
本期內容選編自微信公眾號「開放知識圖譜」。
ACL 2018

■ 連結 | https://www.paperweekly.site/papers/2108
■ 解讀 | 劉兵,東南大學計算機學院博士,研究方向為機器學習、自然語言處理
動機
遠端監督關係抽取方法雖然可以使用知識庫對齊文字的方法得到大量標註資料,但是其中噪聲太多,影響模型的訓練效果。基於 bag 建模比基於句子建模能夠減少噪聲的影響,但是仍然無法剋服 bag 全部是錯誤標註的情形。
為了換機噪聲標註,本文提出基於對抗神經網路的方法,嘗試從自動標註資料中清除噪聲。實驗結果表明,本文提出的方法能夠有效去除噪聲,提升遠端監督方法的抽取效能。
方法框架
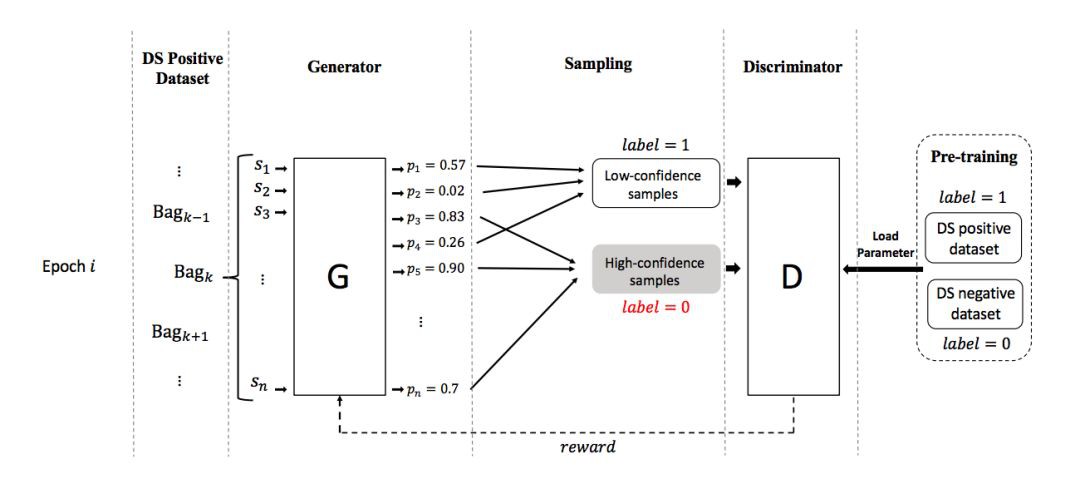
本文提出的方法包括一個生成器和一個判別器,他們的功能是:
1. 生成器:生成器用於將關於關係 r 的有噪聲的資料 P 劃分成兩組:表示正確標註資料的 TP 和表示錯誤標註資料的 FP。模型會輸出每個句子是正確標註的機率,然後依據該機率抽樣,得到 TP,剩餘的作為 FP。
2. 判別器:評價生成器生成的資料劃分的好壞。評價的方法是:首先使用標註為關係 r 的資料 P 和非 r 的資料 N 對判別器做預訓練。在評價生成器的劃分 TP FP 時,有意顛倒 TP FP 的標簽,即 TP 標記為負例,FP 標記為正例,從而形成錯誤的訓練資料,使用該資料繼續訓練判別器,看看該判別器效能下降情況。判別器效能下降越多,說明顛倒標簽的 TP FP 越錯誤,也就是 TP FP 越正確。
對抗過程是:生成器生成資料劃分之後,判別器透過訓練過程來評價該劃分的好壞,並將結果反饋給生成器。生成器根據反饋生成更好的資料,從而更大程度地降低判別器的判別能力。
實驗
實驗部分分析了訓練過程中生成器和判別器的收斂情況、以及去噪效果。在去噪效果方面,從下麵的 P-R 圖可以看出,在去噪後的資料上訓練得到的模型比在去噪前的資料上訓練的模型效果更好。

