
本期內容選編自微信公眾號「開放知識圖譜」。
TKDE

■ 連結 | https://www.paperweekly.site/papers/2194
■ 解讀 | 花雲程,東南大學博士,研究方向為自然語言處理、深度學習、問答系統
動機
對於基於知識圖譜的事實性問答(KBQA),採用基於語法分析的方法,大致分為兩個階段:其一為問題理解,即將問題轉換為 SPARQL 型別的結構化查詢;其二為查詢評分,即對產生的結構化查詢進行置信度評分。
在問答系統中,重點是解決第一階段中的歧義性問題,即解決:第一,短語連結問題,即如何將自然語言問句中的短語連結到正確的物體/類/關係/屬性上;第二,複合問題,即一個自然語言問題可能轉換為多個知識圖譜三元組,而這多個三元組如何組合,才正確表達了問題的意圖,並由此得到正確答案。
因此,為瞭解決第一階段的兩個問題,本文提出基於圖匹配的方法,將解決歧義問題與查詢評分這兩個階段融合在一起,即當得到自然語言問題的一個正確匹配的查詢子圖時,歧義問題也已經同時解決了。
本文為了將自然語言轉換為查詢圖,提出了關係優先(relation-first)和點優先(node-first)的方法。前者從自然語言問句中,儘量抽取對應的關係,並從句法樹中抽取物體來構成查詢圖;後者從問句中儘量抽取對應的物體,再對物體之間的邊進行填充,來構成查詢圖。該方法不需要事先人工設立模板,且對複雜問句分析非常有效。
貢獻
文章的貢獻有:
1. 不同於已有的基於模板的工作,本文工作不需要預先設定模板;
2. 不同於已有的基於語意分析的工作,本文工作的將歧義性問題與查詢評分問題融合成一個問題來解決;
3. 本文工作對於解決複雜問題非常有效,且對於句法依存樹的使用具有容錯率。
方法
本文的工作主旨,是建立一個與自然語言問句意圖充分匹配的查詢圖 Qs,這個查詢圖中可以存在具有歧義性的物體(以節點表示)或關係(以邊表示)。當這個查詢圖被確定下來時,對應的結構化查詢也被唯一確定。
為了建立結構化查詢,本文首先從問句中形成以自然語言成分組成的查詢圖 Qs,再透過圖 Qs 與知識圖譜 G 的同構匹配,來得到結構化查詢。本文的工作主要分為線下和線上部分,其中線上部分又分為關係優先(relation-first)和點優先(node-first)的方法。
1. 線下部分的工作
線下工作,主要是建立兩個字典,分別用於物體-物體指稱和關係-關係指稱。
2. 線上部分的工作——關係優先框架(relation-first framework)
首先使用 Stanford Parser 將自然問句N轉換為句法依存樹 Y。由於線上下部分已經建立了關係指稱詞典,即每一個詞都可能被不同的關係指稱所包含,所以在關係優先框架中,對於 Y 中每一個詞(節點)wi,先找到所有包含 wi 的關係指稱,然後使用深度優先搜尋演演算法來遍歷 Y 中以 wi 為根的子樹,並判斷這個子樹是否與當前關係指稱一一匹配。
如果一個關係指稱中所有的字都在子樹中出現,那麼認為找到一個匹配的句法依存子樹 y,這個關係指稱也是符合自然問句 N 的。
當得到關係指稱之後,就需要找到與這個關係指稱相聯絡的主語和賓語節點。本文根據統計分析,基於句法樹中邊的詞性,而統計出屬於“subject-like”的邊,與“object-like”的邊。
分析關係指稱與句法依存樹,若在依存子樹 y 中有點 w 是可以被匹配為類/物體,則認為這個w是關係指稱的一個主語;否則,觀察 w 與它的子節點中,是否被 subject-like 的邊相連,若是的話,這個子節點就是這個關係指稱的主語。
同理,若 w 與子節點被 object-like 的邊相連,那麼關係指稱的賓語就是這個子節點。如果經過這種規則處理,找不到對應的主語/賓語,那麼就需要應用一些高階規則。
如下圖 1 所示,即一個尋找與關係指稱相關的主/賓語節點的示例。

