

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @zhkun。本文主要集中在句子匹配任務上,作者將 DenseNet 的一些想法引入到了 stack RNN 中,提出了一種基於遞迴聯合註意力的句子匹配模型。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:張琨,中國科學技術大學博士生,研究方向為自然語言處理。
■ 論文 | Semantic Sentence Matching with Densely-connected Recurrent and Co-attentive Information
■ 連結 | https://www.paperweekly.site/papers/2082
■ 作者 | Seonhoon Kim / Jin-Hyuk Hong / Inho Kang / Nojun Kwak
句子匹配(Sentence Matching)是自然語言理解任務中一個非常重要的任務,例如 Natural Language Inference,Paraphrase Identification,Question Answering 等都可以歸屬於這個任務。這個任務主要就是理解句子語意,理解句子之間的語意關係。因此如何去表示這些內容就變得十分重要了。
為了更好的利用原始特徵資訊,作者參考 DenseNet,提出了一種 densely-connected co-attentive recurrent neural network 模型,該模型最突出的地方就是可以從最底層到最頂層一直保留原始資訊以及利用 co-attention 得到的互動資訊。接下來,就對文章進行詳細瞭解。
模型結構
首先是模型圖:

不得不說,這個圖還是很粗糙的,一點都不夠精緻,但模型的基本單元以及整體框架已經完全包含進去了,我們姑且用這個圖對模型進行分析吧。
輸入層
自然語言的任務首先就是輸入層,對每個詞的 one-hot 表示進行 embedding。

這幾個公式很好理解,首先作者將詞的 embedding 分為兩部分,一部分參與訓練,即![]() ,另一部分是固定不動的,即
,另一部分是固定不動的,即![]() ,然後就是詞級別的表示 char-Conv,以及一些 exact match 的匹配特徵,主要是 a 中的每個詞是否在 b 中有對應的詞,然後將這些表示拼接起來,就得到了每個詞的最後表示
,然後就是詞級別的表示 char-Conv,以及一些 exact match 的匹配特徵,主要是 a 中的每個詞是否在 b 中有對應的詞,然後將這些表示拼接起來,就得到了每個詞的最後表示![]() 。
。
密集連線層
在這一層,作者受 DenseNet 啟發,使用了密集連線和 RNN 結合的方法來實現對對句子的處理。首先![]() 表示的是第 l 層的 RNN 的第 t 的隱層狀態。
表示的是第 l 層的 RNN 的第 t 的隱層狀態。
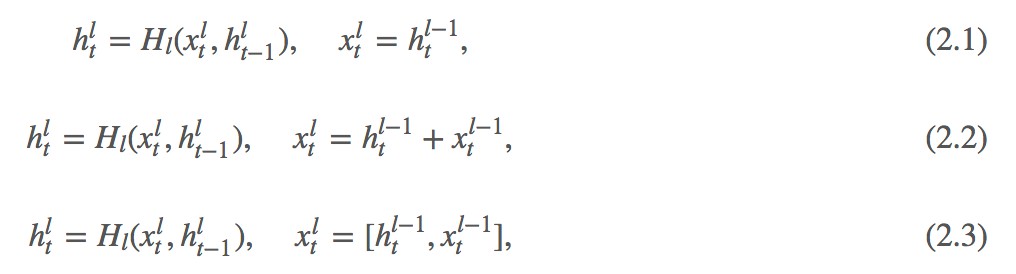
式 2.1 是傳統的多層 RNN 結構,前一層 RNN 的隱層狀態作為當前層的輸入,然後就是 RNN 的計算方式,式 2.2 借鑒了殘差網路,當前層的輸入不僅包含了前一層的隱層狀態,同時包含了前一層的輸入,但他們是相加的方式,作者認為這種相加的形式很可能會阻礙資訊的流動,因此借鑒 DenseNet,作者使用了拼接了方式,這樣不僅保留了兩部分資訊,同時拼接方法也最大程度的保留了各自的獨有資訊。
但這就有一個問題了,多層的 RNN 的引數就不一樣了,因為拼接的方式導致了每一層輸入對應的引數規模是在不斷變大的,這樣就不能做得很深了。
密集連線註意力
因為句子匹配考慮的兩個句子之間關係,因此需要建模兩個句子之間的互動,目前來說,註意力機制是一種非常好的方法,因此作者在這樣也使用了註意力機制。

這個就是傳統的 co-attention 計算方法,計算兩個序列之間的在每個詞上的對應關係,不過作者這裡比較粗暴,直接使用了餘弦相似度來計算每兩個詞之間的相似,這裡也可以使用一個簡單的 MLP 來計算。有意思的地方在下邊:
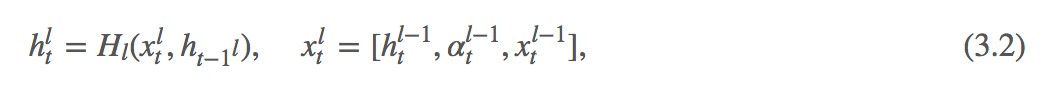
這個就很有意思了,我們傳統的做法是得到每個詞在對方句子上的機率分佈之後,使用對方句子中每個詞向量的加權和作為當前詞的向量表示,而這裡作者直接使用了計算出來的權值分佈,將其作為一個特徵引入到當前層的輸入當中,這個感覺還是很有意思的。
瓶頸處理層
正如前邊提到的,這種 dense 連線方式直接導致的一個問題就是隨著模型的加深,引數量會變的越來越多,這樣最後全連線層的壓力就會特別大。因此作者在這裡使用了一個 AutoEncoder 來解決這個問題。AutoEncoder 可以幫助壓縮得到的巨大向量表示,同時可以保持原始的資訊。這個操作還是很不錯的。
分類層
這是處理兩個句子關係常用的一種匹配方法,作拼接,相減,點乘,不過作者在這裡也是用了相減的絕對值,然後將最終拼接的向量透過一個全連線層,然後根據任務進行 softmax 分類,我個人做過實驗,相減的效果要好於相減的絕對值,因為相減不僅可以表示差異,同時可以表明資訊流方向,而相減的絕對值就更專註於差異了,兩個都用應該是效果比只用一個好的。
實驗結果
照例,上圖,作者在 NLI 任務和 Question Pair 兩個任務上進行了模型驗證,效果當然是十分不錯的。


感想
這篇文章主要集中在句子匹配任務上,將 DenseNet 的一些想法引入到了 stack RNN 中,還是可以給人一些靈感的,比如說從殘差連線到 DenseNet,比如說註意力權值的使用方法,比如說利用 AutoEncoder 來壓縮向量,這些還是十分值得學習的。
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視原論文
