很久沒有寫過總結性的文章,一直想抽時間回顧和整理一下2018年深度學習種一些比較亮眼的技術進步,然後就有了今天的這篇文章。本文結合和人經驗和網上的一些開源文章翻譯整理而成,主要整理深度學習中一且前沿的Contextual Pretrained Model,以及這些開源模型使用場景、開原始碼以及一些公開資料集。本文部分內容僅個人觀點,僅供參考。
2018年深度學習技術取得的最亮眼的成就有哪些?ELMO、GPT、Bert、GPT-2…..以及在異構圖模型領域中模型的發展GCN、GAT等,以及在其他領域的相互滲透。所有這些模型,其核心的本質都在圍繞一個主題-Embedding。Embedding最初起源於深度學習三巨頭之一的Yoshua Bengio在03的JMLR上提出了神經網路語言模型(NNLM),即提出基於神經網路語言模型來訓練low-dimensional、dense的embedding(vector)替換高維的one-hot vector。Dense vector具有很多的優勢,比如緯度低,方便計算機儲存、計算,編碼token本身的語意、背景關係資訊等。
2006年,Geffery Hinton提出了逐層貪心演演算法訓練深度神經網路,並提出了深度學習的概念。2012年,Hinton和他的學生Alex Krizhevsky在ILSVRC-2012憑藉他們設計的深度模型AlexNet獲取本屆競賽的第一名,並且錯誤率遠低於第二名,自此,深度學習逐漸受到學術界和工業界重視。正是在這樣的大背景下,Yoshua Bengio提出的NNLM在2013年,再次回答眾人視線裡,開啟了embedding技術井噴式發展的序幕,之後出現了大家耳熟能詳的各種word embedding pretrained模型,Glove、CBOW、SkipGram,並且這些基於淺層神經網路的embedding tokenization技術確實推動了NLP各項任務的進步,關於這些技術的具體介紹,大家直接網上搜索就可以找到很多詳細的介紹,在此也就不再贅述。但基於這些淺層模型學習到的embedding存在一個嚴重的問題,那就是,每個詞只有一個固定的embedding,完全忽略了詞背景關係環境的不同對詞義的影響。比如說:
你別打擾他,他正在算賬呢。
好了,這回算你贏,下回我再跟你算賬!
再比如:
這些蘋果又大又紅。
你剛剛買的蘋果手機真不錯。
很明顯,這兩句中的“算賬”和“蘋果”完全是不同的含義。基於淺層模型學到的embedding更多學習的是詞與詞之間共現的一種機率分佈,學習到的語意和結構是的資訊對比Contextual 語言模型還是有限的,下文在ELMO部分我們想深入討論這一點。
Word embedding從我個人角度來看,應該算是一種基於預訓練(pretrained)的初始化的一種方式,這一思路可以算是深度學習誕生的精髓。2006年,傑弗裡·辛頓(G. Hinton)提出了深度學習的概念,隨後與其團隊在文章《A fast Learning Algorithm for Deep Belief Nets》中提出了深度學習模型之一,深度信念網路,並給出了一種高效的半監督演演算法:逐層貪心演演算法,來訓練深度信念網路的引數,打破了長期以來深度網路難以訓練的僵局。逐層貪心演演算法主要分為兩步:第一步是基於RBM的逐層無監督的初始化,第二步就是基於有監督的Fine-tuning;這一思路和當前流行的contextual pretrained model,Bert、GPT是一致的。雖然,GPT2透過大量的高質量單語料資料,無監督訓練40多層的,具有15億引數的Stack Transformer模型,可以不用task-specific的fine-tuning過程,也能再很多NLP任務上取得state-of-art的成績,但微軟最近刷遍各項NLP任務的MT-DNN已經證明瞭有監督的微調對於預訓練模型來說是非常重要的,它可以幫助把很多與task相關的知識融入到模型當中,讓模型,如GPT、Bert,不僅General,而且更加professional。
預訓練的思想一致伴隨著深度學習技術發展的歷程,它的核心思想就是藉助深度學習模型複雜的結構和強大的非線性表示學習能力,學習到海量資料種存在的本質(知識),把這些知識以向量或者引數的形式儲存起來,並透過feature或者parameter sharing的形式遷移到其他想相關的領域種。在自然語言領域中,這些共享的embedding或hidden state或model parameter往往編碼了豐富的詞法、句法和語意資訊。無監督的預訓練在影象領域獲得成功,特別是在出現了Imagenet這樣海量的、帶標記的、多類別(1000多類別)訓練樣本之後,預訓練模型已經成為影象領域的標配。有了這樣成功的經驗,很多NLP的應用研究人員就開始嘗試把預訓練的技術遷移到NLP領域來,於是在2018年,特別是Transformer模型在翻譯領域取得成功之後,豐富的NLP pretrained模型產生。本文,就詳細整理Contextual Pretrained Model的技術發展歷史,以及每個模型的原理,詳細對比這些模型之間的差異、使用場景等等。
以下主要內容主要整理和翻譯自lilianweng的個人部落格:https://lilianweng.github.io/lil-log/2019/01/31/generalized-language-models.html ,在此,感謝原作者的分享。
在這篇文章中,我們將討論各種依賴於背景關係來得到word embedding的各種模型產生和迭代過程,以及他們如何部署,以方便下游任務使用。
目錄
Cove
NMT回顧
在下游任務中使用CoVe
ELMO
雙向語言模型
ELMO表示
在下游任務中使用ELMO
Cross-View訓練
模型架構
多工學習
在下游任務中使用CVT
ULMFiT
OpenAI GPT
Transformer解碼器作為語言模型
BPE
無監督的微調
Bert
預訓練任務
輸入embedding
在下游任務中使用BERT
OpenAI GPT-2
Zero-Shot遷移
Byte序列的BPE
模型修改
總結
衡量標準:Perplexity
常見預訓練模型實現(Tensorflow or Pytorch)
Cove
ULMFit
ELMO
Transformer
Bert
Transformer-XL
GPT-2
常見任務和資料集
參考文獻
CoVe
論文:Learned in Translation: Contextualized Word Vectors
Cove(麥卡恩等人,2017年),是背景關係詞向量(Contextual Word Vectors)的縮寫,是一種由機器翻譯領域中的Seq2Seq + Attention模型的Encoder學習得到的word embedding。與傳統的word embedding不同,CoVe單詞表示是整個輸入句子的函式。
NMT回顧
神經機器翻譯( NMT )模型由標準的雙層雙向LSTM構成的編碼器,和帶Attention Module的雙層單向LSTM構成的解碼器組成。假設先採用英-德翻譯任務進行模型預訓練。編碼器學習並最佳化英語單詞的embedding,以便將其翻譯成德語。一般而言,編碼器應該在將單詞轉換成另一種語言之前捕獲該語言相關的高階語意和句法含義,編碼器輸出用於為各種下游語言任務提供基於背景關係化的word embedding。

