
作者丨徐邁、李天一 等
學校丨北京航空航天大學博士生
研究方向丨影片編碼與深度學習
本文概述了 2018 年 6 月發表在 IEEE TIP 期刊的論文 Reducing Complexity of HEVC : A Deep Learning Approach。在此論文中,北京航空航天大學博士研究生李天一及其導師徐邁,提出了一種基於深度學習的影片編碼複雜度最佳化方法,實現了在幾乎不影響編碼效率的前提下,顯著降低高效率影片編碼(High Efficiency Video Coding,HEVC)的複雜度。
■ 論文 | Reducing Complexity of HEVC: A Deep Learning Approach
■ 連結 | https://www.paperweekly.site/papers/2140
■ 原始碼 | https://github.com/HEVC-Projects/CPH
背景
與前一代 H.264/高階影片編碼(Advanced Video Coding,AVC)標準相比,HEVC 標準能夠在相同影片質量下,節省大約 50% 的位元率。這得益於一些先進的影片編碼技術,例如基於四叉樹結構的編碼單元(coding unit,CU)分割結構。然而這些技術也帶來了相當高的複雜度。與 H.264/AVC 相比,HEVC 的編碼時間平均增加約 253%,較高的複雜度就限制了該標準的實際應用。因此,有必要在率失真(rate-distortion,RD)效能幾乎不受影響的前提下,顯著降低 HEVC 編碼複雜度。
從 2013 年 HEVC 正式釋出開始,學界已經在降低編碼複雜度方向進行了廣泛的研究。目前已經存在多種降低 HEVC 編碼複雜度的方法。就編碼過程而言,基於四叉樹的遞迴 CU 分割搜尋,佔據絕大部分編碼時間(在標準參考軟體 HM 中用時超過80%),因此很多方法都透過簡化 CU 分割來降低 HEVC 編碼複雜度。
HEVC 中的 CU 分割結構如圖 1 所示。在標準編碼器中,CU 分割是一種遞迴的搜尋,從最基本的 64×64 編碼樹單元(Coding Tree Unit,CTU)開始,一個 CTU 可以只包含一個 CU,也可以被分成四個子 CU;每個子 CU 又可以選擇是否被分成四個更細的子 CU,以此類推,直到 CU 被分成最小尺寸 8×8 為止。
可見,從最大 64×64 到最小 8×8,多種可能的 CU 尺寸為 HEVC 標準提供了十分靈活的塊分割方式,使編碼器可以從中選出一種率失真代價最小的 CU 分割方案,作為實際編碼結果。
與 H.264 相比,可選擇的分割方案數增多,就更有希望找出率失真代價盡可能小的方案,這就是 HEVC 編碼效率較高的一個重要原因。然而,有利往往也有弊,更多種 CU 分割方案,就意味著編碼器需要花費更多時間,檢查每種方案的率失真代價。
這是一個分層遞迴的過程,編碼器需要對總共 85 個 CU(包括 64 個 8×8 的 CU,16 個 16×16 的 CU,4 個 32×32 的 CU 和 1 個 64×64 CU)編碼,以檢查每個 CU 的率失真代價。相比之下,在最終編碼結果中,只會存在最少 1 個、最多 64 個 CU,因此如果能提前預測出合理的 CU 分割結果,即可直接對所選的 CU 進行編碼,跳過不必要的率失真代價檢查過程。

