

阿裡妹導讀:資料中心已成為支撐大規模網際網路服務的標準基礎設施。隨著資料中心的規模越來越大,資料中心裡每一次軟體(如 JVM)或硬體(如 CPU)的升級改造都會帶來高昂的成本。合理的效能分析有助於資料中心的最佳化升級和成本節約,而錯誤的分析可能誤導決策、甚至造成巨大的成本損耗。
本文整理自阿裡巴巴高階技術專家郭健美(花名:希伯)在Java相關行業會議的分享,主要介紹阿裡大規模資料中心效能監控與分析的挑戰與實踐,希望對你有所啟發。
大家好,很高興有機會與 Java 社群的開發者交流。我的研究領域在軟體工程,主要集中在系統配置和效能方面。軟體工程一個比較常見的活動是找 bug,當然找 bug 很重要,但後來也發現,即便 bug-free 的程式也會被人配置錯,所以就衍生出了軟體配置問題。
很多軟體需要配置化,比如 Java 程式或 JVM 啟動時可以配置很多引數。透過配置,一套軟體可以靈活地提供各種定製化的功能,同時,這些配置也會對軟體整體效能產生不同的影響。當然這些還在軟體配置方面,來了阿裡以後,我有機會把這方面工作擴充套件到了硬體,會更多地結合硬體比如 CPU,來看系統的配置變更和升級改造對效能、可靠性以及業務上線效果的影響。今天主要談談我在這方面的一點工作。

阿裡最有代表性的事件是“雙 11”。這裡還是用的17年的資料,左上角是雙十一的銷售額,17年大概是 253 億美金,比美國同期 Thanksgiving、Black Friday、Cyber Monday 加起來的銷售額還要多。
當然這是從業務層面去看資料,技術同學會比較關註右邊的資料,17年雙十一的交易峰值達到 32.5 萬筆/秒、支付峰值達到 25.6 萬筆/秒。對於企業來說,這麼高的峰值效能意味著什麼?意味著成本!我們之所以關註效能,就是希望透過持續的技術創新,不斷地提高效能、同時節省成本。

雙十一零點的峰值效能不是一個簡單的數字,其背後需要一個大規模資料中心來支撐。 簡單來說,阿裡的基礎架構的上層是各種各樣的應用,比如淘寶、天貓、菜鳥、釘釘,還有雲端計算和支付寶等,這也是阿裡的一個特色,即具有豐富的業務場景。
底層是上百萬臺機器相連的大規模資料中心,這些機器的硬體架構不同、分佈地點也不同,甚至分佈在世界各地。中間這部分我們稱之為中臺,最貼近上層應用的是資料庫、儲存、中介軟體以及計算平臺,然後是資源排程、叢集管理和容器,再下麵是系統軟體,包括作業系統、JVM 和虛擬化等。
中臺這部分的產品是銜接社群與企業的紐帶。這兩年阿裡開源了很多產品,比如 Dubbo、PouchContainer 等,可以看出阿裡非常重視開源社群,也非常重視跟開發者對話。現在很多人都在講開源社群和生態,外面也有各種各樣的論壇,但是像今天這樣與開發者直接對話的活動並不是那麼多,而推動社群發展最終還是要依賴開發者。
這樣大規模的基礎架構服務於整個阿裡經濟體。從業務層面,我們可以看到 253 億美金的銷售額、32.5 萬筆交易/秒這樣的指標。然而,這些業務指標如何分解下來、落到基礎架構的各個部分就非常複雜了。比如,我們在做 Java 中介軟體或 JVM 開發時,都會做效能評估。
大部分技術團隊開發產品後都會有個效能提升指標,比如降低了 20% 的 CPU 利用率,然而這些單個產品的效能提升放到整個交易鏈路、整個資料中心裡面,佔比多少?對資料中心整體效能提升貢獻多少?這個問題很複雜,涉及面很廣,包括複雜關聯的軟體架構和各種異構的硬體。後面會提到我們在這方面的一些思考和工作。