圖1 CoVe中使用的NMT基本模型
源語言(英語)中n個單詞構成的序列: x=[x1,…,xn]。
標的語言(德語) 中的m單詞構成的序列: y=[y1,…,ym]。
源語言單詞Glove vector:Glove( x )。
標的語言種word的隨機初始化embedding向量: z=[z1,…,zm]。
biLSTM編碼器輸出的一系列隱狀態: h=[h1,…,hn]= biLSTM (Glove( x)),其中ht = [ h→t;h←t ] 正向和反向LSTM輸出的隱狀態。
帶註意力機制的解碼器輸出的t時刻word的分佈: p(yt∣H,y1,…,yt−1),其中H是沿著時間維度構成的隱狀態{h}:
解碼器的隱狀態:s(t) = LSTM([z(t-1); h^(t-1)], s(t-1))
註意力權重:α(t) = softmax(H(W1 s(t) + b1)
經過context-adjusted之後的隱狀態: h~(t) = tanh(w2[h⊤α(t);s(t) ] + b2 )
解碼器的輸出: p(yt∣h,y1,…,yt−1)=softmax(Wout h~(t)+bout )
在下游任務中使用CoVe
NMT編碼器輸出的隱狀態被定義為其他語言任務的背景關係向量(context vectors):
CoVe(x)=biLSTM (Glove( x))
原始論文建議將Glove和CoVe結合起來用於問答和分類任務。Glove從全域性單詞共現的頻率中學習,因此它沒有編碼單詞背景關係語境資訊,而CoVe是透過處理文字序列生成的,能夠捕捉單詞背景關係資訊。
v = [Glove( x );CoVe ( x ) ]
給定一個下游任務,我們首先生成輸入單詞的Glove+ CoVe拼接而成向量,然後將它們作為附加特徵饋送到task-specific模型中。

圖2 CoVe embedding是由經過機器翻譯任務訓練的編碼器生成的。編碼器可以嵌入到下游任何特定的模型種。(影象來源:原始論文)
總結: CoVe的侷限性是顯而易見的:
( 1 ) 預訓練受限於翻譯模型種可獲取的雙語資料集資料量的影響;
( 2 ) CoVe對最終效能的貢獻受與特定於任務相關的模型體系結構的限制。
隨後,ELMO透過無監督的預訓練方式剋服了問題( 1 ),OpenAI GPT & BERT透過無監督的預訓練+task-specific 的有監督的fine-tuning進一步剋服了這兩個問題。
ELMO
原始論文:Deep contextualized word representations
ELMO,是Embedding from Language Model的縮寫( Peters等人,2018年),透過無監督預訓練多層雙向LSTM模型來學習帶背景關係資訊的(Contextualized)單詞表示。
雙向語言模型
雙向語言模型( bi-LM )是ELMO的基礎。模型的輸入是由n個token構成的序列,( x1,…,xn),語言模型根據歷史的序列預測(x1…..xi-1)下一個token xi的機率。
在正向計算(forwar pass)過程中,根據歷史之前的序列(x1…..xi-1)預測第i個token xi的機率,

在反向計算(backward pass)過程中,根據歷史之後的序列(xi+1……xn)預測第i個token xi的機率,

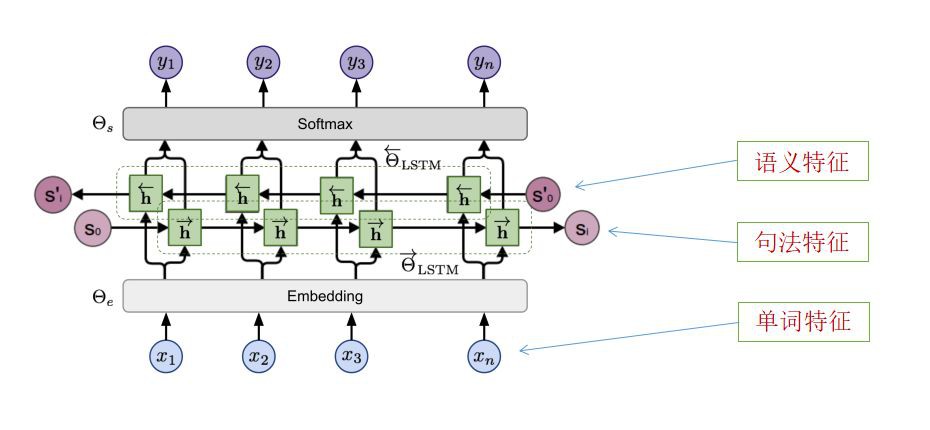
兩個方向上的預測過程都是由多層LSTMs建模的,給定輸入token xi得到隱狀態為h→i,ℓ和h←i,ℓ。最後一層的輸出的隱狀態為hi,L=[h→i,L;h←i,L]作為輸出層的輸入,用於得到最終的輸出yi。模型共享embedding層和softmax層,分別由θe和θs引數化表示。

圖3 ELMO的基於biLSTM的模型
該模型的標的函式(loss function)是最小化兩個方向的負對數似然( =最大化真實單詞的對數似然) :
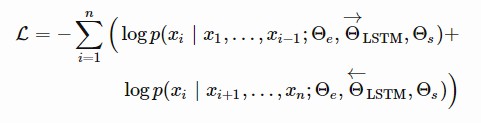
ELMO表示
在L層biLM之上,ELMO透過學習task-specific線性組合,將所有隱狀態stack在一起。token xi的隱狀態表示包含2L+1向量:
Ri={hi,ℓ∣ℓ=0,…,l},其中,h0,ℓ代表embedding層的輸出,且hi,ℓ=[h→i,ℓ;h←i,ℓ]。
S(task)表示加權求和中每個任務的權重(透過softmax進行歸一化)。縮放因子γ(task)用於校正biLM隱狀態分佈和task-specific表示分佈之間的不一致性。

