

花掉大筆經費建設的超算機群為什麼儲存效能這麼差?怎麼向領導交待?
儲存產品那麼多,聽起來都很好,但誰都不說裡面都什麼坑,真是難選。
我只想安靜地寫程式做科研,卻被儲存裝置折磨得頭疼,浪費時間,怎麼避開那些大坑呢?
在NFS環境上測試MPI程式,並行讀寫同一個檔案怎麼結果不對?
程式語言、操作命令很容易學會,但背後的原理不清楚。簡單明瞭的參考資料好難找,一上來就用一堆程式碼講解,看起來費時費力。
這篇文章試圖解決這幾個問題。著急的讀者可以只看結論,然後轉發了事:-)
-
超算應用的並行讀寫樣式與常用儲存測試用例差別很大,從而導致儲存裝置的演示測試效能高,而實際應用效能差。
-
MPI-IO的開發單位說了,決不推薦NFS儲存,效能差。NFS協議為序列讀寫設計,多個客戶端之間相互不協調,導致負載不均、延時增大、元資料開銷增多等後果(能比正常頻寬低80%)。從原理上看,非對稱架構的儲存產品更適合超算軟體的MPI並行IO。
-
在NFS上並行讀寫同一個檔案時,一定要用NFS v3版本的客戶端,併在掛載的時候加上noac選項,否則檔案資料可能不正確。
-
如果序列讀寫檔案,可用NFS儲存;如果並行讀寫檔案,用NFS儲存要能忍受它的低效能。Lustre等非對稱檔案系統並行讀寫效能較高。
-
本文力求淺顯易懂,說清NFS儲存並行讀寫效能差的背後原因。
儲存的功能、效能指標很多,超級計算機看重哪些指標呢?
儲存的可靠性永遠第一位,不能丟資料、不能頻繁故障。第二位的就是讀寫效能,頻寬越高越好。克隆、備份、遠端複製等功能只是錦上添花,不太重要。
流行的儲存產品就可以認為足夠穩定,讀寫效能則強烈地依賴於儲存的介面協議。
市面上的檔案系統很多,但儲存介面協議不多:標準的NFS協議和私有協議。NFS協議應用廣泛,計算節點上安裝的NFS客戶端也由專業機構開發,與作業系統的相容性好。為了得到更好的效能,Lustre這樣的檔案系統選擇自行設計私有協議,自行開發私有客戶端;私有客戶可能對作業系統的版本有一定要求,更新速度也慢,相容性較差。
標準的並不總是好的,對超算機群來說,NFS檔案系統就是噩夢,具體表現如下:
負載不均
小型NFS檔案系統只有1個或2個儲存伺服器(或稱為儲存機頭),不在本文討論範圍內。
超算機群的資料量很大,需要使用分散式檔案系統(3個及以上儲存伺服器)。
NFS協議要求每臺計算伺服器都在掛載一個NFS伺服器,見圖1,一旦掛載成功,就不再改掛其它NFS伺服器;通常在計算伺服器開機的時候執行掛載動作,關機的時候再斷開連線。
超算機群的計算伺服器的數量通常遠遠多於NFS伺服器的數量,例如5:1或10:1甚至更高,因此多臺計算伺服器會掛載同一臺NFS伺服器。為獲得最好效能,計算伺服器與NFS伺服器之間的對應關係要保持均衡,見圖1,計算伺服器C0和C3都掛載NFS伺服器S0,C1和C4都掛載S1。

