來自:CU技術社群(微訊號:ChinaUnix2013)
從事Linux主機建設和運維的同事們在工作中應該經常會遇到批次修改配置資訊或部署應用環境的需求,需要根據需求依次登入標的主機執行一些命令或指令碼,使用shell指令碼的迴圈陳述句是實現這一需求最直觀方式。但是普通的for或do while迴圈都是序列執行的,指令碼耗時每個迴圈耗時*迴圈次數,在較大規模實施或者標的陳述句耗時較長的情況下,序列方式的迴圈指令碼執行時間也不容忽視。
要減少執行序列迴圈的耗時,自然要考慮如何用並行方式解決。在shell之外有一些現成的管理部署工具如parallel、ansible、puppet、saltstack都能解決併發執行多工的問題,但生產系統一般不允許隨意安裝新軟體,因而我們這裡只討論不借助工具,只使用shell指令碼如何實現併發執行多工。
序列執行迴圈時,指令碼中每一次迴圈對應的子行程都是指令碼執行所處shell的前臺行程,同一時間一個shell只能有一個前臺行程,要做到並行執行多個行程,意味著指令碼中的迴圈要放到執行環境shell的後臺,作為後臺行程去執行。
根據這個思路來看一下例1:
1例1 直接使用後臺執行
先來看下迴圈序列執行的情況。
指令碼的迴圈內容以sleep為例,下同。
vi para-0.sh
|
#!/bin/bash Njob=15 #任務總數 for ((i=0; i { echo “progress $i is sleeping for 3 seconds zzz…” sleep 3 } done echo -e “time-consuming: $SECONDS seconds” #顯示指令碼執行耗時 |
執行結果如下圖所示:

可以看到指令碼執行時間45秒與預期15輪*3秒一致。
如果開啟另一個視窗watch sleep行程的話,可以看到同一時刻只有1個sleep行程在跑:

修改指令碼,採用迴圈並行執行的方式。
vi para-1.sh
|
#!/bin/bash Njob=15 for ((i=0; i echo “progress $i is sleeping for 3 seconds zzz…” sleep 3 & #迴圈內容放到後臺執行 done wait #等待迴圈結束再執行wait後面的內容 echo -e “time-consuming: $SECONDS seconds” #顯示指令碼執行耗時 |
執行結果如下圖所示:

可以看到指令碼執行耗時為3秒,與預期1輪*3秒一致。
watch sleep行程,可以看到同一時刻有15個PPID相同的sleep行程在跑:

這種方式從功能上實現了使用shell指令碼並行執行多個迴圈行程,但是它缺乏控制機制。
for設定了Njob次迴圈,同一時間Linux就觸發Njob個行程一起執行。假設for裡面執行的是scp,在沒有pam_limits和cgroup限制的情況下,很有可能同一時刻過多的scp任務會耗盡系統的磁碟IO、連線數、頻寬等資源,導致正常的業務受到影響。
一個應對辦法是在for迴圈裡面再巢狀一層迴圈,這樣同一時間,系統最多隻會執行內嵌迴圈限制值的個數的行程。不過還有一個問題,for後面的wait命令以迴圈中最慢的行程結束為結束(水桶效應)。如果巢狀迴圈中有某一個行程執行過程較慢,那麼整體這一輪內嵌迴圈的執行時間就等於這個“慢”行程的執行時間,整體下來指令碼的執行效率還是受到影響的。

下麵的例2和例3能夠有效避免這些問題。
2例2 使用模擬佇列來控制行程數量
要控制後臺同一時刻的行程數量,需要在原有迴圈的基礎上增加管理機制。
一個方法是以for迴圈的子行程PID做為佇列元素,模擬一個限定最大行程數的佇列(只是一個長度固定的陣列,並不是真實的佇列)。佇列的初始長度為0,迴圈每建立一個行程,就讓佇列長度+1。當佇列長度到達設定的併發行程限制數之後,每隔一段時間檢查佇列,如果佇列長度還是等於限制值,那麼不做操作,繼續輪詢;如果檢測到有併發行程執行結束了,那麼佇列長度-1,輪詢檢測到佇列長度小於限制值後,會啟動下一個待執行的行程,直至所有等待執行的併發行程全部執行完。