▲ 圖1. 關係抽取示例
如圖 1,已知的關係指稱為“budget of”與“direct by”,由於“file”是匹配於物體或類,且“of”與子節點“film”之間以 object-like 的邊 pobj 相連,所以“film”是關係指稱“budget of”的賓語。
此外,雖然“is”與“budget”由subject-like的邊相連,但是“is”並不是一個可以匹配到物體/類的節點,所以“is”不是“budget of”的主語。根據前面所述,與“budget of”最相近的 wh- 詞是“what”,那麼它就是“budget of”的主語。
以上的工作,是透過自然語言問句與句法樹的分析,得到了查詢圖 Qs,後續需要再透過圖 Qs 與知識圖譜 G 的同構匹配,來得到結構化查詢。
Qs 中每一條邊都有匹配的候選謂詞,而 Qs 中每一個節點都有匹配的候選物體或者類,且根據關係指稱詞典和物體指稱詞典,均有一個置信度得分。當 Qs 與知識圖譜 G 進行匹配時,可以找到若干匹配的子圖,從中找到分數最大的 top-k 子圖,就是找到對應的結構化查詢。再執行這個查詢,就可以得到問題對應的答案。
3. 線上部分的工作——節點優先框架(node-first framework)
節點優先框架,是從自然語言問句中找到節點,再對填充節點之間的邊。當填充邊時,肯定會出現同一對節點之間以不同路徑相連的問題,所以透過識別節點、再填充邊的做法,形成的圖為超語意查詢圖 Qu,而 Qs 是其一個子圖。
首先用已有的方法識別出所有的物體指稱,並且將所有 wh- 詞和不能匹配到任何物體的名詞作為萬用字元。比如對於例句“What is thebudget of the film directed by Paul Anderson and starred by a Chinese actor?”可以識別出“what”、“film”、“Paul Anderson”、“Chinese”、“actor”。
其次進行結構的建立。利用句法依存樹,當兩個節點之間沒有其餘節點存在,那麼這兩個節點之間即認為是有邊或路徑相連,即為一個關係指稱,且路徑上所有邊的label組合成為這個關係指稱。
如下圖 2 所示,點“film”與點“Paul Anderson”、“actor”之間都沒有其餘節點存在,所以“film”與“Paul Anderson”存在關係,關係指稱為“directed by”;“film”與“actor”存在關係,關係指稱為“directedstarred by”,由此得到了節點間的關係指稱。
當兩個節點之間的指稱沒有 label 時,如圖 2 的“Chinese”和“actor”,那麼若兩個節點都為物體/類,那麼在知識圖譜中將這兩個節點間的關係填入;若其中一個節點為萬用字元,則在知識圖譜中定位另外一個節點,取與其連線頻數最高的那些謂詞作為候選關係填入。

▲ 圖2. 建立超語意查詢圖
經過關係填充,可以得到 Qu,而 Qu 中將包含所有節點,但以不同邊連線所有節點的子圖以 Si 表示。在將 Si 與結構化查詢圖進行匹配時,採用基於動態規劃的自頂向下的方法來逐步擴充套件。
即首先找到最可能匹配的部分子圖 Q,再將與 Q 中節點相連的邊逐一加入,並評估是否可以與知識圖譜G中的子圖匹配,若可以的話,則繼續加入邊到 Q,直到 Q 是 Qu 的包含了 Qu 所有節點的子圖,那麼就視為找到了一個語意查詢圖;若加入了一條邊後,後續無法產生匹配,則需要回溯,把這條邊從 Q 中刪去,重新加一條新邊,再進行迭代。
實驗
實驗使用了 QALD-6 資料集和 WebQuestions 資料集。QALD 中複雜問題較多,相比之下,WebQuestions 中的簡單問題(一個問題可以由一個三元組表示)居多。
如圖 3 所示的表格,在 QALD-6 的比賽中,NFF(節點優先框架)取得了第二名的成績,而第一名的 CANaLI 需要使用者手動輸入物體和謂詞,大大減少了系統難度,而 NFF/RFF 不需要這樣的人工操作。
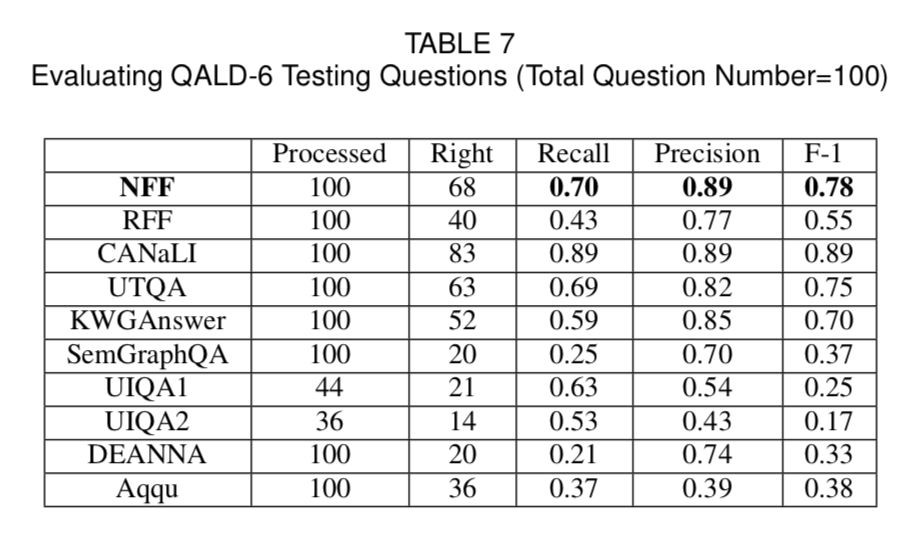
▲ 圖3. QALD-6測試結果
從圖 4 所示的表格可以見到,在 WebQuestions 的測試中,NFF 排在第三位,這是由於關係指稱詞典的改寫率在 WebQuestions 較低導致。而且,本文系統更加由於複雜問題的處理,所以將 Aqqu 放到 QALD 中,其效果降低了很多,遠遠不及本文系統。

