在開展微服務的過程中,瞭解要考慮哪些因素可能是非常有挑戰性的事情。沒有可以直接使用的金科玉律。每個過程都是不同的,因為每個組織面臨的都是不同的環境。在本文中,我將從初創公司的角度分享我們學習到的經驗和麵臨的挑戰,以及我下次引入微服務時,會在哪些方面採取不同的做法。
核心要點
- 從一個易於抽取的小候選功能開始,以便於儘早獲得微服務的體驗;
- 要預先重點關註構建和部署自動化以及監控;
- 儘早處理橫切性的關註點,避免給生產效率帶來負面的影響,比如為單體應用繼續增加功能或者為每個微服務重新實現橫切性的關註點;
- 將系統的事件驅動功能設計得易於演化,考慮採用事件流的方案以減少資料副本的成本並降低新增新微服務的門檻;
- 需要註意,轉換至微服務的過程並不是獨立運轉的。相反,它受到很多環境因素的影響。當心那些阻礙你前進或拖你後腿的環境因素,對它們進行相應的調整,或者至少要在整個組織中意識到這些問題。
在開展微服務的過程中,瞭解要考慮哪些因素可能是非常有挑戰性的事情,對於小團隊來講更是如此。遺憾的是,沒有可以直接使用的金科玉律。每個過程都是不同的,因為每個組織面臨的都是不同的環境。在本文中,我將從初創公司的角度分享我們學習到的經驗和麵臨的挑戰,以及我下次引入微服務時,會在哪些方面採取不同的做法。
從單體應用到微服務的旅程該如何開始?
最初,從各個方面看,我都是從單體應用開始的:我們整個團隊基於一個相互協作的產品開展工作,將其實現為同一個程式碼庫並且基於同一個技術棧。在一段時間內,這種方式能夠很好地運轉。

隨著時間的推移,所有的事情都在演化:團隊在增長,我們為產品不斷新增越來越多的特性,程式碼庫變得越來越大,使用者的數量也在不斷增長。這聽起來非常不錯,對吧?但是……
現在,要完成一件事情需要非常長的時間:會議、討論和決策都要比以往消耗更長的時間。職責無法清晰地劃分,明確具體責任需要花費一定的時間,比如當出現了 bug 的時候。我們的過程變得更加緩慢,生產效率也受到了影響。
我們新增的特性越多,產品使用起來就越複雜。產品的可用性和使用者體驗因為不斷的特性修改而受損。我們不但沒有很好地解決使用者的問題,反而讓他們更加困惑。
因為採用單體軟體架構,我們很難在不影響整個系統的情況下新增新的特性,釋放新的變更也變得非常複雜,即便我們只修改了幾行程式碼,也需要重新構建和部署整個產品。這導致部署會具有很高的風險性,因此部署的頻率也不那麼頻繁,因為新特性的釋出非常緩慢。