阿裡的電商應用主要是用 Java 開發的,我們也開發了自己的 AJDK,這部分對 OpenJDK 做了很多定製化開發,包括:融入更多新技術、根據業務需要及時加入一些 patches、以及提供更好的 troubleshooting 服務和工具。
大家也知道,18年阿裡入選並連任了 JCP EC(Java Community Process – Executive Committee) 職位,有效期兩年,這對整個 Java 開發者社群、尤其是國內的 Java 生態都是一件大事。但是,不是每個人都瞭解這件事的影響。記得之前碰到一位同仁,提到 JCP EC 對阿裡這種大業務量的公司是有幫助,對小公司就沒意義了。
其實不是這樣的,參選 JCP EC 的時候,大公司、小公司以及一些社群開發者都有投票資格,小公司或開發者有一票,大公司也只有一票,地位是一樣的。很多國外的小公司更願意參與到社群活動,為什麼?
舉個簡單例子,由於業務需要,你在 JVM 8 上做了一個特性,費了很大的力氣開發除錯完成、業務上線成功,結果社群推薦升級到 JVM11 上,這時你可能又需要把該特性在 JVM 11 上重新開發除錯一遍,可能還要多踩一些新的坑,這顯然增加了開發代價、拉長了上線週期。但如果你能影響社群標準的制定呢?你可以提出將該特性融入社群下一個釋出版本,有機會使得你的開發工作成為社群標準,也可以藉助社群力量完善該特性,這樣既提高了技術影響力也減少了開發成本,還是很有意義的。

過去我們做效能分析主要依賴小規模的基準測試。比如,我們開發了一個 JVM 新特性, 模擬電商的場景,大家可能都會去跑 SPECjbb2015 的基準測試。再比如,測試一個新型硬體,需要比較 SPEC 或 Linpack 的基準測試指標。
這些基準測試有必要性,因為我們需要一個簡單、可復現的方式來衡量效能。但基準測試也有侷限性,因為每一次基準測試都有其限定的執行環境和軟硬體配置,這些配置設定對效能的影響可能很大,同時這些軟硬體配置是否符合企業需求、是否具有代表性,都是需要考慮的問題。
阿裡的資料中心裡有上萬種不同的業務應用,也有上百萬臺分佈在世界各地的不同伺服器。當我們考慮在資料中心裡升級改造軟體或硬體時,一個關鍵問題是小規模基準測試的效果是否能擴充套件到資料中心裡複雜的線上生產環境?
舉個例子,我們開發了 JVM 的一個新特性,在 SPECjbb2015 的基準測試中看到了不錯的效能收益,但到線上生產環境灰度測試的時候,發現該特性可以提升一個 Java 應用的效能、但會降低另一個 Java 應用的效能。同時,我們也可能發現即便對同一個 Java 應用,在不同硬體上得到的效能結果大不相同。這些情況普遍存在,但我們不可能針對每個應用、每種硬體都跑一遍測試,因而需要一個系統化方法來估計該特性對各種應用和硬體的整體效能影響。
對資料中心來說,評估每個軟體或硬體升級的整體效能影響非常重要。比如,“雙11”的銷售額和交易峰值,業務層面可能主要關心這兩個指標,那麼這兩個指標翻一倍的時候我們需要買多少臺新機器?需要多買一倍的機器麼?這是衡量技術能力提升的一個手段,也是體現“新技術”對“新商業”影響的一個途徑。我們提出了很多技術創新手段,也發現了很多效能提升的機會,但需要從業務上也能看出來。