圖 1
假設一個超算機群有100臺計算伺服器,3臺NFS伺服器。儲存產品的域名掛載功能通常能使每臺NFS伺服器被33或34臺計算伺服器掛載,負載相當均衡。
機群上執行的計算任務,絕大部分不會佔用超過一半的計算伺服器(否則這個機群就該擴容了)。假設一個計算任務佔用8臺計算伺服器,這8臺計算伺服器是由作業排程軟體分配的,有一定的隨機性。最壞的情況下,這8臺計算伺服器掛載的都是同一臺NFS伺服器。那麼8臺計算伺服器上的MPI集合IO操作都會壓到1臺NFS伺服器上,而另外2臺NFS伺服器空閑,浪費了2/3的IO潛力。
這樣的極端不均衡情形出現的機率也許不太大,但中等不均衡狀況出現的機率相當大,例如4/2/2臺計算伺服器分別掛載NFS伺服器C0/ C1/ C2。MPI-IO中的集合IO結束時會有一個行程間同步,因此,聚合IO操作的速度取決於最慢行程的速度,進而取決於負載最重的NFS伺服器C0的速度。
NFS的掛載機制決定了負責不均不可避免:一旦掛載成功,客戶端中途不會自動改變所掛載的NFS伺服器。想中途更改的話,要麼管理員手動改變NFS客戶端與NFS伺服器之間的掛載關係,要麼編寫指令碼根據作業情況自動掛載。中途更改會帶來3個嚴重問題:
-
1. 同一臺計算伺服器上可能執行著兩個或兩個以上的作業,為了一個作業而更改掛載關係,會使其它作業中斷;
-
2. 每個NFS客戶端更改掛載關係不是瞬間完成的,通常會花費幾秒鐘甚至1分鐘,頻繁更改會給儲存裝置帶來壓力;
-
3. 超算機群上通常同時執行著很多個作業,找出一個對所有作業都均衡的掛載方案也是不一件容易的事情。
而Lustre等非對稱檔案系統只掛載元資料伺服器,不掛載IO伺服器,Lustre客戶端可以直接訪問任意的IO伺服器,因此不存類似的負載不均問題。
資料中轉耗時多
NFS客戶端讀寫一個檔案的時候只能向已掛載的NFS伺服器發起請求,因為檔案資料被打散分佈在多個NFS伺服器上,所以NFS伺服器上會有一個中轉操作,見圖2。
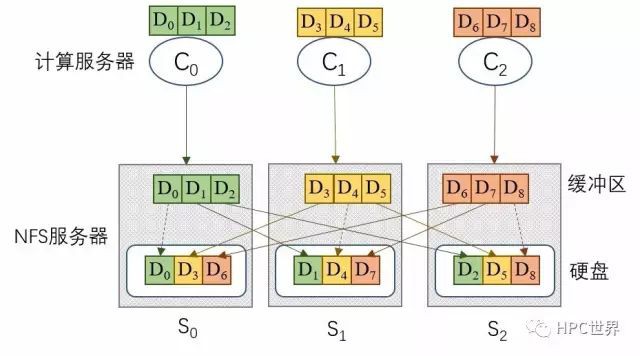
圖 2
圖2中,計算伺服器C0需要向NFS伺服器S0寫入3個連續資料塊D0~D2,而資料塊D0~D2應該分別放置在NFS伺服器S0~S2上。因此,S0需要在緩衝區暫存資料D0~D2,將D0寫入自己的本地硬碟,透過網路將D1和D2分別傳送給NFS伺服器S1和S2。等D0~D2都正確地寫入硬碟,S0才會向C0傳回寫成功的訊號。