執行結果如下圖所示:
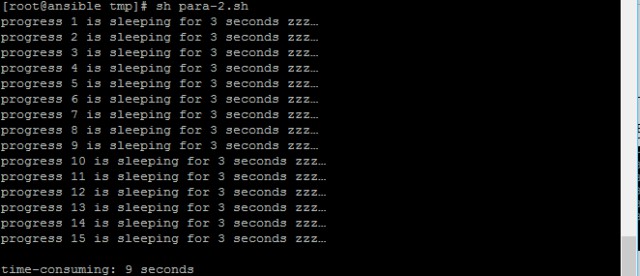
可以看到指令碼執行時間9秒與預期3輪*3秒一致。
watch sleep行程,可以看到同一時刻只有5個sleep行程在跑,與我們限制的數量相符:

這種使用佇列模型管理行程的方式在控制了後臺行程數量的情況下,還能避免個別“慢”行程影響整體耗時的問題:
3例3 使用fifo管道特性來控制行程數量
管道是核心中的一個單向的資料通道,同時也是一個資料佇列。具有一個讀取端與一個寫入端,每一端對應著一個檔案描述符。
命名管道即FIFO檔案,透過命名管道可以在不相關的行程之間交換資料。FIFO有路徑名與之相關聯,以一種特殊裝置檔案形式存在於檔案系統中。
FIFO有兩種用途:
•FIFO由shell使用以便資料從一條管道線傳輸到另一條,為此無需建立臨時檔案,常見的操作cat file|grepkeyword就是這種使用方式;
•FIFO用於客戶行程-伺服器行程程式中,已在客戶行程與伺服器行程之間傳送資料,下麵的例子將使用這種方式。
根據FIFO檔案的讀規則(參考http://www.cnblogs.com/yxmx/articles/1599187.html),如果有行程寫開啟FIFO,且當前FIFO內沒有資料,對於設定了阻塞標誌的讀操作來說,將一直阻塞狀態。
利用這一特性可以實現一個令牌機制。設定一個行數等於限定最大行程數Nproc的fifo檔案,在for迴圈中設定建立一個行程時先read一次fifo檔案,行程結束時再write一次fifo檔案。如果當前子行程數達到限定最大行程數Nproc,則fifo檔案為空,後續執行的併發行程被讀fifo命令阻塞,迴圈內容被沒有觸發,直至有某一個併發行程執行結果並做寫操作(相當於將令牌還給池子)。
需要註意的是,當併發數較大時,多個併發行程即使在使用sleep相同秒數模擬時,也會存在行程排程的順序問題,因而並不是按啟動順序結束的,可能會後啟動的行程先結束。

執行結果如下圖所示:
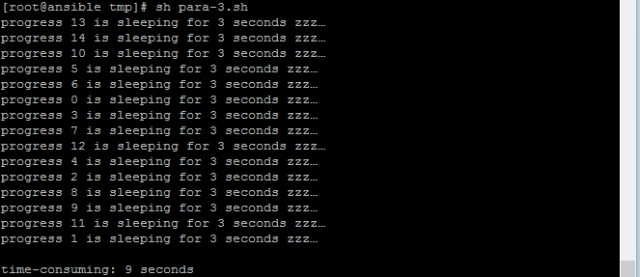
可以看到指令碼執行時間9秒與預期3輪*3秒一致。
watch sleep行程,同樣可以看到同一時刻只有5個sleep行程。
4總結
並行多行程的迴圈陳述句能提高指令碼執行效率。
例1這種沒有控制機制,同一時間可能觸發大量併發行程的指令碼在生產環境中儘量避免使用,巢狀迴圈也儘量少用。
例2例3分別使用陣列元素模擬佇列和利用fifo讀寫阻塞性兩種方式實現了後臺行程數量的控制,適宜作為批次操作的shell指令碼模版。
5後記
關於執行順序的問題,把例2採用佇列方式的例子中的動作 sleep 3修改成sleep$[$RANDOM/10000*5],執行結果仍然是順序的。雖然例3的方式其執行過程是亂序的,考慮到如果使用指令碼只是查詢統計資訊,可以利用Excel中的lookup、match、indirect函式進行資訊整理,也是行得通的。
●編號557,輸入編號直達本文
●輸入m獲取文章目錄

運維
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