因此,對系統進行分離和轉換的需求就出現了。
在三年前,我們改變了產品策略。我們關註可用性和使用者體驗的提升並將我們的產品 JUST SOCIAL 拆分成了多個獨立的應用,其中每個應用負責特定的場景。我們不斷演化這個理念,提供不同的應用來共享檔案、實時交流、管理任務、共享可編輯的內容和協作的新聞以及管理 profile。
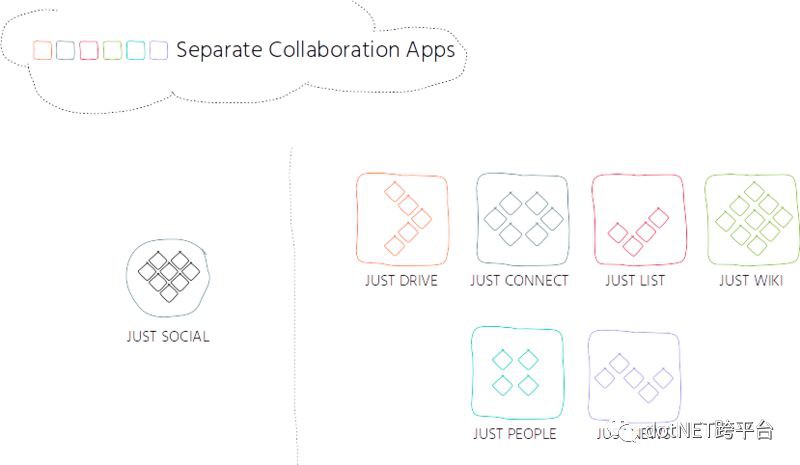
同時,我們將整個團隊拆分成了多個更小的團隊,併為每個團隊分派了特定的一組協作應用(collaboration app),從而實現定義了良好的職責劃分。我們想要建立自治化的團隊,能夠讓他們按照自己的節奏獨立地圍繞系統不同的組成部分開展工作,將跨團隊的影響降低到最小。
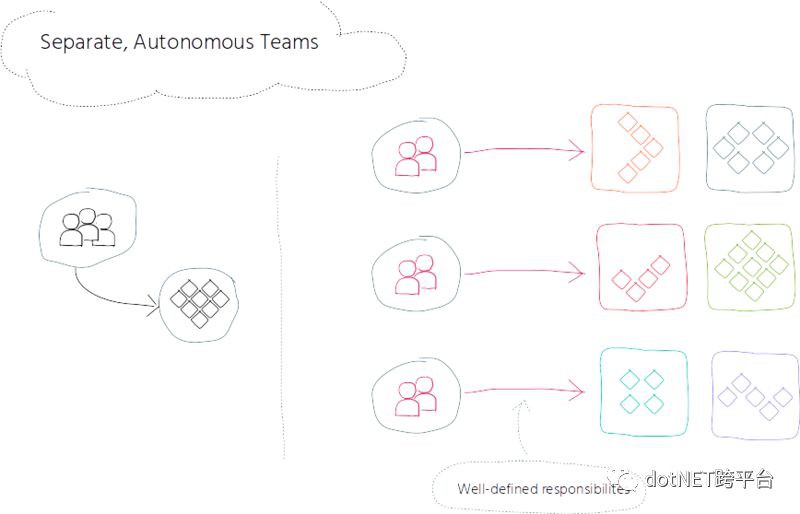
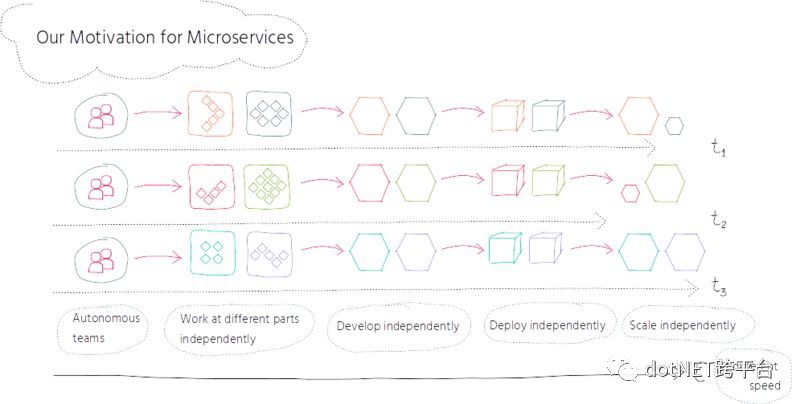
在將我們的產品拆分為多個獨立的協作應用並將團隊分為多個更小的團隊之後,接下來順理成章的步驟就是將自治性和靈活性反映到軟體架構中,這是透過引入微服務實現的。
我們引入微服務的驅動力在於讓系統的不同組成部分能夠實現自治,讓他們按照自己獨立的節奏開展工作,將跨團隊的影響降到最低。透過獨立地開發、部署和擴充套件協同應用,我們希望能夠快速地釋出變更。
我們的微服務之旅首先是從識別適合採取微服務的候選功能開始的。為了識別合適的候選功能,我們必須要考慮如何建模良好服務的核心概念。核心概念遵循服務間松耦合和服務內高內聚的原則。服務內的高內聚通常反映在保持相關行為的一致性方面。在領域驅動設計中,相關行為反應為限界背景關係(Bounded Context)。限界背景關係是領域模型中的語意邊界,服務會負責定義良好的一個業務功能,限界背景關係會對服務進行描述。

