
[ 導讀 ]英雄聯盟是一個需要默契團隊配合的多人對戰遊戲。在瞬息萬變的戰鬥中,如何做出正確的決策非常重要。最近,資料分析師 Philip Osborne 提出了一種利用人工智慧技術提升英雄聯盟中團隊決策水平的方法,並將其開源。該方法不僅參考了大量真實遊戲的統計結果,也將當前玩家的偏好計算在內。

該專案由三部分組成,旨在將 MOBA 遊戲《英雄聯盟》的對戰建模為馬爾科夫決策過程,然後應用強化學習找到最佳決策,該決策還考慮到玩家的偏好,並超越了簡單的“計分板”統計。
作者在 Kaggle 中上傳了模型的每個部分,以便大家更好地理解資料的處理過程與模型結構:
第一部分:
https://www.kaggle.com/osbornep/lol-ai-model-part-1-initial-eda-and-first-mdp
第二部分:
https://www.kaggle.com/osbornep/lol-ai-model-part-2-redesign-mdp-with-gold-diff
第三部分:
https://www.kaggle.com/osbornep/lol-ai-model-part-3-final-output
目前這個專案還在進行當中,我們希望展示覆雜的機器學習方法可以在遊戲中做什麼。該遊戲的分數不只是簡單的“計分板”統計結果,如下圖所示:

動機和標的
英雄聯盟是一款團隊競技電子游戲,每局遊戲有兩個團隊(每隊五人),為補兵與殺人展開競爭。獲得優勢會使玩家變得比對手更強大(獲得更好的裝備,升級更快),一方優勢不斷增加的話,獲勝的機率也會變大。因此,後續的打法和遊戲走向依賴於之前的打法和戰況,最後一方將摧毀另一方的基地,從而贏得比賽。
像這種根據前情建模的情況並不新鮮;多年來,研究人員一直在考慮如何將這種方法應用於籃球等運動中(https://arxiv.org/pdf/1507.01816.pdf),在這些運動中,傳球、運球、犯規等一系列動作會導致一方得分或失分。此類研究旨在提供比簡單的得分統計(籃球中運動員得分或遊戲裡玩家獲取人頭)更加詳細的情況,並考慮建模為時間上連續的一系列事件時,團隊應該如何操作。
以這種方式建模對英雄聯盟這類遊戲來說更為重要,因為在該類遊戲中,玩家補兵和殺人後可以獲得裝備並升級。例如,一個玩家拿到首殺就可以獲取額外金幣購買更強的裝備。而有了這些裝備之後,該玩家變得更加強大進而獲取更多人頭,如此迴圈,直到帶領其隊伍獲取最後的勝利。這種領先優勢被稱為“滾雪球”,因為該玩家會不斷積累優勢,不過很多時候,該玩家在遊戲中所在的隊伍並不一定是優勢方,野怪和團隊合作更為重要。
該專案的標的很簡單:我們是否可以根據遊戲前情計算下一步最好的打法,然後根據真實比賽資料增加最終的勝率。
然而,一場遊戲中影響玩家決策的因素有很多,沒那麼容易預測。不論收集多少資料,玩家獲得的資訊量始終多於任何一臺計算機(至少目前如此!)。例如,在一場遊戲中,玩家可能超水平發揮或發揮失常,或者偏好某種打法(通常根據他們選擇的英雄來界定)。有些玩家自然而然地會變得更加好鬥,喜歡殺戮,有些玩家則比較被動一直補兵發育。因此,我們進一步開發模型,允許玩家根據其偏好調整建議的打法。
讓模型“人工智慧化”
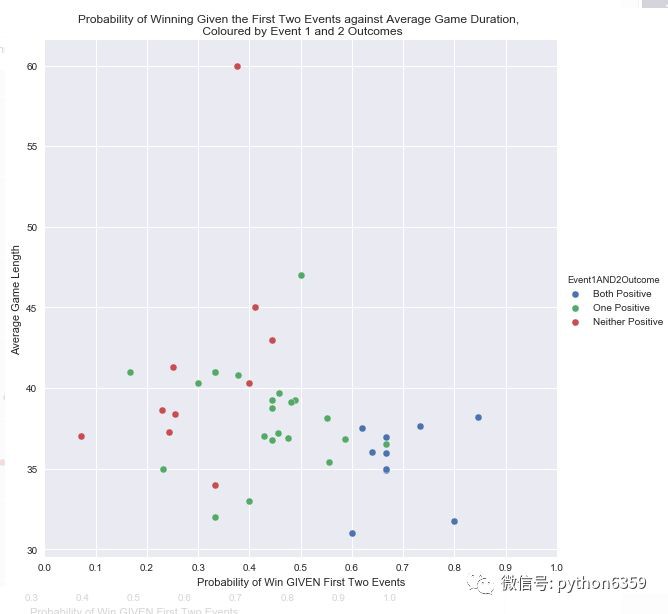
在第一部分中,我們進行了一些介紹性的統計分析。例如,假設隊伍在比賽中補到第一個和第二個兵,我們能夠計算出獲勝的機率,如下圖所示。
有兩個組成部分,使我們的專案超越簡單的統計的人工智慧:
-
首先,在未預先設想遊戲概念時,模型會學習哪些行動是最好的。
-
第二,它試圖瞭解玩家對影響模型輸出的決策的偏好。
我們定義馬爾可夫決策過程及收集玩家喜好的方式會決定模型學習和輸出的內容。
根據匹配統計資訊對馬爾科夫決策過程進行預處理和建立。
AI 模型 II:引入打錢效率
我從第一個模型的結果中意識到,我們沒有考慮到負面和正面事件對未來都可能產生累積的影響。換句話說,無論在當時時間點之前還是之後,當前的 MDP(馬爾科夫決策過程)機率都有可能發生。在遊戲中,這是不正確的。一旦落後,殺人、拿塔、補兵都會變得更難,我們需要考慮到這一點。所以,我們引入隊伍間的打錢效率來重新定義狀態。當前標的是建立一個定義狀態的 MDP,這個狀態可能是事件發生順序,或者隊伍是否落後或領先。我們將金幣差值分為以下幾類:
-
相等:0–999 金幣差值(平均每個隊員 0-200)
-
略落後/領先:1,000–2,499(平均每個隊員 200–500)
-
落後/領先:2,500–4,999(平均每個隊員 500–1,000)
-
遠遠落後/遙遙領先:5,000(平均每個隊員 1,000+)
我們也需要考慮沒有任何事件發生的情況,並把其歸為“無”事件中,以保證每分鐘都有事件發生。這個“無”事件表示一個隊伍決定拖延遊戲,以將那些在早期遊戲中更善於獲得金幣的隊伍區分出來,而不需要殺死(或透過小兵殺死)他們。然而,這樣做也會大大增加資料量。因為我們為匹配可用匹配項已經添加了 7 個類別,但如果我們能訪問更常規的匹配項,那資料量就已足夠了。如前所述,我們可以透過以下步驟來概述:

預處理
-
輸入殺人數、塔數、野怪和金幣差值的資料。
-
將“地址”轉為 ID 特性。
-
移除所有舊版本的遊戲。
-
從金幣差值開始,按照事件的時間、匹配 ID 和與以前一致的團隊進行合計。
-
追加(助攻的)人頭數、怪數和塔數到此末尾,為每個事件建立行並按發生的時間對事件進行排序(平均人頭數)。
-
新增“事件序號”特性,顯示每次匹配中的事件順序。
-
為行上的每個事件建立一個統一的“事件”特性,包括人頭、塔、怪或者“無”事件。
-
每次匹配時將其轉化為行,現在是用列來表示每個事件。
-
只考慮紅隊的視角,以便合併列,視藍隊增益為負紅隊增益。同時增加紅隊的遊戲長度和結果。
-
將所有空白值 (即在前面步驟中結束的遊戲) 替換為匹配的遊戲結果,以便所有行中的最後一個事件是匹配結果。
-
轉換為 MDP,其中 P(X_t | X_t-1)用於每個事件數和由金幣差值定義的狀態之間的所有事件型別。

馬爾科夫決策過程輸出
使用簡易的模型 V6 程式碼
我們最終版本的模型簡單總結如下:
-
引入引數
-
初始化啟動狀態、啟動事件、啟動操作
-
根據 MDP 中定義的首次提供或基於其發生可能性的隨機選擇操作
-
當行動贏或輸時,結束
-
跟蹤事件中所採取的行動和最終結果(贏/輸)
-
根據最終結果所用的更新規則來更新操作
-
重覆 x 次上述步驟
引入獎勵偏好
首先,我們調整模型程式碼,把獎勵歸入回報計算中。然後,當我們執行模型時,引入了對某些行為的偏置,而不是簡單地使獎勵等於零。
-
在第一個例子中,我們顯示瞭如果對一個動作進行積極的評價,會發生什麼;
-
在第二個例子中,顯示對一個動作進行消極的評價,會發生什麼。

如果我們積極評價動作“+KILLS”的輸出

如果我們消極評價動作“+KILLS”的輸出
更真實的玩家偏好
現在我們可以嘗試近似模擬玩家的真實偏好。在這個案例中,我們隨機化一些獎勵以允許遵守以下兩條規則:
-
玩家不想錯過任何補兵
-
玩家優先補兵而不是殺人
因此,我們對人頭和補兵的獎勵都是最小值-0.05,而其它行動的獎勵都在-0.05 和 0.05 之間隨機生成。

