etcd 是一個分散式的、一致性的鍵值儲存系統,主要用於配置共享和服務發現,etcd 基於 Go 語言實現;Google 的容器叢集管理系統 Kubernetes、開源 PaaS 平臺 Cloud Foundry 和 CoreOS 的 Fleet 都廣泛使用了 etcd。有以下特性:
-
簡單:安裝配置簡單,而且提供了 HTTP API 進行互動,使用簡單;
-
安全:可選的 SSL 客戶端證書認證;
-
快速:根據官方提供的 benchmark 資料,單實體支援每秒 2k+ 讀操作;
-
可靠:採用 Raft 演演算法,實現分散式系統資料的可用性和一致性。
HTTP Server:用於處理使用者傳送的 API 請求以及其它 etcd 節點的同步與心跳資訊請求。
Store:用於處理 etcd 支援的各類功能的事務,包括資料索引、節點狀態變更、監控與反饋、事件處理與執行等等,是 etcd 對使用者提供的大多數 API 功能的具體實現。
Raft:Raft 強一致性演演算法的具體實現,是 etcd 的核心。
WAL:Write Ahead Log(預寫式日誌),是 etcd 的資料儲存方式。除了在記憶體中存有所有資料的狀態以及節點的索引以外,etcd 就透過 WAL 進行持久化儲存。WAL 中, 所有的資料提交前都會事先記錄日誌。Snapshot 是為了防止資料過多而進行的狀態快照;Entry 表示儲存的具體日誌內容。
在任何時刻,每一個伺服器節點都處於這三個狀態之一:領導人、跟隨者或者候選人。
在通常情況下,系統中只有一個領導人並且其他的節點全部都是跟隨者。
跟隨者都是被動的:他們不會傳送任何請求,只是簡單的響應來自領導者或者候選人的請求。
領導人處理所有的客戶端請求(如果一個客戶端和跟隨者聯絡,那麼跟隨者會把請求重定向給領導人)。
第三種狀態,候選人,是用來在選舉新領導人時使用。圖二展示了這些狀態和他們之前轉換關係。
Raft 把時間分割成任意長度的任期,如圖三。任期用連續的整數標記。每一段任期從一次選舉開始,一個或者多個候選人嘗試成為領導者。如果一個候選人贏得選舉,然後他就在接下來的任期內充當領導人的職責。
在某些情況下,一次選舉過程會造成選票的瓜分。在這種情況下,這一任期會以沒有領導人結束;一個新的任期(和一次新的選舉)會很快重新開始。
Raft 保證了在一個給定的任期內,最多隻有一個領導者。任期在 Raft 演演算法中充當邏輯時鐘的作用,這會允許伺服器節點查明一些過期的資訊比如陳舊的領導者。
每一個節點儲存一個當前任期號,這一編號在整個時期內單調的增長。當伺服器之間通訊的時候會交換當前任期號。
如果一個伺服器的當前任期號比其他人小,那麼他會更新自己的編號到較大的編號值。
如果一個候選人或者領導者發現自己的任期號過期了,那麼他會立即恢覆成跟隨者狀態。
如果一個節點接收到一個包含過期的任期號的請求,那麼他會直接拒絕這個請求。
Raft 演演算法中伺服器節點之間通訊使用遠端過程呼叫(RPCs):
-
請求投票(RequestVote) RPCs 由候選人在選舉期間發起;
-
附加條目(AppendEntries)RPCs 由領導人發起,用來複制日誌和提供一種心跳機制;
-
傳輸快照 RPCs,伺服器沒有及時的收到 RPC 的響應時,會進行重試, 並且他們能夠並行的發起 RPCs 來獲得最佳的效能;