在我們的場景中,我們使用協作應用作為高層級的限界背景關係,它反映了粗粒度的服務邊界。這是一個很好的起點,後續我們會將它們拆分為更加細粒度的服務層。

我們首先從 JUST DRIVE 的限界背景關係開始,也就是負責檔案管理的協作應用。每個檔案都是由作者建立的。作者相關的資料來自 profile,而後者又是由 profile 管理的限界背景關係來進行管理的,這個功能依然位於單體應用中。

我們從頭構建了一個共存(co-existing)的服務。它實際上並不完全與當前功能的相同,相反,我們引入了新的 UI、添加了更多的特性並將資料結構做了重大的變更。新服務的限界背景關係包括負責業務邏輯的領域模型、編排用例的和管理事務的應用服務以及輸入輸出的配接器,比如 REST 端點和用於持久化管理的配接器。新服務會獨佔檔案狀態,也就是說,它是唯一能夠讀取和寫入檔案的服務。
如前文所述,每個檔案都是由作者建立的,作者的資料來源於單體應用所管理的 profile 資料。

那麼問題就來了,新服務和單體應用之間該如何互動呢?
為了避免每次展現檔案的時候都從 profile 服務中獲取作者資料,我們在新的服務中保留了相關作者資料的一個本地副本。只要不破壞資料的所有權,資料冗餘是沒有問題的,在我們這個場景中,只要 profile 相關的限界背景關係依然獨佔 profile 狀態即可。
由於本地副本和原始的資料會隨著時間的推移而產生差異,所以單體應用需要在 profile 更新的時候通知我們。在 profile 發生變化的時候,單體應用會釋出一個 ProfileUpdatedEvent 事件,新服務需要訂閱這個事件。新服務消費該事件並相應地更新本地副本。

這種事件驅動的服務整合方式降低了服務之間的耦合,因為我們現在不需要跨背景關係遠端直接查詢單體應用了。這種方式增加了自治性,新服務能夠對本地副本做任何事情,而且能夠讓資料連線(join)更加高效,因為它可以使用本地副本連線作者資料,無需透過網路。
我們從頭構建了一個共存的服務,並且為了實現資料複製的目的,引入了事件驅動形式的服務互動。
我們遇到了什麼挑戰以及是如何解決的
從頭開始構建共存的服務通常是一種很好的分解策略,當你想要擺脫某些東西的束縛時,更是如此,比如想要脫離過時的業務邏輯或者現有的技術棧。但是在解耦第一個服務的時候,我們一次性做了太多的事情。如前文所述,我們不僅從頭構建了一個共存的服務,還引入了新的 UI、添加了更多的特性,還對資料結構做了重大的變更。在開始的時候,我們承擔了太多的責任,所以在很晚的時候才看到結果。但是,在開始階段,快速得到結果以獲取使用微服務的經驗和信心是非常重要的。

在下一個備選服務中,我們採取了不同的方式。我們關註 chat 應用的高層級限界背景關係,並遵循自上而下的漸進式分解策略,逐步抽取已有的程式碼。我們首先將 UI 抽取為單獨的 Web 應用,併在單體應用側引入了 REST-API,這樣被抽取出來 Web 應用可以訪問該 API。在這一步,我們可以獨立地開發和部署 Web 應用,從而能夠對 UI 進行快速迭代。

