

伺服器對每個從事IT工作的人來說並不陌生,但是伺服器所涉及的各種知識細節,並非大家都十分清楚,為了讓大家深入瞭解伺服器的關鍵知識點,筆者特意抽時間總結了這篇科普文章,旨在幫助讀者全面瞭解伺服器。今天內容就從伺服器的架構和分類開始(2018.7.20更新)。
按照伺服器體系架構,伺服器主要分為非x86伺服器和x86兩類;非x86伺服器包括大型機、小型機和UNIX伺服器,它們是使用RISC或EPIC,並且主要採用UNIX和其它專用作業系統,RISC處理器主要包括IBM公司的Power和PowerPC處理器,SUN和富士通合作研發的SPARC處理器。EPIC處理器主要是Intel研發的安騰處理器等。

x86伺服器又稱CISC架構伺服器,採用Intel或其它相容x86指令集的處理器晶片和Windows作業系統的伺服器。伺服器按照不同分類方法主要分為如下:
-
CISC:Complex Instruction Set Computing 複雜指令集計算
-
RISC:Reduced Instruction Set Computing 精簡指令集計算
-
EPIC:Explicitly Parallel Instruction Computing 顯式並行指令運算
實際上,伺服器的分類沒有一個統一的標準,下麵從多個緯度來看伺服器的分類可以加深我們對各種伺服器的認識。

高度計量單位
U為機櫃安裝空間的高度度量單位,1U = 44.45 mm = 1.75 inch
容量計量單位
是一種容量計量單位,通常在標示記憶體等具有一般容量的儲存媒介之儲存容量時使用。一般指磁碟空間、檔案大小時使用。

速率單位
指在一個資料傳送系統中,單位時間內透過裝置位元、字元、塊等的平均量。一般在描述傳輸速率或頻寬時使用。如果是位元/秒,就用bit/s (kbit/s, Mbit/s) ,如果是位元組/秒,就用B/s (kB/s、 MB/s、 KB/s), 小寫的k代表1000, 大寫的K代表1024。
計算單位和峰值
每秒浮點運算次數(亦稱每秒峰值速度)是每秒所執行的浮點運算次數(Floating point Operations Per Second)的簡稱,被用來估算電腦效能,尤其是在使用到大量浮點運算的科學計算領域中。

埠自協商
是一個乙太網的過程,兩個相連的裝置選擇通用的傳輸引數,如速度、雙工樣式和流量控制。在這個過程中,連線的裝置首先共享它們的能力(10、100、1000BASE-T ),然後選擇它們都支援的最高效能傳輸樣式。在OSI模型中,對於乙太網,在IEEE 802.3對其做了定義。
伺服器主要軟體
BIOS(Basic Input/Output System) 是伺服器上電後最先執行的軟體。它包括基本輸入輸出控製程式、上電自檢程式、系統啟動自舉程式、系統設定資訊。BIOS是伺服器硬體和OS之間的抽象層,用來設定硬體,為OS執行做準備。 BIOS設定程式是儲存在BIOS晶片中的。
UEFI(Unified Extensible Firmware Interface) 下一代BIOS是UEFI, 即統一的可擴充套件固定介面。這種介面用於作業系統自動從預啟動的操作環境,載入到一種作業系統上,從而使開機程式化繁為簡,節省時間。
CMOS(complementary metal-oxide-semiconductor) 是電腦主機板上一塊特殊的RAM晶片,是系統引數存放的地方。CMOS儲存器是用來儲存BIOS設定後的要儲存資料的。
BMC (baseboard management controller) 對伺服器進行監控和管理。
OS(Operatingsystem)和位數,主要分32bit和64bit作業系統,計算機處理器在RAM(隨機存取儲存器)處理資訊的效率,取決於32位和64位版本。64位版本比32位的可以處理更多的記憶體和應用程式。
簡單理解下,64位版本可以處理的物理記憶體在4GB以上,高達128GB,而32位版本最多可以處理4 GB的記憶體。因此,如果你在計算機上安裝32位版本的Windows,那麼安裝4GB以上的RAM是沒意義的。
伺服器標準
ATCA(AdvancedTelecom Computing Architecture ) 國際標準,ATCA脫胎於在電信、航天、工業控制、醫療器械、智慧交通、軍事裝備等領域應用廣泛的新一代主流工業計算技術: CompactPCI標準。是為下一代融合通訊及資料網路應用提供的一個高價效比的,基於模組化結構的、相容的、並可擴充套件的硬體構架。
ATCA由一系列規範組成,包括定義了結構、電源、散熱、互聯與系統管理的核心規範PICMG3.0以及定義了點對點互聯協議的5個輔助規範組成(以太和光纖傳輸、InfiniBand傳輸、星形傳輸、PCI-Express傳輸和RapidIO傳輸)。
OSCA (Open Service Converged Architecture)開放服務匯聚架構, 是華為基於ATCA標準自研的伺服器平臺
OSTA (Open Standards Telecom Architecture)是由華為技術公司生產的強大的服務處理平臺。它由處理器子系統、交換網路子系統、機電子系統和裝置管理子系統組成。
伺服器的邏輯結構
伺服器的構成包括處理器、硬碟、記憶體、系統匯流排等,和通用的計算機架構類似,但是由於需要提供高可靠的服務,因此在處理能力、穩定性、可靠性、安全性、可擴充套件性、可管理性等方面要求較高。計算機的五大組成部分,最重要的部分是CPU 和記憶體。CPU 進行判斷和計算,記憶體為CPU 計算提供資料。

