G 的圖結構可以是任意的。對序列標註任務,只需要考慮 X 和 Y 都是一個序列,於是可以形成一個如圖 4 所示的簡單鏈式結構圖。在圖中,輸入序列 X 的元素之間並不存在圖結構,因為我們只是將它作為條件,並不做任何條件獨立假設。

▲ 圖4. 輸入序列和標記序列具有相同結構的線性鏈條件隨機場
序列標註問題使用的是以上這種定義線上性鏈上的特殊條件隨機場,稱之為線性鏈條件隨機場(Linear Chain Conditional Random Field)。下麵,我們給出線性鏈條件隨機場的數學定義:
定義 2 :線性鏈條件隨機場 :設 X=(x1,x2,…,xn),Y=(y1,y2,…,yn) 均為線性鏈表示的隨機變數序列,若在給定隨機變數序列 X 的條件下,隨機變數序列 Y 的條件機率分佈 P(Y|X) 滿足馬爾科夫性:

i=1,2,…,n(在i=1和n時只考慮單邊)則稱 P(Y|X) 為線性鏈條件隨機場。X 表示輸入序列,Y 表示與之對應的標記序列。
根據線性鏈條件隨機場上的因子分解定理,在給定觀測序列 X 時,一個特定標記序列 Y 的機率可以定義為:

其中:
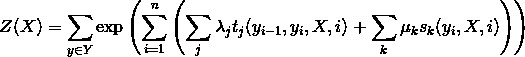
是規範化因子。
上面的式子中 tj 是定義在邊上的特徵函式,依賴於當前和前一個位置,稱為轉移特徵,表示對於觀察序列 X 及其標註序列在 i 及 i−1 位置上標記的轉移機率。sk 是定義在結點上的特徵函式,稱為狀態特徵,依賴於當前位置,表示對於觀察序列 X 及其 i 位置的標記機率。λj 和 μk 分別是轉移特徵函式和狀態特徵函式對應的權值。
線性鏈條件隨機場的最佳化標的
實際上 ,t 和 s 可以用相同的數學形式表示,s 可以同樣也寫為以下形式:
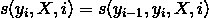
假設有 K1 個轉移特徵,K2 個狀態特徵,定義特徵函式 :
:

再對轉移特徵和狀態特在各個位置 i 求和有:

於是條件機率 P(Y|X) 可以寫為:
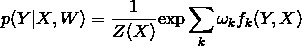

我們把 f 統稱為特徵函式,ω 是權值,是 CRF 模型要求解的引數。
學習時,對於給定的輸入序列和對應的標記序列的集合 D=[(X1,Y1),(X2,Y2),…,(XN,YN)] ,透過正則化的極大似然估計,可以得到如下最佳化標的:
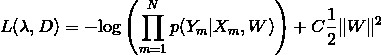
這個最佳化標的,可以透過反向傳播演演算法和整個神經網路一起更新求解。
解碼時,對於給定的輸入序列 X,透過解碼演演算法(通常有:維特比演演算法、Beam Search)求令出條件機率 最大的輸出序列
最大的輸出序列 。
。
CRF小結
條件隨機場是這一篇網路中一個相對複雜的計算單元。值得慶幸的是,在各個深度學習框架的幫助下,大多數情況下,我們只需要知道其原理便可以非常方便的使用,而不必過於關註 其內部的實現細節。
這裡我們再對上面的內容進行一個簡單的總結,方便大家使用 CRF 單元:
1. 在序列標註網路中, CRF 以迴圈神經網路單元輸出向量作為輸入,學習狀態特徵和轉移特徵。
2. 狀態特徵只與當然輸入有關;轉移特徵是一個矩陣,刻畫了標記兩兩之間互相轉移的強度。
3. 假設迴圈神經網路單元輸出向量維度為 h ,序列中含有 t 個詞語,共有 d 個標記:
-
迴圈神經網路輸入矩陣的大小為:Out=t×h;
-
CRF 層以 Out 為輸入學習轉移特徵:透過一個 全連線層將 Out 對映為一個 t×d 的矩陣,也就是轉移特徵;
-
狀態特徵是一個:(d+2)×d 維的矩陣,刻畫了標記之前轉移的強度。 這裡的 +2 是需要學習序列開始
向句子首詞轉移和和句子末尾詞向序列結束轉移這樣兩種特殊的狀態轉移; -
CRF 本質上計算了一個 softmax:給定標記序列出現的機率。但困難之處在於 softmax 的歸一化分母是所有可能標記序列,計算量很大。但由於引入了馬爾科夫假設,這個歸一化分母可以巧妙地透過一個動態規劃演演算法求解。
4. CRF 的學習準則是令 negative log likelihood 最大化。
資料集介紹
這一篇我們使用 Standford CS224d 課程中作業 2 [2] 的 NER 任務資料作為訓練資料源。 進入 data 目錄執行 data/download.sh 指令碼下載資料並預處理訓練資料。預處理包括:1. 為輸入文字序列建立詞典;2. 組織輸入資料格式。
執行結束將會在 data 目錄下看到如下內容。
data
├── dev
├── dev_src.txt
├── dev_src.vocab
├── dev_trg.txt