為瞭解決上面提到的問題,我們開發了 SPEED 平臺。首先是估計當前線上發生了什麼,即 Estimation,透過全域監控採集資料,再進行資料分析,發現可能的最佳化點。比如,某些硬體整體表現比較差,可以考慮替換。
然後,我們會針對軟體或硬體的升級改造做線上評估,即 Evaluation。比如,硬體廠商推出了一個新硬體,他們自己肯定會做一堆評測,得到一組比較好的效能資料,但剛才也提到了,這些評測和資料都是在特定場景下跑出來的,這些場景是否適合用戶的特定需求?
沒有直接的答案。通常,使用者也不會讓硬體廠商到其業務環境裡去跑評測。這時候就需要使用者自己拿這個新硬體做灰度測試。當然灰度規模越大評測越準確,但線上環境都直接關聯業務,為了降低風險,實際中通常都是從幾十臺甚至幾臺、到上百臺、上千臺的逐步灰度。SPEED 平臺要解決的一個問題就是即便在灰度規模很小時也能做一個較好的估計,這會節約非常多的成本。
隨著灰度規模增大,平臺會不斷提高效能分析質量,進而輔助使用者決策,即 Decision。這裡的決策不光是判斷要不要升級新硬體或新版軟體,而且需要對軟硬體全棧的效能有一個很好的理解,明白什麼樣的軟硬體架構更適合標的應用場景,這樣可以考慮軟硬體最佳化定製的方向。
比如,Intel 的 CPU 從 Broadwell 到 Skylake,其架構改動很大,但這個改動的直接效果是什麼?Intel 只能從基準測試中給答案,但使用者可能根據自己的應用場景給出自己的答案,從而提出定製化需求,這對成本有很大影響。
最後是 Validation,就是通常規模化上線後的效果來驗證上述方法是否合理,同時改進方法和平臺。

資料中心裡軟硬體升級的效能分析需要一個全域性的效能指標,但目前還沒有統一的標準。Google 今年在 ASPLOS 上發表了一篇論文,提出了一個叫 WSMeter 的效能指標,主要是基於 CPI 來衡量效能。
在 SPEED 平臺裡,我們也提出了一個全域性效能指標,叫資源使用效率 RUE。基本思想很簡單,就是衡量每個單位 Work Done 所消耗的資源。這裡的 Work Done 可以是電商裡完成的一個 Query,也可以是大資料處理裡的一個 Task。而資源主要涵蓋四大類:CPU、記憶體、儲存和網路。通常我們會主要關註 CPU 或記憶體,因為目前這兩部分消費了伺服器大部分的成本。
RUE 的思路提供了一個多角度全面衡量效能的方法。舉個例子,業務方反映某臺機器上應用的 response time 升高了,這時登入到機器上也看到 load 和 CPU 利用率都升高了。這時候你可能開始緊張了,擔心出了一個故障,而且很可能是由於剛剛上線的一個新特性造成的。
然而,這時候應該去看下 QPS 指標,如果 QPS 也升高了,那麼也許是合理的,因為使用更多資源完成了更多的工作,而且這個資源使用效率的提升可能就是由新特性帶來的。所以,效能需要多角度全面地衡量,否則可能會造成不合理的評價,錯失真正的效能最佳化機會。

下麵具體講幾個資料中心效能分析的挑戰,基本上是線上碰到過的具體問題,希望能引起大家的一些思考。

首先是效能指標。可能很多人都會說效能指標我每天都在用,這有什麼好說的。其實,真正理解效能指標以及系統效能本身並不是那麼容易。舉個例子,在資料中心裡最常用的一個效能指標是 CPU 利用率,給定一個場景,資料中心裡每臺機器平均 CPU 利用率是 50%,假定應用需求量不會再增長、並且軟體之間也不會互相干擾,那麼是否可以把資料中心的現有機器數量減半呢?
這樣,理想情況下 CPU 利用率達到 100% 就可以充分利用資源了,是否可以這樣簡單地理解 CPU 利用率和資料中心的效能呢?肯定不行。就像剛才說的,資料中心除了 CPU,還有記憶體、儲存和網路資源,機器數量減半可能很多應用都跑不起來了。
再舉個例子,某個技術團隊升級了其負責的軟體版本以後,透過線上測試看到平均 CPU 利用率下降了 10%,因而宣告效能提升了 10%。這個宣告沒有錯,但我們更關心效能提升以後是否能節省成本,比如效能提升了 10%,是否可以把該應用涉及的 10% 的機器關掉?這時候效能就不應該只看 CPU 利用率,而應該再看看對吞吐量的影響。
所以,系統效能和各種效能指標,可能大家都熟悉也都在用,但還需要更全面地去理解。