在抽取完 UI 之後,我們就可以更進一步,解耦業務邏輯。分解業務邏輯會對程式碼帶來重大的變更。根據依賴關係,我們可能需要提供一個臨時的 REST API 供單體應用使用,以解決業務邏輯抽取後所帶來的問題。此時,我們依然共享相同的資料儲存。
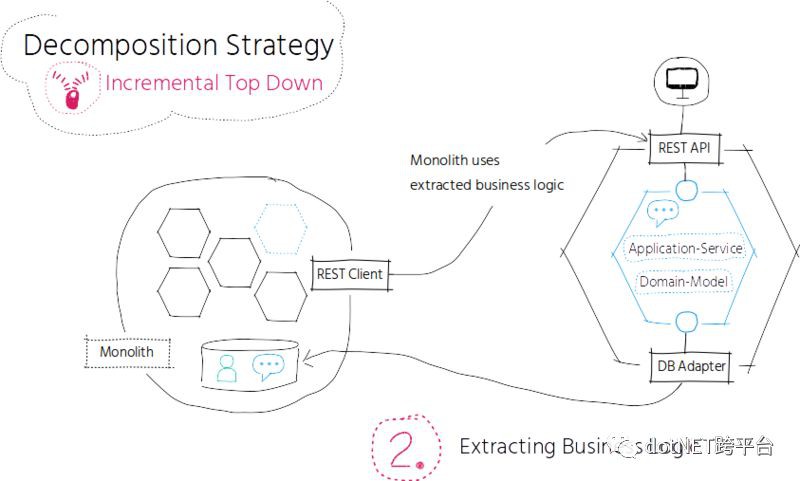
為了實現非耦合的獨立服務,我們最終需要切分資料儲存,以確保新服務能夠獨佔 chat 的狀態。
在每個 chat 討論中,都會涉及到參與者。chat 參與者的資料來源於單體應用中的 profile 資料。如前面描述的 DRIVE 樣例類似,我們儲存一個 chat 參與者資料的本地副本,並訂閱 ProfileUpdatedEvent 事件,從而讓本地副本資料與單體應用中原始資料的保持同步。

從此處開始,我們就可以繼續從單體應用中抽取下一個限界背景關係,或者將我們的粗粒度服務隨後拆分為更細粒度的服務。
另外一項挑戰是對授權的處理
幾乎對於每個服務,我們都會面臨如何授權的問題。我為你描述一個背景:授權處理是非常細粒度的,一直向下延伸到領域物件級別。每個協作應用都要控制其領域物件的許可權,比如檔案的許可權是由該檔案所在的父檔案夾的授權設定來控制的。
另一方面,授權不僅僅是細粒度的,還依賴於服務之間的互動,在某些場景下,領域物件的授權還依賴於父領域物件的授權資訊,而父領域物件的授權資訊是位於其他服務中的,比如,要讀取某個內容頁相關的檔案或者為內容頁新增檔案的話,需要依賴於這個頁面的授權設定,而這個頁面的授權配置位於與檔案本身不同的服務中。
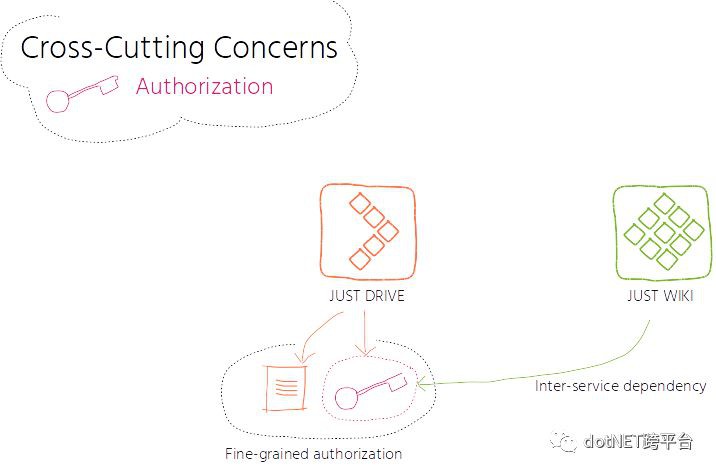
因為這些複雜的需求,解決分散式授權的問題給我們帶來了很大的困擾,而且我們沒有在早期提供解決方案。這樣帶來的結果完全適得其反。其中一個後果就是我們添加了一個新的服務到單體應用中,而單體應用其實早就已經解決過授權的問題了。我們讓單體應用變得更大了,而不是讓它變得更小。另外一個後果就是,我們開始在每個服務上都實現授權。起初,這種做法看上去是合理的,因為我們最初的假設是授權屬於領域模型所在的限界背景關係,但是我們忽略了服務之間的依賴關係。所以,我們不斷地來回覆制資料,增加了衝突的風險。