├── dev_trg.vocab
├── download.sh
├── preprocess.py
├── train
├── train_src.txt
├── train_src.vocab
├── train_trg.txt
└── train_trg.vocab其中需要重點關註的是 train_src.txt 、 train_trg.txt 、 train_src.vocab和train_trg.vocab 檔案。它們分別是:輸入文字序列;文字對應的標記序列;輸入文字序列的詞典以及標記序列詞典。 train_src.txt 和 train_trg.txt 的一行是一條訓練樣本,他們嚴格一一對應。分別執行 head -n 1 train_src.txt 和 head -n 1 train_trg.t xt 會看到如下內容:
EU rejects German call to boycott British lamb .B-ORG O B-MISC O O O B-MISC O O程式結構
我們首先在此整體回顧一下使用 PaddleFluid 平臺和 TensorFlow 執行神經網路模型的整體流程。
PaddleFluid
1. 呼叫 PaddleFluid API 描述神經網路模型。PaddleFluid 中 一個神經網路訓練任務被稱之為一段 Fluid Program 。
2. 定義 Fluid Program 執行裝置: place 。常見的有 fluid.CUDAPlace(0) 和 fluid.CPUPlace() 。
place = fluid.CUDAPlace(0) if conf.use_gpu else fluid.CPUPlace()註:PaddleFluid 支援混合裝置執行,一些 運算(operator)沒有特定裝置實現,或者為了提高全域性資源利用率,可以為他們指定不同的計算裝置。
3. 建立 PaddleFluid 執行器(Executor),需要為執行器指定執行裝置。
exe = fluid.Executor(place)4. 讓執行器執行 fluid.default_startup_program() ,初始化神經網路中的可學習引數,完成必要的初始化工作。
5. 定義 DataFeeder,編寫 data reader,只需要關註如何傳回一條訓練/測試資料。
6. 進入訓練的雙層迴圈(外層在 epoch 上迴圈,內層在 mini-batch 上迴圈),直到訓練結束。
TensorFlow
1. 呼叫 TensorFlow API 描述神經網路模型。 TensorFlow 中一個神經網路模型是一個 Computation Graph。
2. 建立 TensorFlow Session 用來執行計算圖。
sess = tf.Session()3. 呼叫 sess.run(tf.global_variables_initializer()) 初始化神經網路中的可學習引數。
4. 編寫傳回每個 mini-batch 資料的資料讀取指令碼。
5. 進入訓練的雙層迴圈(外層在 epoch 上迴圈,內層在 mini-batch 上迴圈),直到訓練結束。
如果不顯示地指定使用何種裝置進行訓練,TensorFlow 會對機器硬體進行檢測(是否有 GPU), 選擇能夠盡可能利用機器硬體資源的方式執行。
構建網路
基於 PaddleFluid 和 TensorFlow 的序列標註網路分別定義在 sequence_tagging_fluid.py 和 sequence_tagging_tensorflow.py 的 NER_net 類中,詳細資訊請參考完整程式碼,這裡對重要部分進行說明。
載入訓練資料
PaddleFluid:編寫Data Reader
PaddleFluid 模型透過 fluid.layers.data 來接收輸入資料。序列標註網路以圖片以及圖片對應的類別標簽作為網路的輸入:
self.source = fluid.layers.data(
name="source", shape=[1], dtype="int64", lod_level=1)
self.target = fluid.layers.data(
name="target", shape=[1], dtype="int64", lod_level=1)定義 data layer 的核心是指定輸入 Tensor 的形狀( shape )和型別。
序列標註中,輸入文字序列和標記序列都使用 one-hot 特徵作為輸入,一個詞用一個和字典大小相同的向量表示,每一個位置對應了字典中的 一個詞語。one-hot 向量僅有一個維度為 1, 其餘全部為 0。在上面定義的 data layer 中 source 和 target 的形狀都是 1,型別是 int64 。
