
筆者邀請您,先思考:
1邏輯回歸演演算法怎麼理解?
2 如何用Python平臺做邏輯回歸?
logistic回歸是一種機器學習分類演演算法,用於預測分類因變數的機率。 在邏輯回歸中,因變數是一個二進位制變數,包含編碼為1(是,成功等)或0(不,失敗等)的資料。 換句話說,邏輯回歸模型基於X的函式預測P(Y = 1)。
Logistic回歸假設
-
二元邏輯回歸要求因變數為二元的。
-
對於二元回歸,因變數的因子級別1應代表所需的結果。
-
只應包含有意義的變數。
-
自變數應相互獨立。 也就是說,模型應該具有很少或沒有多重共線性。
-
自變數與對數機率線性相關。
-
Logistic回歸需要非常大的樣本量。
記住上述假設,讓我們看一下我們的資料集。
資料探索
該資料集來自UCI機器學習庫,它與葡萄牙銀行機構的直接營銷活動(電話)有關。 分類標的是預測客戶是否將訂閱(1/0)到定期存款(變數y)。 資料集可以從這裡下載。
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib.pyplot as plt
plt.rc("font", size = 4)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
import seaborn as sns
sns.set(style="white")
sns.set(style="whitegrid", color_codes=True)
資料集提供銀行客戶的資訊。 它包括41,188條記錄和21個欄位。
data = pd.read_csv("raw_data/banking.csv", essay-header=0)
data = data.dropna()
print(data.shape)
print(list(data.columns))

輸入變數
-
age(數字)
-
job:工作型別(分類:管理員,藍領,企業家,女傭,管理人員,退休人員,自僱人員,服務人員,學生,技術員,失業,未知)
-
marital:婚姻狀況(分類:離婚,已婚,單身,未知)
-
education:教育(分類:“basic.4y”, “basic.6y”, “basic.9y”, “high.school”, “illiterate”, “professional.course”, “university.degree”, “unknown”)
-
default:有信用違約嗎?(分類:沒有,有,未知)
-
housing:有房貸嗎?(分類:沒有,有,未知)
-
loan:有個人貸款嗎?(分類:沒有,有,未知)
-
contact:聯絡溝通型別(分類:蜂窩,電話)
-
month:聯絡的最後一個月份(分類:“jan”,“feb”,“mar”,…,“nov”,“dec”)
-
day_of_week:一週中最後的聯絡日(分類:“mon”,“tue”,“wed”,“thu”,“fri”)
-
duration:上次聯絡持續時間,以秒為單位(數字)。重要提示:此屬性會嚴重影響輸出標的(例如,如果持續時間= 0,則y =’否’)。在執行呼叫之前不知道持續時間,也就是說,在呼叫結束之後,y顯然是已知的。因此,此輸入僅應包括在基準目的中,如果打算採用現實的預測模型,則應將其丟棄
-
campaign:此廣告系列期間和此客戶端執行的聯絡人數量(數字,包括最後一次聯絡)
-
pdays:從上一個廣告系列上次聯絡客戶端之後經過的天數(數字; 999表示之前未聯絡客戶)
-
previous:此廣告系列之前和此客戶端之間執行的聯絡人數量(數字)
-
poutcome:上一次營銷活動的結果(分類:“失敗”,“不存在”,“成功”)
-
emp.var.rate:就業變化率 – (數字)
-
cons.price.idx:消費者價格指數 – (數字)
-
cons.conf.idx:消費者信心指數 – (數字)
-
euribor3m:euribor 3個月費率 – (數字)
-
nr.employed:員工人數 – (數字)
預測變數(所需標的)
y – 客戶是否訂購了定期存款? (二進位制:“1”表示“是”,“0”表示“否”)
因變數的條形圖
sns.countplot(x = 'y', data=data, palette="hls")
plt.show()
如下圖:

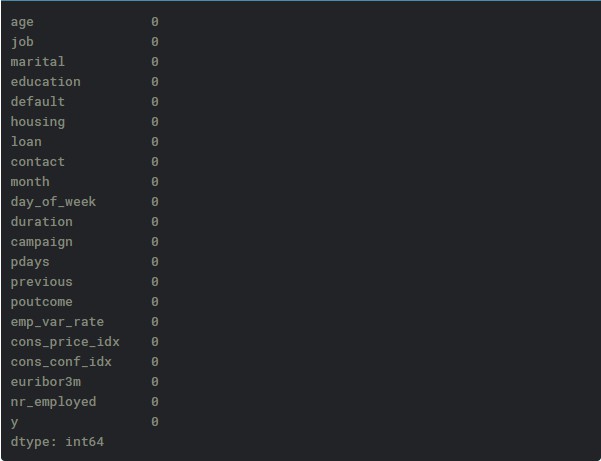
檢查缺失值
print(data.isnull().sum())
客戶工作型別分佈
sns.countplot(y = "job", data=data)
plt.show()
如下圖:

客戶婚姻狀態分佈
sns.countplot(x = "marital", data=data)
plt.show()
如下圖:

信用違約的條形圖
sns.countplot(x="default", data=data)
plt.show()
如下圖:

房貸條形圖
sns.countplot(x="housing", data=data)
plt.show()
如下圖:

個人貸條形圖
sns.countplot(x="loan", data=data)
plt.show()
如下圖:

先前的市場活動結果條形圖
sns.countplot(x="poutcome", data=data)
plt.show()
如下圖:

我們的預測將基於客戶的工作,婚姻狀況,他(她)是否有違約信用,他(她)是否有住房貸款,他(她)是否有個人貸款,以及之前營銷的結果活動。 因此,我們將刪除不需要的變數。
data.drop(data.columns[[0, 3, 7, 8, 9, 10, 11, 12, 13, 15, 16, 17, 18, 19]], axis=1, inplace=True)
資料預處理
建立虛擬變數,即只有兩個值的變數,零和一。
在邏輯回歸模型中,將所有自變數編碼為虛擬變數使得容易地解釋和計算odds比,並且增加繫數的穩定性和顯著性。
data2 = pd.get_dummies(data, columns =['job', 'marital', 'default', 'housing', 'loan', 'poutcome'])
刪除Unknown的列
print(data2.columns)
data2.drop(data2.columns[[12, 16, 18, 21, 24]], axis=1, inplace=True)
print(data2.columns)

完美! 正是我們後續步驟的需求。
檢查自變數之間的獨立性
sns.heatmap(data2.corr())
plt.show()
看起來不錯。
將資料拆分為訓練和測試集
X = data2.iloc[:,1:]
y = data2.iloc[:,0]
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)
檢查訓練資料集就足夠了
print(X_train.shape)
(30891, 23)
很好! 現在我們可以開始構建邏輯回歸模型。
Logistic回歸模型
訓練集上擬合邏輯回歸
classifier = LogisticRegression(random_state=0)
classifier.fit(X_train, y_train)
預測測試集結果並建立混淆矩陣
confusion_matrix()函式將計算混淆矩陣並將結果以陣列傳回。
y_pred = classifier.predict(X_test)
from sklearn.metrics import confusion_matrix
confusion_matrix = confusion_matrix(y_test, y_pred)
print(confusion_matrix)
結果告訴我們,我們有9046 + 229個正確的預測和912 + 110個不正確的預測。
準確性
print('Accuracy of logistic regression classifier on test set: {:.2f}'.format(classifier.score(X_test, y_test)))
Accuracy of logistic regression classifier on test set: 0.90
分類器視覺化
本節的目的是視覺化邏輯回歸類規則器的決策邊界。 為了更好地對決策邊界進行視覺化,我們將對資料執行主成分分析(PCA),以將維度降低到2維。
from sklearn.decomposition import PCA
X = data2.iloc[:,1:]
y = data2.iloc[:,0]
pca = PCA(n_components=2).fit_transform(X)
X_train, X_test, y_train, y_test = train_test_split(pca, y, random_state=0)
plt.figure(dpi=120)
plt.scatter(pca[y.values==0,0], pca[y.values==0,1], alpha=0.5, label='YES', s=2, color='navy')
plt.scatter(pca[y.values==1,0], pca[y.values==1,1], alpha=0.5, label='NO', s=2, color='darkorange')
plt.legend()
plt.title('Bank Marketing Data Set\nFirst Two Principal Components')
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.gca().set_aspect('equal')
plt.show()
如下圖:

def plot_bank(X, y, fitted_model):
plt.figure(figsize=(9.8,5), dpi=100)
for i, plot_type in enumerate(['Decision Boundary', 'Decision Probabilities']):
plt.subplot(1,2,i+1)
mesh_step_size = 0.01 # step size in the mesh
x_min, x_max = X[:, 0].min() - .1, X[:, 0].max() + .1
y_min, y_max = X[:, 1].min() - .1, X[:, 1].max() + .1
xx, yy = np.meshgrid(np.arange(x_min, x_max, mesh_step_size), np.arange(y_min, y_max, mesh_step_size))
if i == 0:
Z = fitted_model.predict(np.c_[xx.ravel(), yy.ravel()])
else:
try:
Z = fitted_model.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:,1]
except:
plt.text(0.4, 0.5, 'Probabilities Unavailable', horizontalalignment='center',
verticalalignment='center', transform = plt.gca().transAxes, fontsize=12)
plt.axis('off')
break
Z = Z.reshape(xx.shape)
plt.scatter(X[y.values==0,0], X[y.values==0,1], alpha=0.8, label='YES', s=5, color='navy')
plt.scatter(X[y.values==1,0], X[y.values==1,1], alpha=0.8, label='NO', s=5, color='darkorange')
plt.imshow(Z, interpolation='nearest', cmap='RdYlBu_r', alpha=0.15,
extent=(x_min, x_max, y_min, y_max), origin='lower')
plt.title(plot_type + '\n' +
str(fitted_model).split('(')[0]+ ' Test Accuracy: ' + str(np.round(fitted_model.score(X, y), 5)))
plt.gca().set_aspect('equal');
plt.tight_layout()
plt.legend()
plt.subplots_adjust(top=0.9, bottom=0.08, wspace=0.02)
model = LogisticRegression()
model.fit(X_train,y_train)
plot_bank(X_test, y_test, model)
plt.show()
如下圖:

如您所見,PCA降低了Logistic回歸模型的準確性。 這是因為我們使用PCA來減少維度,因此我們從資料中刪除了資訊。 我們將在以後的帖子中介紹PCA。
用於製作此文章的Jupyter筆記本可在此處獲得。 我很樂意收到有關上述任何內容的反饋或問題。
作者:Susan Li
原文連結:
https://datascienceplus.com/building-a-logistic-regression-in-python-step-by-step/
版權宣告:作者保留權利,嚴禁修改,轉載請註明原文連結。
資料人網是資料人學習、交流和分享的平臺http://shujuren.org 。專註於從資料中學習到有用知識。
平臺的理念:人人投稿,知識共享;人人分析,洞見驅動;智慧聚合,普惠人人。
您在資料人網平臺,可以1)學習資料知識;2)建立資料部落格;3)認識資料朋友;4)尋找資料工作;5)找到其它與資料相關的乾貨。
我們努力堅持做原創,聚合和分享優質的省時的資料知識!
我們都是資料人,資料是有價值的,堅定不移地實現從資料到商業價值的轉換!
點選閱讀原文,進入資料人網,獲取資料知識。
公眾號推薦:
鏈達君,專註於分享區塊鏈內容。

艾鴿英語,專註於分享有趣的英語內容。