長話短說:我們最終將授權處理合併到了一個中心化的微服務中。
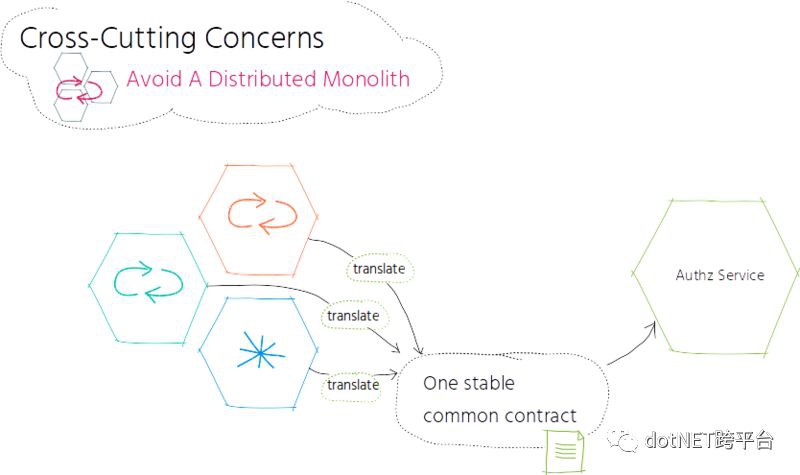
與中心化服務一併出現的是引入分散式單體應用的風險。當修改系統中的某一部分時,你必須要同時修改其他的組成部分,這是已引入分散式單體應用的強烈訊號。以我們的場景為例,當引入需要授權的新協作應用時,我們需要同時修改中心化的授權服務。我們同時遇到了單體應用和分散式應用的缺點:服務是緊耦合的,而且服務還需要透過緩慢、不穩定的網路來進行通訊。

於是,我們提供了一個通用的契約,這個契約屬於授權服務,所有的下游服務都必須要遵守該契約。在我們的場景中,服務會將授權相關的行為轉換成授權服務能夠理解的契約,授權服務不需要額外的轉換。這種轉換是在每個下游服務中發生的,而不是在中心化的授權服務中發生的。這種通用契約能夠確保我們在引入新的服務時,不需要同時修改和重新部署中心化的認證服務了。有個先決條件是這個通用的契約是穩定的,或者說至少向下相容,否則的話,我們會將問題轉移給下游服務,這會導致它們需要不斷進行更新。
我們學習到了什麼
在開始階段需要特別註意,最好從易於提取的小型服務開始,以便於快速得到結果並獲取使用微服務的早期經驗。如果要處理粗粒度的大型服務,就我們而言,將拆分過程分為增量式的步驟會更加易於管理,例如增量式地由上到下進行分解,也就是每次只執行一個可管理的步驟。