PaddleFluid 支援非填充的序列輸入,這是透過 LoD Tensor 實現的。關於什麼是 LoD Tensor 請參考上一篇使用 PaddleFluid 和 TensorFlow 訓練 RNN 語言模型中的介紹,這一篇不再贅述。有了 LoD Tensor 的概念後,在 PaddleFluid 中,透過 DataFeeder 模組來為網路中的 data layer 提供資料,呼叫方式如下麵的程式碼所示:
train_reader = paddle.batch(
paddle.reader.shuffle(
data_reader(conf.train_src_file_name, conf.train_trg_file_name,
conf.src_vocab_file, conf.trg_vocab_file),
buf_size=1024000),
batch_size=conf.batch_size)
place = fluid.CUDAPlace(0) if conf.use_gpu else fluid.CPUPlace()
feeder = fluid.DataFeeder(feed_list=[net.source, net.target], place=place)
觀察以上程式碼,需要使用者完成的僅有:編寫一個實現讀取一條資料的 python 函式: data_reader 。 data_reader 的程式碼非常簡單,我們再來看一下它的具體實現:
def data_reader(src_file_name, trg_file_name, src_vocab_file, trg_vocab_file):
def __load_dict(dict_file_path):
word_dict = {}
with open(dict_file_path, "r") as fdict:
for idx, line in enumerate(fdict):
if idx 2: continue
word_dict[line.strip().split("\t")[0]] = idx - 2
return word_dict
def __reader():
src_dict = __load_dict(src_vocab_file)
trg_dict = __load_dict(trg_vocab_file)
with open(src_file_name, "r") as fsrc, open(trg_file_name,
"r") as ftrg:
for src, trg in izip(fsrc, ftrg):
src_words = src.strip().split()
trg_words = trg.strip().split()
src_ids = [src_dict[w] for w in src_words]
trg_ids = [trg_dict[w] for w in trg_words]
yield src_ids, trg_ids
return __reader
在上面的程式碼中:
1. data_reader 是一個 python generator ,函式名字可以任意指定,無需固定。
2. data_reader 開啟輸入序列檔案和標記序列檔案,每次從這兩個檔案讀取一行,一行既是一條訓練資料,傳回一個 python list,這個 python list 既是序列中所有時間步。具體的資料組織方式如下表所示,其中 i 代表一個整數:

3. paddle.batch() 介面用來構造 mini-batch 輸入,會呼叫 data_reader 將資料讀入一個 pool 中,對 pool 中的資料進行 shuffle,然後依次傳回每個 mini-batch 的資料。
TensorFlow:使用Dataset API
在之前的篇章中我們都使用 TensorFlow 的 placeholder 接入訓練資料,這一篇我們使用一種新的方式 TensorFlow 在 r1.3 版本之後引入的 Dataset API 來讀取資料。
參考 Google 官方給出的 Dataset API 中的類圖 [3],使用 TensorFlow 的 Dataset API,首先引入兩個抽象概念:
1. tf.data.Dataset 表示一系列元素,其中每個元素包含一個或多個 Tensor 物件。
2. tf.data.Iterator 提供了從資料集中取出元素的方法。 Iterator.get_next() 會在執行時生成 Dataset 的下一個 /mini-batch 元素。

定義 Dataset
