來自:CDA資料分析師(微訊號:cdacdacda)
作者 Ctipsy
《我不是藥神》是由文牧野執導,寧浩、徐崢共同監製的劇情片,徐崢、週一圍、王傳君、譚卓、章宇、楊新鳴等主演 。影片講述了神油店老闆程勇從一個交不起房租的男性保健品商販程勇,一躍成為印度仿製藥“格列寧”獨家代理商的故事。
該片於2018年7月5日在中國上映。上映之後獲得一片好評,不少觀眾甚至直呼“中國電影希望”,“《熔爐》、《辯護人》之類寫實影片同水準”,誠然相較於市面上一眾的摳圖貼臉影視作品,《藥神》在影片質量上確實好的多,不過我個人覺得《藥神》的火爆還有以下幾個原因:
-
影片題材稀少帶來的新鮮感,像這類”針砭時弊” 類影視作品,國內太少。
-
順應潮流,目前《手機》事件及其帶來的影響和國家層面文化自信的號召以及影視作品水平亟待提高的大環境下,《藥神》的過審與上映本身也是對該類題材一定程度的鼓勵。
-
演員靠譜、演技扎實,這個沒的說,特別是王傳君的表現,讓人眼前一亮。
本文透過爬取《我不是藥神》和《邪不壓正》豆瓣電影評論,對影片進行視覺化分析。
截止7月13日:《我不是藥神》豆瓣評分:8.9 分,貓眼:9.7 分,時光網:8.8 分 。
截止7月13日: 《邪不壓正》 豆瓣評分:7.2 分,貓眼:7.4 分,時光網:7.3 分 。
豆瓣的評分質量相對而言要靠譜點,所以本文資料來源也是豆瓣。
0. 需求分析
-
獲取影評資料
-
清洗分析儲存資料
-
分析展示影評城市來源、情感
-
分時展示電影評分趨勢
-
當然主要是用來熟練pandas和爬蟲及視覺化技能
1. 前期準備
1.1 網頁分析
豆瓣從2017.10月開始全面禁止爬取資料,僅僅開放500條資料,白天1分鐘最多可以爬取40次,晚上一分鐘可爬取60次數,超過此次數則會封禁IP地址
tips發現
實際操作發現,點選影片評論頁面的
後頁時,url中的一個引數start會加20,但是如果直接賦予’start’每次增加10,網頁也是可以存在的!
-
登入狀態下,按網頁按鈕點選
後頁,start最多為480,也就是20*25=500條 -
非登入狀態下,最多為200條
-
登入狀態下,直接修改url的方法可以比官方放出的評論數量多出了一倍!!!
1.2 頁面佈局分析
本次使用xpath解析,因為之前的部落格案例用過正則,也用過beautifulsoup,這次嘗試不一樣的方法。
如下圖所示,本此資料爬取主要獲取的內容有:
-
評論使用者ID
-
評論內容
-
評分
-
評論日期
-
使用者所在城市
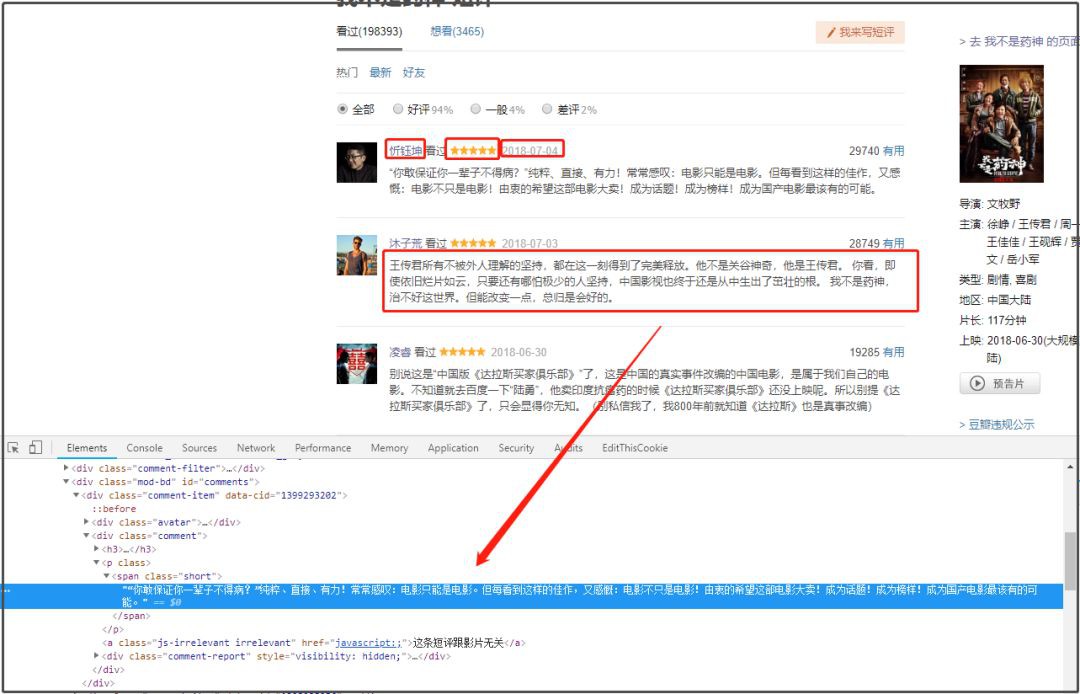
城市資訊獲取
評論頁面沒有城市資訊,因此需要透過進入評論使用者主頁去獲取城市資訊元素。
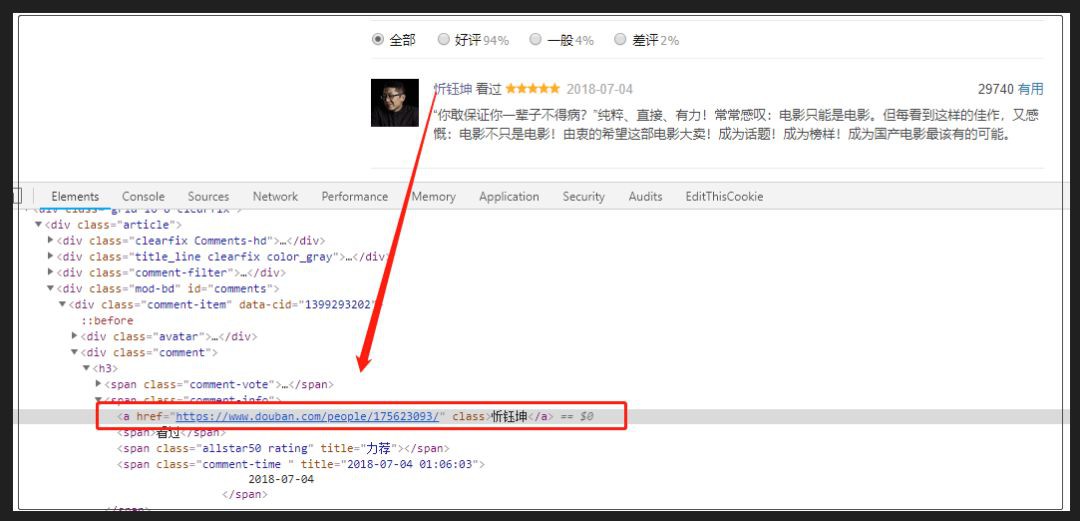
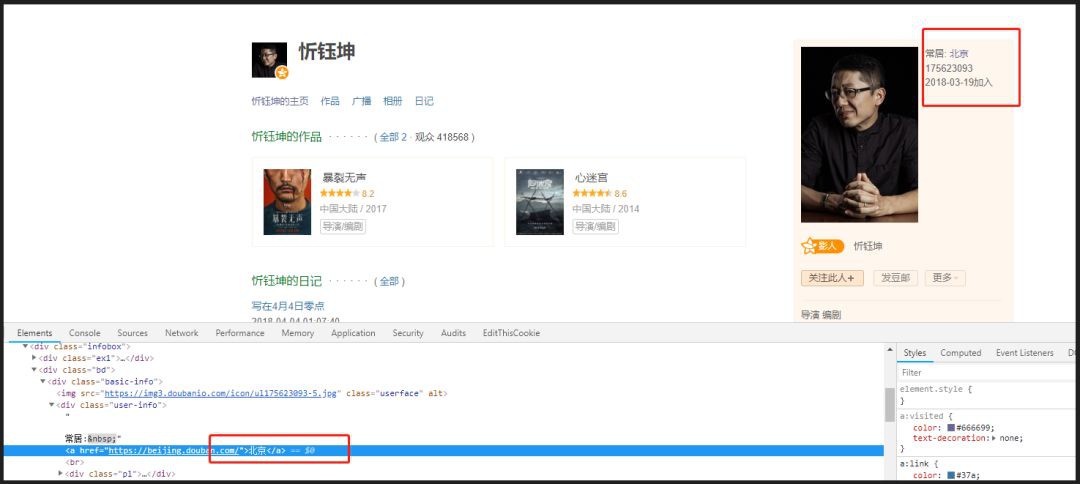
透過分析頁面發下,使用者ID名稱裡隱藏著主頁連結!所以我的思路就是request該連結,然後提取城市資訊。
2. 資料獲取-爬蟲
2.1 獲取cookies
因為豆瓣的爬蟲限制,所以需要使用cookies作身份驗證,透過chrome獲取cooikes位置如下圖:

2.2 載入cookies與essay-headers
下麵的cookie被修改了,諸君需要登入後自己獲取專屬cookieo(∩_∩)o
essay-headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
cookies = {'cookie': 'bid=GOOb4vXwNcc; douban-fav-remind=1; viewed="27611266_26886337"; ps=y; ue="citpys原創分享@163.com"; " \