▲ 圖1. HEVC中CU分割結構
早期的 CU 分割預測方法大多為啟髮式的,根據編碼中的一些特徵(如影象內容複雜度、率失真代價、運動向量資訊等)和人為制定的決策規則,在進行遞迴搜尋之前,提前決定 CU 分割。2015 年以後,利用機器學習預測 CU 分割的一些方法被陸續提出,例如用支援向量機的自動學習,彌補了先前方法中需要人為制定決策規則的缺點。
然而,上述方法中的特徵都需要手動提取,這在一定程度上依賴於研究者的先驗知識,難以確定選取的特徵是否為最優,並且容易忽略一些隱含但有用的特徵。為實現特徵自動提取,另有文獻透過搭建簡易的摺積神經網路(convolutional neural network,CNN)結構決定 CU 分割,初步實現了利用深度學習思想降低 HEVC 複雜度。
儘管相關研究已經取得諸多成果,在本文方法提出之前,已有文獻中的網路結構還比較淺,難以充分發揮深度學習的優勢,並且,先前基於 CNN 的方法都只適用於幀內樣式,對於實際應用更廣泛的幀間樣式則無能為力。
在設計演演算法之前,作者首先直觀地分析 CU 分割結果,如圖 2 所示,幀內樣式的 CU 結果主要由 CTU 中的影象內容決定,一般紋理越密集之處,CU 分割也越密集,反之亦反。當然 CU 分割不僅僅取決於紋理的細密程度,若一個 CU 中紋理比較密集,但恰好可以透過相鄰 CU 資訊來準確預測,那麼此 CU 也有可能不被分割。
無論如何,CU 分割結果和影象內容緊密相關,因此在幀內樣式中,本文首先提出一種與 CU 分割相適應的 CNN 結構,透過影象內容自動提取特徵,來學習 CU 分割結果。

▲ 圖2. 幀內樣式CTU內容與CU分割結果示例
對於幀間樣式,可以發現 CU 分割結果不僅與影片內容有關,還取決於相近幀內容的相似度。例如,在背景靜止或只有緩慢運動的影片中,CTU 中的內容可能比較細密,但可以由參考幀準確預測得到,那麼這個 CTU 很可能不被分割。
鑒於此,本文提出一種長-短期記憶(Long Short-Term Memory,LSTM)模型,以學習幀間樣式 CU 分割的時序依賴關係。在幀間樣式中,本文將 CNN 與 LSTM 結合使用,同時學習影片內容的空間和時間相關性。如圖 3 所示,將連續若干幀的 CTU 影象資訊輸入到 CNN+LSTM 中,預測每一幀的 CU 分割結果。另外,與幀內樣式不同,幀間樣式中輸入網路的是殘差影象,這是考慮到殘差影象本身就包含時間相關性資訊,有利於準確預測。

▲ 圖3. 幀間樣式CTU內容與CU分割結果示例
思路
確定總體思路後,作者首先構建一個大規模的 CU 分割資料庫,為訓練神經網路提供資料支撐,並有望促進 HEVC 編碼複雜度最佳化的後續研究。本資料庫同時涵蓋了幀內和幀間樣式的全部四種配置(All Intra,Low Delay P,Low Delay B 和 Random Access,簡稱 AI,LDP,LDB 和 RA),其中幀內樣式資料來自 2000 個無損影象,幀間的來自 111 個無損影片。所有資料均採用 4 個不同量化引數(Quantization Parameter,QP)壓縮,以適應不同位元速率和編碼質量。
在資料庫中,每個樣本由兩部分組成:CU 中影象內容構成的亮度矩陣,以及一個二分類標簽代表是否分割。表 1 顯示了本資料庫的樣本組成,可見在每種樣式中,都收集到超過 1 億個樣本,且正負樣本分佈大體均勻,保證能夠有效訓練。

▲ 表1. CU分割資料庫的樣本組成
在取得足量資料後,本文又提出一種分層 CU 分割圖(hierarchical CU partition map,HCPM),對整個 CTU 中的 CU 分割進行高效建模。傳統的 CU 分割預測,一般是把 CU 分割過程視為各自獨立的三級分類器,分別預測每個 64×64 的 CU、32×32 的 CU 和 16×16 的 CU 是否分割。然而,傳統方法每次預測只能得到一個 CU 的分割結果,若要得到整個 CTU 的分割結果,需要最多 21 次預測,計算量較大,並且會增加演演算法本身的計算時間。
為解決這一問題,在本文的 HCPM 中,可直接將一個 CTU 輸入到網路中,得到 1+4+16 個節點的結構化輸出,來預測 CTU 中所有可能的 CU 是否分割。
如圖 4 所示,對於一個 CTU,透過資料庫可以得到正確的 CU 分割結果,每個存在的 CU 都用 1 代表分割,0 代表不分割,即 HCPM 真值;將此 CTU 透過深度網路處理,會得到相應的 HCPM 預測值。網路的訓練就是使 HCPM 預測值盡可能接近真值。如此,透過構建高效的 HCPM,可以大幅節省演演算法本身的呼叫時間,有利於最終降低編碼複雜度的標的。