▲ 圖4. WebQuestions測試結果
關於錯誤回答問題的分析,其一是由於詞典中的未登入物體/類/關係,導致匹配錯誤;其二是對於聚集型問題,本文的方法無法回答。
總結
這篇文章主要提出了一種基於圖匹配的方法,來進行自然語言問題的回答。與之前的工作不同的是,在本文的工作中,物體識別、關係識別的歧義性問題是在查詢評分的階段中完成的,而之前的工作是將這兩個階段分開進行。
由於是利用結構化查詢圖來進行答案檢索以及解決歧義,這是個高效的方法。所以,基於圖匹配的方法,不僅可以提高系統準確性(尤其是對於複雜問題),而減少了整個系統的響應時間。
此外,這些工作都可以利用文字來進行工程化地實現,並不涉及複雜的神經網路模型,在應用或專案中,容易實現。
IJCAI 2017

■ 連結 | https://www.paperweekly.site/papers/2192
■ 解讀 | 李丞,東南大學碩士,研究方向為知識圖譜構建及更新
動機
隨著知識圖譜技術的快速發展,知識圖譜正在越來越多的應用中扮演重要的角色。但是現有的知識圖譜存在一個很明顯的缺陷:圖譜中的資料的實時性很差。絕大多數知識圖譜從構建完成開始,其中的資料便不再更新。即使有更新,更新的週期也非常長。每一次的更新都是一次費時費力的、類似於重新構建知識圖譜的過程。
這樣的更新機制一方面需要消耗大量網路頻寬和計算資源,另一方面由於每次更新所消耗的代價太大,這就限制了更新的頻率,使得知識圖譜中資料的實時性非常差。由於缺乏一個實施的更新機制,圖譜中這些沒有同步更新的資料中存在大量的錯誤,這使得這些資料無法被利用。這種資料的滯後性給知識圖譜的應用帶來了很大的侷限性。
貢獻
1. 本文提出一個實時更新知識圖譜資料的方法框架,可以以較高的準確率預測出哪些物體需要被更新,從而以較低的代價和較高的頻率對知識圖譜進行更新,從而實現了知識圖譜的實時、動態更新;
2. 本文將其提出的知識圖譜更新框架部署在 cn-dbpedia 上,用於對 cn-dbpedia 的實時更新,更新頻率設定為每天更新一次,實踐結果表明,更新的效果非常好。
方法

本文所提出的知識圖譜更新框架主要分為 4 個步驟:
1. 從網際網路上抽取、識別出最近一段時間內熱門的實體(以下簡稱熱詞)。
熱詞的抽取來源包括:熱門新聞的標題、搜尋引擎的熱門搜尋以及入口網站的熱門話題。從這些來源抽取出熱門的短語或句子,利用命名物體識別(NER)技術抽取出其中的物體。
由於現有的 NER 技術的召回率都小於 90%,因此為了提高熱詞抽取的召回率,可以採用一種極端的方法:利用分詞技術直接對這些句子和短語進行分詞,然後窮舉分詞後得到的所有物體。如果百科頁面中有該物體相關的頁面,則該物體便抽取成功。
2. 根據第一步中抽取出的熱詞,對知識庫做更新。
更新的原則是如果知識庫中已經存在該物體,就到百科網站中對該物體做知識庫實時更新,如果知識庫中不存在該物體,就將該物體及其相關的百科資訊新增到知識庫中。
3. 從前兩步被更新的物體的百科頁面中的超連結中擴充套件得到和這些物體語意相關的更多物體,作為候選的待更新物體。
因為某一時間段的熱詞數量都是有限的,因此透過前兩步抽取出的熱詞數量很少,為了更新更多的物體,需要對熱詞進行擴充套件抽取。擴充套件抽取的方法就是從已經抽取出來的熱詞的百科頁面中的超連結中獲取更多的物體。
這一抽取方法是基於這樣的原理:如果一個物體在某一時間段內屬於熱詞,它的屬性值有可能會被經常更新,那麼和它語意相關的物體的屬性也很有可能需要被更新。而物體百科頁面中的連結正是表達了這樣一種語意相關的關係。
4. 對第 3 步得到的候選的待更新物體進行優先順序排序,按優先順序從高到底,依次對候選佇列中的物體到知識庫進行更新。
本論文所提出的知識圖譜更新框架追求一種實時性,即它對知識庫更新的頻率的要求是很高的。由於更新的頻率非常高,再加上百科網站也存在一定的反爬取策略,因此每次能更新的物體數量是有上限的。
本論文假定每天所挑選出的待更新的物體數量為 K。雖然並不能保證這 K 個物體最終都會有資料被更新,但是要想辦法使得最後所挑選出的 K 個待更新物體中,有盡可能多的物體最終得到了更新,而盡可能減少挑選出那些最後不需要被更新的物體,減少無用功。因此所有待更新的物體中,只能挑出部分優先順序高的進行更新。
本論文所提出的更新策略為:第 1 步中直接抽取出的熱詞具有最高的優先順序,優先進行更新。對於後面擴充套件抽取出的相關物體,按照優先順序由高到低依次進行更新,直至更新總數達到 K 或者待更新物體佇列為空為止。本文提出的優先順序刻畫模型為:

其中 x 為物體,E[u(x)] 是物體 x 的優先順序,P(x) 是物體 x 的預測更新頻率,該值由本論文設計並訓練的回歸模型預測得出,ts (x) 是知識圖譜中 x 最後一次被更新的時間。如果物體 x 不在知識圖譜中,ts (x) 定義為負無窮。由此可以看出,如果候選物體更新佇列中的有新的物體(現有知識圖譜中沒有的物體),那麼這些新的物體的更新優先順序會很高。
預測 P(x) 值得回歸模型透過監督學習的方式訓練得到。本論文為每個物體設計了 8 個特徵,包括物體在百科中存在的時長、總計被更新次數、使用者訪問次數、物體頁面中所有超連結總數、物體百科頁面長度等這些可以反應物體熱度的特徵。
透過這些特徵刻畫物體的熱度,然後透過監督學習的方式訓練生成回歸模型並用於預測物體的 P(x) 值。P(x) 值反映的是物體的被更新頻率,該值越大,代表物體的熱度越高,那麼它被更新的優先順序也更高。
實驗
本文實驗採用的資料集是 cn-dbpedia,將本文所提出的更新框架部署在 cn-dbpedia上,並將更新頻率設定為每天更新一次。更新效果如下表所示:
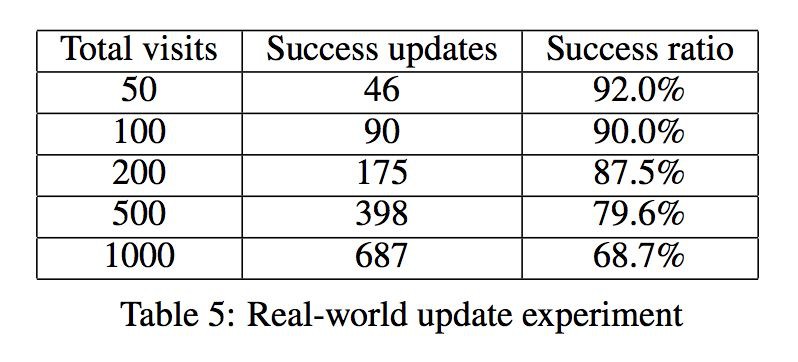
一次成功的更新是指檢查物體對應的百科頁面中的相關資訊,如果該物體的屬性發生了改變、需要被更新,那麼這次檢查是成功的。實驗結果表明,該框架在 cn-dbpedia 上更新的成功率較高,能夠有效地對知識圖譜進行動態的更新。
ICML 2017

■ 連結 | https://www.paperweekly.site/papers/2191
■ 原始碼 | https://github.com/rstriv/Know-Evolve
■ 解讀 | 王旦龍,浙江大學碩士,研究方向為自然語言處理
對於事件資料,需要動態更新的知識圖譜來儲存知識圖譜中關係的時許資訊。本文提出了 Know-Evolve 這種基於神經網路的動態知識圖譜來學習物體在不同時刻的表示。
在動態知識圖譜中,事件由四元組表示,相比於普通的三元組,增加了時間資訊,因此在動態知識圖譜中,物體之間的可能透過多個相同的關係連線,但是這些關係會關聯到不同的時序資訊。Know-Evolve 中,使用時間點過程(temporal point process)來描述時間點的影響。
在時間點過程中,某一時刻發生某事件的機率可以表示為:

其中:
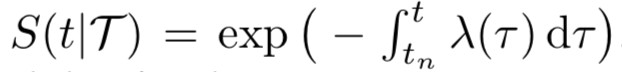
具體而言,Know-Evolve 中使用了 Rayleigh 過程來表示 λ(t),並使用一個神經網路來擬合 Rayleigh 過程的引數,對於發生在時刻 t 的四元組,有:

其中:

上式中,V 表示物體對應的向量表示,R 表示關係對應的矩陣,t-1 表示物體在上次被更新後的狀態,![]() 表示頭物體或尾物體中最後被更改的時間。
表示頭物體或尾物體中最後被更改的時間。
此外,每次將新的四元組加入到動態知識庫後,動態知識庫中與該四元組相關的物體也會相應地進行更新,更新地過程用一個 RNN 來表示。
對於頭物體,有:
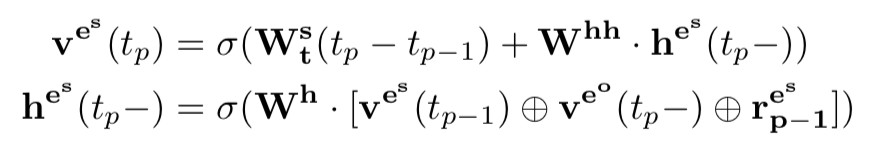
對於尾物體,有:
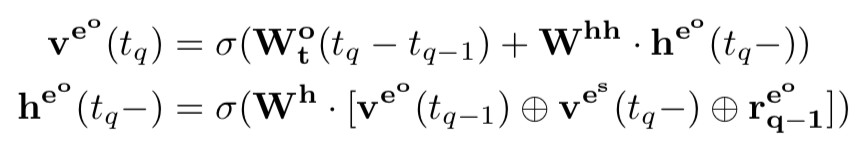
模型的訓練透過最大化訓練資料中四元組發生機率進行,對應的損失函式為對數損失函式。