儘早處理橫切性的關註點非常重要,這樣能夠避免適得其反的後果,比如不斷擴大單體應用而不是縮減它,或者在每個服務中都重新實現橫切性的關註點。

在引入中心化的橫切服務時,需要註意不要引入分散式單體應用。在這種情況下,通用且穩定的契約能夠幫助我們避免出現分散式單體應用。

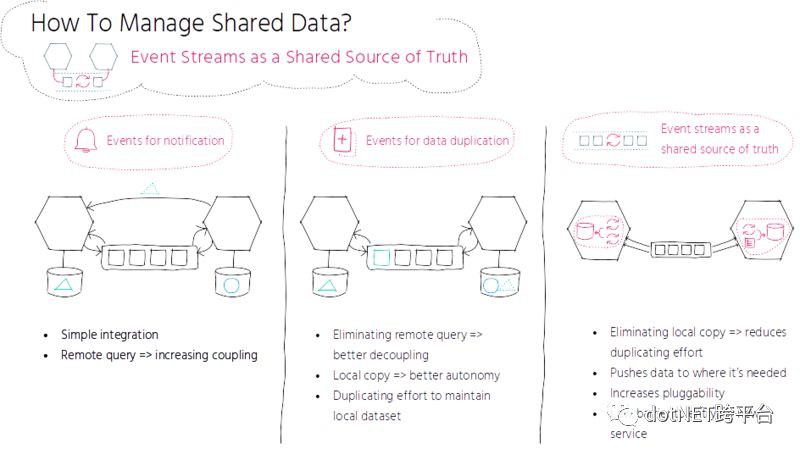
要設計易於演化的系統,事件驅動的服務互動方式是實現服務間高度解耦的關鍵。事件可以用作通知,也可以用於生成資料副本(關於事件驅動的狀態轉移,參見上文關於從頭構建共存服務的內容),我們還可以透過長期保留事件將事件儲存作為主要的資料源。

當事件單純用於通知的目的時,其他背景關係中的額外資料通常會以跨背景關係查詢的方式直接進行請求,比如 REST 請求。我們可能會更喜歡遠端查詢的簡潔性,而不願處理本地維護資料集所帶來的開銷,在資料集會不斷增長的情況下更是如此。但是遠端查詢增加了服務之間的耦合性,並且在執行時將服務系結在了一起。
我們可以將對其他背景關係的遠端查詢進行內部化處理,這是透過引入相關跨背景關係資料的本地副本來實現的。如上面的 JUST DRIVE 樣例所述,為了避免每次展現檔案的時候都從 profile 服務中請求相關的作者資料,我們複製了作者資料,併在檔案微服務中保留了一個本地副本。我們需要保證副本資料和原始資料的同步,這意味著當原始資料變化的時候,要立即同步我們的本地副本。為了獲取已修改資料的通知,服務需要訂閱包含資料變化的事件並相應地更新本地副本。在本例中,事件是用來生成資料副本的,這樣能夠避免遠端查詢並降低服務之間的耦合性。這種方式也能實現更好的自治性,因為服務能夠對本地副本執行任何操作。
對於事件驅動服務的互動,我們在早期就引入了 Apache Kafka,這是一個分散式、具有容錯性、可擴充套件的日誌提交服務。最初,我們使用 Apache Kafka 的主要目的是實現通知和生成資料副本的功能。最近,我們引入 Apache Kafka Streams 作為共享的事實源,以減少資料複製的開銷並實現服務的高可插拔性,降低新服務進入的壁壘。
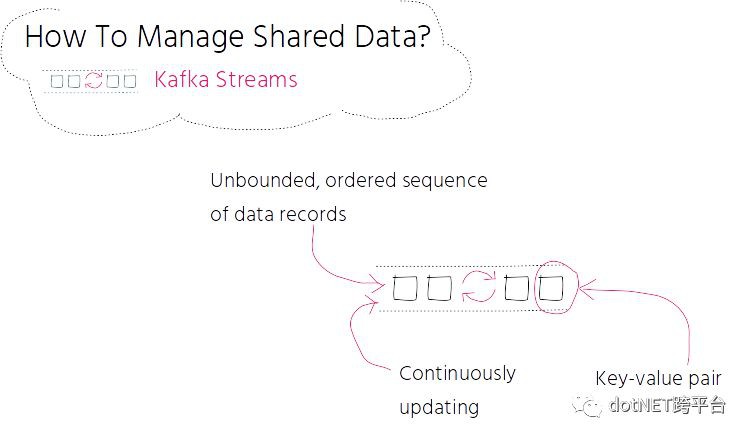
流是無界有序且持續更新的結構化資料記錄組成的序列。資料記錄有一個 key-value 對組成。
當你的服務在 Apache Kafka 流背景關係中啟動時,Kafka 主題將會載入到你的流中,你可以在服務的範圍內處理它。主題通常是一個邏輯分類,表明瞭哪些服務可以釋出和訂閱。每個流都會緩衝到一個狀態儲存中,這是一個輕量級的基於硬碟的資料。載入的流會在你自己的程式碼中使用,不會在 Kafka 代理中執行,它執行在你的微服務行程中。流能夠讓資料出現在任何需要的地方,這會增強效能和自治性。

