
多讀論文可以豐富我們的知識、拓展我們的視野,讓我們領略其他智者的思想,讓我們的思路也變得開闊起來。在此,鼓勵大家多多閱讀論文,挑些自己感興趣的論文,仔細體會作者的思想,最好動手多多推研一下公式,相信你一定能收穫不少靈感。
奉上本週份的10篇筆者認為不錯的論文,希望諸位朋友也能從中有所收穫。
1、An intriguing failing of convolutional neural networks and the CoordConv solution

內容概述:很少有一些新奇的策略能像摺積(Convolution)那樣,對深度學習產生如此大的影響。對於涉及畫素或空間表示的任何問題,一般都會認為摺積神經網路可能是最合適的。在本文中,我們透過看似微不足道的坐標變換問題(Coordinate Transform Problem)來給出了一個反例,該問題只需要學習( x,y )笛卡爾空間和one-hot畫素空間中的坐標。儘管摺積網路看起來似乎很適合解決這項任務,但我們的實驗顯示結果卻恰恰相反。我們先在一個toy problem上驗證並分析了失敗的原因,並給出了我們的解決方案。我們的解決方法稱為CoorConv,它透過使用額外的坐標通道使得摺積可以訪問自己的輸入坐標。在不犧牲普通摺積的計算和引數效率的情況下,CoorConv允許網路根據最終任務的要求,學習完美的平移不變性(translation invariance)或不同程度的平移依賴性(translation dependence)。CoorConv用比普通的摺積少10 – 100倍的引數,以完美的泛化和150倍的速度解決坐標變換問題(Coordinate Transform Problem)。這種鮮明的對比提出了這樣一個問題: 在其他任務中,這種inability of convolution在多大程度上持續存在,從內部潛移默化地阻礙模型的效能?這個問題的完整答案需要進一步研究,但我們初步證明,用CoorConv代替摺積可以對多種任務的模型進行改進。在GAN中使用CoorConv,可以產生較少的樣式崩潰(mode collapse),因為高階的空間延遲(high-level spatial latent)和畫素之間的轉換變得更容易學習。基於MNIST資料集,Faster R – CNN檢測模型顯示,當使用CoorConv時,IOU提高了24 %,在增強學習( RL )領域, Playing Atari遊戲中,使用CoorConv層可以使agent顯著受益。
2、Convergence Problems withGenerative Adversarial Networks (GANs)

內容概述:生成對抗網路( GANs )是一種新的生成建模方法,其標的是學習真實資料的分佈。它們經常被證明很難訓練: GANs同機器學習中的很多其他技術不同,因為GAN被描述為discriminator和generator之間的雙人遊戲。這既造成了訓練過程中的不可靠性,也造成了我們缺乏對GAN是如何收斂?如果收斂,又會收斂到哪裡?等問題的理解。本文主要目的是介紹關於GANs的,比較mathematician的理論,突出正反兩方面的結果。這包括如何鑒別訓練GANs時存在的問題,以及GANs的拓撲(topology)和博弈論觀點(game-theoretic perspectives)是如何幫助我們理解和改進我們近年來的技術的。
3、Feature Selection for Unsupervised Domain Adaptation using Optimal Transport

內容概述:本文基於新興的最優運輸理論(optimal transportation theory),提出了一種新的,用於無監督領域自適應特徵選擇的方法。我們基於最近關於領域適應性(domain adaptation)中最佳傳輸(optimal transport)的理論分析,表明optimal transport可以直接給出一種利用域間轉移的特徵選擇過程。在此基礎上,我們提出了一種新的演演算法,旨在透過源域(source domain)和標的域(target domain)之間的相似性對特徵進行排序,這種排序是透過分析我們所提出的最優運輸問題的解的耦合矩陣(coupling matrix)來獲得的。我們在一個著名的標準資料集上評估了我們的方法,並證明瞭它具有選擇正確feature的能力,從而獲得更好的分類效能。此外,我們還表明,所提出的演演算法可以作為現有領域自適應技術的預處理步驟,在保持可比結果的同時,在計算時間方面獲得了巨大的加速。最後,在臨床影像資料庫上對演演算法進行了驗證,並取得了良好的效果。
4、Latent Alignment and Variational Attention