▲ 圖4. 分層CU分割圖示例(HCPM)
幀內樣式
下麵分別介紹幀內和幀間樣式中的深度神經網路結構。
在幀內樣式中,作者設計了一種可以提前終止的分層 CNN(early-terminated hierarchical CNN,ETH-CNN)。該網路輸入一個 64×64 CTU 的亮度資訊,輸出所有不同尺寸 CU 的分割機率,即前文所述的 HCPM。其中的提前終止機制,可以減少網路本身的時間複雜度。

▲ 圖5. ETH-CNN結構
ETH-CNN 包含兩個預處理層,三個摺積層,一個歸併層和三個全連線層,結構如圖 5 所示。各部分的具體配置與功能,闡述如下。
預處理層
對 CTU 原始亮度矩陣進行去均值和降取樣等預處理操作。為了適應最終的 HCPM 三級輸出,從預處理層開始,輸入資訊就在三條併列的分支 B1、B2 和 B3 中操作。
首先,在去均值操作中,CTU 的亮度矩陣減去影象整體或某一區域性的平均亮度,以減小影象間的亮度差異。之後,考慮到分割深度較淺的 CTU 一般對應平滑的影象內容,沒有過多細節資訊,因此在 B1 和 B2 中,對去均值的亮度矩陣進一步降取樣,將矩陣尺寸轉化為 16×16 和 32×32,進一步降低後續的計算複雜度。
並且,透過這種選擇性的降取樣,能保證後續摺積層的輸出尺寸(1×1、2×2 和 4×4)與 HCPM 的三級輸出標簽數相一致,使摺積層輸出結果具有比較清晰、明確的意義。
摺積層
在每條分支中,對預處理後的資料進行三層摺積操作。在同一層裡,所有三條分支的摺積核大小相同。首先,在第 1 摺積層中,預處理後資料與 16 個 4×4 的核進行摺積,獲得 16 種不同的特徵圖,以提取影象資訊中的低階特徵。在第 2、第 3 摺積層中,將上述特徵圖依次透過 24 個和 32 個 2×2 的核進行摺積,以提取較高階的特徵,最終在每條分支中均得到 32 種特徵圖。
所有摺積層中,摺積操作的步長等於核的邊長,恰好能實現無重疊的摺積運算,且大多數摺積核作用域為 8×8,16×16,32×32 或 64×64 等(邊長均為 2 的整數次冪),在位置和尺寸上都恰好對應各個互不重疊的 CU。因此,ETH-CNN 中的摺積與 HEVC 的 CU 分割過程相適應。
歸併層
將三條分支中第 2、第 3 摺積層的所有特徵歸併在一起,組合成一個向量。如圖 5 中間的藍色箭頭所示,歸併後的特徵由 6 種不同來源的特徵圖組合而成,這有助於獲得多種全域性與區域性特徵。
全連線層
將歸併後的特徵再次分為三條支路進行處理,同樣對應於 HCPM 中的三級輸出。由於經歷了特徵歸併,此處的任何一條支路都可以利用完整 CTU 中的特徵,來預測 HCPM 中某一級 CU 的分割結果。在每條支路中,特徵向量依次透過三個全連線層,包括兩個隱含層和一個輸出層,最終的輸出即為 HCPM 預測值。
此外,需要考慮量化引數 QP 對 CU 分割的影響。一般隨著 QP 減小,有更多的 CU 會被分割,反之,當 QP 增大時,則傾向於不分割。因此,在 ETH-CNN 的第一、第二全連線層中,將 QP 作為一個外部特徵,新增到特徵向量中,使網路能夠對 QP 與 CU 分割的關係進行建模,在不同 QP 下準確預測分割結果,提高演演算法對不同編碼質量和位元速率的適應性。
另外,透過 ETH-CNN 的提前終止機制,可以跳過第二、三級全連線層,以節省計算時間,即:如果第一級最大尺寸的 CU 不分割,則不需要計算第二級是否分割;如果第二級的 4 個 CU 都不分割,則不需要計算第三級是否分割。
其他層
在 CNN 訓練階段,將第一、第二全連線層的特徵分別以 50% 和 20% 的機率隨機丟棄(dropout),防止過擬合,提高網路的泛化能力。在訓練和測試階段,所有摺積層和第一、二個全連線層均用修正線性單元(rectified linear units, ReLU)啟用。所有分支的第三個全連線層,即輸出層,採用 S 形(sigmoid)函式進行啟用,使輸出值都位於 (0,1) 內,與 HCPM 中的二值化標簽相適應。
幀間樣式
在幀間樣式中,需要同時考慮 CTU 內容中的空間相關性,以及不同幀 CTU 內容的時間相關性。在 ETH-CNN 的基礎上,作者進一步提出可以提前終止的分層 LSTM(early-terminated hierarchical LSTM,ETH-LSTM),來學習幀間 CU 分割的長、短時依賴關係。