在損失函式中,後一項需要對頭物體,關係,尾物體進行遍歷,這個計算量是很大的,本文中使用了取樣的方法來近似計算得到這部分的值。
實驗使用了 GDELT 和 ICEWS 這兩個時序知識庫,相比於其他的方法,本文的結果均有限制的提升。
ICML 2017

■ 連結 | https://www.paperweekly.site/papers/1656
■ 原始碼 | https://github.com/quark0/ANALOGY
■ 解讀 | 汪寒,浙江大學碩士,研究方向為知識圖譜、自然語言處理
本文的主要創新點就是把類比推理應用到 KG embedding 中,透過對模型的 score function 新增某些約束來捕獲 KG 中類比結構的資訊,進而最佳化 KG 中物體和關係的 embedding 表示,併在 FB15K 和 WN18 資料集上達到 state-of -the-art 效能。
Analogical Structure
什麼是類比結構?以 word embedding 中最著名的一句話為例,“man is to king as woman is to queen”,用 abcd 分別表示 man, king, woman, queen 四個物體,用 r 和 r’ 表示 crown 和 male->female 關係,這就可以得到四個三元組。

視覺化一下,就可以得到一個平行四邊形結構,捕獲這個結構的資訊也就是本文的 motivation,且更複雜的類比結構的基本組成單元就是這個平行四邊形結構。

對於線性對映來說,一個理想的特性,就是所有有相同起點和終點的有向圖,都形成了所謂的 compositional equivalence,在上圖中就是 ,且若關係集合 R 中任意兩個關係都滿足 compositional equivalence,則稱 R 是一個 commuting family。
,且若關係集合 R 中任意兩個關係都滿足 compositional equivalence,則稱 R 是一個 commuting family。
Method
本文將關係 r 視為線性對映,即給定三元組 (s,r,o),作者希望對於所有有效的三元組,都能滿足 ,滿足的程度就用一個 score function 表示,模型的標的就是學到恰當的 v 和 W,來讓這個 score function 給有效的三元組高分,無效的三元組低分。為什麼用線性對映而不用transE那樣的加法對映呢?作者的看法是,用矩陣定義的線性對映表達能力比用向量定義的加法對映更強。
,滿足的程度就用一個 score function 表示,模型的標的就是學到恰當的 v 和 W,來讓這個 score function 給有效的三元組高分,無效的三元組低分。為什麼用線性對映而不用transE那樣的加法對映呢?作者的看法是,用矩陣定義的線性對映表達能力比用向量定義的加法對映更強。

為了捕獲 KG 中類比結構的資訊,本文在objective function上加入了 Normal Matrix 和 compositional equivalence 的約束,而後者就是 ,即線上性對映上的具體實現,最後得到的 objective function 就是:
,即線上性對映上的具體實現,最後得到的 objective function 就是:

Why Normal Matrix
引理1,對於任意實正規矩陣 A,存在一個實正交矩陣 Q 和分塊對角矩陣 B,滿足 A=QBQT,其中 B 的每個對角塊要麼是個實數,要麼是個 2 維實矩陣,x 和 y 都是實數。這個引理表明任意一個實正規矩陣都可以分塊對角化。
引理 2,若一系列實正規矩陣組成了一個 commuting family,那麼它們可以用同一個 Q 分塊對角化。這個引理表明,若一個稠密關係矩陣集合{Wr}相互可交換,那麼就可以同時被分塊對角化成一個稀疏矩陣集合{Br}。
結合以上兩個性質,可以對 score function 進行推導,過程如下:

即對於任意標的函式 7 的解 (v*,W*) ,都有對應的 (u*,B*) 滿足。
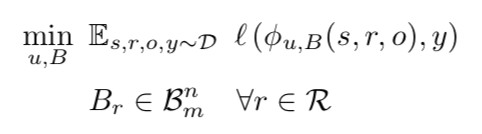
標的函式簡化成了這個樣子,其中 B 表示對角線上有 n 個實數的 m 階對角方陣。
Unified View of Representative Methods
作者也證明瞭本文模型是 unified method,以 DistMult 為例,它的 score func 如:

實際上這就是 n=m 的 ANALOGY 版本,其中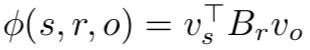 ,
, 。
。
Experiments
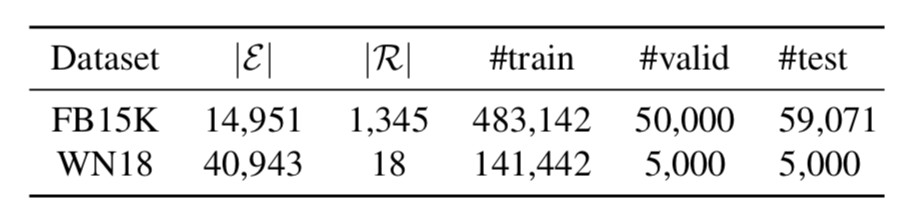
實驗用的資料集是 FB15K 和 WN18,作者用了 19 個 baseline 做對比,metrics 用的也是常用的 MRR 和 Hits@k。由下表可以知道 FB15K 的關係數非常多,因此對其建模也更難,KG 中包含的類比結構也更多,而在這個資料集上,ANALOGY 的表現超過了所有 baseline 模型,這證明瞭捕獲類比結構資訊的作用。
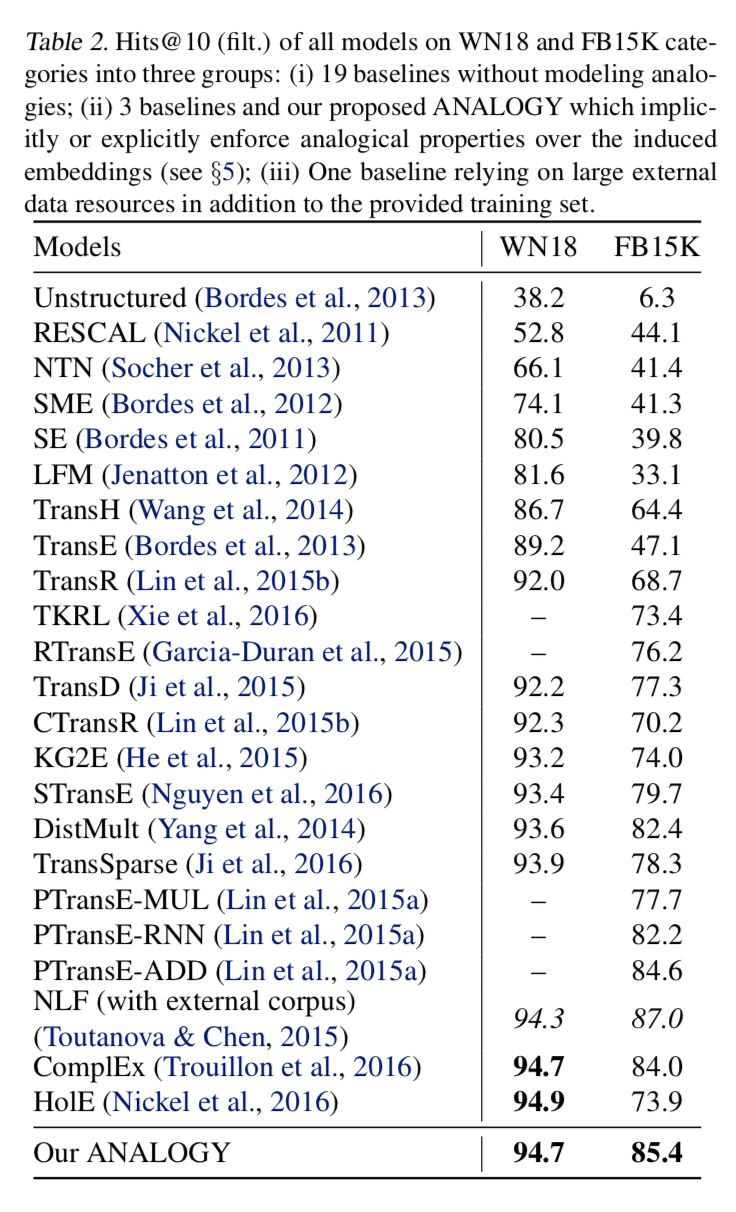
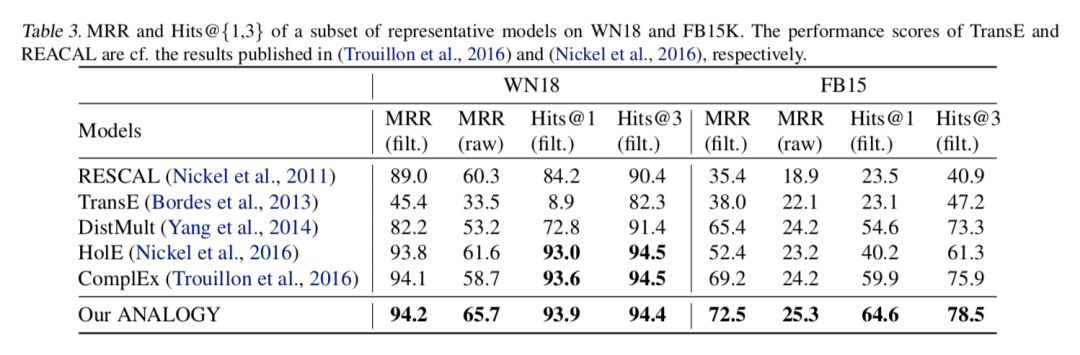
而下圖則表明在所有指標上,ANALOGY 的表現都超過了 DistMult,ComplEx 和 HolE,且這三個是 ANALOGY 的特例。
ACL 2017