內容概述:Neural Attention力已經成為自然語言處理和相關領域中許多最新模型的核心架構。註意力網路(Attention network)是一種易於訓練且有效的soft simulating alignment的方法;然而,這種方法在機率意義上並不排斥latent alignment。這種特性使得很難將註意力與其他對齊方法進行比較,難以將其與機率模型組合,也難以根據觀察到的資料進行後驗推斷。另外一個相關的latent方法,即hart attention,解決了這些問題,但通常更難訓練,也不太準確。本文主提出了變分註意力網路(variational attention networks),一種基於amortized variational inference的具有更緊密的approximation bounds的,用於替代soft attention和hard attention,學習latent variable alignment的解決方案。我們進一步提出減少梯度方差的方法,使這些方法在計算上可行。實驗表明,對於機器翻譯和visual question answering,效率低下的exact latent variable models優於標準的神經註意力模型,但當基於hard attention進行訓練時,這些增益就消失了。另一方面,變分註意力(variational attention)具有很有優秀的效能,同時訓練速度與神經註意力模型相當。
5、Learning Efficient Convolutional Networks through Network Slimming
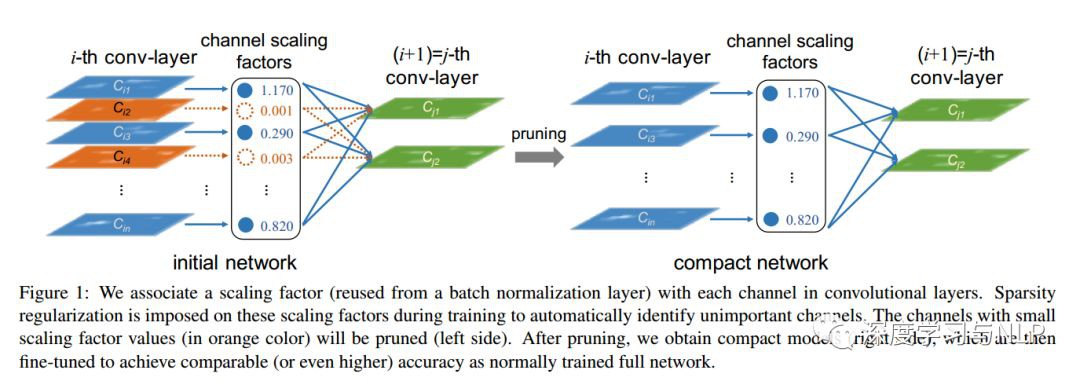
內容概述:摺積神經網路( CNNs )在許多實際應用中的部署在很大程度上受到其高計算成本的制約。本文提出了一種新的CNNs學習方法,同時實現以下標的: 1 )減少模型規模;2 )減少執行時的記憶體佔用;3 )在不影響精度的情況下,減少計算操作的次數。這是透過在網路中以簡單而有效的方式加強通道級的稀疏性(channel-level sparsity)來實現的。與現有的許多方法不同,該方法直接應用於CNN體系結構中,將訓練過程的開銷減到最小,並且所得到的模型不需要特殊的軟硬體加速器。我們稱之為“網路瘦身(network slimming)”方法,它以大而廣的網路為輸入模型,但在訓練過程中,會自動識別不重要的通道(channels)併在訓練結束後進行修剪,從而產生具有相當精確度且輕薄緊湊的模型。我們使用VGGNet、ResNet和densent等多種典型CNN模型,在各種影象分類資料集上實驗驗證了我們方法的有效性。對於VGGNet來說,network slimming使模型大小減少了20倍,計算操作減少了5倍。
6、The GAN Landscape: Losses, Architectures, Regularization, and Normalization
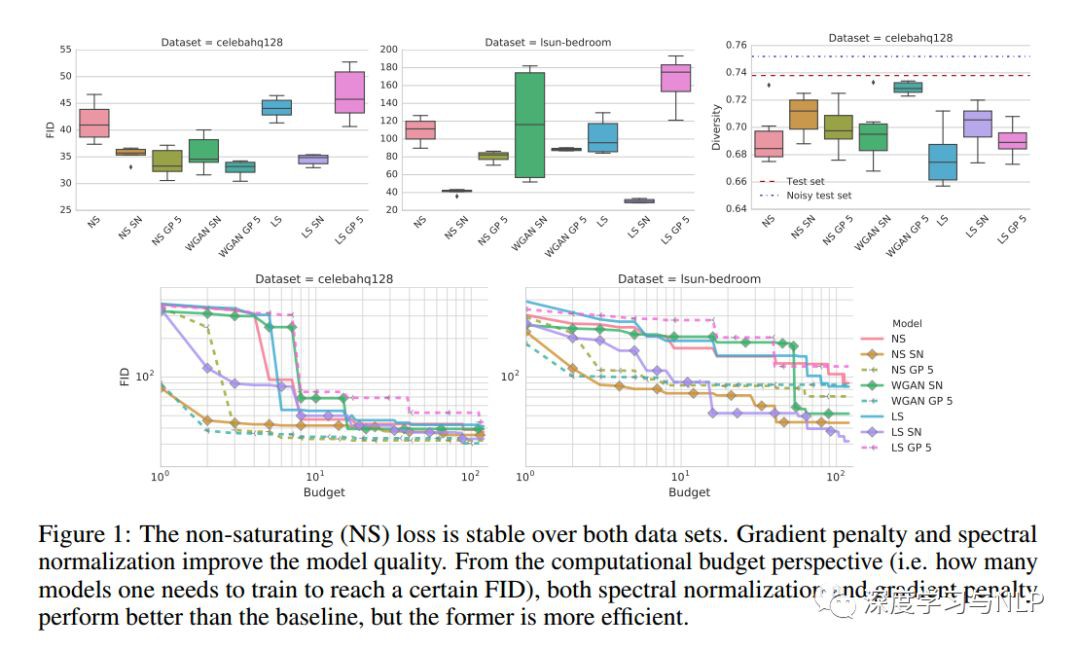
內容概述:生成對抗性網路( GANs )是一種深層生成模型(deep generative model),旨在以無監督的方式學習標的分佈(target distribution)。雖然GAN成功地應用於許多問題,但眾所周知,訓練GAN是一項的很具挑戰性的任務,需要大量的超引數調整(hyperparameter tuning)、神經架構工程和大量瑣碎的“trick”。許多成功的實際應用,加上缺乏對於GANs失敗可能性的量化,導致了大量proposed losses、正則化和歸一化方案以及神經架構。在這項工作中,我們從實際的角度出發,清醒地看待GAN的現狀。我們再現了GAN當前的狀況,並對其未來發展進行了適當的探索。我們討論常見的pitfall和raproducibility issues,在Github上開源我們的程式碼,併在TensorFlow Hub上提供預先訓練的模型。