為了評估不同層的隱狀態具體捕獲了什麼樣的資訊,ELMO分別被應用於語意密集型(semantic-intensive)和語法密集型(syntax-intensive)任務,使用biLM的不同層中的表示(Representation)處理:
語意(Semantic)任務:詞義消歧( word sense disambiguation,WSD )任務強調給定語境下單詞的含義。biLM最底層的輸出的表示比第一層的輸出的表示獲得更好的效果。
句法(Syntax)任務:詞性標註任務(POS)旨在推斷一個單詞在一個句子中的語法角色。實驗證明使用biLM第一層的輸出的表示可以比最底層的輸出表示獲得更高的精度。
對比研究表明,ELMO底層表示學習到了很多句法特徵,而在高層表示學習到更多語意特徵。
因為不同的層傾向於學習不同型別的資訊,所以將它們堆疊在一起會更有幫助。
在下游任務中使用ELMO
類似於CoVe可以幫助不同型別的下游任務,ELMO embedding也可以嵌入到下游不同型別任務的模型中。此外,對於某些任務(如SNLI和SQuAD,但不是SRL ),把ELMO embedding加入到輸出端也有幫助。
ELMO提出的改進對於具有少量監督訓練資料集的任務來說是非常有幫助的。有了ELMO,我們也可以用更少的標記資料來獲得更好的效能。
總結:語言模型的預訓練是無監督的,理論上,由於無標簽的文字語料庫非常豐富,預訓練可以盡可能地擴大規模。然而,它仍然依賴於task-specific的模型,因此這種改進只是漸進的,而為每個任務尋找一個好的模型架構仍然不是一件容易的事情。
ELMO仍然存在兩個比較明顯的不足:
1、使用Bi-LSTM模型構建語言模型,捕捉語意、長距離依賴和task-specific特徵抽取、平行計算的能力弱於基於Self-Attention的Transformer模型。論文《Why Self-Attention? A Targeted Evaluation of Neural Machine Translation Architectures》,已經證明Transformer已經在捕捉長距離特徵依賴、語意特徵、任務相關特徵和平行計算的能力,優於LSTM和CNN。關於CNN、LSTM和Transformer的詳細對比,可以參考張俊林老師的文章:《放棄幻想,全面擁抱Transformer:自然語言處理三大特徵抽取器(CNN/RNN/TF)比較》。
2、透過拼接(word embedding,Forward hidden state,backward hidden state)方式融合特徵的方式,削弱了語言模型特徵抽取的能力。
因此,GPT、BERT、MT-DNN和GPT-2基於Transformer構建LM,解決了問題一;對各種NLP任務進行改造,以適應pre-trained模型,即預訓練的模型結構不變,只是改變輸入的組織方式,很好的避免了問題2;具體的任務改造基本類似,這裡以BERT為例簡要介紹一下,後面會詳細介紹。
NLP中的任務多種多樣,大約有60多種,基本可以分為4類:
分類任務:句子分類、情感分類…..
序列標註任務:詞性標註(POS)、物體識別(NER)、分詞、語意角色標註(SRL)….
句子關係推理任務:蘊含關係判斷、問答、自然語言推理……
文字生成任務:機器翻譯、摘要抽取、機器創作……
分類任務,輸入整個句子,輸出一個類別標簽;序列標註任務,輸入一個token,輸出一個類別標簽;關係推理,則是將兩個句子拼接到一起作為輸入,輸出兩個句子直接的關係。Bert沒有給出文本生成的處理方法,GPT-2中給出了Auto-Regressive的方法來訓練語言模型,用於文字生成LM的訓練,簡單來說,輸入一句上文,輸出一個下一個token,再把該token作為輸入,不停地迭代生成一段話。
GPT、BERT、MT-DNN的訓練都分成兩步,第一步是無監督的預訓練,這和ELMO一致,目的是透過無監督的學習,充分利用海量的單語資料學習關於source language的詞法、句法和語意相關的feature;第二步是有監督的fine-tuning,將更多地task-specific相關的資訊融合到模型表示中,使學習到的只是更加professional,比如BERT當中的Next Sentence預測問題、MT-DNN中給出的Multi-Task的Fine-tuning等等。
因此,對於ELMO的改進主要有兩個重要的思路:
1、Task-Specific相關的Multi-Task微調(Fine Tuning),典型代表微軟的MT-DNN。
2、基於Transformer的Generative Pretrain(生成式預訓練),典型代表GPT。
這兩個思路又是如何產生的呢?首先要介紹下Cross-View訓練和ULMFiT模型。
Cross-View訓練
原始論文:Semi-Supervised Sequence Modeling with Cross-View Training
在ELMO中,兩個獨立的模型在兩個不同的訓練階段進行無監督的預訓練和task-specific的有監督地學習。Cross-View訓練(Cross-View Training,CVT;Clark等人,2018 )將兩個訓練階段組合成一個統一的半監督學習過程,其中bi-LSTM編碼器輸出的表示(representation)透過帶標簽資料上的監督學習和輔助任務(auxiliary tasks)上無標簽資料的無監督學習來改進。
模型架構
該模型由兩層雙向LSTM編碼器和初級預測模組(Primary Prediction Module)組成。在訓練過程中,交替給模型輸入帶標簽和不帶標簽的batch資料。
使用帶標簽的訓練樣本訓練模型時,所有的模型引數都透過標準的監督學習來更新。loss是標準的交叉熵。
無監督訓練時,初級預測模組仍然可以產生一個“soft”標的,儘管我們不知道它們的精確程度。在幾個輔助任務中,預測器只看到和處理與輸入相關的資訊,例如只在一個方向上使用編碼器隱狀態表示。期望輔助任務的輸出將與輸入的全域性相關的主要預測標的相匹配。
這樣,編碼器被迫將整個背景關係的知識提取為部分表示(partial representation)。在這個階段,biLSTM編碼器被反向傳播,但是主要預測模組是固定的。loss是最小化輔助預測和主要預測之間的差異(distance)。
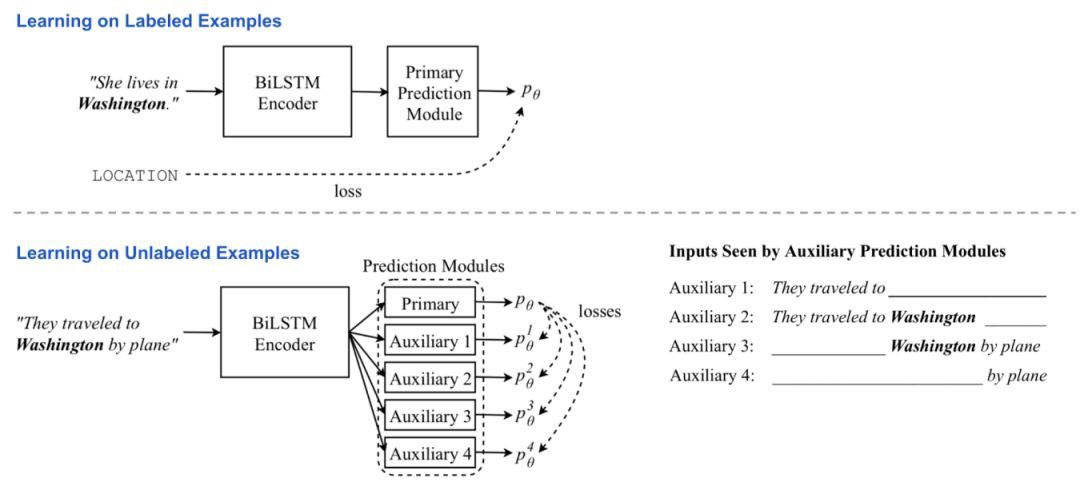
圖4 半監督語言模型cross-view訓練概述(影象來源:原始論文)
多工學習
當同時訓練多個任務時,CVT為額外的任務增加了幾個預測模型。它們都共享同一個句子表示編碼器。在有監督訓練期間,一旦隨機選擇了一項任務,相應預測器和表示編碼器(representation encoder)中的引數就會更新。對於無標簽的訓練樣本,透過最小化每個任務的輔助輸出和主要預測標的之間的差異這種聯合學習的方式來最佳化編碼器。
多工學習鼓勵模型學習更具通用性的representation,同時產生了一個不錯的副產品:來自無標簽資料的all-tasks-labeled 樣本。考慮到跨任務標簽是有用的,但是相當罕見,它們是寶貴的資料標簽。
在下游任務中使用CVT
理論上,主要的預測模組(primary prediction module)可以採用任何形式,通用或特定於某個任務的設計。CVT論文中的例子包括這兩種情況。
在像NER或POS類似的序列標註任務構成的聯合學習任務中,預測器模組的輸出端通常包含由兩個全連線層和一個softmax層構成的機率預測器,預測label機率分佈。對於每個token xi,我們採用對應的task輸出的隱狀態,h1(i)和h2(i)作為softmax層的輸入:

前向或後向LSTM狀態僅僅作為輔助任務第一層的輸入。因為他們只observe區域性的背景關係,無論是在左邊還是右邊,他們都必須像語言模型一樣學習,試圖根據背景關係預測下一個標簽。fwd和bwd輔助任務只朝著一個方向。未來和過去的任務分別在向前和向後的方向上向前邁進了一步。
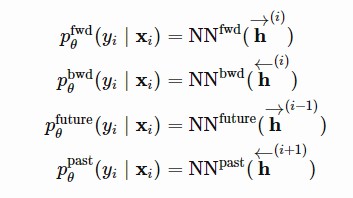
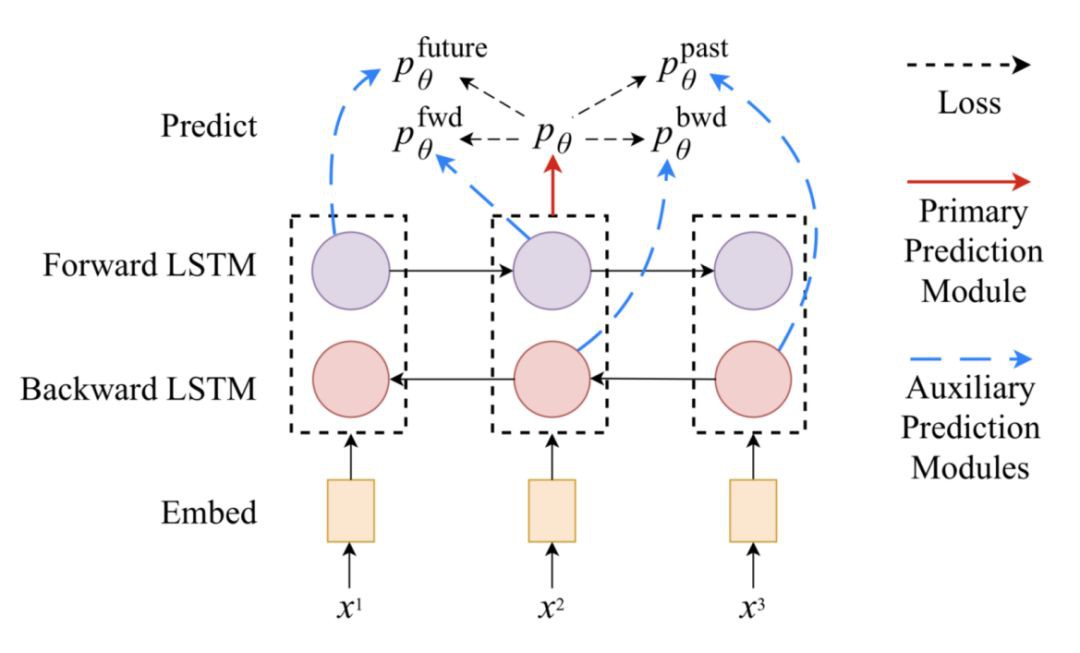
圖5 序列標註任務依賴於四個輔助預測模型,它們的輸入只涉及一個方向的隱狀態:向前、向後、未來和過去。(影象來源:原文)
請註意,如果主預測模組採用了dropout,則dropout層在使用有標簽資料進行訓練時照常工作,但在使用無標簽資料進行訓練期間為輔助任務生成“soft”標的時不適用。
在機器翻譯任務中,主要預測模組被一個標準的單向LSTM解碼器所取代,這是值得註意的。有兩個輔助任務: ( 1 )透過隨機將一些值歸零,dropout掉一些Attention權值;( 2 )預測標的序列中的未來單詞。輔助任務匹配的主要預測是透過在input sequence上執行固定的主要解碼器和beam search產生的最佳預測標的序列。
ULMFiT
原始論文:Universal Language Model Fine-tuning for Text Classification
ULMFiT( Howard & Ruder,2018年)首次嘗試了Generative Pretrained LM + Task-Specific微調的想法,其直接動機是ImageNet預訓練用於計算機視覺任務取得了巨大成功。基本模型是AWD-LSTM。
ULMFiT遵循三個步驟,併在下游語言分類任務種獲得了良好的遷移學習效果:
1 )一般LM預訓練:基於維基百科text資料。
2 )標的任務LM微調:ULMFiT提出了兩種用於穩定微調的訓練技術。見下文。
Discriminative微調的想法來源於LM的不同層捕獲不同型別的資訊(見上文討論)。ULMFiT建議用不同的學習率來調整不同的層,{η1….ηl…..ηL},其中,η1是第一層的基本學習率,ηL是L層的學習率。
傾斜三角形學習速率(Slanted triangular learning rate, STLR )是指一種特殊的學習速率調整策略,它首先線性增加學習速率,然後線性衰減。增加階段較短,因此模型可以快速收斂到適合任務的引數空間,而衰減週期較長,可以進行更好的微調。
3 )標的任務分類器微調:預處理LM後面增加了兩個FFN層,並增加了一個softmax層獲得標的輸出機率分佈。
串聯池化(Concat pooling)透過mean-pooling和max-pooling從歷史隱狀態種抽取特徵,拼接起來以得到最終的隱狀態。
逐步解凍(Gradual unfreezing)有助於避免Catastrophic Forgetting,方法是從最後一層開始逐漸unfreezing模型的層。首先,最後一層解凍並微調一個epoch。然後解凍下一層。重覆這個過程,直到所有的層都被tuned。
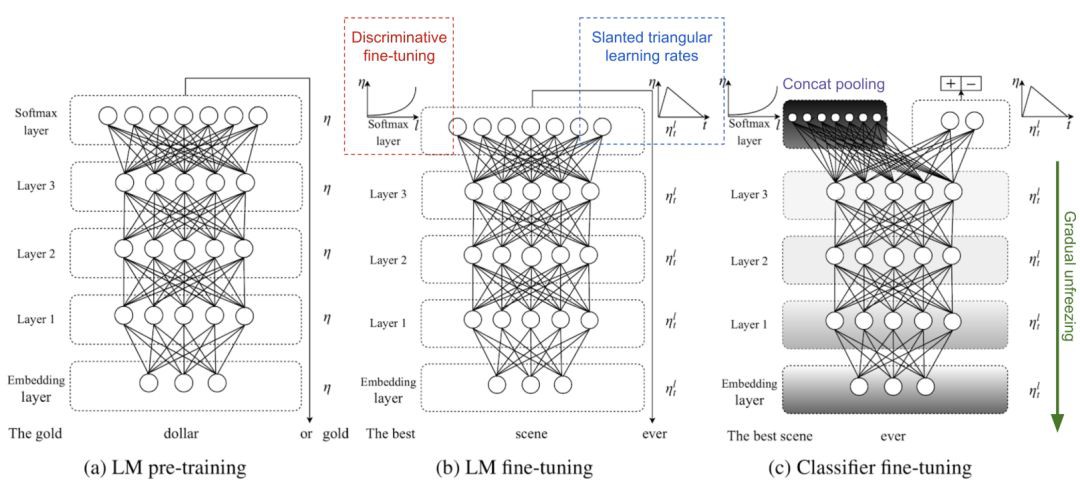
圖6 ULMFiT的三個訓練階段。(影象來源:原文)
開放式GPT
原始論文:Improving Language Understanding by Generative Pre-Training
與ELMO的想法類似,OpenAI GPT,Generative Pre-training Transformer的縮寫( Radford等人,2018年),透過在大量免費文字語料庫上進行訓練,將無監督語言模型擴充套件到更大的規模。儘管相似,GPT與ELMO有兩個主要區別。
1. 模型體系結構不同: ELMO模型透過獨立訓練的從左到右和從右到左多層LSTMs的簡單級聯構成,而GPT是一個多層單向的Transformer解碼器。
2. 在下游任務使用帶背景關係資訊的Embedding的方式不同: ELMO需要為特定的任務訓練特定模型,然後把embedding當作特徵提供給特地任務使用,而GPT對所有任務都是相同的模型。
Transformer解碼器作為語言模型
與傳統的Transformer架構相比,Transformer解碼器模型丟棄了編碼器部分,因此模型只有一個輸入。
輸入句子embedding經過多層Transfomer處理。每一層都由一個multi-head self-attention層和一個pointwise feed-forward層構成。最終經過softmax層輸出在標的token上的機率分佈。如圖7所示