▲ 圖6. ETH-LSTM結構
ETH-LSTM 的結構如圖 6 所示。由於幀間樣式同樣需要提取 CTU 中的空間特徵,首先,仍然將 CTU 輸入到 ETH-CNN 中。但與幀內樣式不同,幀間樣式的網路輸入是殘差 CTU 的亮度資訊,而不是原始 CTU 的亮度資訊。這裡的殘差,是透過對當前幀進行快速預編碼獲得的,此過程與標準編碼過程相似,唯一區別是將 CU 和 PU 強制設為最大尺寸 64×64,以節省編碼時間。
儘管額外的預編碼過程帶來了時間冗餘,但這種冗餘只佔標準編碼時間的 3%,不會顯著影響演演算法的最終效能。將殘差 CTU 透過 ETH-CNN 進行處理後,把第 7 層(即第 1 個全連線層)三個支路輸出的特徵向量,送入到 ETH-LSTM 的三級,以備後續處理。
在 ETH-LSTM 中,第 1、2、3 級各有一個 LSTM 單元。每個 LSTM 單元接受當前時刻的輸入向量(即 CNN 處理後的特徵),以及上一時刻 LSTM 產生的狀態向量,由此來更新當前時刻 LSTM 的狀態向量和輸出向量。LSTM 單元的輸出向量,再依次透過兩個全連線層做進一步處理,最終得到 HCPM 所需的二值化 CU 分割機率。
與幀內樣式類似,此處的每個全連線層也考慮了外部特徵:QP 值和當前幀在 GOP 中的幀順序,以適應不同編碼質量和幀位置對 CU 分割的影響。與 ETH-CNN 類似,ETH-LSTM 中同樣引入提前終止機制,以減少 ETH-LSTM 中的計算冗餘。最終,將 ETH-LSTM 中三個級別的輸出聯合起來,即可得到 HCPM 預測結果。
實驗
在測試本方法效能時,選用 18 個 HEVC 標準影片以及本文影象資料庫中的 200 幅測試影象,保證測試資料的多樣性和代表性,在 QP 22,27,32,37 和全部四種標準配置(AI,LDP,LDB 和 RA)下,用標準 HEVC 編碼器和作者改進後的編碼器分別進行編碼,比較編碼時間的減少率和率失真效能。幀內和幀間樣式的測試結果如表 2 和表 3 所示。