AAAI 2018

■ 連結 | https://www.paperweekly.site/papers/2109
■ 解讀 | 徐康,南京郵電大學講師,研究方向為情感分析、知識圖譜
任務簡介
特定標的的基於側面的情感分析,在原來基於側面的情感分析的基礎上,進一步挖掘細粒度的資訊,分析特定物件的側面級別的情感極性。具體任務的示例如圖 1 所示,給定句子識別該句子描述了哪個標的的哪個側面,並且識別出關於該側面的情感極性。
 ▲ 圖1. 特定標的的側面級別的情感分析示例
▲ 圖1. 特定標的的側面級別的情感分析示例

▲ 圖2. 文字描述多個標的的多個側面的示例
從圖 2 的示例中,我們可以看出真實的文字描述中,我們可能同時描述多個標的和關於這些標的的多個側面,原來基於側面的情感分析,一般用於評論分析,假定標的物體已經給定,因此該任務只能識別出側面以及分類該側面的情感,更一般的情況,該任務並不能解決,因此,需要構建新的任務,特定標的的基於側面的情感分析,同時抽取文字的描述的標的、它們對應的側面以及描述這些側面的情感極性。
例如,給定句子“I live in [West London] for years. I like it and itis safe to live in much of [west London]. Except [Brent] maybe.”包含兩個標的 [west London] 和 [Brent]。
我們的標的就是識別標的的側面並且分類這些側面的情感。我們想到的輸出就是關於標的 [WestLondon] 的結果 [‘general’:positive;‘safety’:positive] 和關於標的 [Brent] 的結果 [‘general’: negative; ‘safety’:negative]。
現有方法的不足:
1. 在一個句子中,同一個標的可能包含多個實體(同一個標的的不同表述方式,例如,同義詞、簡寫等)或者一個標的對應一個句子中的多個詞語。但是,現有的方法都假設所有的實體對於情感分類的重要性是一樣的,簡單地計算所有實體的向量的均值。事實上,同一個標的中的個別實體對於情感分類的重要性明顯高於其他的實體。
2. 現有的層次註意力機制模型將關於給定標的、側面和情感的建模過度簡化成一種黑盒的神經網路模型。現有的研究方法都沒有引入外部知識(情感知識或者常識知識)到深度神經網路,這些知識可以有助於側面和情感極性的識別。
模型簡述和常識知識:
本文提出的神經結構如圖 2 所示,包含兩個模組:序列編碼器和層次註意力模組。給定一個句子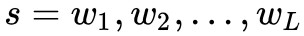 ,首先查閱詞向量表將句子中輸入的詞語全部變成詞向量
,首先查閱詞向量表將句子中輸入的詞語全部變成詞向量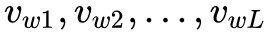 。
。
其中序列編碼器基於雙向 LSTM,將詞向量轉換成中間隱含層序列輸出,註意力模組置於隱含層輸出的頂部,其中比較特殊的是,本結構中加入標的級別的註意力模組該模組的輸入不是序列全部的中間隱含層輸出,而是序列中描述標的物件對應的位置的詞語的隱含層輸出(如圖 2 中的紫色模組),計算這些詞語的自註意向量 Vt。
這裡標的級別的註意力模組的輸出表示標的,標的的表示結合側面的詞向量用於計算句子級別的註意力表示,將整個句子表示一個向量,這個句子級別的註意力模組傳回一個關於特定標的和側面的句子向量,然後用這個向量預測這個標的對應的側面的情感極性。

▲ 圖3. 註意力神經結構
為了提升情感分類的精確度,本文使用常識知識作為知識源嵌入到序列編碼器中。這裡使用 SenticNet 作為常識知識庫,該知識庫包含了 5000 個概念關聯了豐富的情感屬性(如表 1 所示),這些情感屬性不但提供了概念級別的表示,同時提供了側面和它們的情感之間對應的語意關聯。
例如,概念“rottenfish”包含屬性“KindOf-food”可以直接關聯到側面“restaurant”或者“food quality”,同時情感概念“joy”可以支撐情感極性的分類(如圖 4 所示)。