不妨將計算伺服器與NFS伺服器之間的資料流量稱為外部流量,將NFS伺服器之間的資料流量稱為內部流量。顯然圖2中的外部流量為9(9個資料塊),內部流量為6。容易推算,NFS伺服器的數量為M的時候,外部流量與內部流量的比例是M:M-1。在M較大的時候,例如10,有效流量(外部流量)的比例稍稍超過50%,等價於將網路頻寬上限降低於一半,嚴重影響檔案系統效能。一個解決辦法是增加一套網路交換機、每臺NFS伺服器增加一個網口,專走內部流量,當然這樣會增加成本。
即使配備內部網路,仍然無法解決IO路徑長的問題:檔案資料從NFS客戶端走到NFS伺服器上的硬碟上,幾乎都要走一個中轉過程(比例(M-1)/M),必然導致延時變長。作為對比,看看Lustre的IO路徑,見圖3,資料塊的最終目的地是哪個IO伺服器,計算伺服器上的Lustre客戶端就將資料塊傳送到哪個IO伺服器,不但節省了內部流量(從而省了交換機和網絡卡)而且減小了延時。
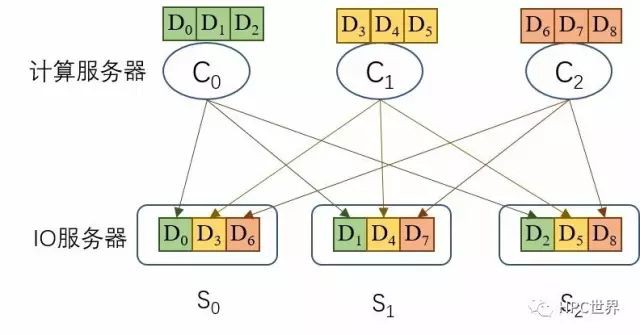
圖 3
也許有人會想,能不能將圖2中內部流量在NFS伺服器的記憶體中暫存一下啊,資料一旦寫入記憶體就告訴NFS客戶寫成功了。這個思路正確,但需要將內部流量暫存在保電的記憶體中(例如NVDIMM或NVRAM,就是記憶體條上配備電容或電池),防止伺服器突然掉電而丟失暫存的資料。保電記憶體會增加成本,價格比普通記憶體條貴不少。
保電記憶體仍然不能消除讀操作的資料中轉延時,見圖4。仍然拿Lustre檔案系統來對比,見圖5,安裝在計算伺服器上的Lustre客戶端先從元資料伺服器(MDS)獲得檔案分佈圖(layout),然後就知道了每一個資料塊都存放在哪個IO伺服器的哪個位置, Lustre客戶端直接從相應的IO伺服器上讀取資料塊,沒有中轉,節省內部流量而且消除了中轉延時。
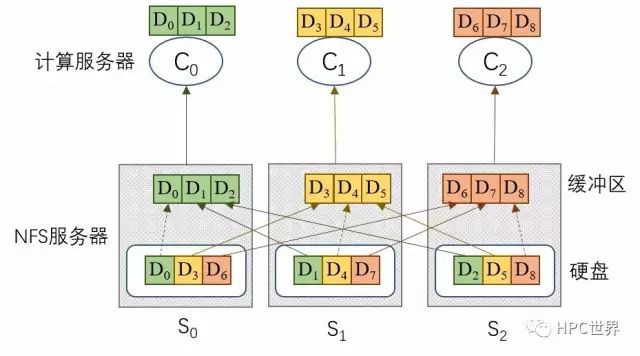
圖 4
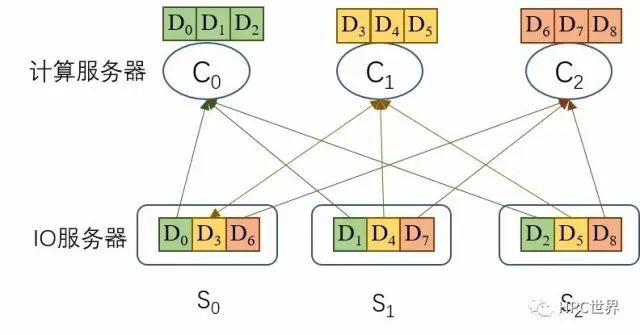
圖 5
最嚴重的問題還是一致性和檔案鎖
ROMIO官方檔案[1]說,決不鼓勵在NFS儲存上執行MPI-IO程式,原檔案如下:
It is worth first mentioning that in no way do we encourage the use of ROMIO on NFS volumes. NFS is not a high-performance protocol, nor are NFS servers typically very good at handling the types of concurrent access seen from MPI-IO applications.