▲ 表2. 幀內樣式複雜度和率失真效能對比

▲ 表3. 幀間樣式複雜度和率失真效能對比
兩表中的 BD-BR 和 BD-PSNR 是衡量率失真效能的關鍵指標,代表相同質量下的位元速率變化和相同位元速率下的質量變化。在編碼複雜度最佳化中,對塊分割的快速判決並不是絕對準確,因此所有演演算法都會不同程度地帶來率失真損失,即 BD-BR>0,BD-PSNR<0。這兩項指標的絕對值越小,說明對率失真效能的不利影響越小,演演算法越優。表中的 ΔT 為編碼時間節省率,絕對值越大說明演演算法越優。可見,本文方法在率失真效能優於先前方法的前提下,能夠更有效地降低編碼複雜度。
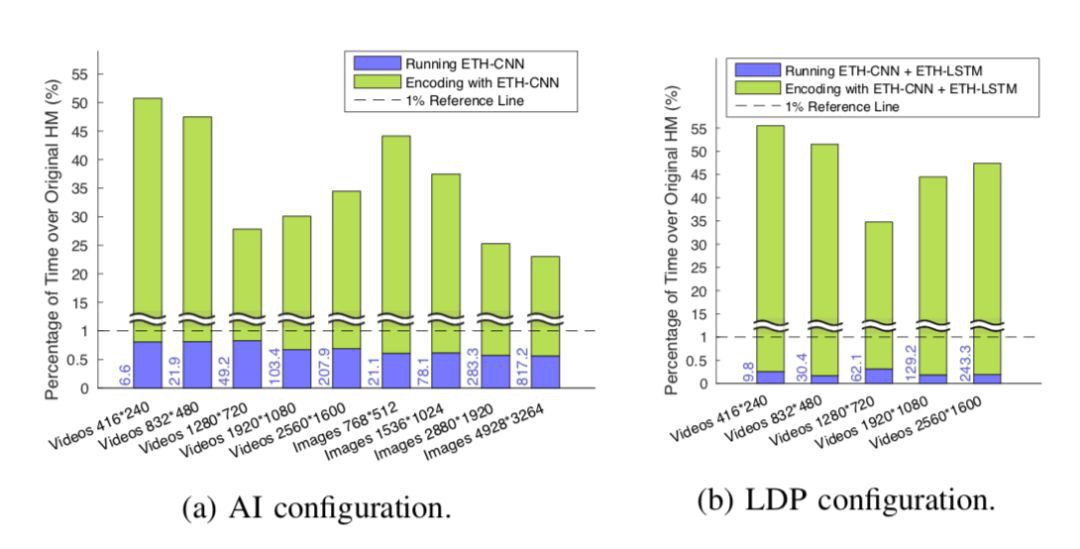
▲ 圖7. 編碼時間構成。藍柱和綠柱代表網路執行時間和本方法中HM編碼時間佔原編碼時間的百分比,柱左側的藍色數字代表網路執行的絕對時間(單位毫秒)
總結
至此,已經說明瞭本文方法的有效性。兼顧良好的複雜度和率失真效能,是因為深度神經網路能夠準確預測 CU 分割。另一個自然而然的問題是:既然網路層數和引數都比較多,網路本身的執行是否比較費時,影響總的編碼時間?
實際上,如圖 7 所示,無論在幀內或幀間樣式,網路本身的執行時間都不超過原編碼時間的 1%,因此幾乎不會影響最終的編碼複雜度。這得益於獨特的、適用於 CU 分割的網路結構,包括三個主要原因:
1. 首先,CU 分割結果採用高效的 HCPM 表示,呼叫一次 CNN(或 CNN+LSTM),即可預測整個 CTU 中所有 CU 的分割結果,使網路執行次數遠少於傳統方法中分別預測每個 CU;
2. 其次,ETH-CNN 中的摺積層跨度等於核的寬度,即摺積核間無重疊,這與傳統的有重疊摺積相比,複雜度能降低到幾分之一到幾十分之一;
3. 另外,ETH-CNN 和 ETH-LSTM 都提供了提前終止機制,能夠根據上一級 CU 分割結果跳過下一級的一部分運算。
以上幾個原因,使得深度網路本身執行時間遠小於 HM 編碼時間,保證了本文方法降低編碼複雜度的可行性和有效性。

點選標題檢視更多論文解讀:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文
