
作者丨鄧雲天
學校丨哈佛大學NLP組博士生
研究方向丨自然語言處理
摘要
Attention 註意力模型在神經網路中被廣泛應用。在已有的工作中,Attention 機制一般是決定性的而非隨機變數。我們提出了將 Attention 建模成隱變數,並應用 VAE 和 policy gradient 訓練模型。在不使用 KL annealing 等 trick 的情況下訓練,在 IWSLT 14 German-English 上建立了新的 state-of-the-art。
■ 論文 | Latent Alignment and Variational Attention
■ 連結 | https://www.paperweekly.site/papers/2120
■ 原始碼 | https://github.com/harvardnlp/var-attn
背景
近年來很多文章將 VAE 應用到文字生成上,透過引入隱變數對文字中的一些不確定性(diversity,如文章風格主題、蘊含情感等)進行建模。這樣做往往會遇到一個常見的問題—— KL collapsing。這個問題最早在 16 年時由 Bowman 指出 [1],其描述的現象是直接訓練 VAE 得到的 KL 接近 0——這也就意味著近似後驗和先驗一樣,使得隱變數被模型忽略 [5]。
Bowman 的解決辦法是使用 KL annealing [1](KL 項的權重從 0 開始逐漸增加到 1)或者 word dropout(不常用在此略過)。隨後,17 年 Yang 等人對 KL collapsing 的問題進行了更細緻的分析 [2],並提出降低 decoder 的 contextual capacity 改善這個現象。此外 Zhao 等人提出 bag-of-word loss 去解決這個問題 [3]。18年 Graves 等人也對 KL collapsing 進行了分析 [4]。
在我們的工作中,Attention 被建模成隱變數。值得註意的是,我們將 Attention 建模成隱變數並不是為了單純應用 VAE 這個工具,而是因為我們認為將 Attention 建模成隱變數可以為 decoder 提供更 clean 的 feature,從而在不增加模型引數的情況下提高模型的表達能力(註意 inference network 在測試階段不被使用因此不計入模型引數)。
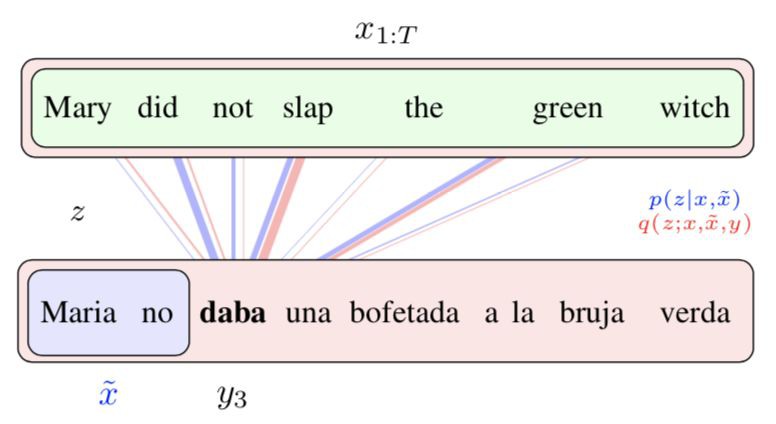
以下是一個簡單的直覺:下圖藍色部分展示的是傳統 Attention,下圖紅色部分展示的我們提出的隱變數 Attention。傳統的 Attention 機制僅能透過之前生成的單詞確定當前即將生成單詞的 Attention,而因為存在多種翻譯方式,所以會出現 attend 到和實際翻譯的單詞並不對應的位置的問題。而在紅色部分展示的我們提出的隱變數 Attention 中,我們可以透過全部的源文字和標的文字去得到更準確的後驗 Attention,因此 Attention 和實際翻譯應該 attend 的源單詞對應得更好。並且,這樣得到的更好的後驗 Attention 可以提供給 decoder,從而使 decoder 拿到更 clean 的 feature,藉此可以得到更好的模型。
方法
基於這個直覺,我們將註意力 Attention 建模成隱變數。假定 x 是源文字,y 是標的文字,z 是 attention,根據標準的 VAE 方法,我們引入 inference network q(z | x, y) 去近似後驗,那麼 ELBO 可以表達為(為了簡單我們考慮標的文字只有一個單詞的情況):