▲ 表1. SenticNet 的示例
因為 SenticNet 的高維度阻礙了將這些常識知識融合到深度神經網路結構中。AffectiveSpace 提出了方法將 SenticNet 中的概念轉化成連續低維度的向量,而且沒有損失原始空間中的語意和情感關聯。基於這個新的概念空間,本文將概念級別的資訊嵌入到深度神經網路模型中可以更好地分類自然語言文字中的側面和情感分類。

▲ 圖4. SenticNet 語意網路的部分
實驗結果
本文主要評估了兩個子任務:一是側面分類,二是基於側面的情感分類;主要評估兩個測度,精確度、Macro-F1 和 Micro-F1;實驗室的資料集包括 SentiHood 和 Semeval-2015;常識知識庫使用 SenticNet 和使用 AffectiveSpace 作為概念 embedding,如果沒有抽取到概念,那麼使用零向量作為輸入。實驗結果如圖 5 和圖 6 所示。

▲ 圖5. 在 SentiHood 資料集上的效能
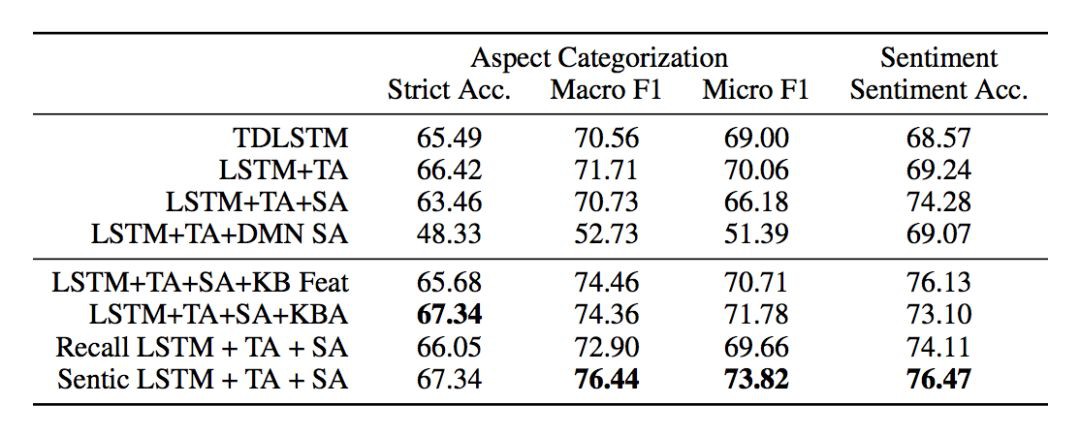
▲ 圖6. Semeval-2015 資料集的效能
WWW’ 2018

■ 連結 | https://www.paperweekly.site/papers/2097
■ 解讀 | 鄧淑敏,浙江大學博士生,研究方向為知識圖譜與文字聯合表示學習,動態知識圖譜,時序預測
動機
推薦系統最初是為瞭解決網際網路資訊過載的問題,幫助使用者針推薦其感興趣的內容並給出個性化的建議。新聞具有高度時效性和話題敏感性的特點,一般而言新聞的熱度不會持續太久,而且使用者關註的話題也多是有針對性的。其次,新聞的語言高度濃縮,往往包含很多常識知識,而目前基於詞彙共現的模型,很難發現這些潛在的知識。因此這篇文章提出了 DKN,將知識表示融合到新聞推薦系統中。
模型
首先看一下 DKN 模型的框架,如下圖所示:

DKN 模型主要分成三部分:知識抽取(Knowledge Distillation)、知識感知摺積神經網路(KCNN: Knowledge-aware CNN)、用於抽取使用者興趣的註意力網路(Attention Network: Attention-based UserInterest Extraction)。下麵對這三部分進行詳細的介紹。
1. 知識抽取
知識抽取模組的輸入是一些使用者點選的新聞標題以及候選新聞的標題。整個過程可以參見下圖。

首先將標題拆成一組詞,然後將標題中的詞與知識庫的物體進行連結。如果可以找到詞所對應的物體,那麼再接著找出距離連結物體一跳之內的所有鄰接物體,並將這些鄰接物體稱之為背景關係物體。尋找背景關係物體的過程如下圖所示。