必須首先強調,我們決不鼓勵在NFS捲上使用ROMIO。NFS不是一個高效能的協議,NFS伺服器通常也不擅長處理MPI-IO應用裡的併發訪問。
由於NFS協議非常流行,ROMIO必須硬著頭皮支援NFS儲存。但有下麵3個前提要求[1]:
-
NFS v3客戶端
-
在掛載的NFS目錄上,檔案鎖函式 fcntl必須能夠正常工作
-
計算伺服器掛載NFS儲存的時候必須使用選項noac
其實不強制要求v3版本的NFS客戶端,只要檔案鎖函式fcntl正常工作就行,但用NFS v3能夠保證fcntl正常工作,省去了驗證的麻煩。
為什麼要求檔案鎖函式fcntl和選項noac呢?ROMIO官網並沒有解釋,而論文[2]說出了其中原理。
檔案鎖保證併發訪問的正確性
NFS協議是為序列訪問設計的,即每個客戶端訪問不同的檔案,不支援多個客戶端同時訪問同一個檔案。具體表現為,檔案描述符(對應open函式傳回的檔案控制代碼)不能共享:如果N個客戶端想同時讀寫同一個檔案,那麼N個客戶端都必須呼叫一次open函式以便得到檔案描述符。這個N客戶端雖然開啟同一個檔案,但客戶端之間並不相互協調,相互不知道對方的動作,可能導致寫衝突。
假設客戶端C1和C2同時寫檔案f1.txt,C1寫的範圍是[0-1023]位元組,而C2寫的範圍是[512-1515]位元組。按照NFS協議,C1和C2之間不相互協調,那麼就可能導致C1和C2同時寫檔案區間[512-1023],檔案中最終資料不可預知。
為了避免資料衝突,ROMIO使用檔案鎖函式fcntl。在C1準備寫檔案的[0-1023]位元組時,先呼叫函式fcntl鎖住這個檔案區間,以便客戶端C1獨佔操作。客戶端C2寫檔案區間[512-1023]寫資料時,檔案系統發現區間[512-1023]被客戶端C1鎖住了,於是讓客戶端C2等待。客戶端C1寫操作完成之後C2才能開始寫。
fcntl保證並行IO操作的正確性,代價是降低了效能。按照MPI-IO分析文章中的經驗推斷,集合IO涉及的MPI行程越多,鎖競爭越激烈,效能下降越嚴重。
noac選項關掉快取
因為NFS設計時就沒有考慮多個行程同時讀寫同一個檔案的情況,所以NFS客戶端就可以採用激進的快取機制:不但快取檔案資料還快取檔案屬性資訊。檔案屬性包含讀、寫、執行許可權、atime(access time, 最後1次訪問時間 )/mtime(modification time,最後修改時間)/ctime(change time,元資料的最後改變時間)等。
這樣以來,多個MPI行程聚合IO時就有檔案同步的問題:如果開啟了資料快取機制,行程A透過NFS客戶端CA寫入檔案區間[0-511],操作傳回時,檔案資料可能真的已經寫到NFS伺服器的硬碟上,也可能還停留在CA的快取裡。假設緊接著的MPI聚合IO操作要求行程B透過NFS客戶端CB讀取檔案區間[0-511],這時就會出現3種情形:
- NFS客戶端CA已經將檔案區間[0-511]寫入NFS伺服器,而NFS客戶端CB也沒有快取區間[0-511]的資料(壓根沒快取或者舊快取過期了)。此時行程B透過CB讀檔案區間[0-511]的請求使得CB向NFS伺服器請求檔案資料,從而行程B能得到正確資料。
- NFS客戶端CA還沒有將檔案區間[0-511]寫入NFS伺服器,仍然儲存在CA的快取中。此時NFS客戶端CB無論如何也讀不到最新的資料,從而行程B能得到錯誤的舊資料。
- NFS客戶端CA已經將檔案區間[0-511]寫入NFS伺服器,而NFS客戶端CB本地快取了檔案屬性和檔案區間[0-511]的資料。行程B向CB請求讀檔案區間[0-511]時,CB就會對比檔案資料快取的更新時間和檔案屬性快取中記錄的檔案最後修改時間(mtime等)。因為客戶端CA不能主動向客戶端CB推送檔案已經更新訊息,而客戶端CB快取的掃清又有一定的時間間隔,所以客戶端CB就可能得出錯誤的結論:快取中的檔案資料就是最新的,不用從NFS伺服器重新讀取。最終導致行程B讀到錯誤的舊資料。