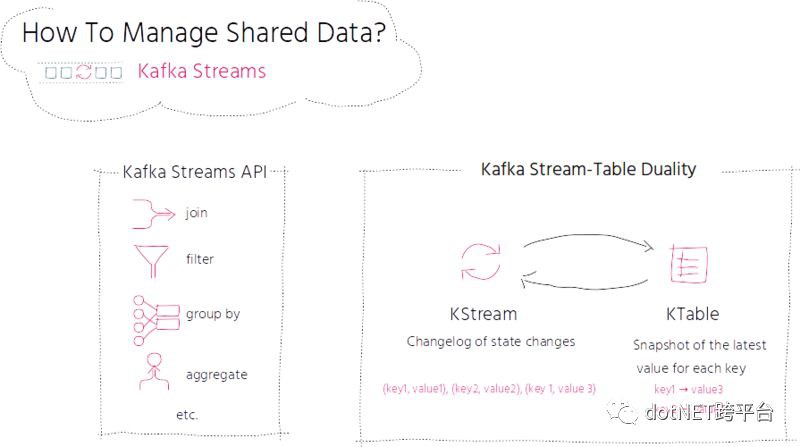
Apache Kafka 提供了一個 Stream API。Stream 可以藉助領域特定語言(Domain Specific Language,DSL)進行連線、過濾、分組或聚合,流中的每條訊息都可以使用類似函式的操作進行處理,比如對映、轉換或窺探等。
在實現流處理的時候,通常會同時需要流以及進行功能增強的資料庫。Kafka 的 Streams API 透過對流和表的核心抽象提供了該功能。在流和表之前其實存在緊密的關聯關係,也就是所謂的流 – 表二元性(stream-table duality)。流可以看做表的變更日誌,流中的每條資料記錄都捕獲了表中的一次狀態變更。表可以視為快照,對應於流中每個 key 的最新值。
當我們想要展現一條檔案及其作者資料時,藉助 Kafka Streams,我們可以這樣做:檔案服務根據 document 主題建立一個 KStream,並根據 profile 主題得到的作者相關 profile 資料來完善該檔案。在這個增強的過程中,檔案服務會根據 profile 主題建立 KTable。現在,我們可以將流和表進行連線,並將它的結果儲存為新的狀態儲存,這樣就可以在外部進行訪問了,執行方式類似於內建的 Materialized View。每當 profile 或檔案更新的時候,它相關的 Materialized View 也會進行更新。