這樣,根據新聞標題可以得到三部分的資訊,分別是詞,連結物體,以及背景關係物體。利用 word2vec 模型可以得到詞的向量表示,利用知識圖譜嵌入模型(這裡用的 TransD)可以得到知識庫物體的向量表示。其中,連結物體的表示就是 TransD 的訓練結果,如果連結不上就 padding。背景關係物體的表示就是對多個物體的表示進行平均,如果前一步沒有連結物體這裡也同樣 padding。由此分別得到了詞、連結物體、背景關係物體的向量表示。
2. 知識感知摺積神經網路
KCNN 在得到新聞標題三方面資訊的向量表示之後,下一步是要將它們放到同一個模型中進行訓練。但是這裡存在的問題是,三者不是透過同一個模型學出來的,直接放到同一個向量空間不合理。這篇文章使用的方法是,先把連結物體、背景關係物體的向量表示透過一個非線性變換對映到同一個向量空間:


然後類似於影象中 RGB 的三通道,將詞、連結物體、背景關係物體的向量表示作為 CNN 多通道的輸入。這樣 KCNN 的輸入就可以表示為:

然後透過摺積操作得到新聞標題的向量表示:
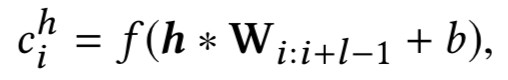
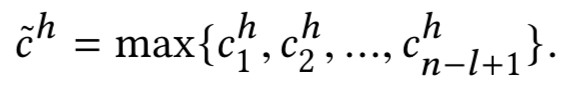

KCNN 的架構可以參考下圖。這裡還用了不同大小的摺積核進行摺積。

3. 註意力網路
給定使用者 i 的點選歷史新聞:
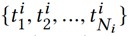
透過 KCNN 得到它們的向量表示:
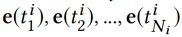
採用一個 DNN 作為註意力網路和一個 softmax 函式計算歸一化影響力權重:
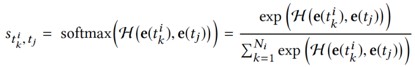
這樣可以得到使用者 i 關於候選新聞 t_i 的向量表示:

使用者 i 點選新聞 t_j 的機率由另一個 DNN 預測:

實驗
資料集
這篇文章的資料來自 bing 新聞的使用者點選日誌,包含使用者 id,新聞 url,新聞標題,點選與否(0未點選,1點選)。蒐集了 2016 年 10 月 16 日到 2017 年 7 月 11 號的資料作為訓練集。2017年7月12號到8月11日的資料作為測試集合。使用的知識圖譜資料是 Microsoft Satori。以下是一些統計資料以及分佈。