行程A和行程B先後寫同一個檔案區間的場景,NFS快取也有可能導致資料錯誤,過程類似,請讀者自行分析,不贅述。
保證MPI 集合IO結果正確的必要條件是:一個行程的操作結果能被其它行程立即看到。讀者可以拿上面行程A和行程B先寫後讀同一個檔案區間的場景來驗證,將寫操作涉及的檔案資料立即刷入NFS伺服器+檔案屬性資訊在行程間保持同步就能避免那些錯誤的發生。
檔案屬性同步很簡單,用noac選項關掉檔案屬性快取即可。這樣以後,NFS客戶端每次檢視檔案屬性的時候都要向NFS伺服器抓取。仍然拿行程A和行程B先寫後讀的場景來說:客戶端CA將檔案區間[0-511]立即寫入NFS伺服器,NFS伺服器上檔案屬性也隨之更新;客戶端CB讀取檔案區間[0-511]時,先從NFS伺服器獲取最新的檔案屬性,與本地快取的檔案資料的更新對比後發現NFS伺服器上的資料是最新的,於是棄用本地快取的資料,轉而從NFS伺服器讀取最新的檔案資料。行程B讀到正確資料。
關掉快取,向NFS伺服器寫入、請求檔案屬性的次數就會大增,會降低儲存系統的效能。
不知道鎖邊界
ROMIO對集合IO的最佳化關鍵是巧妙利用檔案系統的鎖粒度。使用“鎖界對齊”、“靜態迴圈”、“分組迴圈”幾個大招的前提是知道檔案的鎖邊界在哪裡。Lustre、GPFS等並行檔案系統介面豐富,可以方便地獲取鎖邊界。而NFS協議沒有這樣的介面命令,ROMIO不知道NFS儲存裝置上的鎖粒度,很可能使用預設的“均勻剖分”策略,顯然不能達到最好效能。
NFS儲存實測效能
前面都是從原理上定性分析MPI集合IO在NFS儲存上效能差,有沒有定量分析呢?到底差到什麼程度呢?是降低10%還是降低90%呢?
回答是:沒有在嚴肅的學術論文中看到NFS的並行IO效能資料。推測原因可能有這些:
- 技術實力雄厚的超算中心早就知道NFS儲存不適合,沒有採購,也就沒有實測資料。
- 業界已知的結論,定量對比也算不上亮眼的成果,就不浪費時間寫這方面的論文了。
- 即使大中型超算採購了NFS儲存,釋出效能差的資料是自己打臉,沒幾個人會幹。
儘管如此,效能下降幅度還是可以估算的。網路上有人聲稱[3] noac選項會降低至20%的寫頻寬,可信度請自行分辨。
參照Lustre,如果ROMIO對NFS儲存採用“均勻剖分”策略,那麼它的效能最差情況下只有“分組迴圈”的4%(500/13000),見圖6。

圖 6
負載不均、資料中轉對效能的影響沒看到資料。但noac選項和檔案鎖fcntl這兩項就可能使效能下降至0.8%(20%*4%)。如果您知道更多更準確的資料,煩請告知。
參考文獻
[1] ftp://ftp.mcs.anl.gov/pub/romio/users-guide/node12.html
[2] Latham R., Ross R., Thakur R. (2004) The Impact of File Systems on MPI-IO Scalability. In: Kranzlmüller D., Kacsuk P., Dongarra J. (eds) Recent Advances in Parallel Virtual Machine and Message Passing Interface. EuroPVM/MPI 2004. Lecture Notes in Computer Science, vol 3241. Springer, Berlin, Heidelberg
[3] http://beowulf.beowulf.narkive.com/9ZbvJ8JH/mpi-io-nfs-alternatives
來源:HPC世界
推薦閱讀:
溫馨提示:
請識別二維碼關註公眾號,點選原文連結獲取更多HPC高性算技術資料總結。