■ 連結 | https://www.paperweekly.site/papers/2195
■ 解讀 | 吳桐桐,東南大學博士生,研究方向為自然語言問答
導讀
學術界近兩年來十分關註如何將文字等非結構化資料和知識庫等結構化資料對映到相同的語意空間中,然而在相同的語意空間中建模的過程會受到文字中物體指稱(mention)歧義的影響,即文字中的同一個姓名如邁克爾·喬丹可能指的是著名的籃球運動員喬丹也可能是我們敬仰的教授喬丹,那麼在語意空間中,因為他們的字面表達相同而將其建模成為統一的向量顯然是不合理的。
因此,文中提出了一種新的 mention 向量表示的學習框架Multi-Prototype Entity Mention Embedding (MPME),它可以根據物體指稱所對應的詞義的不同而聯合文字和知識庫學習到不同的表示。
此外,文中提出了一種類似於語言模型的方法解決了物體指稱的語意消歧問題。最後,實驗部分利用物體連結任務作為 MPME 的應用場景,取得了當前最優的實驗效果。
研究動機
當前有相當多的工作研究如何將文字和知識庫進行關聯建模,顯然這樣會為自然語言處理及知識庫相關的研究任務帶來比較大的效能提升。
當前的研究思路可以粗略地分為兩類,其一是利用深度神經網路將物體和詞語直接在統一的語意空間中進行建模,但這類方法比較受限於計算複雜度以及語料的規模。其二是分別對知識庫中的物體以及文字中的物體指稱進行建模,並且利用 wiki 百科中的外鏈獲取 mention 和 entity 之間的關聯,相當於在各自訓練的過程中加入了一層約束用於確保他們在各自的語意空間中有相似的表達。
上述兩類方法都會面對同一個物體指稱可能對應到多個物體的歧義問題,即文字中提到的邁克爾喬丹可能是教授也可能是運動員或其他不甚知名的人,也會面臨多個物體指稱對應同一個物體的歧義問題,即文字中出現的姚明和小巨人可能指的同一個人。因此本文著手解決物體指稱的語意歧義問題,類似於傳統的物體連結任務。
創新點
本文提出了一種新型的物體指稱表示學習方法 MPME,結合文字資訊以及知識庫資訊學習物體指稱的表示;此外,文中還提出了一種基於語言模型的決策方法來進行物體指稱的語意消歧。
模型
本文使用的資料是從 New York Times 上抓取的 99872 篇文章。在定性分析中,apple,amazon,obama,trump 的詞義變化軌跡如下所示:

▲ MPME框架結構示意圖
如圖所示,模型可以大致分成兩個部分。
其一是表示學習部分,透過 Word Embedding 和 Knowledge Graph Embedding 對文字和知識庫分別進行建模,其中每個物體指稱都對應著一個物體集合,也就是它們潛在的語意。
在 Entity Representation Learning 中,訓練的標的是有相似的關聯物體的物體之間更相似。在 Text Representation Learning 中,物體指稱將和其他詞彙一起透過 Skip-Gram 模型進行訓練,在Mention Representation Learning 中,物體指稱被替換為相應的詞義(sense),背景關係的表示來自文字表示學習部分,物體的表示來自知識庫表示學習部分,標的是得到更好的物體指稱的表達 sj*,使得根據背景關係資訊,能夠確定物體指稱所對應的語意(對應哪個物體)。
其二是測試場景下的消歧部分,模型會綜合考慮物體指稱對應的背景關係資訊,以及物體指稱對應各個語意的統計機率分佈進行計算。
實驗結果
文章的標的是訓練得到一組高質量的物體指稱向量,仍然沒有跳出表示學習的框架,因此實驗部分首先比較了採用 MPME 之後,訓練得到的向量的相似物體指稱都有哪些,以及從 mention embedding 和相應的 entity embedding 餘弦距離的角度進行了分析,各項指標相對對比模型 SPME 提高了 1% 左右,這一部分就不做贅述了。
同時,文章利用 mention embedding 在物體連結任務上進行了驗證,在 AIDA 資料集上,不管是有監督的物體連結任務還是無監督的物體連結任務,利用 MPME 均取得了相較於之前最好結果 3% 左右的提升。
啟發
mention之間的資訊
本文中把文字和知識庫分別單獨進行建模,mention 的建模過程中比較多的考慮 mention 和 entity 之間的關聯,所謂的背景關係更多的是以詞視窗內詞彙的形式出現的,而不是背景關係中其他的 mention,因此有可能會忽略一些關鍵的資訊。
傳統的物體連結方法中比較多使用的一類是基於圖的演演算法,其優勢便在於能夠更充分的發掘 mention 和 mention 之間,mention 和 entity 以及 entity 和 entity 直接的結構關聯資訊,利用這些資訊進行消歧已經足夠有效(體現在物體連結任務的準確率上),那麼也可以嘗試利用圖結構更好地學習 mention 的表示。
潛在的問題在於,假設 mention 所對應的兩個歧義物體屬於同一個 category,那麼它們會共享十分相似的背景關係,透過本文所題出的方法將不能很好的解決這個問題。比如兩隻都叫做旺財的狗,它們的日常表現應該會比較相似,唯一不同的可能就只有它們的主人不同,這一點需要背景關係中 mention 的參與,共同建模。
未登入詞的處理
實際的應用場景中,未登入 mention 的數目理應遠多於已經訓練的 mention 的數目,這樣才能體現出模型或方法的泛化能力,這也為我們提出更加 general 的 framework 提出的新的需求,或者說,訓練的過程盡可能簡單,所需的額外資訊盡可能的少,對未登入詞的發現更加友好的框架。
NIPS 2017