目前 Dataset API 還提供了三種預定義好的定義 Dataset 的方式。這一篇中我們主要面向文字資料的處理,使用其中的 TextLineDataset 介面。
tf.data.TextLineDataset:介面的輸入是一個檔案串列,輸出是一個 TensorFlow dataset , dataset 中的每一個元素就對應了檔案中的一行。透過下麵的呼叫傳入輸入序列文字路徑和標記序列文字路徑便可傳回一個 Dataset 。
src_dataset = tf.data.TextLineDataset(src_file_name)
trg_dataset = tf.data.TextLineDataset(trg_file_name)獲取 Iterator
需要說明的是,TensorFlow 中的迴圈神經網路要求一個 mini-batch 之內序列長度相等,使用 Dynamic RNN 時,batch 和 batch 之間序列長度可以不相等,因此對一個 mini-batch 之內的資料需要進行填充。
Dataset API 提供了 padded_batch 幫助構造填充後的 mini-batch 資料。
提示:使用 bucket 分桶,從桶內取 mini-batch 資料,填充至一個 batch 中的最長序列長度能夠有效提高 dynamic rnn 的計算效率。
下麵的程式碼傳回 Iterator ,使用先分桶,然後再取 mini-batch 資料填充至 batch 中最長序列長度的方式。完整程式碼請參考:iterator_helper_tf [4]。
def get_data_iterator(src_file_name,
trg_file_name,
src_vocab_file,
trg_vocab_file,
batch_size,
pad_token="“,
max_sequence_length=None,
unk_id=1,
num_parallel_calls=4,
num_buckets=5,
output_buffer_size=102400,
is_training=True):
def __get_word_dict(vocab_file_path, unk_id):
return tf.contrib.lookup.index_table_from_file(
vocabulary_file=vocab_file_path,
key_column_index=0,
default_value=unk_id)
src_dataset = tf.data.TextLineDataset(src_file_name)
trg_dataset = tf.data.TextLineDataset(trg_file_name)
dataset = tf.data.Dataset.zip((src_dataset, trg_dataset))
if is_training:
dataset = dataset.shuffle(
buffer_size=output_buffer_size, reshuffle_each_iteration=True)
src_trg_dataset = dataset.map(
lambda src, trg: (tf.string_split([src]).values, \
tf.string_split([trg]).values),
num_parallel_calls=num_parallel_calls).prefetch(output_buffer_size)
src_dict = __get_word_dict(src_vocab_file, unk_id)
trg_dict = __get_word_dict(trg_vocab_file, unk_id)
src_pad_id = tf.cast(src_dict.lookup(tf.constant(pad_token)), tf.int32)
trg_pad_id = tf.cast(trg_dict.lookup(tf.constant(pad_token)), tf.int32)
# convert word string to word index
src_trg_dataset = src_trg_dataset.map(
lambda src, trg: (
tf.cast(src_dict.lookup(src), tf.int32),
tf.cast(trg_dict.lookup(trg), tf.int32)),
num_parallel_calls=num_parallel_calls).prefetch(output_buffer_size)