7、Towards more Reliable Transfer Learning
內容概述:多源遷移學習(Multi-source transfer learning)已被證明在標的內標記資料(within-target labeled data)稀缺的情況下是有效的。以前的工作主要集中在利用域相似性,並且假設source domain被豐富地或者至少是相對地標記。儘管這一強有力的假設在實踐中從未成立,但本文適當忽略這一假設,著力於解決與不同標簽量和不同的可靠性來源相關的挑戰。第一個挑戰是融合領域相似性(domain similarity)和源可靠性(source reliability),提出一種新的遷移學習方法,它可以同時利用源–標的相似性和源間關係。第二個挑戰主要關於pool-based的主動學習(active learning),其中Oracle僅在源域中可用,從而形成了一個整合的主動遷移學習框架,其中包括分佈匹配(distribution matching)和不確定性取樣。在合成資料集和兩個真實資料集上的大量實驗有力證明,我們提出的方法優於包括state-of-art的遷移學習方法在內的多種baseline。
8、Universal Transformers
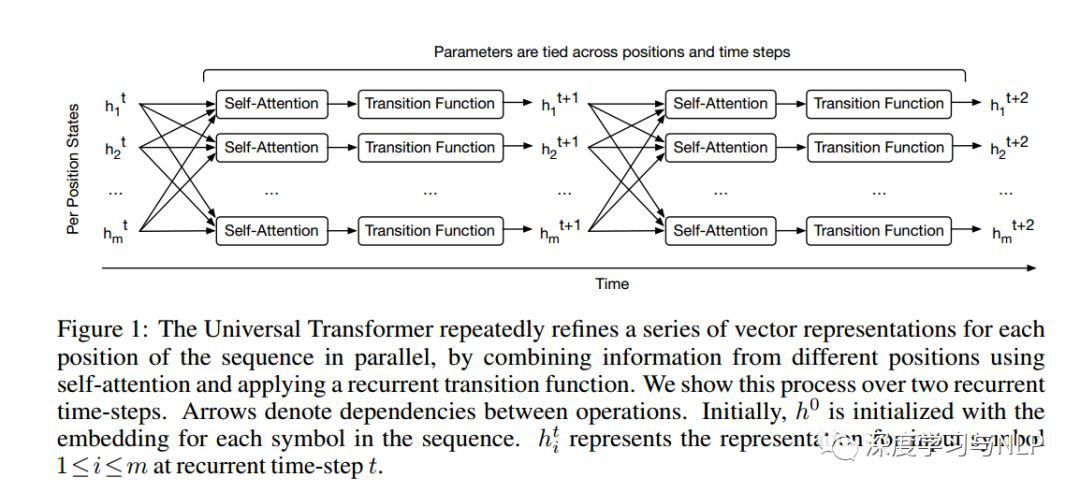
內容概述:Self-attentive前饋序列模型已經在序列建模任務上獲得了令人驚艷的成績,包括機器翻譯、影象生成和句法分析,從而被認為可以替代傳統的遞迴神經網路( RNNs ),而RNNs至今仍是解決許多序列建模問題的標準架構。然而,雖然取得了這些成功,但像Transformer這樣的前饋序列模型任然未能獲得廣泛使用,因為有些問題用RNN處理非常容易,但Transformer卻不行(比如,Transformer沒法實現複製機制(copy mechanism);並且,在推理(inference)階段,遇到比trainin corpus中更長的句子時,Transformer沒法處理)。此外,與RNNs相比,Transformer的計算速度更慢,這限制了其實際應用。本文提出了一種通用Transformer,它不僅能解決以上所以實踐或理論上存在的問題,併在幾個任務上都獲得了效能的提高。通用Transformer不像RNNs那樣,每次recurring只處理一個symbol,而是所有已經執行過的所有recurrent step都會參與計算,對每個step的representation都會進行revise。為了融合來自序列不同部分的資訊,通用Transformer在每個recurrent step都採用self-attention mechanism。假設有足夠的記憶體,通用Transformer的recurrence特性將提升它的計算效率。此外,我們還採用了自適應計算時間(adaptive computation time, ACT )機制,允許模型動態調整序列中每個位置的representation的修改次數。除了節省計算量,我們還表明ACT可以提高模型的精度。我們的實驗表明,在各種演演算法任務和多種大規模語言理解任務上,通用Transformer的泛化效果明顯優於普通Transformer和機器翻譯中的LSTM模型,在bAbI推理任務和具有挑戰性的LAMBADA語言建模任務上取得了最新的成績。
9、Recent Advances in Deep Learning: An Overview
內容概述:深度學習是機器學習和人工智慧研究的最新方向之一。也是當下最流行的科研方向之一。深度學習方法給計算機視覺和機器學習帶來了革命性的進步。時不時地就會有新的深度學習技術誕生,超越最好的機器學習甚至是現有的深度學習技術。近年來,深度學習技術取得了許多重大突破。由於深度學習技術正高速發展,特別是對於新入門深度學習領域的研究人員來說,很難follow該領域新的一些技術。在本文中,我們將簡要討論下過去幾年來深度學習的最新進展。
10、Manifold Adversarial Learning