圖7 OpenAI GPT中的Transformer解碼器模型架構
Loss是負對數似然度(negative log-likelihood),與ELMO相同,但沒有反向計算(序列從後往前的計算)。比方說,k大小的背景關係視窗位於標的單詞之前,損失如下:

有監督的微調
OpenAI GPT提出的最實質性的升級是擺脫task-specific模型,直接使用預先訓練的語言模型!
以分類為例。比方說,在帶標簽的資料集中,每個輸入都有n個標簽,x=(x1,…,xn),還有一個標簽y。GPT首先透過預先訓練的Transformer解碼器處理輸入序列x,最後一個token xn的最後一層輸出是hL(n)。然後,只有一個新的可訓練權重矩陣Wy,它可以預測類別標簽上的分佈。

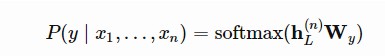
Loss是最小化真實標簽的負對數似然度。此外,新增LM loss作為輔助loss被認為是有益的,因為:
( 1 )它有助於在訓練期間加快收斂速度
( 2 )有望提高監督模型的泛化能力。
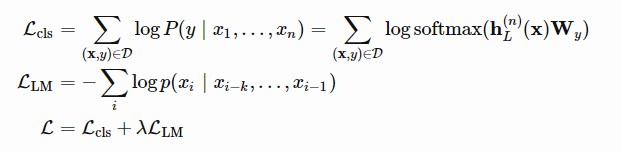
基於類似的設計,對於其他任何下游任務不需要更改網路結構(見圖8)。如果任務輸入包含多個句子,則在每對句子之間新增一個特殊的分隔符( $ )。這個定界符標簽的embedding是一個我們需要學習的新引數,但是它應該非常小。
對於句子相似性任務,因為排序無關緊要,所以兩個排序都包括在內。對於多項選擇任務,背景關係與每個答案候選項配對。
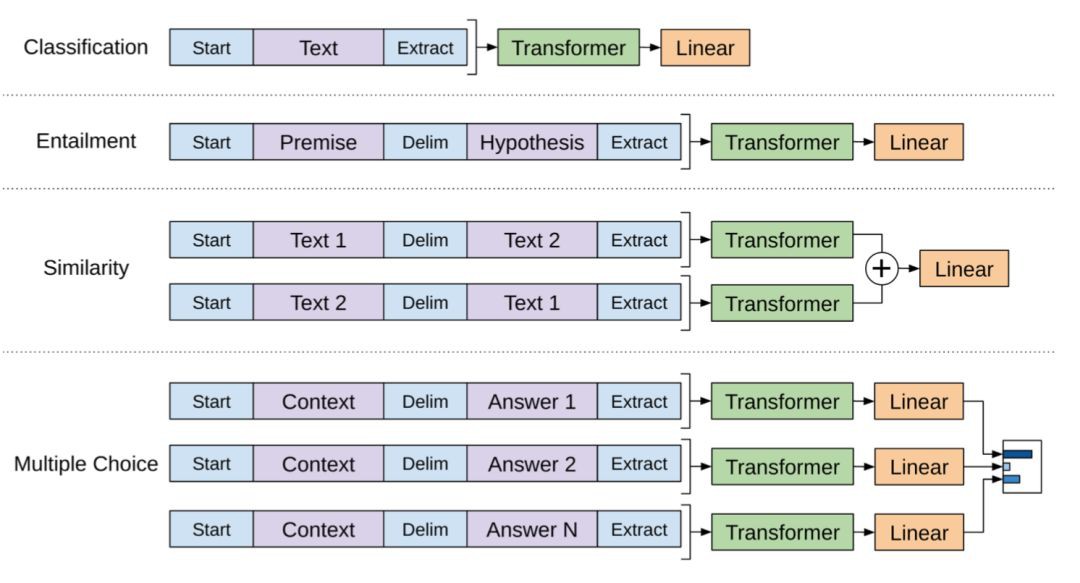
圖8 針對下游任務的稍加修改的GPT Transformer模型的輸入。(影象來源:原文)
總結:看到這樣一個通用的框架能夠在當時( 2018年6月)的大多數語言任務上擊敗SOTA,這是非常簡潔和令人鼓舞的。在第一階段,語言模型的生成性預訓練可以吸收盡可能多的自由文字(free text)。然後在第二個階段,利用小的帶標註資料集和一組最小的新引數對模型進行微調,以適應特定的任務。
GPT的一個侷限性是它的單向特性—該模型只被訓練來預測未來left-to-right context,這限制了GPT的學習能力,特別是後面Bert論文中實驗證明反向hidden representation對於模型學習是非常重要的(儘管,後來GPT-2證明,只要資料量大、資料質量足夠好、模型足夠複雜,其餘一切都是浮雲)。
BERT
原始論文:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
BERT,是Bidirectional Encoder Representations from Transformer的縮寫( Devlin等人,2019年)是GPT的直系後代:在自由文字上訓練一個大型語言模型,然後在沒有定製網路架構的情況下微調特定任務。
與GPT相比,BERT主要有3點不同:
1、最大的區別和改進是使訓練雙向Transformer進行預訓練。該模型學習預測左右兩邊的背景關係。根據ablation研究的論文聲稱:“我們模型的雙向性質是最重要的新貢獻”。
2、提出遮蔽語言模型( Mask language model,MLM )和Next Sentence來訓練模型。
3、對輸入Embbeding處理也不太一樣。
預訓練任務
BERT的模型架構是一個多層雙向Transformer編碼器。
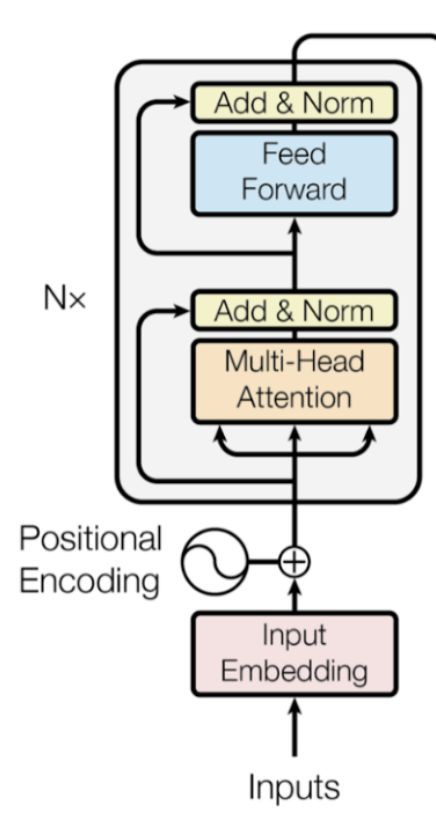
圖9 回顧Transformer編碼器模型架構。(影象來源:Transformer 論文)
為了鼓勵雙向預測和句子級理解,BERT的訓練被分成兩個輔助任務,而不是基本的語言任務(也就是說,在給定的背景關係中預測下一個標簽)。
任務1 :遮蔽語言模型( Mask language model,MLM )
毫無疑問的是,基於一個word雙向背景關係學習得到的representation,無論是句法上還是語意上,都比僅依賴上文學習到的representation要好。BERT透過對“掩碼語言模型”任務的訓練來鼓勵模型實現這一標的:
1. 隨機遮蔽每個序列中15 %的token。因為如果我們只用一個特殊的佔位符[MASK]替換遮蔽的token,那麼在微調期間將永遠不會遇到這個特殊的token。因此,BERT採用了幾種啟髮式技巧:
( a )以80 %的機率,用[MASK]替換所選單詞;
( b )以10 %的機率,替換為一個隨機的單詞;
( c )以10 %的機率,保持不變。
2. 該模型只預測缺失的單詞,但是它沒有關於哪些單詞已經被替換或者哪些單詞應該被預測的資訊。輸出大小僅為輸入大小的15 %。
這一思想其實和傳統的Skip-Gram模型中的Negative Sampling的思想其實很類似。
任務2 :下一句(Next sentence)預測
由於許多下游任務涉及理解句子之間的關係(即QA、NLI ),BERT增加了另一項輔助任務,訓練二進位制分類器來判斷一個句子是否是另一個句子的下一個句子:
1. 取樣句子對( A,B ),以便:
( a) 50%的時間,B跟隨A;
( b) 50%的時候,B不跟隨A。
2. 該模型處理兩個句子,並輸出一個二進位制標簽,指示B是否是A的下一個句子
上述兩項輔助任務的訓練資料可以從任何單語語料庫中輕鬆生成。因此,訓練的語料規模是無限的。訓練的loss是平均遮蔽LM似然和平均下一句預測似然之和。