"push_noty_num=0; push_doumail_num=0; ap=1; loc-last-index-location-id="108288"; ll="108288"; dbcl2="187285881:N/y1wyPpmA8"; ck=4wlL'}
url = "https://movie.douban.com/subject/" + str(id) + "/comments?start=" + str(page * 10) + "&limit;=20&sort;=new_score&status;=P"
res = requests.get(url, essay-headers=essay-headers, cookies=cookies)
res.encoding = "utf-8"
if (res.status_code == 200):
print("\n第{}頁短評爬取成功!".format(page + 1))
print(url)
else:
print("\n第{}頁爬取失敗!".format(page + 1))
一般掃清頁面後,第一個請求裡包含了cookies。
2.3 延時反爬蟲
設定延時發出請求,並且延時的值還保留了2位小數(自我感覺模擬正常訪問請求會更加逼真…待證實)。
time.sleep(round(random.uniform(1, 2), 2))2.4 解析需求資料
這裡有個大bug,找了好久!
因為有的使用者雖然給了評論,但是沒有給評分,所以score和date這兩個的xpath位置是會變動的。
所以需要加判斷,如果發現score裡面解析的是日期,證明該條評論沒有給出評分。
name = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/text()'.format(i))
# 下麵是個大bug,如果有的人沒有評分,但是評論了,那麼score解析出來是日期,而日期所在位置spen[3]為空
score = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[2]/@title'.format(i))
date = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/span[3]/@title'.format(i))
m = '\d{4}-\d{2}-\d{2}'
match = re.compile(m).match(score[0])
if match is not None:
date = score
score = ["null"]
else:
pass
content = x.xpath('//*[@id="comments"]/div[{}]/div[2]/p/span/text()'.format(i))
id = x.xpath('//*[@id="comments"]/div[{}]/div[2]/h3/span[2]/a/@href'.format(i))
try:
city = get_city(id[0], i) # 呼叫評論使用者的ID城市資訊獲取
except IndexError:
city = " "
name_list.append(str(name[0]))
score_list.append(str(score[0]).strip('[]\'')) # bug 有些人評論了文字,但是沒有給出評分
date_list.append(str(date[0]).strip('[\'').split(' ')[0])
content_list.append(str(content[0]).strip())