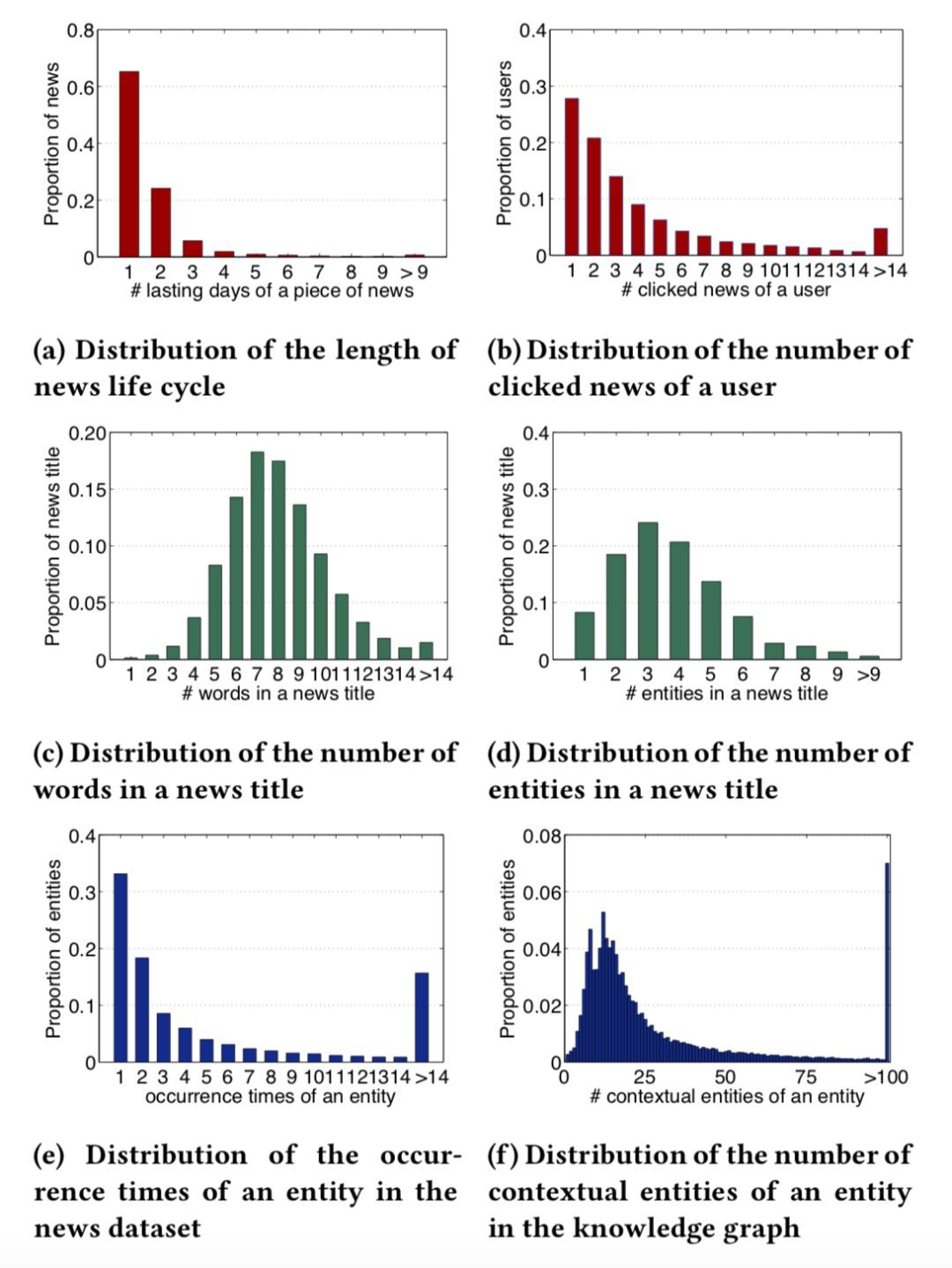
實驗用的評價指標是 AUC 和 F1,對比實驗結果如下表所示。

下麵這張表展示了 DKN 本身的一些變數對實驗結果的影響:

筆者認為,DKN 的特點是融合了知識圖譜與深度學習,從語意層面和知識兩個層面對新聞進行表示,而且物體和單詞的對齊機制融合了異構的資訊源,能更好地捕捉新聞之間的隱含關係。利用知識提升深度神經網路的效果將會是一個不錯的方向。
AAAI 2018

■ 連結 | https://www.paperweekly.site/papers/1988
■ 原始碼 | https://github.com/adityaSomak/PSLQA
■ 解讀 | 楊海宏,浙江大學博士,研究方向為知識問答與推理
論文概述
視覺問答(Visual Question Answering)現有兩大類主流的問題, 一是基於圖片的視覺問答(ImageQuestion Answering),二是基於影片的視覺問答(Video Question Answering)。而後者在實際處理過程中,常常按固定時間間隔取幀,將影片離散化成圖片(frame)的序列,剔除大量冗餘的資訊,以節省記憶體。
當前視覺問答的研究主要關註以下三個部分:
1. 延續自然語言處理中,對註意力機制(Attention Mechanism)和記憶網路(Memory Network)的研究,旨在透過改進二者提高模型對文字和影象資訊的表達能力,透過更豐富的分散式表示來提升模型的精度。另一方面,也可以視作是對神經計算機(Neural Machine)其中鍵值模組(Key-value,對應註意力)和快取模組(Cache,對應記憶網路)的改進。
2. 密集地研究可解釋性(Interpretability)和視覺推理(Visual Reasoning)。對同領域多源異構資料,這類研究方向將問答視為一種檢索或人機互動方式,希望模型能提供對互動結果(即答案)的來由解釋。
3. 將文字或影象,以及在影象中抽取的一系列資訊,如場景圖譜(SceneGraph),圖片標題(Image Caption)等視為是”知識來源”,在給定一個問題時,如何綜合考慮所有的知識,並推斷出最後的答案。
文章開頭提到的論文,便是朝著第三個方向再邁進一步。
模型
本文提出的主要模型,是一個基於一階謂詞機率軟邏輯(Probabilistic Soft Logic)的顯式推理機。如果你已經訓練好了一個用於視覺問答的神經網路模型,那麼這個顯式推理機可以根據模型的輸出結果,綜合考慮資訊後,更正原本模型的輸出結果。這樣的後處理能提升模型的精度。下圖就是一個這樣的例子。