將 Apache Kafka Streams 與其他的事件驅動方式進行對比的話,它不需要維護本地副本,這減少了維護資料副本和保持資料同步的開銷。Apache Kafka Streams 會將資料推送到需要的地方,並且執行在與服務相同的行程中。它增加了可插拔性,你可以插入新的服務並立即使用流,不需要搭建額外的資料儲存。它能夠減少開銷,增強效能、自治性並降低新服務的進入壁壘。
這個轉換的過程並不是隔離執行的,它會受到各種環境因素的影響:團隊的規模、結構和技能都會影響到怎樣做才是可控的,尤其是在開始階段,如果是一個的團隊並且 DevOps 經驗很欠缺的話,將會對轉換的速度造成一定的影響。
你的轉換過程還會受到一個因素的影響,那就是你依然要處理遺留的系統。維護它所耗費的時間會相應地減少進行轉換的時間。執行時環境也會影響這個過程。你是在內部環境中執行還是作為雲原生應用執行?你是否能夠依賴託管服務,比如託管的 API- 閘道器,還是需要自行搭建和維護?
如果你的策略是在短期內引入新特性的話,那麼就會面臨決策上的糾結,那就是將新需求在何處實現:如果作為新的獨立服務的話,會耗費一定的時間,如果採取快捷的方式,將其新增到單體應用上,那就會帶來讓單體應用越來越大,而不能對其進行縮減的風險。

註意那些阻礙前進或減緩速度的環境因素,並相應地調整它們,或者至少在你的組織中引起註意。記住: 每一次過程都是不同的,你的過程可能和我們的完全不同。

如果下次繼續引入微服務的話,在哪些方面的做法會有所不同
首先,我會檢查組織的戰略是否與微服務的標的相一致,那就是最大化產品的敏捷性以及獨立快速地釋出變更,例如,如果你的組織關註較長的釋出週期並希望將所有內容部署在一起,那麼微服務可能不是最佳選擇,因為無法充分利用微服務的優勢。
如果你決定採用微服務的話,每個人都必須投入其中,包括管理層。每個人都需要意識到這個過程是非常複雜和耗時的,當你還沒有多少經驗的時候更是如此。
與產品相符的、跨功能的、自治的團隊可以很好地與微服務架構樣式協作,但是應該儘早考慮向 DevOps 文化的轉變。每個團隊都應該為持續的迭代做好準備,並且能夠開發、釋出、運維和監控他們負責的服務。
將單體應用拆分成多個獨立的服務,只是整個過程的一部分,而如何運維它們則是另外一回事兒。你擁有的服務越多,它們的自動化構建和部署流程就變得越重要。
如果我重做一次的話,我將從一個易於抽取的小型候選服務開始,不僅要關註它的拆分,還要關註構建和部署的自動化,並預先監控第一個服務,它可以作為後續服務的基礎。要搭建這個基礎環境,可能需要從每個組抽取一個人形成一個臨時的任務組。
每個微服務從一開始就應該有自己的 CI/CD 管道。另一個需要考慮的問題是將每個微服務進行容器化,從而能夠得到輕量級、封裝好的執行時環境,它能夠在各個階段中保持一致,如果你以後想要在雲環境中執行服務的話,更需如此。
另外,還需要儘早考慮監控的問題,包括日誌聚合。監控不僅包括伺服器,還包括服務指標,如請求延遲、吞吐量和錯誤率,以便於跟蹤服務的健康狀況和可用性。要形成結構化和標準化的日誌輸出,如時間格式(如 ISO8601)和時區(如 UTC),並引入具有 correlation id 和日誌聚合的請求背景關係,這有助於問題的診斷和剖析。
很多事情需要預先處理,這非常耗時並且需要得到整個組織的關註。微服務是實現最大化產品敏捷性的投資,而不在於削減成本。
為了保持在市場上的競爭力,產品的敏捷性和持續改進是區別於競爭對手的關鍵因素。微服務可以提升產品的敏捷性並持續改善,但是它需要每個人的貢獻,包括管理者。
關於作者
Susanne Kaiser 是來自德國漢堡的獨立技術諮詢師,她曾經擔任過初創公司的 CTO,並將該公司的 SaaS 解決方案從單體架構遷移為微服務架構。她具有電腦科學的背景,在軟體開發和軟體架構方面有超過 15 年的經驗,經常在國際性的技術會議上演講。
原文地址:https://www.infoq.cn/article/31IdBpWgTQZU7e5-uwh1
.NET社群新聞,深度好文,歡迎訪問公眾號文章彙總 http://www.csharpkit.com 