city_list.append(city)2.5 獲取電影名稱
從url上只能獲取電影的subject的8位ID數值,引起需要自行解析網頁獲取ID號對應的電影名稱,該功能是後期改進新增的,因此為避免現有程式碼改動多(偷個懶),採用了全域性變數賦值給movie_name,需要註意全域性變數呼叫時,要加global宣告一下。
pattern = re.compile('.*?.*?(.*?) 短評', re.S)
global movie_name
movie_name = re.findall(pattern, res.text)[0] # list型別3. 資料儲存
因為資料量不是很大,因為普通csv儲存足夠,把獲取的資料轉換為pandas的DF格式,然後儲存到csv檔案中。
infos = {'name': name_list, 'city': city_list, 'content': content_list, 'score': score_list, 'date': date_list}
data = pd.DataFrame(infos, columns=['name', 'city', 'content', 'score', 'date'])
data.to_csv(str(ID) + "_comments.csv")
因為考慮到程式碼的復用性,所以main函式中傳入了兩個引數。
-
一個是待分析影片在豆瓣電影中的ID號(這個可以在連結中獲取到,是一個8位數。
-
一個是需要爬取的頁碼數,一般設定為49,因為網站只開放500條評論。
另外有些電影評論有可能不足500條,所以需要調整,之前嘗試透過正則匹配分析頁面結構。
4. 資料清洗
爬取出來的結果如下:

4.1 城市資訊清洗
從爬取的結果分析可以發現,城市資訊資料有以下問題:
-
有城市空缺
-
海外城市
-
亂寫
-
pyecharts尚不支援的城市,目前支援的城市串列可以看到Github相關連結:
https://github.com/pyecharts/pyecharts/blob/master/pyecharts/datasets/city_coordinates.json
step1: 過濾篩選中文字
透過正則運算式篩選中文,透過split函式提取清理中文,透過sub函式替換掉各類標點符號。
line = str.strip()
p2 = re.compile('[^\u4e00-\u9fa5]') # 中文的編碼範圍是:\u4e00到\u9fa5
zh = " ".join(p2.split(line)).strip()
zh = ",".join(zh.split())
str = re.sub("[A-Za-z0-9!!,%\[\],。]", "", zh)
step2: 匹配pyecharts支援的城市串列
一開始我不知道該庫有城市串列資料(只找了官網,沒看github)所以使用的方法如下,自己上網找中國城市字典,然後用excel 篩選和串列分割功能快速獲得一個不包含省份和’市’的城市字典,然後匹配。後來去github上issue了下,發現有現成的字典檔案,一個json文字,得到的回覆如下(^__^)。

這樣就方便了,直接和這個串列匹配就完了,不在裡面的話,直接list.pop就可以了 但是這樣還有個問題,就是爬取下來的城市資訊中還包含著省份,而pyecharts中是不能帶省份的,所以還需要透過分割,來提取城市,可能存在的情況有:
· 兩個字:北京
· 三個字:攀枝花
· 四個字:山東煙臺
· 五個字:四川攀枝花
· 六個字:黑龍江哈爾濱
…
因此我做了簡化處理:
-
名稱為2~4的,如果沒匹配到,則提取後2個字,作為城市名。
-
名稱為>4的,如果沒匹配到,則依次嘗試提取後面5、4、3個字的。