▲ 圖1. 一個正面例子
圖 1 中紅色六邊形標示的 “PSL Engine”,是顯式推理的核心部分。透過這一個部分,將 “VQA” 的預測結果與” Visual Relation(視覺關係)”,“Question Relation(問題關鍵詞關係)”和”Phrasal Knowledge(語言常識)”三部分資訊綜合起來進行推理,更新答案。此處是一個正向例子。
推理過程具體如下:
1. 生成 VQA 答案:存在一個視覺問答的神經網路模型,對於這幅圖片和相應問題,預測出最有可能的答案是:教堂(church)和穀倉(barn)。
2. 生成Visual Relation:透過利用 Dense Captioning system (Johnson, Karpathy, and Fei-Fei 2016) 生成圖片的文字描述,再用 Stanford Dependency Parsing (De Marneffe et al. 2006) 抽取生成描述中的關鍵詞,再啟髮式的方法為關鍵詞對新增上關係,構成三元組。這代表了從圖片中抽取出有效的結構化資訊.。
3. 生成 Question Relation:再次使用 StanfordDependency Parsing 及啟髮式方法抽取問題中包含的三元組資訊。
4. 生成 Phrasal Knowledge:將所有相關關鍵詞在 ConceptNet 和詞向量中索引,並計算相似度。
5. 由機率軟邏輯推理引擎綜合前面四步生成的所有資訊,更新 VQA 答案對應的得分並重新排序,得到新的結果。
在推理過程中,使用了機率軟邏輯來綜合考量各種生成的事實。其核心思想是:由謂詞和變元組成的命題,真值不在侷限於 1 或 0(真或假),而是可以在閉區間 [0, 1] 上取值。一個簡單的例子是:
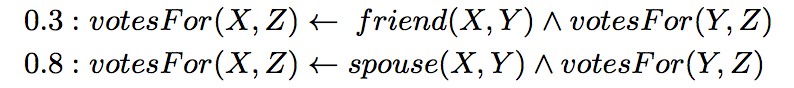
“X 和 Y 是朋友關係且 Y 為 Z 投票,蘊含 X 為 Z 投票”的權重是 0.3。而“X 和 Y 是伴侶關係且 Y 為 Z 投票,蘊含 X 為 Z 投票”的權重是 0.8。回到本文的例子,綜合所有生成的命題併進行推理的過程如下:
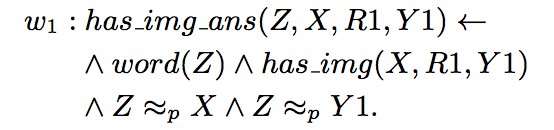
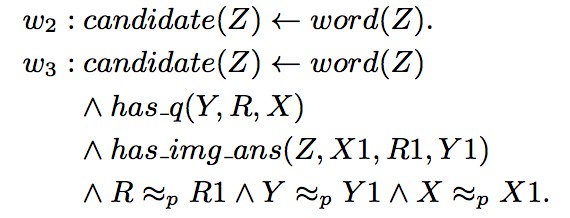

在此,命題的權重 w_i 是需要學習的部分。而最佳化的標的是使得滿足最多條件的正確答案的權重最高。
實驗
在資料集 MSCOCO-VQA (Antol et al. 2015) 測試,讓我們看看效果:

▲ 圖2. 實驗結果中的 8 個例子
WSDM 2018

■ 連結 | https://www.paperweekly.site/papers/2110
■ 解讀 | 李林,東南大學碩士,研究方向為知識圖譜構建及更新
動機
詞語的演化伴隨著意思和相關詞彙的改變,是語言演化的副產品。透過學習詞語的演化,能夠推測社會趨勢和人類歷史中不同時期的語言結構,傳統的詞語表示技術並不能夠捕獲語言結構和詞彙資訊。本文提出了動態統計模型,能夠學習到具有時間感知的詞向量,同時解決了相鄰時間片段中詞向量的“對齊”,實現了用來進行語意發現的動態詞向量模型。
論文貢獻
1. 本文的動態詞向量模型可以看作傳統“靜態”詞向量方法(如:word2vec)的提升。
2. 本文透過在所有時間片段上並行的學習臨時詞向量,實現詞向量的聯合學習,然後透過正則化項平滑詞向量的變化,解決了對準問題。實驗結果表明,本文透過正則化項實現對準的方法優於傳統動態詞向量中分步進行訓練和對準的方法。
3. 本文利用塊坐標下降方法來解決所有時間序列上詞向量聯合學習造成的計算問題。
4. 本文的方法在不同的時間片段中,共享了大多數詞的資訊。這使得本文的方法針對資料稀疏問題,具有健壯性,使得能夠處理一些時間片段中的罕見詞彙。
模型
本文為不同的時間範圍學習到了不同的向量表示,並透過距離的定義,選出和一個詞相似的“鄰居”。為不同的時間週期訓練不同的詞向量,一個關鍵問題,就是不同時間中的詞向量如何對準;通常來說訓練詞向量的 cost function 具有旋轉不變性,這樣在不同時間對同一個詞學習到的向量可能不在相同的潛在空間中,這使得為不同時間片段訓練詞向量時,詞的位置可能變的雜亂無章,無法和上一個時間段的詞向量進行對準。
本文透過對所有時間序列上的詞向量進行聯合學習,避免單獨解決對準問題。具體的,透過在所有時間片段上並行的學習臨時詞向量,然後透過正則化項平滑詞向量的變化,最後利用塊坐標下降方法來解決時間序列上進行詞向量聯合學習的計算問題。
對於靜態詞向量的訓練,本文計算了所有詞彙之間的點互資訊 PMI,把訓練詞向量中求內積的操作看作是點互資訊值,那麼類似於負取樣這種詞向量訓練技巧可以看作點互資訊 PMI 的低秩分解,真實資料往往非常稀疏,存在高效的低秩分解方法。透過在每一個時間片段上進行低秩分解,來為詞向量引入時間引數:

詞向量 U(t) 可以透過分解 PPMI(t,L) 得到,透過最小化連續時間片段中詞向量的 L2 範數來進行對準;整合以上內容,時態詞向量的計算方法透過以下標的函式的最小化來得到:
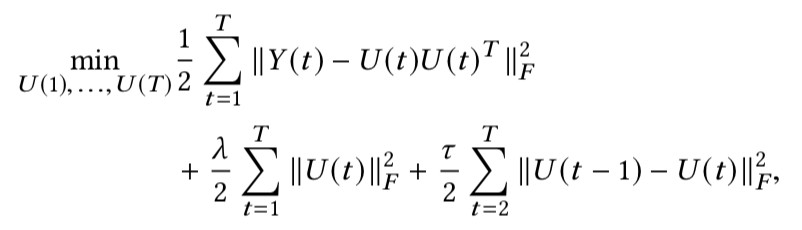
實驗
本文使用的資料是從 New York Times 上抓取的 99872 篇文章。在定性分析中,apple,amazon,obama,trump 的詞義變化軌跡如下所示:

實驗結果中,詞義的變化軌跡透過“鄰居”詞彙的變化給出,能夠清晰的看到語意的演化過程。表明瞭本文的動態詞向量方法能夠有效的捕獲詞義的演化。

點選以下標題檢視更多相關文章:

▲ 戳我檢視比賽詳情
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視更多論文推薦