快取
快取的出現主要是為瞭解決CPU運算速度與記憶體讀寫速度不匹配的矛盾,因為CPU運算速度要比記憶體讀寫速度快很多,這樣會使CPU花費很長時間等待資料到來或把資料寫入記憶體。CPU快取是位於CPU與記憶體之間的臨時儲存器,它的容量比記憶體小的多但是交換速度卻比記憶體要快得多。
快取的工作原理是當CPU要讀取一個資料時,首先從快取中查詢,如果找到就立即讀取並送給CPU處理;如果沒有找到,就用相對慢的速度從記憶體中讀取並送給CPU處理,同時把這個資料所在的資料塊調入快取中,可以使得以後對整塊資料的讀取都從快取中進行,不必再呼叫記憶體。
目前所有主流處理器大都具有一級快取(level 1 cache,簡稱 L1 cache)和二級快取(L2 cache), 少數高階處理器還集成了三級快取(L3 cache)。
-
一級快取可分為一級指令快取(instruction cache)和一級資料快取(data cache)。一級指令快取用於暫時儲存並向CPU 遞送各類運算指令;一級資料快取用於暫時儲存並向CPU 遞送運算所需資料,這就是一級快取的作用。
-
二級快取就是一級快取的緩衝器:一級快取製造成本很高因此它的容量有限,二級快取的作用就是儲存那些CPU處理時需要用到、一級快取又無法儲存的資料。
-
三級快取和記憶體可以看作是二級快取的緩衝器,它們的容量遞增,但單位製造成本卻遞減。
記憶體(Memory)和儲存(Storage)的區別
大多數人常將記憶體(Memory)與儲存空間(Storage)兩個名字混為一談,尤其是在談到兩者的容量的時候。記憶體(Memory)是指計算機中所安裝的隨機存取記憶體的容量,而儲存(Storage)是指計算機內硬碟的容量。
為了避免混淆,我們將計算機比喻為一個有辦公桌與檔案櫃的辦公室。檔案櫃代表計算機中提供儲存所有所需檔案及資料的硬碟,工作時將需要的檔案從檔案櫃中取出並放到辦公桌上以方便取得,辦公桌就像保持資料及資料取用方便的記憶體。
記憶體頻率
記憶體主頻和CPU主頻一樣,習慣上被用來表示記憶體的速度,它代表著該記憶體所能達到的最高工作頻率。記憶體主頻是以MHz(兆赫)為單位來計量的。記憶體主頻越高在一定程度上代表著記憶體所能達到的速度越快。記憶體主頻決定著該記憶體最高能在什麼樣的頻率正常工作。
系統啟動方式
啟動系統通常有三種方式:冷啟動、熱啟動和複位啟動。
-
冷啟動:過程包括上電、全面自檢、系統引導及初始化等工作;
-
熱啟動:和冷啟動的區別是不需要重新上電、自檢的範圍很小;
-
複位啟動:和冷啟動的區別僅僅在於無須上電。
主機板南北橋區別
一個主機板上最重要的部分可以說就是主機板的晶片組了,主機板的晶片組一般由北橋晶片和南橋晶片組成,兩者共同組成主機板的晶片組。
北橋晶片主要負責實現與CPU、記憶體、AGP介面之間的資料傳輸,同時還透過特定的資料通道和南橋晶片相連線。北橋晶片的封裝樣式最初使用BGA封裝樣式,到Intel的北橋晶片已經轉變為FC-PGA封裝樣式,不過為AMD處理器設計的主機板北橋晶片依然還使用傳統的BGA封裝樣式。
南橋晶片相比北橋晶片來講,南橋晶片主要負責和IDE裝置、PCI裝置、聲音裝置、網路裝置以及其他的I/O裝置的溝通,南橋晶片到目前為止還只能見到傳統的BGA封裝樣式一種。
交換與路由
交換:完成訊號由裝置入口到出口的轉發。只要是和符合該定義的所有裝置都可被稱為交換裝置。
二層交換機工作在資料鏈路層。二層交換機就是普通的交換,把資料以幀的形式發送出去。三層交換機工作在網路層。三層交換機既可以作交換機又可以做路由器。
路由:是把資訊從源穿過網路傳遞到目的地的行為,在路上,至少遇到一個中間節點。它們的主要區別在於橋接發生在OSI參考協議的第二層(連結層),而路由發生在第三層(網路層)。這一區別使二者在傳遞資訊的過程中使用不同的資訊,從而以不同的方式來完成其任務。