-
其餘情況,經過觀察原始資料發現數量極其稀少,可以忽略不作處理。
d = pd.read_csv(csv_file, engine='python', encoding='utf-8')
for i in d['city'].dropna(): # 過濾掉空的城市
i = translate(i) # 只保留中文
if len(i)>1 and len(i)<5: # 如果名稱個數2~4,先判斷是否在字典裡
if i in fth:
citys.append(i)
else:
i = i[-2:] # 取城市名稱後兩個,去掉省份
if i in fth:
citys.append(i)
else:
continue
if len(i) > 4:
if i in fth: # 如果名稱個數>2,先判斷是否在字典裡
citys.append(i)
if i[-5:] in fth:
citys.append(i[-5:])
continue
if i[-4:] in fth:
citys.append(i[-4:])
continue
if i[-3:] in fth:
citys.append(i[-3:])
else:
continue
result = {}
while '' in citys:
citys.remove('') # 去掉字串中的空值
print("城市總數量為:",len(citys))
for i in set(citys):
result[i] = citys.count(i)
return result
但是這樣可能還有漏洞,所以為保證程式一定不出錯,又設計瞭如下校驗模組:
思路就是,迴圈嘗試,根據xx.add()函式的報錯,確定城市名不匹配,然後從list中把錯誤城市pop掉,另外註意到豆瓣個人主頁上的城市資訊一般都是是到市,那麼縣一級的區域就不考慮了,這也算是一種簡化處理。
while True: # 二次篩選,和pyecharts支援的城市庫進行匹配,如果報錯則刪除該城市對應的統計
try:
attr, val = geo.cast(info)
geo.add("", attr, val, visual_range=[0, 300], visual_text_color="#fff", is_geo_effect_show=False,
is_piecewise=True, visual_split_number=6, symbol_size=15, is_visualmap=True)
except ValueError as e:
e = str(e)
e = e.split("No coordinate is specified for ")[1] # 獲取不支援的城市名稱
info.pop(e)
else:
break
5. 基於snownlp的情感分析
snownlp主要可以進行中文分詞(演演算法是Character-Based Generative Model)、詞性標註(原理是TnT、3-gram 隱馬)、情感分析(官網木有介紹原理,但是指明購物類的評論的準確率較高,其實是因為它的語料庫主要是購物方面的,可以自己構建相關領域語料庫,替換原來的,準確率也挺不錯的)、文字分類(原理是樸素貝葉斯)、轉換拼音、繁體轉簡體、提取文字關鍵詞(原理是TextRank)、提取摘要(原理是TextRank)、分割句子、文字相似(原理是BM25)。
官網還有更多關於該庫的介紹,在看本節之前,建議先看一下官網,裡面有最基礎的一些命令的介紹。
官網連結:https://pypi.org/project/snownlp/