■ 連結 | https://www.paperweekly.site/papers/2193
■ 原始碼 | https://github.com/fanyangxyz/Neural-LP
■ 解讀 | 張文,浙江大學博士生,研究方向為知識圖譜的分散式表示與推理
動機
本文提出了一個可微的基於知識庫的邏輯規則學習模型。現在有很多人工智慧和機器學習的工作在研究如何學習一階邏輯規則,規則示例如下圖:

形式化本文關心的邏輯規則如下:

每一個規則由多個約束條件組合而成,並且被賦予一個置信度 α,其中 query(Y,X) 表示一個三元組,query 表示一個關係。
不同於基於 embedding 的知識庫推理,規則應該是物體無關的,規則可以應用於任何新新增到知識庫中的物體,但在知識庫 embedding 方法裡,新新增到知識庫中的物體由於沒有對應的表示,無法就這些物體進行相關的推理。
不同於以往的基於搜尋和隨機遊走的規則學習方法,本文的標的是提出一個可微的一階謂詞邏輯規則學習模型,可用基於梯度的方法進行最佳化求解。
本文提出的 Neural LP 模型主要收到 TensorLog 的啟發。TensorLog 可視為一個可微的推理機。知識庫中的每個物體用一個 one-hot 向量表示,每個關係 r 定義為一個矩陣運算元 M_r,M_r 為一個稀疏的毗連矩陣,維度為 n_e×n_e, 其中 n_e 表示物體的個數。每一條邏輯規則的右邊部分被表示為以下形式:
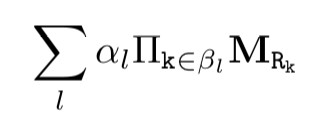
所以總結本文關心的最佳化問題如下:

V_x 和 V_y 分別為一個由規則推理得到的三元組。在上式的最佳化問題中,演演算法需要學習的部分分為兩個:一個是規則的結構,即一個規則是由哪些條件組合而成的;另一個是規則的置信度。
由於每一條規則的置信度都是依賴於具體的規則形式,而規則結構的組成也是一個離散化的過程,因此上式整體是不可微的。因此作者對前面的式子做了以下更改:

主要交換了連乘和累加的計算順序,對預一個關係的相關的規則,為每個關係在每個步驟都學習了一個權重,即上式的![]() 。其中 T 為超參,表示規則的長度。由於上式固定了每個規則的長度都為 T,這顯然是不合適的。
。其中 T 為超參,表示規則的長度。由於上式固定了每個規則的長度都為 T,這顯然是不合適的。
為了能夠學習到變長的規則,Neural LP 中設計了記憶向量 u_t,表示每個步驟輸出的答案——每個物體作為答案的機率分佈,還設計了兩個註意力向量:一個為記憶註意力向量 b_t ——表示在步驟 t 時對於之前每個步驟的註意力;一個為運算元註意力向量 a_t ——表示在步驟 t 時對於每個關係運算元的註意力。
每個步驟的輸出由下麵三個式子生成:

其中 a_t 和 b_t 基於一個 RNN 生成,具體如下:
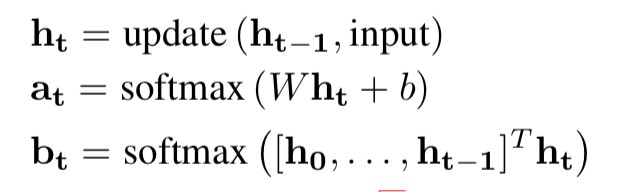
其中隱層變數 h_t 由一個 LSTM 生成。
本文還設計了一個根據訓練結果解析規則的演演算法如下:

實驗
本文的實驗相當豐富,主要包括:
1. 兩個標準資料集上的統計關係學習相關的實驗

2. 在 1616 的網格上的路徑尋找的實驗

3. 知識庫補全實驗

為了證明 Neural LP 的歸納推理的能力,本文還特別設計了一個實驗,在訓練資料集中去掉所有涉及測試集中包含的物體的三元組,然後訓練並預測,得到結果如下:
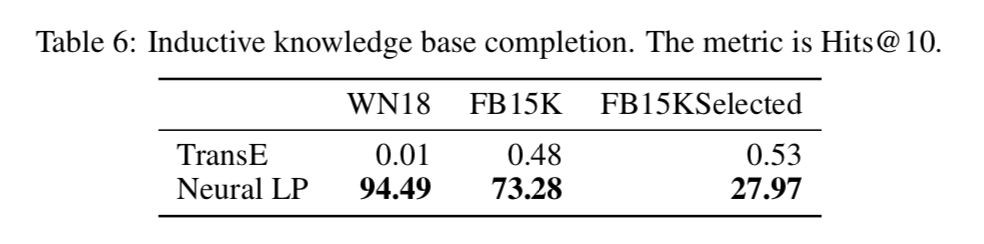
這個實驗有效地證明瞭 Neural LP 的歸納推理的能力。
4. 知識庫問答的實驗

總結
本文提出了一個可微的規則學習模型,並強調了知識庫中的規則應該是物體無關的,非常值得借鑒。有興趣的讀者可以閱讀一下原文。

點選以下標題檢視更多相關文章:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視更多論文推薦