圖10 BERT、OpenAI GPT和ELMO模型體系結構的比較。(影象來源:原文)
輸入embedding
輸入embedding是三個部分的總和:
1. WordPiece標簽化embedding: WordPiece模型最初是針對日語或韓語分詞問題提出的。代替使用自然拆分的英語單詞,它們可以被進一步劃分成更小的sub-word單元,以便更有效地處理稀有或未知的單詞。如果有興趣的話,請閱讀連結的論文,瞭解拆分單詞的最佳方式。
2. 片段(Segment)embedding:如果輸入包含兩個句子,它們分別有句子A embedding和句子B embedding,並且被特殊字元[SEP]分隔開;如果輸入只包含一個句子,則只使用句子A embedding。
3. 位置embedding:位置embedding是透過學習得到的,而不是硬編碼的。
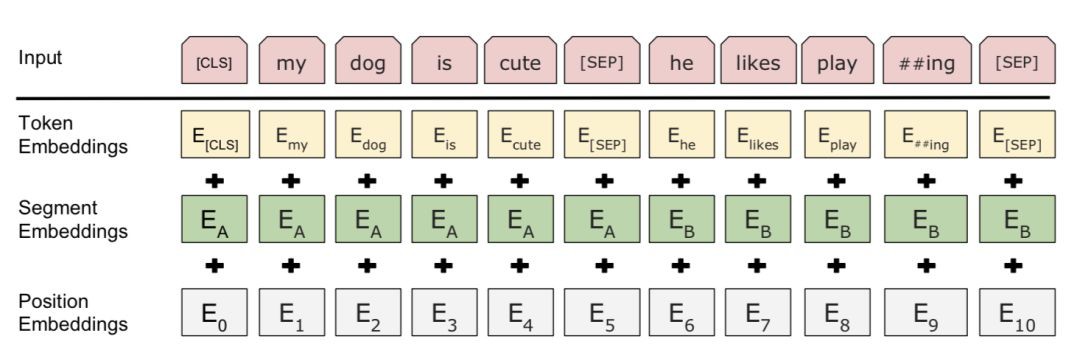
圖11 Bert輸入表示。(影象來源:原文)
請註意,第一個標簽都是[ CLS ]—一個佔位符,稍後將用於下游任務的預測。
在下游任務中使用BERT
BERT微調只需要新增幾個新引數,就像OpenAI GPT一樣。
對於分類任務,我們透過獲取特殊的第一token [CLS]、h L~ [ CLS ]的最終隱狀態,並將其乘以一個小權重矩陣,softmax(h L~ [ CLS ], Wcls),得到其預測輸出。
對於像SQuAD這樣的QA任務,我們需要預測給定問題在給定段落中的text span。BERT預測每個標簽的兩個機率分佈,即text span的開始和結束。只有兩個新的小矩陣,Ws和We,是在微調過程中新學到的,softmax( h(i)LWs )和oftmax(hL(i)We )定義了兩個機率分佈。
總的來說,用於下游任務微調的附加部分非常少—一兩個權重矩陣將Transformer的隱狀態轉換成可解釋的格式。檢視該論文以瞭解其他案例的實施細節。
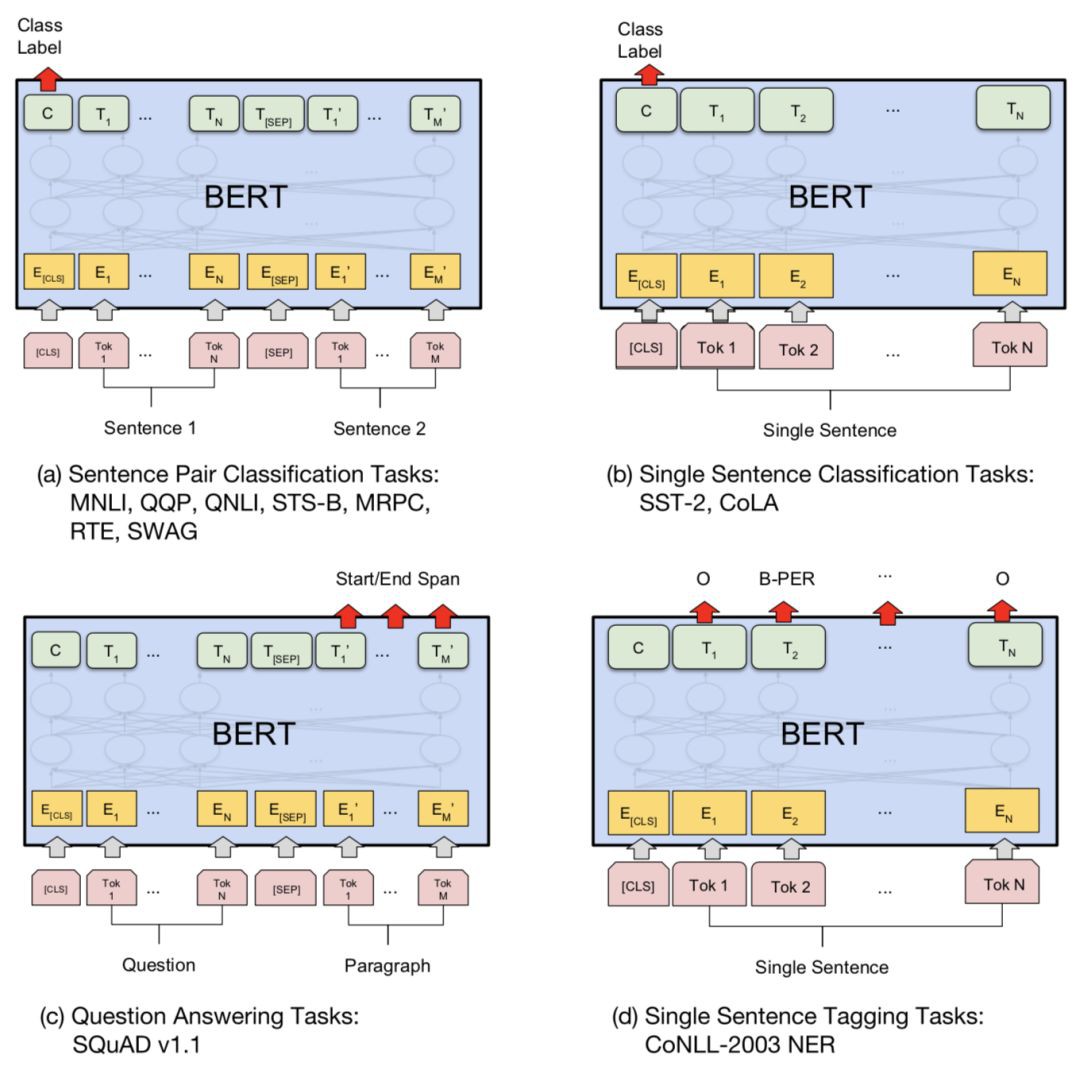
圖12 為下游任務在稍加修改的BERT模型中訓練標的。(影象來源:原文)
彙總表比較了OpenAI GPT和BERT fine-tuning之間的差異。
OpenAI GPT-2:Language Models are Unsupervised Multitask Learners
OpenAI GPT-2語言模型是GPT的直接繼承者。與GPT-2與GPT-1相比,模型結構基本一致,任然採用多層單向Transformer模型,主要是在訓練資料方面有很大不同:
1、資料量更大、更廣泛的訓練資料,Reddit上抓去了800萬各種型別的資料。
2、對訓練資料進行篩選,選擇更高質量的資料訓練網路。
3、GPT-2層數增加一倍,有1.5B的引數,比原始GPT多10倍,並且在Zero-Shot Transfer場景下,在8個測試語言建模資料集中的7個資料集上,獲得了SOTA結果。
4、一些細微的網路結構上的修改。
正是因為擁有了更加豐富、更大量的訓練資料,模型結構也比GPT-1更加複雜,學習到的Feature更加廣泛和準確。因此,OpenAI GPT-2的巨大改進在小資料集和用於測量長期相關性的資料集上尤為顯著。
Zero-Shot Transfer