由於snownlp全部是unicode編碼,所以要註意資料是否為unicode編碼。因為是unicode編碼,所以不需要去除中文文字裡面含有的英文,因為都會被轉碼成統一的編碼上面只是呼叫snownlp原生語料庫對文字進行分析,snownlp重點針對購物評價領域,所以為了提高情感分析的準確度可以採取訓練語料庫的方法。
attr, val = [], []
info = count_sentiment(csv_file)
info = sorted(info.items(), key=lambda x: x[0], reverse=False) # dict的排序方法
for each in info[:-1]:
attr.append(each[0])
val.append(each[1])
line = Line(csv_file+":影評情感分析")
line.add("", attr, val, is_smooth=True, is_more_utils=True)
line.render(csv_file+"_情感分析曲線圖.html")
6. 資料視覺化與解讀
6.0 文字讀取
在後面的commit版本中,我最終只傳入了電影的中文名字作為引數,因此相較於之前的版本,在路徑這一塊兒需要做寫調整。由於python不支援相對路徑下存在中文,因此需要做如下處理:
-
step1 獲取檔案絕對路徑
-
step2 轉換路徑中的\為\\
-
step3 如果還報錯,在read_csv中加引數read_csv(csv_file, engine='python', encoding='utf-8')
-
註意: python路徑中,如果最後一個字元為\會報錯,因此可以採取多段拼接的方法解決。
完整程式碼如下:
path = os.path.abspath(os.curdir)
csv_file = path+ "\\" + csv_file +".csv"
csv_file = csv_file.replace('\\', '\\\\')
6.1 評論來源城市分析
呼叫pyecharts的page函式,可以在一個影象物件中建立多個chart,只需要對應的add即可。
城市評論分析的思路如下:
-
經過步驟4的的清洗處理之後,獲得形如[("青島", 9),("武漢", 12)]結構的資料。
-
透過迴圈試錯,把不符合條件的城市資訊pop掉。
except ValueError as e:
e = str(e)
e = e.split("No coordinate is specified for ")[1] # 獲取不支援的城市名稱
info.pop(e)
-
遍歷dict,抽取資訊賦值給attr和val為畫圖做準備。
for key in info:
attr.append(key)
val.append(info[key])
函式程式碼如下:
geo1 = Geo("", "評論城市分佈", title_pos="center", width=1200, height=600,
background_color='#404a59', title_color="#fff")
geo1.add("", attr, val, visual_range=[0, 300], visual_text_color="#fff", is_geo_effect_show=False,
is_piecewise=True, visual_split_number=10, symbol_size=15, is_visualmap=True, is_more_utils=True)
#geo1.render(csv_file + "_城市dotmap.html")
page.add_chart(geo1)