上面不等式的右側是 ELBO,其中第一項是從 q(z | x, y) 中取樣出 Attention,使用取樣出的 Attention 作為 decoder 的輸入計算 cross entropy loss,第二項是確保後驗分佈接近先驗分佈。這裡值得註意的是,此處的先驗和一般的 VAE 不同,我們的先驗是和模型一起學習的。
因為我們的 p(z | x) 和 q(z | x, y) 都是 categorical 分佈,所以我們使用 policy gradient 去最佳化上面的標的函式。由於 decoder 和 encoder 之間的主要資訊傳輸通道是透過 attention,如果忽略了這個隱變數,就會無法得到源文字的資訊而得到很大的 penalty。這與之前的許多工作中直接把隱變數加入到每個 decoding step 不同,因為那樣即使 decoder 忽略了隱變數,也可以達到很好的模型表現 [5]。因此透過直接最佳化標的函式這個隱變數也不易被忽略,我們的實驗完全驗證了這一點。
由於我們的後驗 q 能看到全部的 x 和 y,因此後驗中取樣的 Attention 可以比先驗 p(z | x) 好,比如以下的例子:

這裡我們把德語(縱向)翻譯成英語(橫向)。紅色代表先驗,即只觀測到 x 而不觀測到 y 的 p(z | x),藍色代表後驗,即觀測到全部資訊的 p(z | x, y)。註意到在第二個單詞 actually 處,紅色的先驗試圖 attend 到 nun 後面的逗號“,”,從而試圖生成一個 “well,” 的翻譯結果。然而實際的英語翻譯中並沒有逗號,反而直接是 well actually。
由於後驗 q(z | x, y) 可以看到實際的翻譯,因此藍色的後驗正確 attend 到了 tatsachlich 上。註意到訓練標的 ELBO 中我們從 q 中取樣 Attention 給 decoder,因此透過使用 VAE 的方法,decoder 得到了更準確的 Attention 訊號,從而可能提高模型的表達能力。
結果
實驗上,我們在 IWSLT 14 German-English 上得到了新的 state-of-art。其中 KL 大約在 0.5,cross entropy loss 大約在 1.26,而且我們人工比較了很多後驗和先驗也很符合我們的建模直覺。
歡迎嘗試我們的程式碼,我們提供了能復現我們 state-of-art 效果的 preprocessing、training、evaluation 的 command,以及我們報告的模型。
相比過去的大部分工作是從 Attention 計算出來的固定維度的 context vector,我們提出了將 Attention 建模成隱變數,即在 simplex 上的 Attention 本身。由於我們的工作是對 Attention 註意力機制的改進,因此理論上可以被應用到一切包含 Attention 的 task 中。文章裡除了機器翻譯外我們也做了個視覺問答系統的實驗。我們的具體模型和 inference network 的結構請參見我們的論文和程式碼。
限於作者的水平,本文中有錯誤和紕漏在所難免,望讀者朋友多多包涵。也歡迎發郵件給我 dengyuntian@seas.harvard.edu 交流。
參考文獻
[1]. Bowman et al, Generating Sentences from a Continuous Space
[2]. Yang et al, Improved Variational Autoencoders for Text Modeling using Dilated Convolutions
[3]. Zhao et al, Learning Discourse-level Diversity for Neural Dialog Models using Conditional Variational Autoencoders
[4]. Graves et al, Associative Compression Networks for Representation Learning
[5]. Zhang et al, Variational Neural Machine Translation

點選標題檢視更多論文解讀:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文