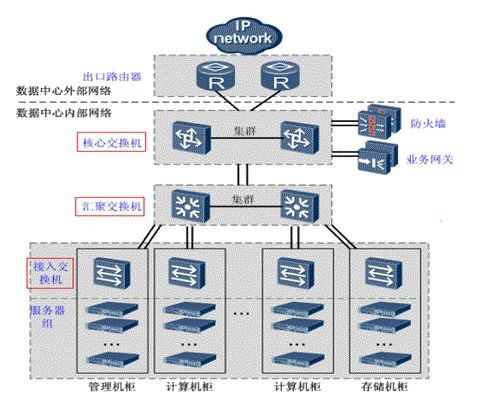
-
接入交換機:一般用於直接連線電腦。通常將網路中直接面向用戶連線或訪問網路的部分稱為接入層。負責連線機櫃內部的伺服器。
-
匯聚交換機:匯聚相當於一個區域性或重要的中轉站,將位於接入層和核心層之間的部分稱為分佈層或匯聚層。完成接入層交換機流量的匯聚,並與核心層交換機連線。
-
核心交換機:相當於一個出口或總彙總。完成資料報文的高速轉發,並提供對外的網路介面。
堆疊和級聯
級聯和堆疊是多臺交換機或集線器連線在一起的兩種方式。它們的主要目的是增加埠密度,主要區別:
級聯是上下關係(匯流排型、樹型或星型的級聯),堆疊是平等關係(堆疊中多臺交換機作為一個整體對外體現為一臺邏輯裝置)。
-
級聯可以連線不同型別或廠家的交換機,而堆疊只有在同系列的交換機之間。
-
交換機間的級聯在理論上沒有級聯數的限制。疊堆有最大限制,堆疊中多臺交換機作為一個整體對外體現為一臺邏輯裝置。
堆疊組建時會選舉出一臺交換機做為主交換機(Master),剩下的交換機稱為從交換機(Slave)。主交換機是整個堆疊系統中的控制中心。堆疊中每一臺交換機都同時具備成為主交換機或者從交換機的能力。
浮點數精度
-
半精度浮點數是一種計算機使用的二進位制浮點數資料型別。半精度浮點數使用2位元組(16位)儲存。
-
單精度浮點數格式是一種計算機資料格式,在計算機儲存器中佔用4個位元組(32 bits),利用“浮點”(浮動小數點)的方法,可以表示一個範圍很大的數值。
-
雙精度浮點數(Double)是計算機使用的一種資料型別。比起單精度浮點數,雙精度浮點數使用 64 位(8位元組)來儲存一個浮點數。
時間跳變和漸變
NTP client和server的時間同步有兩種情況: 時間跳變(time step)和漸變(time slew)。時間跳變是指在client和server間時間偏差(Offset)過大時(預設128ms),瞬間調整client端的系統時間。
時間漸變是指時間差較小時,透過改變client端的時脈頻率,進而改變client端中”1秒”的”真實時間”,保持client端時間連續性。如果client端比server端慢10s,client端的中每1秒現實時間是1.0005秒,雖然client端的時間仍然是1秒1秒增加的,透過調整每秒的實際時間,直到與server的時間相同。
FC SAN的Zone
Zone是FC SAN特有一種概念,目的用來配置同一個交換機上面不同裝置之間的訪問許可權。同在一個zone裡面的裝置可以互相訪問。Brocade交換機有個Default zone,出廠時候所有交換機埠都在一個default zone裡面,預設是不允許互相訪問的。
-
Zone可以根據交換機埠ID(Domain 、Port ID)或者裝置WWN來劃分。
-
一個Zone裡面可以部分裝置是交換機埠ID,部分是WWN的混合Zone。
-
Hard Zone和Soft Zone是早期交換機廠商根據對Zone實現方式做的一個分類。透過硬體來實現的叫做Hard Zone,透過軟體來實現叫做soft zone;早期一般稱基於埠ID的Zone為Hard zone,基於WWN的Zone為Soft Zone。現在這兩個型別的Zone都是基於硬體實現。
-
最佳使用WWN來劃分Zone,始終遵循Single Initiator原則 。
-
交換機通常把多個Zone納入一個Zone Set管理,每個交換機可以保留多個Zone Set配置,一次有且只有一個Zone Set配置能夠被啟用。