geo2 = Geo("", "評論來源熱力圖",title_pos="center", width=1200,height=600, background_color='#404a59', title_color="#fff",)
geo2.add("", attr, val, type="heatmap", is_visualmap=True, visual_range=[0, 50],visual_text_color='#fff', is_more_utils=True)
#geo2.render(csv_file+"_城市heatmap.html") # 取CSV檔案名的前8位數
page.add_chart(geo2)
bar = Bar("", "評論來源排行", title_pos="center", width=1200, height=600 )
bar.add("", attr, val, is_visualmap=True, visual_range=[0, 100], visual_text_color='#fff',mark_point=["average"],mark_line=["average"],
is_more_utils=True, is_label_show=True, is_datazoom_show=True, xaxis_rotate=45)
#bar.render(csv_file+"_城市評論bar.html") # 取CSV檔案名的前8位數
page.add_chart(bar)
pie = Pie("", "評論來源餅圖", title_pos="right", width=1200, height=600)
pie.add("", attr, val, radius=[20, 50], label_text_color=None, is_label_show=True, legend_orient='vertical', is_more_utils=True, legend_pos='left')
#pie.render(csv_file + "_城市評論Pie.html") # 取CSV檔案名的前8位數
page.add_chart(pie)
page.render(csv_file + "_城市評論分析彙總.html")



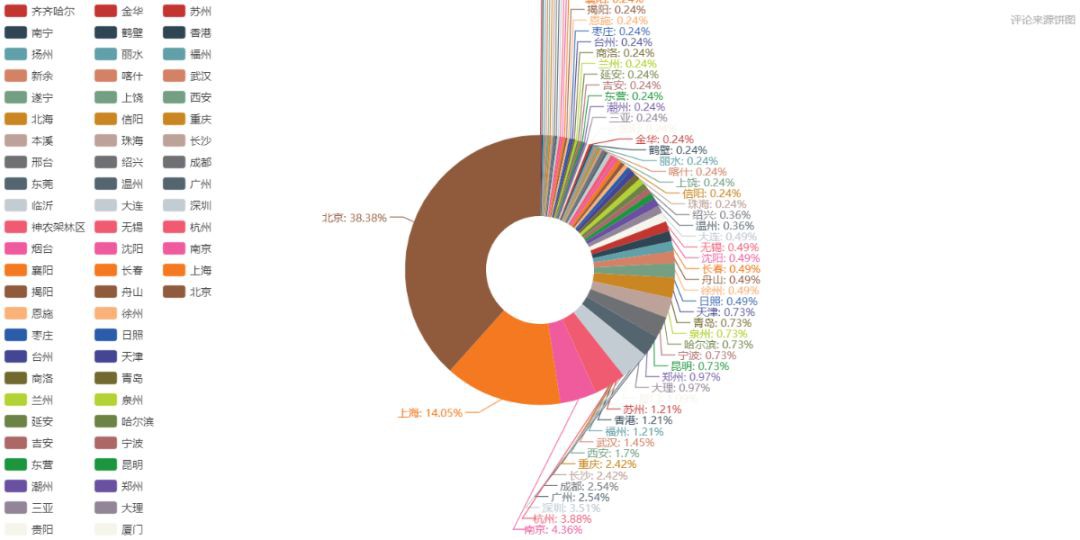
從上圖可以看出,《我不是藥神》的觀影人群中,排名前十的城市依次為 北京、上海、南京、杭州、深圳、廣州、成都、長沙、重慶、西安。
而相對的《邪不壓正》觀影人群,排名前十依次為 北京、上海、廣州、成都、杭州、南京、西安、深圳、長沙、哈爾濱。
電影消費是城市消費的一部分,某種程度上可以作為觀察一個城市活力的指標。上述城市大都在近年的GDP排行中居上游,消費力強勁。
但是我們不能忽略城市人口基數和熒幕數量的因素。一線大城市的熒幕數量總額是超過其他二三線城市的,大城市人口基數龐大,極多的熒幕數量和座位、極高密度的排片場次,讓諸多人便捷觀影,這樣一來票房自然就比其他城市高出不少,活躍的觀眾評論也多。
6.2 評論情感分析
0.5以下為負面情緒,0.5以上為正面情緒,因為電影好評太多,為了圖形的合理性(讓低數值的統計量也能在圖中較明顯的展示),把評論接近1的去掉了。當然按理說情緒正面性到1的應該很少,出現這種結果的原因我覺得是語料庫的鍋。

6.3 電影評分走勢分析
思路如下:
-
讀取csv檔案,以dataframe(df)形式儲存
-
遍歷df行,儲存到list
-
統計相同日期相同評分的個數,例如dict型別 ('很差', '2018-04-28'): 55
-
轉換為df格式,設定列名
info_new.columns = ['score', 'date', 'votes']
-
按日期排序,