隨機化玩家獎勵後的輸出
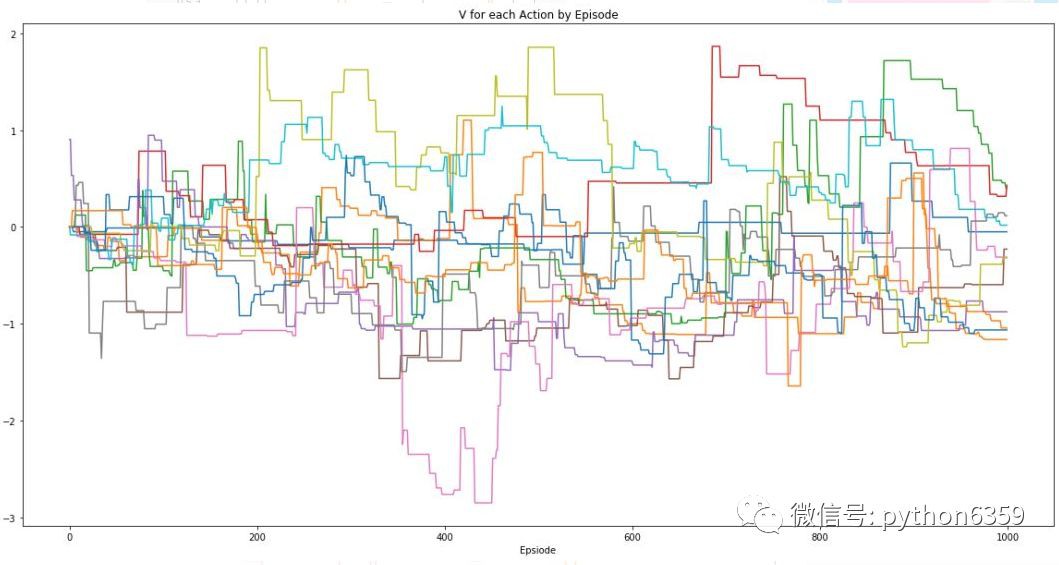
隨機化玩家所有動作的獎勵後所獲得的輸出
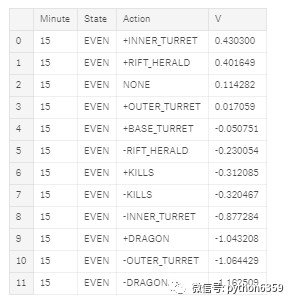
最終輸出,顯示給定當前金幣差值狀態和分鐘的每個動作的值
總結及玩家對獎勵的反饋
我過分簡化了某些特徵(如“kills”實際上並不代表人頭的數量),資料也不太可能表示正常的匹配。然而,我希望本文能夠清晰地展現一個有趣的概念,鼓勵更多人討論這一領域今後的走向。
首先,我將列出在實現之前需要作出的重要改進:
-
使用更多能夠代表整個玩家群體(而不只是競爭性比賽)的資料計算 MDP。
-
提高模型效率,將其計算時間控制在更合理的範圍。蒙特卡洛以耗時著稱,因此我們將探索更高效的演演算法。
-
採用更高階的引數最佳化以進一步改進結果。
-
捕捉、對映原型玩家對更真實的獎勵訊號的反饋。
我們引入了針對影響模型輸出而給予的獎勵,但該如何獲得獎勵?我們可以考慮幾種方法,但是根據我之前的研究,我認為最好的方法就是考慮一種既涉及到行動的個體質量又考慮到轉變質量的獎勵。
這變得越來越複雜,我不會在此文中展開,但簡而言之,我們想為玩家匹配決策,其中下一個最佳決策取決於最新情況。比如,如果一隊玩家將對方全部殲滅,他們可能會去拿大龍。我們的模型已經將一個序列中事件發生的機率考慮在內,因此,我們也應該用同樣的方式思考玩家的決策。這一想法來自一篇論文《DJ-MC: A Reinforcement-Learning Agent for Music Playlist Recommendation》,該論文闡釋瞭如何更加詳細地將反饋映射出來。
反饋的收集方式決定了我們的模型能有多成功。依我之見,我們這麼做的最終標的是為玩家的下一步決策提供最佳實時建議。如此一來,玩家就能從根據比賽資料算出的幾條最佳決策(根據獲勝情況排序)中做出選擇。可以在多個遊戲中跟蹤該玩家的選擇,以進一步瞭解和理解該玩家的偏好。這也意味著,我們不僅可以追蹤決策的結果,還能預測該玩家的意圖(例如,該玩家試圖拆塔結果卻被殺了),甚至還能為更高階的分析提供資訊。
當然,這樣的想法可能造成團隊成員意見不符,也可能讓遊戲變得沒那麼令人興奮。但我認為這樣的想法可能對低水平或者常規水平的玩家有益,因為這種水平的遊戲玩家難以清楚地溝通遊戲決策。這也可能幫助識別“毒瘤”玩家,因為團隊指望透過投票系統來統一意見,然後就能看出“毒瘤”玩家是不是一直不遵循團隊計劃,忽略隊友。

實時遊戲環境中的模型推薦投票系統示例
原文連結:
https://towardsdatascience.com/ai-in-video-games-improving-decision-making-in-league-of-legends-using-real-match-statistics-and-29ebc149b0d0