GPT-2的預訓練任務僅僅包含第一步預訓練語言模型。所有下游語言任務都被構建為預測條件機率,沒有任務特定的微調。
LM模型非常適合處理文字生成任務(Text Generation)。
機器翻譯任務,比如,從英語到漢語,被構造出如下的條件LM:“英陳述句子=漢陳述句子”和“標的英陳述句子=”。
例如,條件機率的預測看起來像: P (?| I like green apples. = 我喜歡綠蘋果。A cat meows at him. =一隻貓對他喵。 It is raining cats and dogs. = ” )
QA任務的格式與機器翻譯類似,把問題和答案放在一起構成Context。
摘要抽取任務是在抽取完文章的背景關係資訊之後,透過新增TL:DR :來觸發的。
位元組序列上的BPE介紹
BPE
位元組對編碼( Byte Pair Encoding,BPE )用於編碼輸入序列。BPE最初是在20世紀90年代作為一種資料壓縮演演算法提出的,後來被用來解決機器翻譯中的開放詞彙(OOV詞)問題,因為當我們翻譯成一種新的語言時,很容易會遇到稀有和未知的單詞。出於稀有和未知單詞通常可以分解成多個子單詞的直覺,BPE透過迭代和貪婪地合併頻繁的字元對,找到了最佳的分詞方法。
與最初的GPT相同,GPT-2輸入採用BPE處理,使用UTF-8位元組序列。每個位元組可以在8 bits中表示256個不同的值,而UTF-8種一個字元最多可以使用4個位元組,總共支援最多231231個字元。因此,對於位元組序串列示,只需要大小為256的詞彙表,不需要擔心預處理、tokenization等。儘管有這些好處,當前位元組級(byte-level)的LMs與SOTA word-level的LMs的效能差距仍然不可忽略。
BPE透過貪心的方式合併頻繁共現的位元組對。以防止它生成多個版本的常用詞(比如對於dog,生成dog. dog! dog?),GPT-2防止BPE跨類別合併字元(因此dog不會與標點符號合併,如。,!還有?)。這些技巧有助於提高最終位元組分段的質量。
使用位元組序串列示,GPT-2能夠為任何Unicode字串分配機率,而不需要任何預處理步驟。
模型修改
與GPT相比,GPT-2除了具有更多的Transformer層和引數之外,只包含了很少的架構修改:
Layer normalization被移動到每個sub-block的輸入,類似於一種“building block”型別的殘差單元(不同於原始型別“bottleneck”,它在weight layers之前先進行batch normalization)。
在最終的自self-attention塊之後添加了額外的layer normalization。
初始化被修改為與模型深度相關的函式。
Residual layer的weights最初按1 / N的繫數縮放,其中N是殘餘層的數量。
使用更大的詞彙量和背景關係大小。
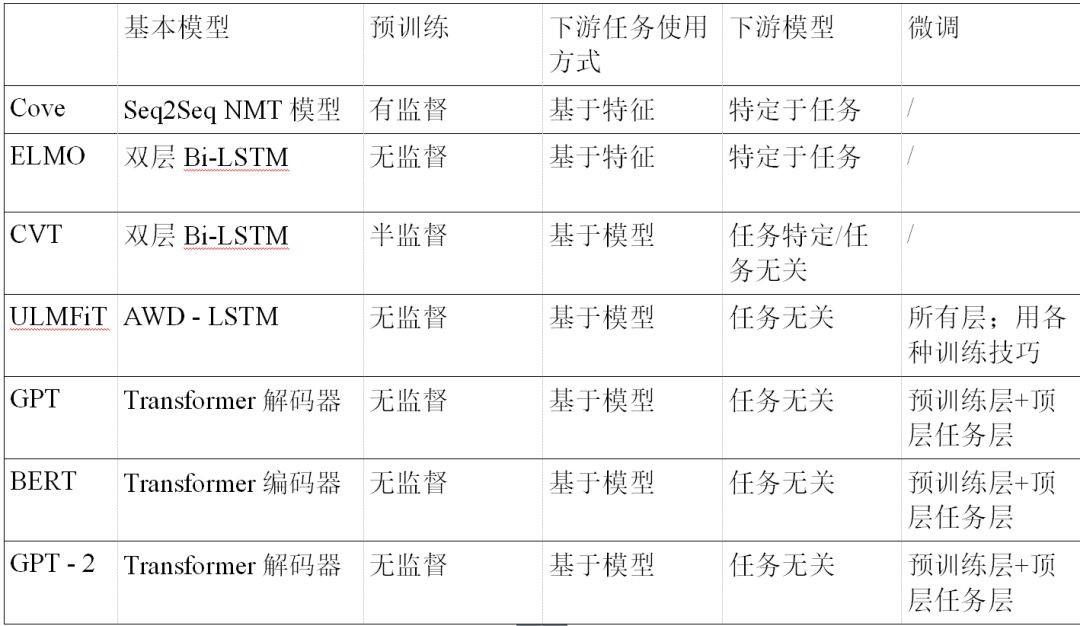
總結:現有流行Contextual-Based LM的對比。
衡量標準:Perplexity(Perplexity度)
Perplexity經常被用作一種內在的評估指標,用來衡量語言模型在多大程度上能夠捕捉到基於背景關係的真實單詞分佈。
離散機率分佈p的Perplexity被定義為熵的冪:

給定一個包含N單詞的句子,s=(w1,…,wN),熵計算公式如下,簡單地假設每個單詞有相同的頻率,1/N :

這句話的Perplexity變成了:

一個好的語言模型應該能預測高單詞機率。因此,Perplexity越小越好。
常見預訓練模型實現(Tensorflow or Pytorch)
Cove:《Learned in Translation: Contextualized Word Vectors》
Pytoch:https://github.com/salesforce/cove
Keras:https://github.com/rgsachin/CoVe
ULMFit:《Universal Language Model Fine-tuning for Text Classification》
PyTorch:https://github.com/fastai/fastai/tree/ulmfit_v1
ELMO:《Deep contextualized word representations》
PyTorch:https://github.com/allenai/allennlp
TensorFlow:https://github.com/allenai/bilm-tf
GPT-1:《Improving Language Understanding by Generative Pre-Training》
PyTorch:https://github.com/huggingface/pytorch-openai-transformer-lm
TensorFlow:https://github.com/openai/finetune-transformer-lm
Bert:《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》
PyTorch:https://github.com/huggingface/pytorch-pretrained-BERT
TensorFlow:https://github.com/google-research/bert
Transformer-XL:《Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context》
PyTorch:https://github.com/kimiyoung/transformer-xl/tree/master/tf
TensorFlow:https://github.com/kimiyoung/transformer-xl/tree/master/pytorch
XLM:《Cross-lingual Language Model Pretraining》
PyTorch:https://github.com/facebookresearch/XLM
GPT-2:《Language Models are Unsupervised Multitask Learners》
TensorFlow:https://github.com/openai/gpt-2
常見任務和資料集
問答
SQuAD(斯坦福問答資料集) :閱讀理解資料集,由維基百科的一組文章中提出的問題組成,每個問題的答案都是一段文字。
RACE (來自考試的閱讀理解) :一個大規模的閱讀理解資料集,有超過28000篇文章和近100000個問題。資料集是從中國的英語考試中收集的,這些考試是為中學生和高中生設計的。
常識推理
故事完形填空:評估故事理解和生成的常識推理框架。測試要求系統從兩個選項中選擇multi-sentence故事的正確結尾。
SWAG(Situations With Adversarial Generations):多種選擇;包含113k個句子對補全例子,用於評估基礎常識推理
自然語言推理( NLI ) :也稱為文字蘊涵,在邏輯上辨別一個句子是否可以從另一個句子中推斷出來。
RTE (識別文字蘊涵) :由文字蘊涵比賽產生的一組資料集。
SNLI (斯坦福自然語言推理) :由570000個人工書寫的英陳述句子對組成的集合,用entailment, contradiction和neutral的標簽進行平衡分類。
MNLI (多型別NLI ) :與SNLI相似,但有更多樣的文字風格和主題,從轉錄演講、通俗小說和政府報告中收集。
QNLI (問題NLI ) :從小隊資料集轉換為成對(問題、句子)的二進位制分類任務。
SciTail :由選擇題科學考試和網路句子建立的蘊涵資料集。
命名物體識別( NER ) :標簽文字中的單詞序列,這些單詞序列是事物的名稱,如個人和公司名稱,或者基因和蛋白質名稱
CoNLL 2003 NER任務:由路透社的新聞報道組成,主要關註四類命名物體:個人、地點、組織和其他物體的名稱。
OntoNotes 0.5 :這個語料庫包含英文、阿拉伯文和中文文字,用四種不同的物體型別( PER、LOC、ORG、MISC )標簽。
路透社語料庫:大量路透社新聞報道的集合。
細粒度的凈入學率
情感分析
SST:斯坦福情感分析資料集
IMDb :二分類的大型電影評論資料集。
語意角色標註( SRL ) :模擬句子的predicate-argument結構,通常被描述為回答“誰對誰做了什麼”。
CoNLL-2004和CoNLL-2005
句子相似性:也稱為釋義檢測
MRPC (微軟釋義語料庫) :它包含從網上新聞中抽取的成對的句子,帶的註釋表明每對句子在語意上是否相等。
QQP ( Quora問題對) STS標準資料集:語意文字相似性
句子可接受性:註釋句子語法可接受性的任務。
CoLA(語言可接受性語料庫):二進位制單句分類任務。
文字短語切分:將文字分成句法上相關的短語。
CONLL – 2000
詞性標註:在每個詞上標註詞性,如名詞、動詞、形容詞等。賓夕法尼亞樹庫的華爾街日報部分( Marcus等人,1993年)。
機器翻譯:參見Standard NLP頁面。
WMT 2015英語-捷克資料(大)
WMT 2014英語-德語資料(中)
IWSLT 2015年英語-越南語資料(小)
共指消歧:
Conll – 2012
長期依賴:
LAMBADA (語言建模擴充套件到了話語層面) :從BookCorpus中提取的一組敘事段落,任務是預測最後一個單詞,這需要至少50個背景關係標記,人類才能成功預測。
兒童書籍測試資料集:由Gutenberg專案免費提供的書籍製作而成。任務是預測10名candidate中缺失的單詞。
多工基準
GLE多工標準資料集: https://gluebenchmark.com
decaNLP基準資料集: https://decanlp.com
無監督預處理資料集
圖書語料庫:該語料庫包含“超過7000本來自包括冒險、幻想和浪漫在內的各種型別的獨特的未出版書籍”
1B文字語言模型語料庫
英文維基百科: ~ 2.5億字
參考文獻
[1] Bryan McCann, et al. “Learned in translation: Contextualized word vectors.” NIPS. 2017.
[2] Kevin Clark et al. “Semi-Supervised Sequence Modeling with Cross-View Training.” EMNLP 2018.
[3] Matthew E. Peters, et al. “Deep contextualized word representations.” NAACL-HLT 2017.
[4] OpenAI Blog “Improving Language Understanding with Unsupervised Learning”, June 11, 2018.
[5] OpenAI Blog “Better Language Models and Their Implications.” Feb 14, 2019.
[6] Jeremy Howard and Sebastian Ruder. “Universal language model fine-tuning for text classification.” ACL 2018.
[7] Alec Radford et al. “Improving Language Understanding by Generative Pre-Training”. OpenAI Blog, June 11, 2018.
[8] Jacob Devlin, et al. “BERT: Pre-training of deep bidirectional transformers for language understanding.” arXiv:1810.04805 (2018).
[9] Mike Schuster, and Kaisuke Nakajima. “Japanese and Korean voice search.” ICASSP. 2012.
[10] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
[11] Ashish Vaswani, et al. “Attention is all you need.” NIPS 2017.
[12] Peter J. Liu, et al. “Generating wikipedia by summarizing long sequences.” ICLR 2018.
[13] Sebastian Ruder. “10 Exciting Ideas of 2018 in NLP” Dec 2018.
[14] Alec Radford, et al. “Language Models are Unsupervised Multitask Learners.”. 2019.
[15] Rico Sennrich, et al. “Neural machine translation of rare words with subword units.” arXiv preprint arXiv:1508.07909. 2015.



DeepLearning_NLP


深度學習與NLP
商務合作請聯絡微訊號:lqfarmerlq