info_new.sort_values('date', inplace=True)
-
遍歷新的df,每個日期的評分分為5種,因此需要插入補充缺失數值。
補充缺失數值
建立新df,遍歷匹配各種評分型別,然後插入行。
creat_df = pd.DataFrame(columns = ['score', 'date', 'votes']) # 建立空的dataframe
for i in list(info_new['date']):
location = info_new[(info_new.date==i)&(info_new.score=="力薦")].index.tolist()
if location == []:
creat_df.loc[mark] = ["力薦", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="推薦")].index.tolist()
if location == []:
creat_df.loc[mark] = ["推薦", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="還行")].index.tolist()
if location == []:
creat_df.loc[mark] = ["還行", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="較差")].index.tolist()
if location == []:
creat_df.loc[mark] = ["較差", i, 0]
mark += 1
location = info_new[(info_new.date==i)&(info_new.score=="很差")].index.tolist()
if location == []:
creat_df.loc[mark] = ["很差", i, 0]
mark += 1
info_new = info_new.append(creat_df.drop_duplicates(), ignore_index=True)
細節
由於遍歷匹配時,抽取的評分等級和上文程式碼中的“力薦”、“推薦”、“還行”、“較差”、“很差”次序可能不一致,因此最後會有重覆值出現,所以在拼接兩個df時,需要duplicates()去重。
info_new = info_new.append(creat_df.drop_duplicates(), ignore_index=True)
之後就可以遍歷df取數畫圖了(第二中遍歷df的方法)。
for index, row in info_new.iterrows(): # 第二種遍歷df的方法
score_list.append([row['date'], row['votes'], row['score']])
前面還提到了一種遍歷方法。
for indexs in d.index: # 一種遍歷df行的方法
d.loc[indexs].values[:])

從上述日評分投票走勢圖可以發現,在影片上映開始的一週內,為評論高峰,尤其是上映3天內,這符合常識,但是也可能有偏差,因為爬蟲獲取的資料是經過豆瓣電影排序的,倘若資料量足夠大得出的趨勢可能更接近真實情況。
另外發現,影片在上映前也有部分評論,分析可能是影院公映前的小規模試映,且這些提前批的使用者的評分均值,差不多接近影評上映後的大規模評論的最終評分 ,從這些細節中,我們或許可以猜測,這些能提前觀看影片的,可能是資深影迷或者影視從業人員,他們的評論有著十分不錯的參考價值。
那麼日後在觀看一部尚未搬上大熒幕的影片前,我們是否可以透過分析這些提前批使用者的評價來決定是否掏腰包去影院避免邂逅爛片呢?