廣播時間(broadcastTime) << 選舉超時時間(electionTimeout) << 平均故障間隔時間(MTBF)
廣播時間指的是從一個伺服器並行的傳送 RPCs 給叢集中的其他伺服器並接收響應的平均時間;
平均故障間隔時間就是對於一臺伺服器而言,兩次故障之間的平均時間。廣播時間必須比選舉超時時間小一個量級,這樣領導人才能夠傳送穩定的心跳訊息來阻止跟隨者開始進入選舉狀態;透過隨機化選舉超時時間的方法,這個不等式也使得選票瓜分的情況變得不可能。選舉超時時間應該要比平均故障間隔時間小上幾個數量級,這樣整個系統才能穩定的執行。
Raft 使用心跳機制來進行領導人選舉。當叢集初始化時候,每個 node 都是跟隨者身份。node 節點繼續保持著跟隨者狀態直到他從領導人或者候選者處接收到有效的 RPCs。
領導者週期性的向所有跟隨者傳送心跳包(即不包含日誌項內容的附加日誌項 RPCs)來維持自己的權威。如果一個跟隨者在一段時間裡沒有接收到任何訊息,也就是選舉超時,那麼他就會認為系統中沒有可用的領導者, 並且發起選舉以選出新的領導者。
要開始一次選舉過程,跟隨者先要增加自己的當前任期號並且轉換到候選人狀態。然後他會並行的向叢集中的其他伺服器節點傳送請求投票的 RPCs 來給自己投票。
候選人會繼續保持著當前狀態直到以下三件事情之一發生:
-
自己贏得了這次的選舉;
-
其他的 node 成為領導者;
-
一段時間之後沒有任何一個 node 獲勝;
當一個候選人從整個叢集的大多數伺服器節點獲得了針對同一個任期號的選票,那麼他就贏得了這次選舉併成為領導人。每一個 node 最多會對一個任期號投出一張選票,按照先來先服務的原則。要求大多數選票的規則確保了最多隻會有一個候選人贏得此次選舉。一旦候選人贏得選舉,他就立即成為領導人。然後他會向其他的伺服器傳送心跳訊息來建立自己的權威並且阻止新的領導人的產生。
在等待投票的時候,候選人可能會從其他的伺服器接收到宣告它是領導人的附加日誌項 RPC。如果這個領導人的任期號(包含在此次的 RPC 中)不小於候選人當前的任期號,那麼候選人會承認領導人合法並回到跟隨者狀態。 如果此次 RPC 中的任期號比自己小,那麼候選人就會拒絕這次的 RPC 並且繼續保持候選人狀態。
第三種可能的結果是候選人既沒有贏得選舉也沒有輸:如果有多個跟隨者同時成為候選人,那麼選票可能會被瓜分以至於沒有候選人可以贏得大多數人的支援。當這種情況發生的時候,Raft 演演算法使用隨機選舉超時時間的方法來確保很少會發生選票瓜分的情況,就算發生也能很快的解決。為了阻止選票起初就被瓜分,選舉超時時間是從一個固定的區間(例如 150-300 毫秒)隨機選擇。這樣可以把伺服器都分散開以至於在大多數情況下只有一個伺服器會選舉超時;然後他贏得選舉併在其他伺服器超時之前傳送心跳包。
在選票瓜分的情況下,每一個候選人在開始一次選舉的時候會重置一個隨機的選舉超時時間,然後在超時時間內等待投票的結果;這樣減少了在新的選舉中另外的選票瓜分的可能性。
etcd 的儲存分為 記憶體儲存 和 持久化(硬碟)儲存 兩部分。
在 WAL 的體系中,所有的資料在提交之前都會進行日誌記錄。在 etcd 的持久化儲存目錄中,有兩個子目錄。
一個是 WAL,儲存著所有事務的變化記 錄;另一個則是 snapshot,用於儲存某一個時刻 etcd 所有目錄的資料。