剛才提到 SPEED 的 Estimation 會收集線上效能資料,可是收集到的資料一定對嗎?這裡講一個 Hyper-Threading 超執行緒的例子,可能對硬體瞭解的同學會比較熟悉。超執行緒是 Intel 的一個技術,比如我們的筆記本,一般現在都是雙核的,也就是兩個 hardware cores,如果支援超執行緒並開啟以後,一個 hardware core 就會變成兩個 hardware threads,即一臺雙核的機器會有四個邏輯 CPU。
來看最上面一張圖,這裡有兩個物理核,沒有開啟超執行緒,兩邊 CPU 資源都用滿了,所以從任務管理器報出的整臺機器平均 CPU 利用率是 100%。左下角的圖也是兩個物理核,開啟了超執行緒,每個物理核上有一個 hardware thread 被用滿了,整臺機器平均 CPU 利用率是 50%。
再看右下角的圖,也是兩個物理核,也開啟了超執行緒,有一個物理核的兩個hardware threads 都被用滿了,整臺機器平均 CPU 利用率也是 50%。左下角和右下角的 CPU 使用情況完全不同,但是如果我們只是採集整機平均 CPU 利用率,看到的資料是一樣的!
所以,做效能資料分析時,不要只是想著資料處理和計算,還應該註意這些資料是怎麼採集的,否則可能會得到一些誤導性的結果。
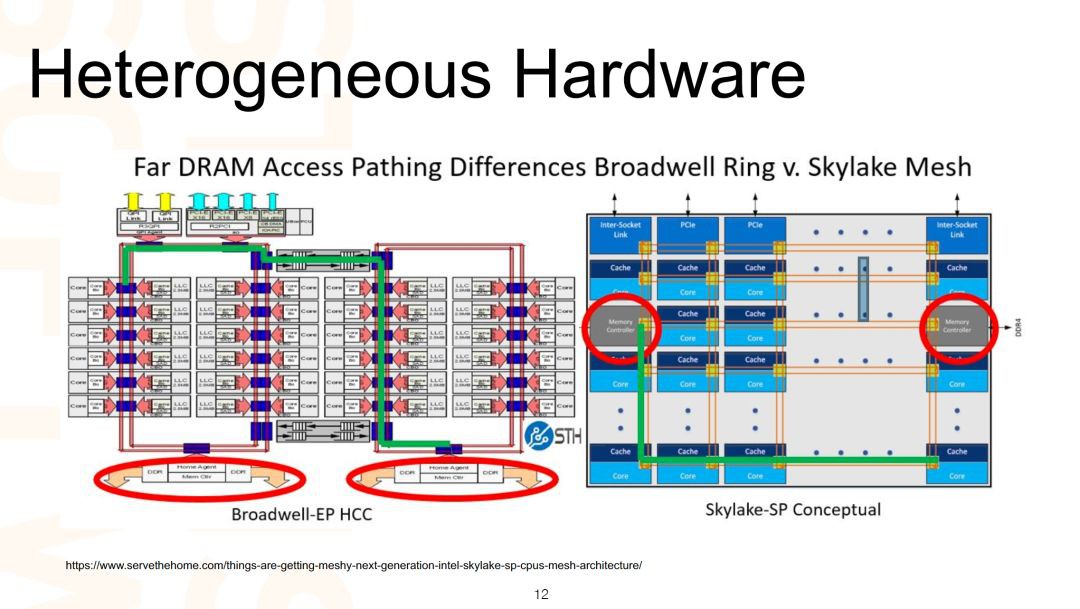
資料中心裡的硬體異構性是效能分析的一大挑戰,也是效能最佳化的一個方向。比如這裡左邊的 Broadwell 架構,是 Intel 過去幾年伺服器 CPU 的主流架構,近幾年在推右邊的 Skylake 架構,包含最新的 Cascade Lake CPU。Intel 在這兩個架構上做了很大的改動,比如,Broadwell 下訪問記憶體還是保持多年的環狀方式,而到了 Skylake 改為網格狀方式。
再比如,L2 Cache 到了Skylake 上擴大了四倍,通常來說這可以提高 L2 Cache 的命中率,但是 cache 越大也不代表性能就一定好,因為維護 cache coherence 會帶來額外的開銷。這些改動有利有弊,但我們需要衡量利和弊對整體效能的影響,同時結合成本來考慮是否需要將資料中心的伺服器都升級到 Skylake。
瞭解硬體的差異還是很有必要的,因為這些差異可能影響所有在其上執行的應用,並且成為硬體最佳化定製的方向。