內容概述:最近提出的對抗訓練方法提升了模型對對抗樣本的魯棒性,併在很多監督和半監督領域中取得了很多最優的結果。但所有現有的對抗訓練方法都只考慮了最糟糕的幹擾例子(即,對抗性例子)如何影響模型輸出,所以,儘管他們取得了成功,但這種方法只針對極端樣本,明顯缺乏普適性。在本文中,我們提出了一種新的對抗學習方法,稱為流形對抗性訓練(Manifold Adversarial Training, MAT )。MAT是基於最壞的擾動(perturbation)如何影響manifold而不是output space來構建一個對抗學習框架。首先得到一個具有高斯混合模型( Gaussian Mixture Model, GMM )的latent data space。一方面,MAT試圖以最壞的方式擾動輸入樣本,使其透過distribution manifold。另一方面,深度學習模型經過訓練,試圖在潛在空間中提升流形平滑度(manifold smoothness),並透過Gaussian mixture的變化(給定資料點周圍的區域性擾動)來測量。更重要的是,由於潛在空間比輸出空間更具資訊性(more informative),因此所提出的MAT可以學習到更健壯緊湊的資料表示,從而進一步提高效能。在三個基準資料集上進行了一系列有監督和半監督的實驗,結果表明,所提出的MAT能夠取得顯著的效能提升,遠優於目前最優的對抗性方法。
往期精彩內容推薦
基於深度學習的文字分類6大演演算法-原理、結構、論文、原始碼打包分享
模型彙總15 領域適應性Domain Adaptation、One-shot/zero-shot Learning概述
模型彙總-12 深度學習中的表示學習_Representation Learning
斯坦福大學2017年-Spring-最新強化學習(Reinforcement Learning)課程分享



DeepLearning_NLP


深度學習與NLP
商務合作請聯絡微訊號:lqfarmerlq