6.4 影評詞雲圖
思路如下:
-
讀取csv檔案,以dataframe(df)形式儲存
-
去除評論中非中文文字
-
選定詞雲背景
-
調整最佳化停用詞表

薑文背景圖

《邪不壓正》詞雲圖
臺詞
從詞雲圖中可以探究到,評論多次提到“臺詞”,《邪不壓正》的臺詞確實依舊帶著濃濃的薑文味,例如:
一、治腳嗎?不治。治治吧。不治。治治。《邪不壓正》
二、怎麼相信一個寫日記的人。《邪不壓正》
三、“我就是為了這醋,包了一頓餃子”。《邪不壓正》
四、冰川期就要來了,海平面降低了,那幾個島越來越大,跟澳大利亞連一塊兒了。《邪不壓正》
五、你總是給自己設定障礙,因為你不敢。《邪不壓正》
六、正經人誰寫日記啊。《邪不壓正》
七、都是同一個師傅教的,破不了招啊。《邪不壓正》
八、你對我開槍,不怕殺了我,不怕。你不愛我,傻瓜,子彈是假的。《邪不壓正》
九、外國男人只想亂搞,中國男人都想成大事。《邪不壓正》
十、老蔣更不可靠,一個寫日記的人能可靠嗎,正經人誰寫日記啊?《邪不壓正》
十一、你每犯一次錯,就會失去一個爸爸。《邪不壓正》
十二、誰把心裡話寫日記裡啊,日記這玩意本來就不是給外人看,要是給外人看了,就倆字下賤!《邪不壓正》
十三 、咳咳…還等什麼呢。——薑文《邪不壓正》
十四、我當時問你在幹嘛,你拿著肘子和我說:真香。《邪不壓正》
十五、“我要報仇!”“那你去呀!你不敢?”“我等了十五年了,誰說我不敢?”“那你為什麼不去,你不敢”“對,我不敢”《邪不壓正》
喜歡
雖然這部影片評分和薑文之前的優秀作品相比顯得寒酸,但是觀眾們依舊對薑導演抱有期望,支援和喜愛,期待他後續更多的精彩作品;程式剛跑完,詞雲裡突然出現個爸爸,讓我卡頓了(PS:難道程式bug了???),接著才想起來是影片中的薑文飾演的藍爸爸,以此稱呼薑導,可見鐵桿粉絲的滿滿愛意~
一步之遙
同時可以發現評論中,薑文的另一部作品《一步之遙》也被提及較多。誠然,《邪不壓正》確實像是《讓子彈飛》和《一步之遙》的糅合,它有著前者的邪性與瀟灑,又帶有後者的戲謔和浪漫。因而喜歡《一步之遙》的觀眾會愛上本片,反之不待見的觀眾也會給出《一步之遙》的低分。

徐崢背景圖

《我不是藥神》詞雲圖
高頻重點詞彙有:
-
中國
-
題材
-
現實
-
煽情
-
社會
-
故事
-
好看
-
希望
詞雲分析結果展現出的強烈觀感有一部分原因是《我不是藥神》的意外之喜,寧浩和徐崢兩個喜劇界的領軍人物合作,很自然的以為會是喜劇路數,誰能想到是一部嚴肅的現實題材呢?
倘若是尚未觀看本片的讀者,僅從情感分析的角度看,我相信也可以下對本片下結論:值得去影院體驗的好電影。正如我在文章開篇所說,《藥神》的誕生,給中國當前的影片大環境帶來了一股清流,讓人對國產電影的未來多了幾分期許。
7. 總結
-
練習一下pandas操作和爬蟲。
-
沒有自己構建該領域的語料庫,如果構建了相關語料庫,替換預設語料庫,情感分析準確率會高很多。所以語料庫是非常關鍵的,如果要正式進行文字挖掘,建議要構建自己的語料庫。
-
pyecharts畫圖挺別緻的。
附錄一下爬取分析的“邪不壓正”的電影資料,因為圖形和分析過程相似,所以就不單獨放圖了,(ps:薑文這次沒有給人帶來太大的驚喜==)
影片:《邪不壓正》——Python資料分析
Github完整程式碼:https://github.com/Ctipsy/DA_projects/tree/master/我不是藥神
●編號473,輸入編號直達本文
●輸入m獲取到文章目錄
推薦↓↓↓

演演算法與資料結構
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
本站僅按申請收錄文章,版權歸原作者所有
如若侵權,請聯絡本站刪除