透過 WAL 和 snapshot 相結合的方式,etcd 可以有效的進行資料儲存和節點故障恢復等操作。既然有了 WAL 實時儲存了所有的變更,為什麼還需要 snapshot 呢?隨著使用量的增加,WAL 儲存的資料會暴增,為了防止磁碟很快就爆滿,etcd 預設每 10000 條記錄做一次 snapshot,經過 snapshot 以後的 WAL 檔案就可以刪除。而透過 API 可以查詢的歷史 etcd 操作預設為 1000 條。首次啟動時,etcd 會把啟動的配置資訊儲存到 data-dir 引數指定的資料目錄中,如下圖:
etcd 一般部署叢集推薦奇數個節點,推薦的數量為 3、5 或者 7 個節點構成一個叢集。如下使用三個節點為例:
yum install etcd
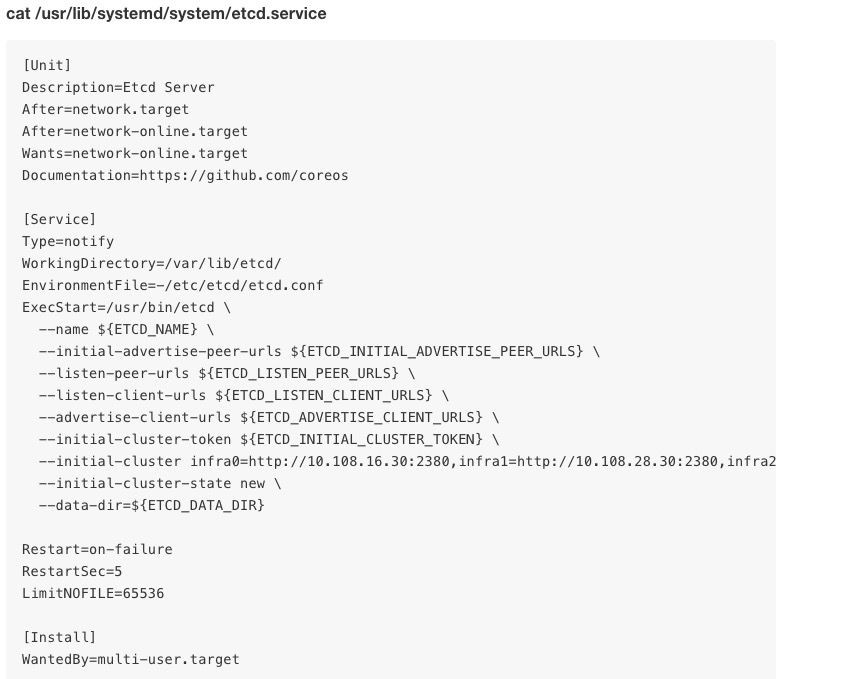
2、修改配置,如下配置檔案根據實際應用場景做相應的修改。
systemctl start etcd.service
註意:如果修改了 etcd.service 檔案,需要先 load 配置,再啟動服務。
systemctl daemon-reload
systemctl start etcd.service
V3: ETCDCTL_API=3 etcdctl member list
V2: etcdctl cluster-health
V3: ETCDCTL_API=3 etcdctl –endpoints=[10.108.187.32:2379,10.108.187.12:2379,10.108.28.30:2379,10.108.16.30:2379] endpoint status
V3: ETCDCTL_API=3 etcdctl –endpoints=[10.108.187.32:2379,10.108.187.12:2379,10.108.28.30:2379,10.108.16.30:2379] endpoint health
Raft 強一致性演演算法的具體實現是 etcd 的核心;理解 raft 一致性演演算法,是理解 Etcd 叢集工作原理的基礎,本文拿出大量篇幅來描述 raft 協議中領導人選舉,使大家清晰的明白選舉過程;raft 協議除了領導人選舉,還包含日誌複製和安全等兩個重要模組。日誌複製模組是 etcd 叢集資料一致性的基礎,安全模組是 etcd 叢集穩定和可靠的基礎,都比較重要。
本文是 etcd 服務簡介、架構、工作原理和服務部署解析入門,etcd 服務叢集還包括叢集使用、叢集管理、叢集升級、叢集資料備份和叢集監控等內容,大家可以進行更深一步的學習。
Kubernetes專案實戰訓練將於2018年8月17日在深圳開課,3天時間帶你係統掌握Kubernetes。本次培訓包括:Docker介紹、Docker映象、網路、儲存、容器安全;Kubernetes架構、設計理念、常用物件、網路、儲存、網路隔離、服務發現與負載均衡;Kubernetes核心元件、Pod、外掛、微服務、雲原生、Kubernetes Operator、叢集災備、Helm等,點選下方圖片檢視詳情。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
![]()
微信掃一掃
使用小程式