TPC基準(Benchmark)標準規範
TPC(Transaction Processing Performance Council)是由數10家會員公司建立的非盈利組織,總部設在美國。TPC的成員主要是計算機軟硬體廠家,而非計算機使用者,它的功能是制定商務應用基準程式(Benchmark)的標準規範、效能和價格度量,並管理測試結果的釋出。
TPC已經推出了多套Benchmarks,被稱為TPC-A、TPC-B、TPC-C和TPC-D。其中A和B已經過時不再使用了。TPC-C是線上事務處理(OLTP)的基準程式,TPC-D是決策支援(Decision Support) 的基準程式。TPC即將推出TPC-E,作為大型企業(Enterprise)資訊服務的基準程式。
TPC-C使用三種效能和價格度量,其中效能由TPC-C吞吐率衡量,單位是tpmC。tpm是Transactions Per Minute的簡稱;C指TPC中的C基準程式。它的定義是每分鐘內系統處理的新訂單個數。
CPU親和性
處理器親和性又稱處理器關聯。透過處理器關聯可以將虛擬機器或虛擬處理器對映到一個或多個物理處理器上。該技術基於對稱多處理機作業系統中的Native Central Queue排程演演算法。佇列(Queue)中的每一個任務(行程或執行緒)都有一個標簽(Tag)來指定它們傾向的處理器。在分配處理器的階段,每個任務就會分配到它們所傾向的處理器上。
處理器親和性利用了這樣一個事實,就是行程上一次執行後的殘餘資訊會保留在處理器的狀態中(也就是指處理器的快取)。如果下一次仍然將該行程排程到同一個處理器上,就能避免一些不好的情況(比如快取未命中),使得行程的執行更加高效。
排程演演算法對於處理器親和性的支援各不相同。有些排程演演算法在它認為合適的情況下會允許把一個任務排程到不同的處理器上。比如當兩個計算密集型的任務(A和B)同時對一個處理器具有親和性時,另外一個處理器可能就被閑置了。這種情況下許多排程演演算法會把任務B排程到第二個處理器上,使得多處理器的利用更加充分。
處理器親和效能夠有效地解決一些高速快取的問題,但卻不能緩解負載均衡的問題。而且,在異構系統中,處理器親和性問題會變得更加複雜。
簡單網路管理協議(SNMP)
SNMPv1/v2/v3/v2c主要用於網路監控和管理。在SNMP模型中,有一或多個管理系統和多個被管理系統。每一個被管理系統上有執行一個代理(Agent)軟體透過SNMP向管理系統報告資訊。一個SNMP管理的網路由下列三個關鍵元件組成:
-
網路管理系統 (NMS): 執行應用程式監視並控制被管理的裝置。也稱為管理物體(managing entity),網路管理員在這兒與網路裝置進行互動。NMS提供網路管理需要的大量運算和記憶資源。一個被管理的網路可能存在一個以上的NMS。
-
被管理的裝置(managed device): 一個被管理的裝置是一個網路節點,它包含一個存在於被管理的網路中的SNMP代理。被管理的裝置透過管理資訊庫(MIB)收集並儲存管理資訊,並且讓網路管理系統能夠透過SNMP代理者獲取這項資訊。
-
代理(agent): 執行在被管理裝置中的網路管理軟體。代理控制本機的管理資訊,以和SNMP相容的格式傳送這些資訊。
關於伺服器虛擬化技術,前期詳細總結分享過<虛擬化技術最詳細解析>文章,請點選連結查閱詳情。筆者對本號涉及的技術做了總結和彙總(20+本打包),請識別小程式獲取電子書詳細資訊。

熱文閱讀
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多技術資料。

Stay hungry Stay foolish