# Add in sequence lengths.
src_trg_dataset = src_trg_dataset.map(
lambda src, trg: (src, trg, tf.size(src)),
num_parallel_calls=num_parallel_calls).prefetch(output_buffer_size)
def __batching_func(x):
return x.padded_batch(
batch_size,
padded_shapes=(
tf.TensorShape([None]), # src
tf.TensorShape([None]), # trg
tf.TensorShape([]), #seq_len
),
padding_values=(src_pad_id, trg_pad_id, 0, ))
if num_buckets > 1:
def __key_func(unused_1, unused_2, seq_len):
if max_sequence_length:
bucket_width = (
max_sequence_length + num_buckets – 1) // num_buckets
else:
bucket_width = 10
bucket_id = seq_len // bucket_width,
return tf.to_int64(tf.minimum(num_buckets, bucket_id))
def __reduce_func(unused_key, windowed_data):
return __batching_func(windowed_data)
batched_dataset = src_trg_dataset.apply(
tf.contrib.data.group_by_window(
key_func=__key_func,
reduce_func=__reduce_func,
window_size=batch_size))
else:
batched_dataset = __batching_func(curwd_nxtwd_dataset)
batched_iter = batched_dataset.make_initializable_iterator()
src_ids, trg_ids, seq_len = batched_iter.get_next()
return BatchedInput(
initializer=batched_iter.initializer,
source=src_ids,
target=trg_ids,
sequence_length=seq_len)
構建網路結構及執行
構建網路結構及執行的過程對兩個平臺上都是常規流程。
1. 構建網路時呼叫相關的 API 介面,令一個 計算單元的輸出成為下一個計算單元的輸入建立起網路的連通性;具體請參考 sequence_tagging_fluid.py 和 sequence_tagging_tensorflow.py 中 NER_net 類的實現。
2. 執行訓練以及解碼具體請參考 sequence_tagging_fluid.py 和 sequence_tagging_tensorflow.py 中 train 函式的實現。
模型中核心模組:LSTM 單元在兩個平臺下的差異及註意事項請參考上一篇:使用 PaddleFluid 和 TensorFlow 訓練 RNN 語言模型,這裡不再贅述。
總結
這一篇繼續在序列標註模型中瞭解 PaddleFluid 和 TensorFlow 在接受序列輸入,序列處理策略上的不同。
1. PaddleFluid 引入了 LoD Tensor 的概念,所有序列處理模組(包括所有迴圈神經網路單元,文字摺積)都支援非填充的序列輸入,使用時無需對 mini-batch 資料進行填充,也就避免了對填充位的各種特殊處理,這一點非常方便。
2. TensorFlow 中的 Dynamic RNN 支援 mini-batch 之間序列不等長,但仍要求一個 mini-batch 內的資料填充至一樣長。
3. PaddleFluid 中透過 Data Feeder 提供訓練資料,只需要編寫一個 python generator 實現從原始輸入檔案中讀取一條訓練樣本, 框架會完成資料 shuffle 和組織 mini-batchd 工作。
4. 這一篇使用了 TensorFlow r1.3 後 release 的 Dataset API,資料讀取部分也是一個 computation graph,能夠提高 I/O 效率,使用相對複雜一些。
本篇程式碼中提供了透過資料並行策略在 PaddleFluid 平臺下使用多塊 GPU 卡進行訓練,在 TensorFlow 中使用多卡相對複雜一些,這些主題會在下麵繼續討論。
參考文獻
[1]. 本文配套程式碼
https://github.com/JohnRabbbit/TF2Fluid/tree/master/05_sequence_tagging
[2]. Standford CS224d課程作業2
http://cs224d.stanford.edu/assignment2/index.html
[3]. Google官方Dataset API
https://developers.googleblog.com/2017/09/introducing-tensorflow-datasets.html
[4]. iterator_helper_tf
https://github.com/JohnRabbbit/TF2Fluid/blob/master/05_sequence_tagging/iterator_helper_tf.py
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群刷論文