現代網際網路服務的軟體架構非常複雜,比如阿裡的電商體系架構,而複雜的軟體架構也是效能分析的一個主要挑戰。舉個簡單的例子,圖中右邊是優惠券應用,左上角是大促主會場應用,左下角是購物車應用,這三個都是電商裡常見的業務場景。從 Java 開發的角度,每個業務場景都是一個 application。電商客戶既可以從大促主會場選擇優惠券,也可以從購物車裡選擇優惠券,這是使用者使用習慣的不同。
從軟體架構角度看,大促主會場和購物車兩個應用就形成了優惠券應用的兩個入口,入口不同對於優惠券應用本身的呼叫路徑不同,效能影響也就不同。
所以,在分析優惠券應用的整體效能時需要考慮其在電商業務裡的各種錯綜複雜的架構關聯和呼叫路徑。像這種複雜多樣的業務場景和呼叫路徑是很難在基準測試中完全復現的,這也是為什麼我們需要做線上效能評估。

這是資料分析裡著名的辛普森悖論,在社會學和醫學領域有很多常見案例,我們在資料中心的效能分析裡也發現了。這是線上真實的案例,具體是什麼 App 我們不用追究。
假設還用前面的例子,比如 App 就是優惠券應用,在大促的時候上線了一個新特性 S,灰度測試的機器佔比為 1%,那麼根據 RUE 指標,該特性可以提升效能 8%,挺不錯的結果。但是如果優惠券應用有三個不同的分組,分組假設就是關聯剛才提到的不同入口應用,那麼從每個分組看,該特性都降低了應用的效能。
同樣一組資料、同樣的效能評估指標,透過整體聚集分析得到的結果與透過各部分單獨分析得到的結果正好相反,這就是辛普森悖論。既然是悖論,說明有時候應該看總體評估結果,有時間應該看部分評估結果。在這個例子裡面,我們選擇看部分評估、也就是分組上的評估結果,所以看起來這個新特性造成了效能下降,應該繼續修改並最佳化效能。
所以,資料中心裡的效能分析還要預防各種可能的資料分析陷阱,否則可能會嚴重誤導決策。

最後,還有幾分鐘,簡單提一下效能分析師的要求。這裡通常的要求包括數學、統計方面的,也有電腦科學、程式設計方面的,當然還有更重要的、也需要長期積累的領域知識這一塊。這裡的領域知識包括對軟體、硬體以及全棧效能的理解。
其實,我覺得每個開發者都可以思考一下,我們不光要做功能開發,還要考慮所開發功能的效能影響,尤其是對資料中心的整體效能影響。比如,JVM 的 GC 開發,社群裡比較關心 GC 暫停時間,但這個指標與 Java 應用的 response time 以及所消耗的 CPU 資源是什麼關係,我們也可以有所考慮。
來源:阿裡技術
推薦閱讀:
溫馨提示:
請識別二維碼關註公眾號,點選原文連結獲取更多IO效能評估分析資料總結。



